
오늘 포스팅은 Lecture 5
CNN(Convolution Neural Networks)
에 대한 내용입니다.
앞부분에 신경망의 역사에 대해 나오는데,
- 1957년 퍼셉트론, Backpropagation 불가.
- 아다린, 마다린(위에 퍼셉트론 겹겹이 쌓은 것, 동일하게 Backpropagation 불가)
- 루멀하트 논문(역전파가 나오긴 했는데, 문제 많아서 이후 암흑기)
- 2006년경, 역전파 제대로 동작하는 연구 시작
- 딥러닝 연구 시작
- 딥러닝 폭발적 발전(2010년대 초반)
그리고 CNN연구도 간략하게 설명했는데, 이런게 있다 정도만 얘기해서 넘어가겠다 (다음에 매우 자세하게 얘기한다)
간단히 이렇게 정리하고 넘어가도록 하겠습니다.
FC(Fully Connected Layer)
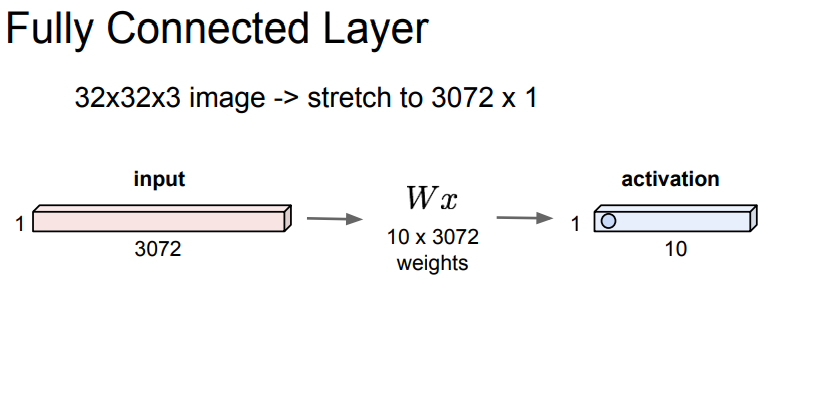
완전 연결 계층은 단순하게 3차원 배열로 어떤 input값이 들어오면, 1차원 배열 형태로 변환하는 것을 뜻합니다.
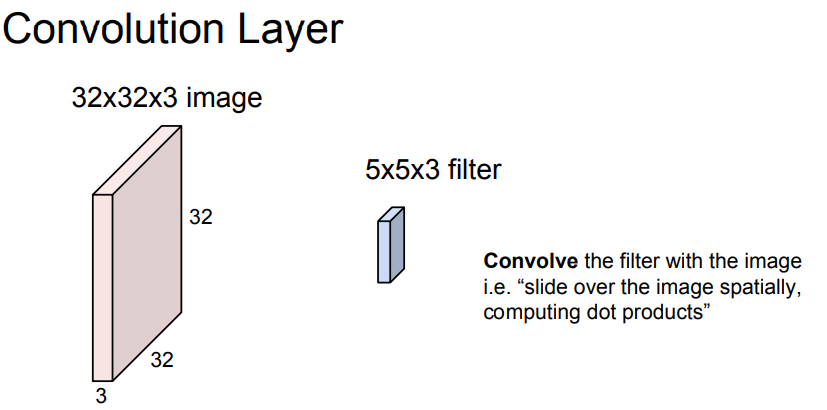
다음은 Convolution 계층에 대한 이야기 입니다.
그림은 거창한데, FC와는 다르게, 3차원 배열을 유지하되, 중간에 3차원 배열의 필터를 껴 넣어서 3차원 구조를 유지합니다.
그리고 이 계층에서 보통 activation function(저번 강의에서 간략하게 설명했던 것)을 중간중간 껴 넣는데
self.layer = nn.Sequential(
nn.Conv2d(in_channels = 1, out_channels = 16, kernel_size = 5),
nn.ReLU(), #
nn.Conv2d(in_channels = 16, out_channels = 32, kernel_size = 5),
nn.ReLU(), #
nn.MaxPool2d(kernel_size = 2, stride = 2),
nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 5),
nn.ReLU(), #
nn.MaxPool2d(kernel_size = 2, stride = 2)
)코드로 표현하면 이렇게 나타나게 됩니다.
