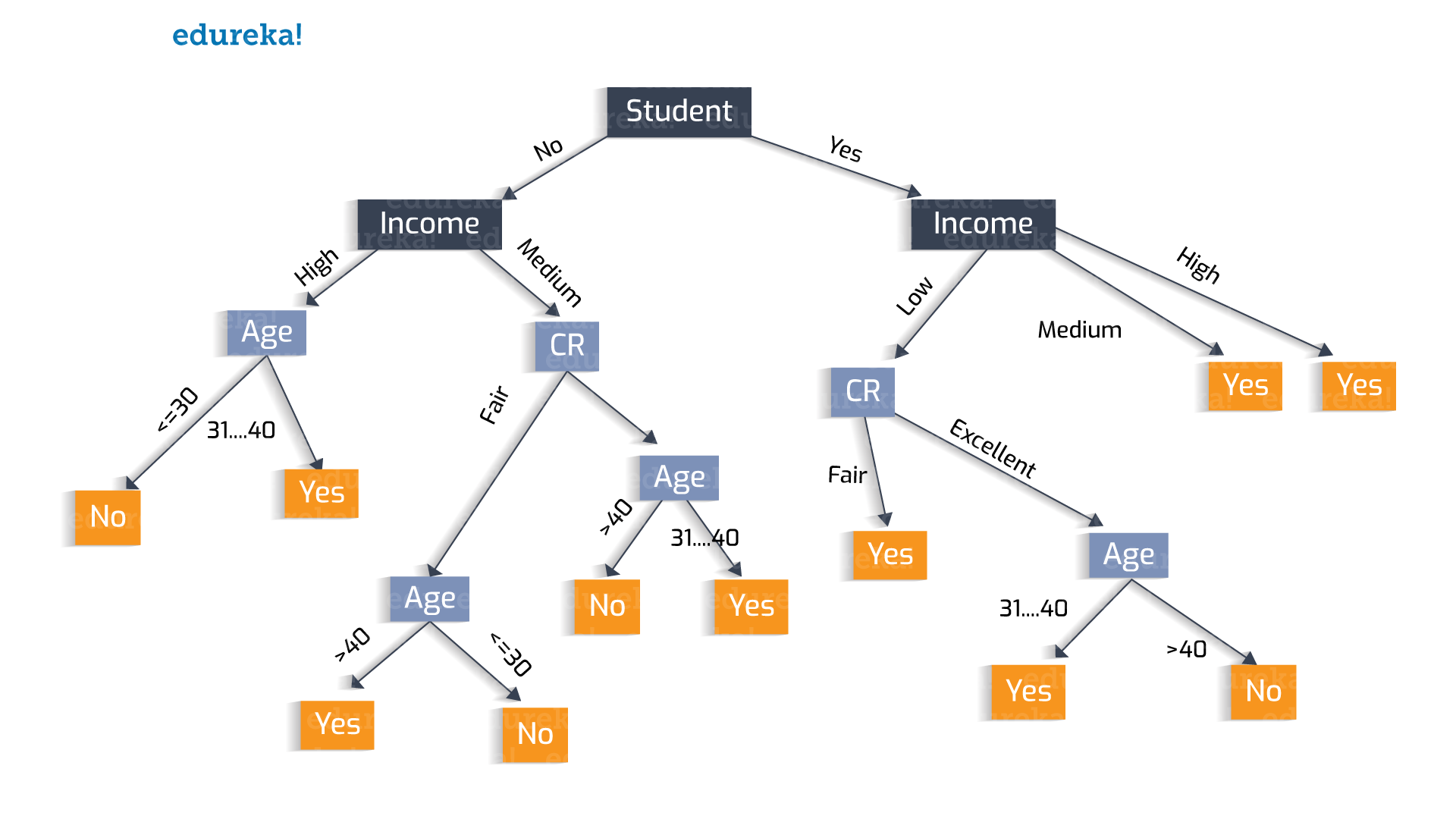
📌 DecisionTree 란?
의사 결정 트리는 우연 이벤트 결과, 리소스 비용 및 유틸리티 를 포함하여 트리와 같은 의사 결정 모델 과 가능한 결과 를 사용 하는 의사 결정 지원 도구입니다 . 조건부 제어문만 포함 하는 알고리즘 을 표시하는 한 가지 방법 입니다.
