
이번 포스팅은 4강에 대한 내용입니다.
이번 내용은
역전파(Backpropagation)
신경망(Neural Networks)
이었습니다.
크게 나누면 2가지 밖에 안되었으나, 굉장히 어려웠다.
Forward Pass(FP)가 순방향, input값에 의해서 마지막까지 어느 영향을 끼치는가에 대한 것이라면,
Backpropagation(역전파)은 FP값을 구하기 위해 '역순'으로 계산하는 과정을 뜻합니다.
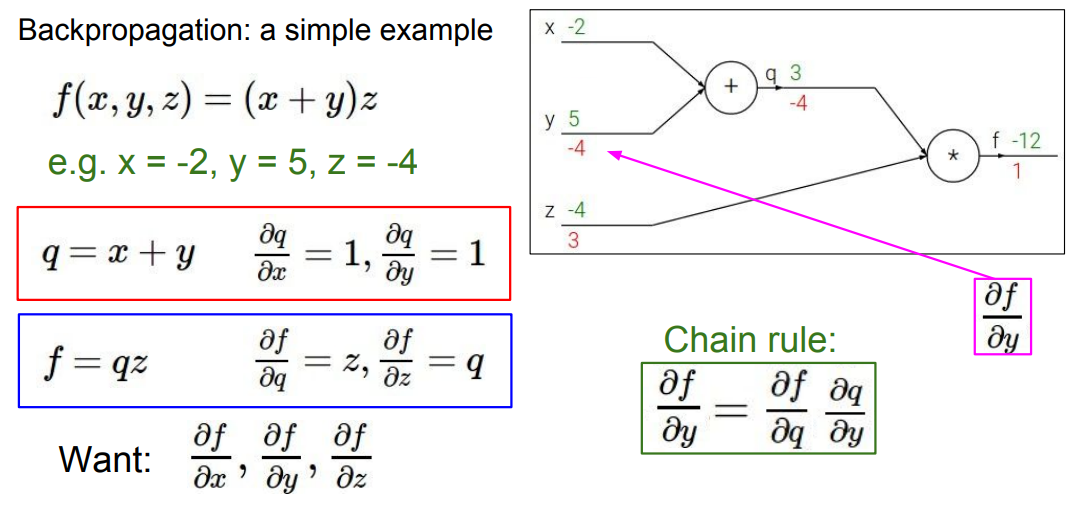
위 그림은 역전파의 예시를 들기 위해서 나온 그림입니다.
초기 input값을 구하기 위해서 역순으로 구하는 것이어서 오른쪽부터 거꾸로 보면 됩니다.
또한 ∂q / ∂x 값이 'local gradient'
옆에 있는 ∂f / ∂q는 'global gradient'라고 합니다.
FP시에는 local gradient값을 구해서 메모리에 저장하고,
'역전파'시에는 local gradient와 global gradient값을 서로 곱해주는(Chain rule)을 사용해서 구할 수 있습니다.
이 예시가 input값이 단순 3가지일 때의 예시이고,
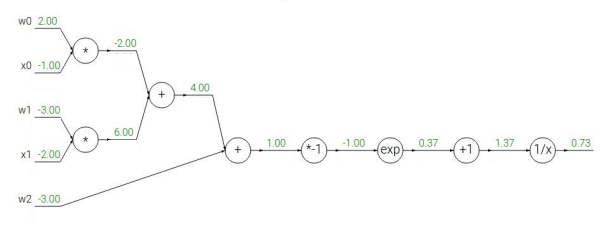
이 예시는 input값이 더 많을 때의 예시 입니다.
역전파시, 위의 Chain rule방식을 동일하게 사용하고,
여기서 각각의 연산자는 다음과 같은 특징을 갖고 있습니다.
Add gate: gradient distributer(경사 분배기)
Max gate: gradient router(경사 라우터)
Mul gate: gradient switcher(경사 스위처)
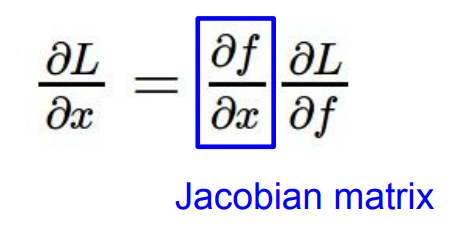
또 벡터(Matrix)구조를 가진 순전파, 역전파 예시도 나왔습니다.
