
📌 개요
머신러닝에 대해 간단한 실습을 하는 동시에,
Python을 다시 집어가며 복습을 해보려고 합니다!
제가 사용한 Tool과 데이터 들은 바로 아래를 통해 확인해 주세요!
📖 Tool / Satting
- Python
- Jupyter
- file (csv)
📖 File
https://drive.google.com/drive/folders/1hxGgCnvdsAtzsG6lXUXJoxeSyr4C4iux 에 가서 아래 파일 2개를 다운받아서 같은 폴더 내로 파일 옮기기!
CCTV_in_Seoul.csv
population_in_Seoul.xls
📌 코딩 시작!
📖 학습 목표
- 서울시 각 구별 CCTV수를 파악해보자!
- 인구대비 CCTV가 많거나 적은 지역 파악하기!
📋 파일 세팅
✍ 입력
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt📋 csv파일 읽기
✍ 입력
CCTV_Seoul = pd.read_csv('CCTV_in_Seoul.csv')✍ 입력
CCTV_Seoul.head(2)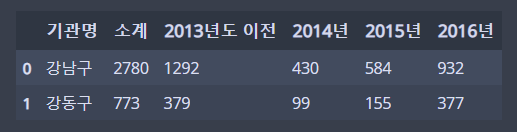
💿 수정파일 저장
CCTV_Seoul.rename(columns={'기관명':'지역구'}, inplace=True)📋 Excel파일 읽기
pop_Seoul = pd.read_excel('population_in_Seoul.xls', header=2, usecols="B,D,G,J,N")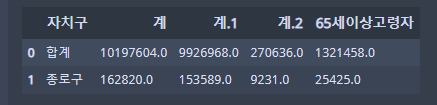
✍ 입력
pop_Seoul.columns = ['지역구', '인구 수', '한국인 수', '외국인 수', '65세이상 고령자 수']계, 계.1 ,등으로 나온 컬럼들의 이름을 수정해주는 코드

이렇게 수정이 잘 됐다는 것을 확인 할 수 있다.
📖 결측치 확인
✍ 입력
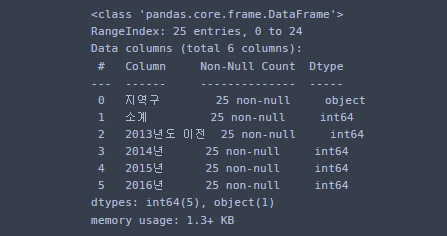
CCTV_Seoul.info()info 함수를 사용하면 데이터의 대략적인 정보를 확인 할 수 있디.
✍ 입력
pop_Seoul.info()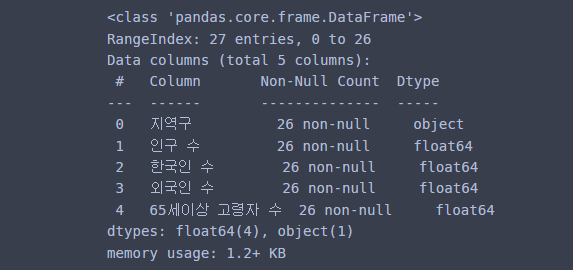
✍ 입력
pop_Seoul['한국인 수'].isnull().isnull을 사용하면 > 불리언(T/F) 값으로 반환하고, 결측치 값에만 True를 반환한다.
💻 출력

✍ 입력
pop_Seoul[pop_Seoul['한국인 수'].isnull()]불리언 인덱싱 - 조건 필터링을 하게 되면, True 자리의 데이터만 반환한다.
💻 출력

결측치 삭제
pop_Seoul.drop(26, inplace=True)axis = 0 디폴트값 (기본값) 이며, 컬럼을 삭제 할 때에는 axis = 1로 설정해주어야 한다.