📖 라이브러리 삽입
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt📌 데이터
data = pd.read_csv('mushroom.csv')📖 데이터 컬럼 수 확인
data.shape📋 데이터 정보
data.info()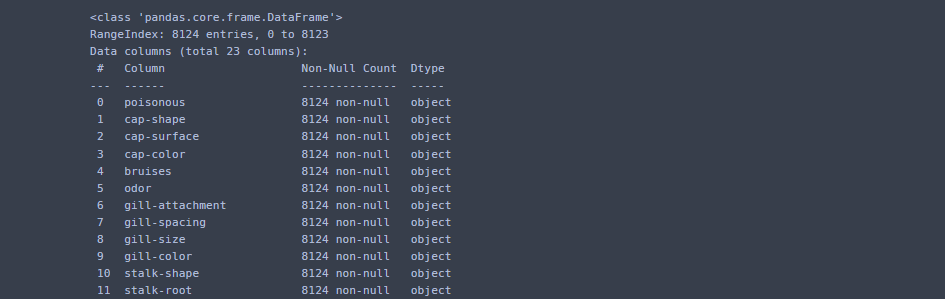
📋 데이터 확인
data.head()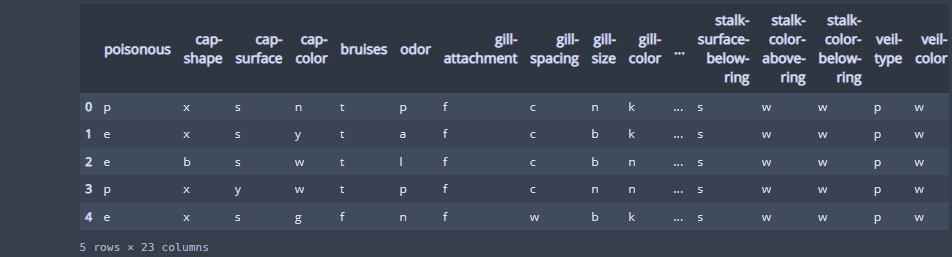
📖 문제와 정답으로 나누기
X = data.loc[:, 'cap-shape':]
y = data['poisonous']📋 데이터의 통계값 확인
data.describe()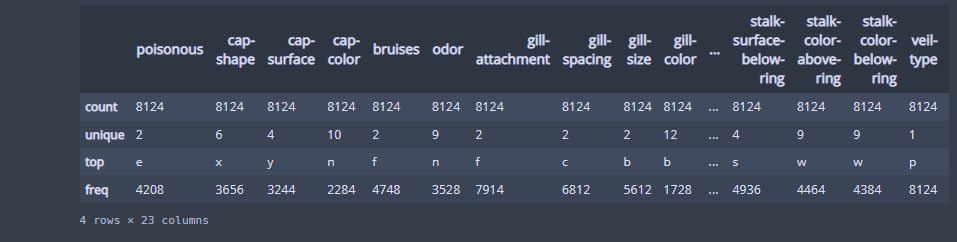
📌 원-핫 인코딩
- 인코딩 : 머신러닝 모델이 문자로 학습이 안된다 > 숫자 데이터로 바꿔준다!
- 라벨 인코딩 : 단순 수치로 매핑함 > 순서사 있는 데이터라면 괜찮다!
- 원-핫 인코딩 : 0, 1 만을 이용하여 데이터 표현
- 분류하고자 하는 범주만큼 자릿수(특성 수)를 만들고 해당하는 데이터는 1, 나머지는 0으로 표현하는 방법!
- 범주형 데이터를 표현하는 가장 많이 쓰이는 방법!
📖 원-핫 데이터 만들기
X_one_hot = pd.get_dummies(X)확인
X_one_hot💻 출력
📌 모델링
📖 라이브러리 삽입
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X_one_hot,
y,
test_size=0.3)X_train.shape, y_train.shape
X_test.shape, y_test.shape
📖 라이브러리 삽입
from sklearn.tree import DecisionTreeClassifier📋 모델생성
tree_model = DecisionTreeClassifier()📋 학습
tree_model.fit(X_train,y_train)
📋 평가
tree_model.score(X_train, y_train)
📋 평가 데이터로의 평가
tree_model.score(X_test, y_test)
일반화 : 훈련데이터에 적당히 학습이 되서 평가데이터를 잘 맞추는 형상
과대적합 : 훈련데이터에 과대적합, 평가데이터에도 과대적합
📌 시각화
!pip install graphviz
📖 라이브러리 삽입
from sklearn.tree import export_graphviz
export_graphviz(tree_model, out_file='tree.dot',
class_names=['p','e'],
feature_names=X_one_hot.columns,
impurity=False, # 불순도를 그림에 표현 할 것인가?
