
📌 머신러닝 개요
📖 머신러닝 개념
머신러닝은 인공지능(AI)의 하위 집합이다.
학습과 개선을 위해 명시적으로 컴퓨터를 프로그래밍하는 대신, 컴퓨터가 데이터로 학습하고 경험을 통해 개선하도록 훈련하는 데 중점을 둔다.
머신러닝에서 알고리즘은 대규모 데이터 세트에서 패턴과 상관관계를 찾고 분석을 토대로 최적의 의사결정과 예측을 수행하도록 훈련된다.
머신러닝 애플리케이션은 적용을 통해 개선되며 이용 가능한 데이터가 증가할수록 더 정확해진다.
📖 CHPTCHA(캡차)
Completely Automated Public Turing test to tell Computers and Humans Apart의 약자로 "사람과 컴퓨터를 판별하는 튜링 테스트" 라는 의미를 가진다.
📌 인공지능의 종류
📖 약한 인공지능 (Weak AI)
- 학습을 통해 문제를 해결
- 주어진 조건 아래서만 작동 > 사람을 흉내 내는 수준
- 자율자동차, 구글 번역, 페이스북 추천, 등
- 구글 AlphaGo, IBM Watson, 아마존 Alexa, Apple Siri, 등
📖 강한 인공지능 (Strong AI)
- 사고를 통해 문제 해결
- 사람과 같은 지능 (추론, 문제해결, 계획, 의사소통, 감정, 지혜, 양심)
- <에이아이> '데이빗', <아이 로봇> '써니', <엑스 아키나> '에이바'
📖 초 인공지능 (Super AI)
- 창의력을 통해 문제 해결
- 모든 영역에서 인간을 뛰어넘는 인공지능
- <매트릭스> '아키텍트', <터미네이터> '스카이넷', <트랜센던스> '캐스터'
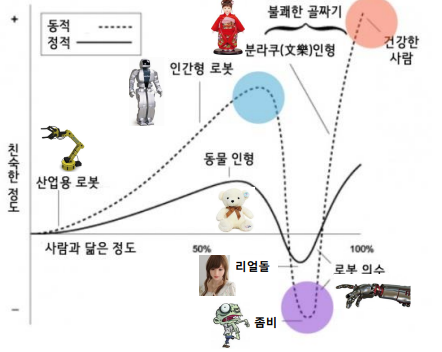
📌 불쾌한 골짜기 (Uncanny valley)
인간이 로봇에 느끼는 호감도가 증가하다가 어느정도에 사람과 유사해지면 갑자기 강한 거부감을 느끼는 현상 (1970), 모리 마사히로
📌 머신러닝의 종류
📖 지도학습 (Supervised Learning)
- 데이터에 대한 Label(명시적인 답)이 주어진 상태에서 컴퓨터를 학습시키는 방법
- 분류(Classification)와 회구(Regression)으로 나뉘어진다.
📋 분류 (Classification)
- 미리 정의된 여러 클래스 레이블 중 하나를 예측하는 것
- 속성 값을 입력, 클래스 값을 출력으로 하는 모델
- 붓꽃(iris)의 세 품종중 하나로 분류, 암 분류 등
- 이진분류, 다중 분류, 등이 있다.
📋 회귀 (Regression)
- 연속적인 숫자를 예측하는 것
- 속성 값을 입력, 연속적인 실수 값을 출력으로 하는 모델
- 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득 예측
- 예측 값의 미묘한 차이가 크게 중요하지 않다.
📖 비지도 학습 (Unsupervised Learning)
- 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법.
- 데이터의 숨겨진 특징, 구조, 패턴을 파악하는데 사용
- 데이터를 비슷한 특성끼리 묶는 클러스터링(Clustering)과 차원 축소(Dimensionality Reduction)등이 있다.
📖 강화 학습 (Reinforcement Learning)
- 지도학습과 비슷하지만 완전한 답(Label)을 제공하지 않는 특징이 있다.