✍ 입력
pop_Seoul.drop('외국인 수', axis=1)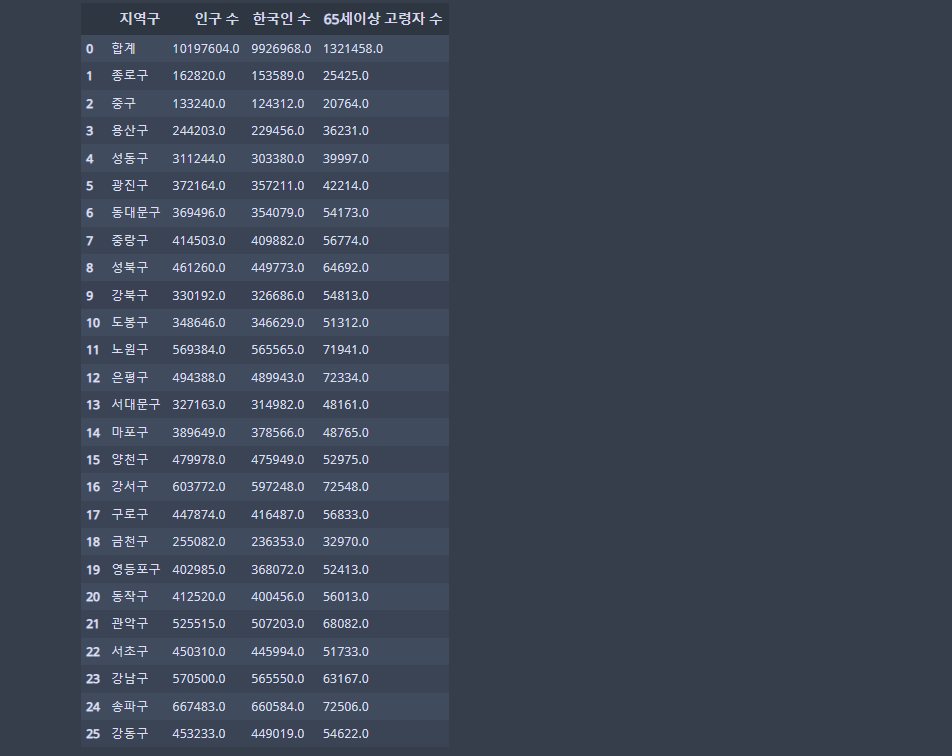
📖 CCTV수가 많거나 적은 지역을 파악
CCTV_Seoul.sort_values(by='소계')파이썬에서 정렬하는 함수는 sort_index()과 sort_values()가 있다.
나는 내림차순 정렬을 해보려고 한다.
✍ 입력
CCTV_Seoul.sort_values(by='소계', ascending=False).head(5)
📖 데이터 프레임 병합
CCTV_지역구_set = set(CCTV_Seoul['지역구'].unique())
pop_지역구_set = set(pop_Seoul['지역구'].unique())중복 없는 데이터를 먼저 확인 한다.
✍ 입력
CCTV_지역구_set - pop_지역구_set
pop_지역구_set - CCTV_지역구_set컬럼들에 대한 정보들을 뺴주고, 확인 한다.
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on='지역구')merge(df1, df2, on=기준), how : 병합의 방식을 지정, inner, outer, left, right
data_result💻 출력
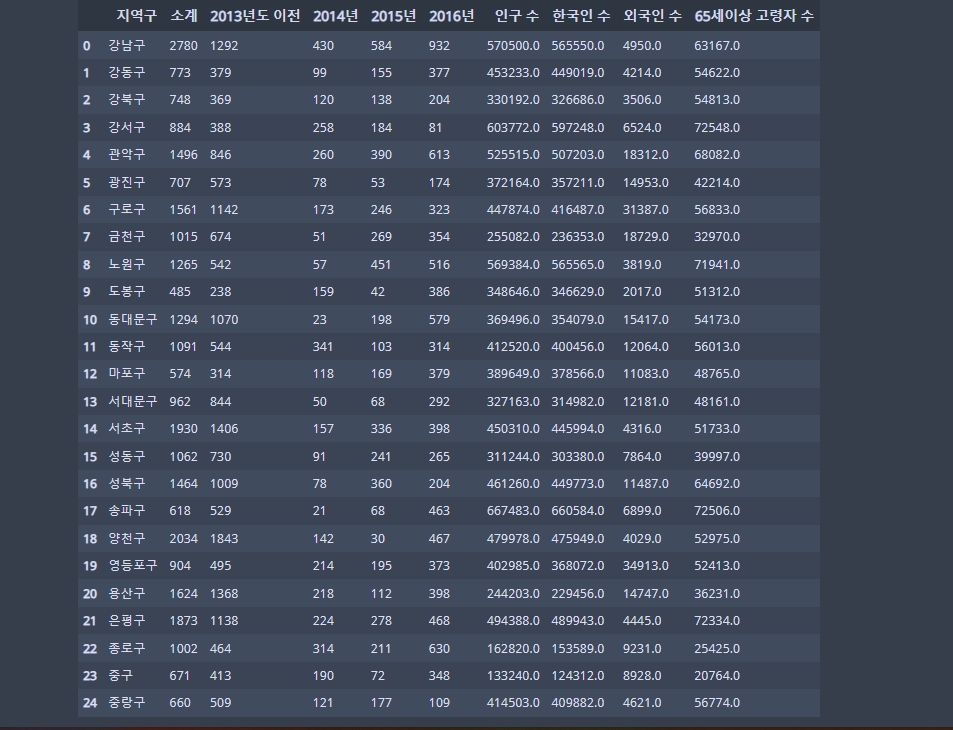
데이터를 묶어서 지역별 인구와 CCTV수를 확인한다.