물론 중간중간 활성화 함수는 다 통일할 필요는 없다.
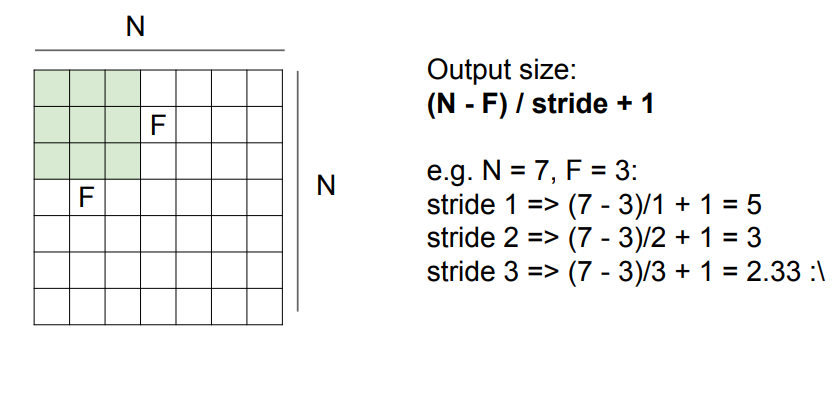
그리고 kernel_size와 stride값에 대해서 설명을 했는데, 위 예시는 input이 7 x 7인 사이즈를 3 x 3인 필터를 거치는 예시를 들었습니다.
kernel_size에 따라서 stride값도 잘 생각을 해줘야합니다. 위에 수식은 stride값이 1, 2까지는 데이터 손실이 일어나지 않는데, 3이면 2.33과 같이 데이터 손실이 일어나는 것을 잘 설명해줍니다.
도장(kernel_size)을 종이(input_size)에 쾅 찍는데, 이걸 어떻게 맞추느냐에 따라 데이터 손실 이 일어나는지, 일어나지 않는지 라는 말과 같다.
nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2) 코드로 나타내면 이렇게 된다.(프레임 워크는 Pytorch)
데이터 손실에 대해서 설명을 했는데, 이걸 방지하기 위해서 zero padding 과정을 거치게 됩니다.
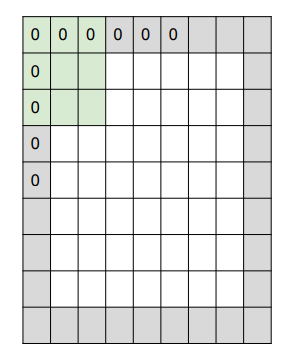
이렇게 끝 부분에 0을 끼워넣는 것과 같다.
Pooling Layer(풀링)
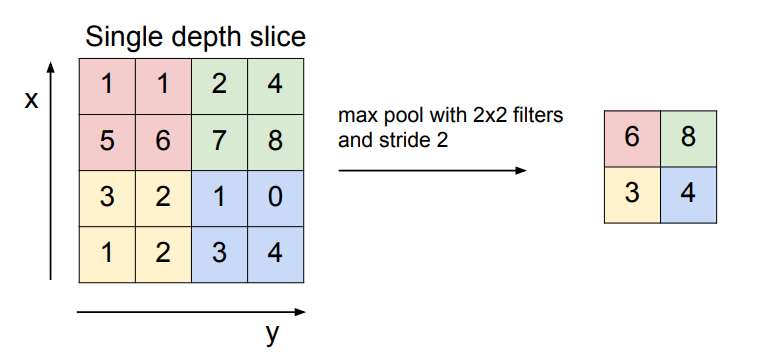
풀링 계층에 대한 이야기도 나왔습니다.
위 그림은 Max Pooling에 대한 내용인데,
풀링 계층 사용 이유는 다음과 같습니다.
1. Down sampling(더 작고, 관리하기 편하게)
2. 즉각적 활성화를 위해서
또한 대표적으로
Max Pooling(최댓값을 뽑아내는 것)
AVG Pooling(평균값 뽑아내는 것)
이렇게 두가지를 보통 많이 사용합니다.
풀링 계층에서는 '다운 샘플링'을 위해서 zero padding을 사용하지 않는다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