- 기계는 더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
- 주로 게임이나 로봇을 학습시키는데 많이 사용
📌 머신러닝 활동 분야
- 기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 전혀 해결 방법이 없는 복잡한 문제
- 새로운 데이터에 적응해야하는 유동적인 환경
- 대량의 데이터에서 통찰을 얻어야 하는 문제
📌 머신러닝 학습과정
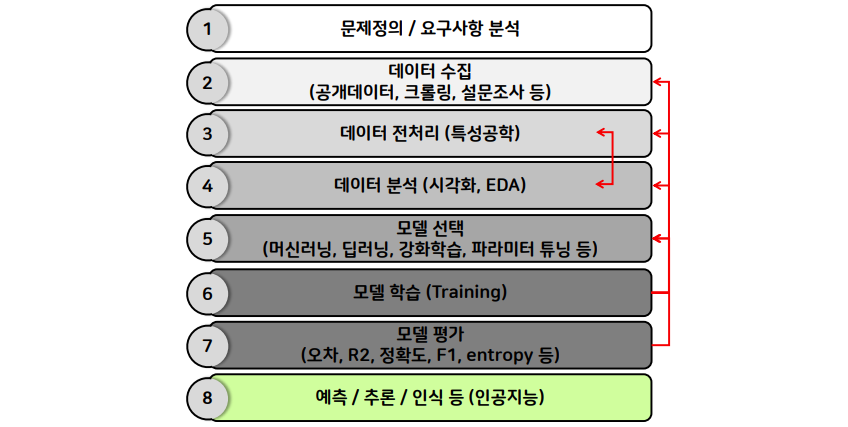
📖 1. Problem identification (문제정의)
- 비즈니스 목적 정의
- 현재 솔루션의 구성 파악
- 지도 vs 비지도 vs 강화
- 분류 vs 회귀
📖 2. Data Collect (데이터 수집)
- File (CSV, XML, JSON)
- Database
- Web Crawler (뉴스, SNS, 블로그, 등)
- IoT 센서를 통한 수집
- Survey
📖 3. Data Preprocessing (데이터 전처리)
- 결측치 처리 (삭제 or 대체 (중간, 평균, 예측값, 등))
- 이상치(outlier) 처리 (삭제 or 대체 (중간, 평균, 예측값, 범주화, 등))
- Cleaning (오류 수정)
- Feature Engineering (특성공학)
- Scaling (단위 변환)
- Transform (새로운 속성 추출)
- Encoding (범주형 > 수치형)
- Binning (수치형 > 범주형)
- Normalization (정규분포화)
- 범주형 데이터 통합
📖 EDA (탐색적 데이터분석)
- 기술통계, 변수간 상관관계
- 시각화
- Feature Selection (사용할 특성 선택)
- 단변수 시각화 : Histogram(빈도수), Doxplot(평균, 중간값, 등)
- 이변수 시각화 : Scatter plot (수치 상관관계), 누적막대그래프 (범주, 독립성 분석), 범주별 Histogram
- 다변수 시각화 : Violin plot, 3차원 그래프, 등
📖 Model 선택, Hyper Parameter 조정
- 목적에 맞는 적절한 모델 선택
- KNN, SVM, Linear Regression, Ridge, Lasso, Decision Tree, Random forest, CNN, RNN ...
- Hyper Parameter
📖 Model Training (학습)
- model.fit (X_train, y_train)
(train 데이터와 test데이터를 7:3 정도로 나눔)- model.predict(X-test)
📖 Evaluation (평가)
- MSE / RMSE
- R2 Score
- accuracy (정확도)
- recall (재현율)
- precision (정밀도)
- f1 score
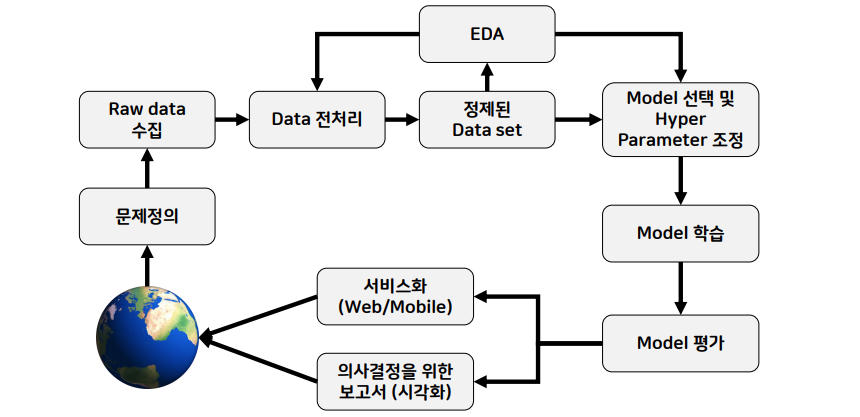
📌 머신러닝 학습과정

숨쉬는 돌멩이, 말하는 감자.