📖 인구수 대비 CCTV 비율 알아보기
data_result['인구대비 CCTV비율'] = (data_result['소계'] / data_result['인구 수']) * 100연산된 값을 새 컬럼으로 만들어주는 동시에, 새 컬럼 생성 : 기존에 없는 컬럼 이름에 값을 대입,
컬럼 수정: 기존의 컬럼에 값을 대입시켜주면 값만 수정된다.
✍ 입력
data_result.sort_values(by='인구대비 CCTV비율')인구수 대비 CCTV가 많은 지역을 오름차순으로 정렬 했다.
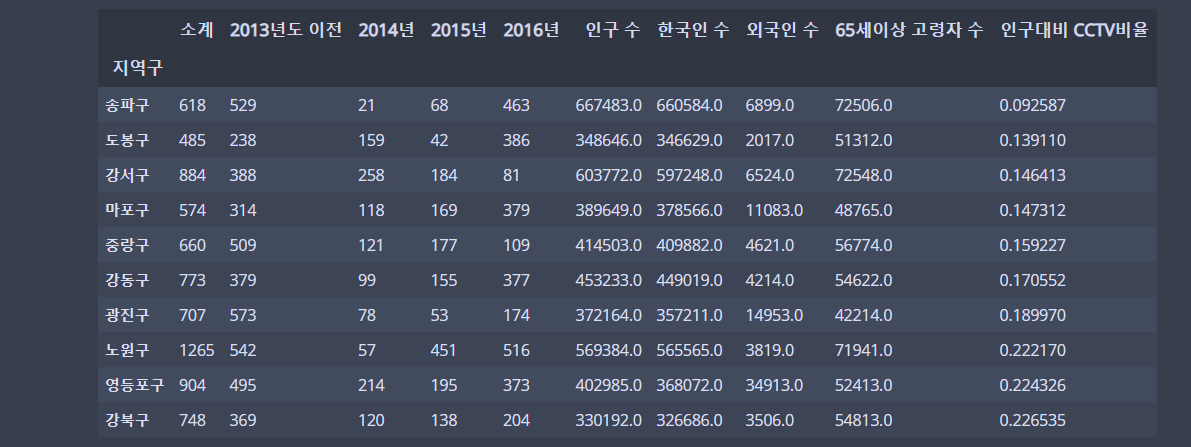
✍ 입력
x = data_result.sort_values(by='인구대비 CCTV비율')['지역구']
y = data_result.sort_values(by='인구대비 CCTV비율')['인구대비 CCTV비율']from matplotlib import rc
rc('font', family='Malgun Gothic')한글이 지원되는 폰트로 설정해 준다.
✍ 입력
plt.figure(figsize=(9,6)) # (가로,세로) 그리프 크기지정
plt.barh(x, y)
plt.xlabel('인구대비 CCTV비율') # x축이름
plt.ylabel('지역구') # y축 이름
plt.grid() # 격자무늬 생성
plt.show()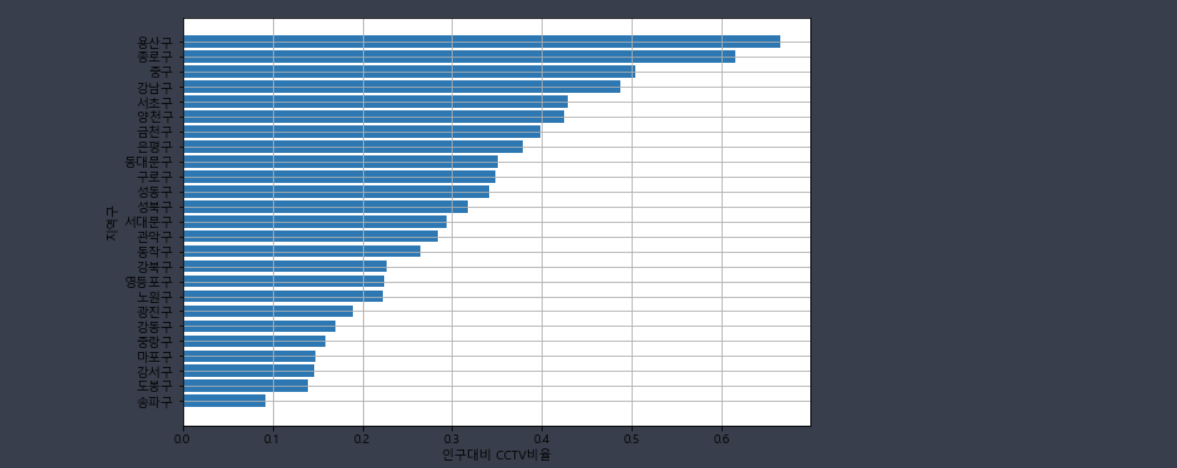
보기가 편하게 하기 위해 나는 가로 그래프로 했다.