filled=True)📋 시스템 환경 변수 등록하기
import os
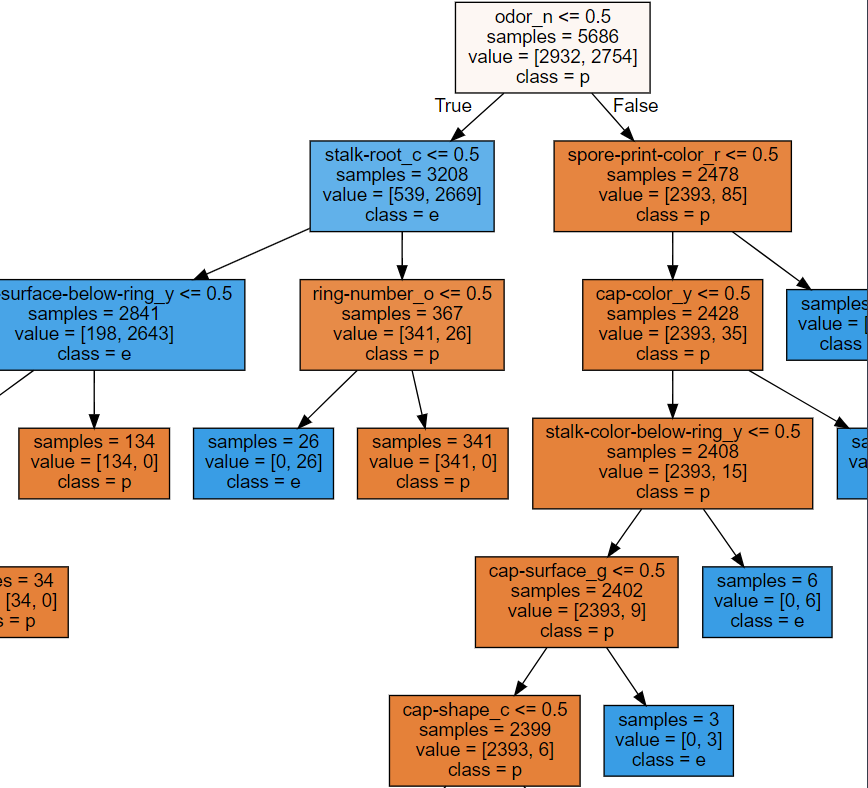
os.environ["PATH"]+=os.pathsep+'C:/Program Files/Graphviz/bin/'📖 Decision Tree
import graphviz
with open('tree.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))💻 출력
📋 tree.png 파일 생성
from subprocess import check_call
check_call(['dot','-Tpng','tree.dot','-o','tree.png'])📌 모델수정
max_depth=None => 질문을 끝까지 계속 던짐.
tree_model2 = DecisionTreeClassifier(max_depth = 3)📋 모델 분리
tree_model2.fit(X_train, y_train)📖 확인
export_graphviz(tree_model2, out_file='tree2.dot',
class_names=['p','e'],
feature_names=X_one_hot.columns,
impurity=False,
filled=True)
check_call(['dot','-Tpng','tree2.dot','-o','tree2.png'])📌 특성 선택
Decision Tree가 생각하는 특성별 중요도
전체 특성의 중료도를 보여줌(117개)
0 ~ 1 까지 숫자로 표현
0 = 중요하지 않다, 사용하지 않았다.
전체의 합이 1
✍ 입력
fi = tree_model2.feature_importances_학습 / 예측시에 시간이 오래걸리면
중요하지 않은 컬럼 삭제 > 성능저하, 속도향상
df = pd.DataFrame(fi, index= X_one_hot.columns)
df.sort_values(by = 0, ascending= False)💻 출력

📌 교차검증
✍ 입력
from sklearn.model_selection import cross_val_score
# 사용할 모델, 문제데이터, 정답데이터, 데이터 분할 수(cv)
score = cross_val_score(tree_model2, X_train, y_train, cv=5)
score서로 다른 5개의 데이터로 판단한 결과의 평균
새로운 데이터가 들어왔을때 대략적으로 보여줄 성능
score함수 대신 교차검증을 사용해서 확인하는게 더 정확함
✍ 입력
score.mean() 💻 출력


숨쉬는 돌멩이, 말하는 감자.