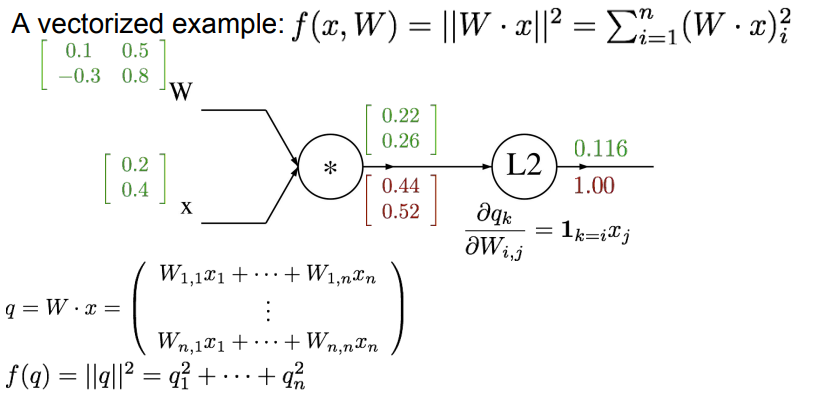
모든 계산과정은 위와 동일하고, Matrix만 추가된 구조입니다.
신경망(Neural Networks)
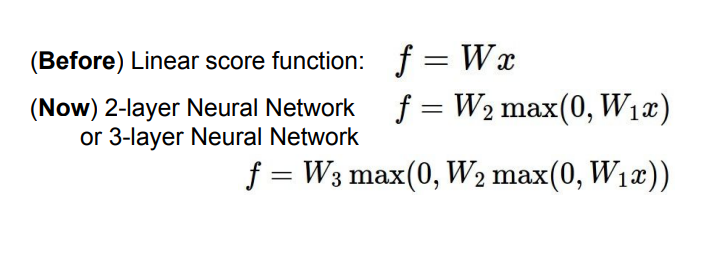
가장 기초가 되는 선형 함수에서는 f = Wx로,
2-layer NN에서는 W_2 max(0, W_1x)로,
계층이 하나씩 늘어날 수록, 그 중에서 최댓값(Max)을 뽑아내는 것입니다.
또한 여러 활성화 함수가 존재하는데,

대표적으로 이렇게 총 6가지의 활성화 함수를 설명했습니다.
sigmoid함수를 많이 사용한다(0 ~ 1값에 수렴하기 때문)고 했는데, 각 활성화 함수의 특징은 다음에 다룬다고 했다.
그리고,
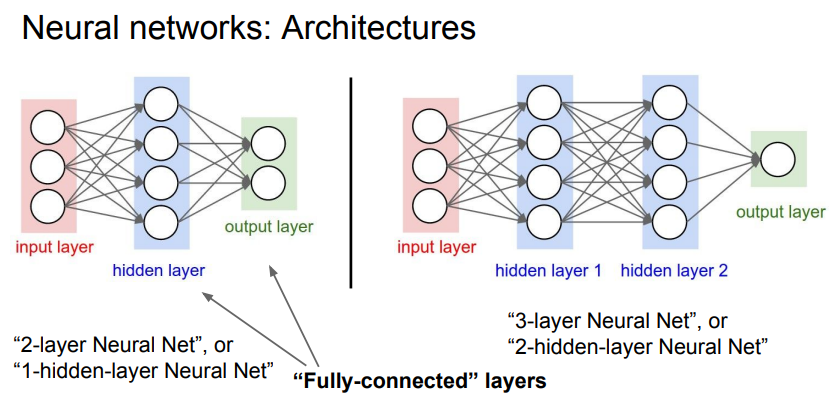
신경망의 대략적 구조에 대해 설명했는데, 각 hidden layer, output layer를 거칠 때, FC 구조를 가져야 한다고 합니다.
self.fc_layer = nn.Sequential(
nn.Linear(64 * 3 * 3, 100),
nn.ReLU(),
nn.Linear(100, 10) 코드로 나타내면 이렇게 표현할 수 있다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