📖 상관계수 확인
data_result.head()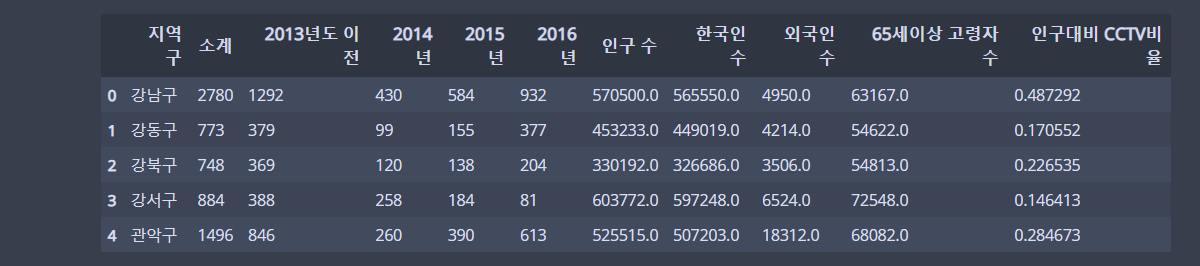
✍ 입력
data_result.set_index('지역구', inplace=True)구 컬럼을 인덱스로 설정해준다.
✍ 입력
data_result.head(2)💻 출력

✍ 입력
data_result.corr()💻 출력
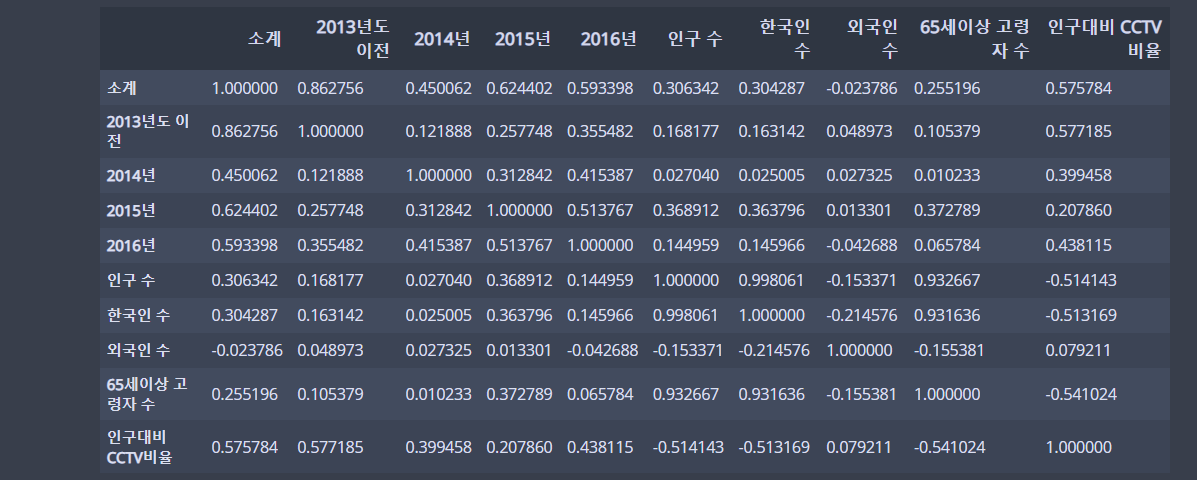
상관계수, -1 ~ 1 사이값을 반환한다.
