[RX-EEND 리뷰] Auxiliary Loss of Transformer with Residual connection For End-to-end Speaker Diarization
2
EEND
목록 보기
10/11
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
ICASSP 2022 에 올라온 논문입니다. (Paper)
글쓴이의 첫 논문이다😋
Citation
@misc{yu2021auxiliary,
title={Auxiliary Loss of Transformer with Residual Connection for End-to-End Speaker Diarization},
author={Yechan Yu and Dongkeon Park and Hong Kook Kim},
year={2021},
eprint={2110.07116},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Introduction
Background
- SA-EEND 이전 포스팅 내용 참고
Previous Limitation
- SA-EEND의 Layer 개수에 따른 성능 저하 현상
- 생각보다 많지 않은 Layer 수에서 성능 저하가 발생하는 현상 발견
- Motivation
- Object Detection 분야의 DETR과 Efficient-DETR은 Transformer Decoder의 각 레이어 출력에 대한 Auxiliary Loss를 사용하며, 이것이 Transformer 가 동일한 일을 하도록 감독관의 역할을 한다고 설명한다.
- 위 DETR은 bipartite matching loss로 label target이 stable 하지 않은 Loss 를 사용한다.
- 우리는 SA-EEND 또한 Permutation Invariant Training (PIT) Loss와 같이 Label이 불안정한 상태로
Auxiliary Loss가 Transformer 가 동일한 일을 하도록 도와주는 역할을 하지 않을까? 라고 생각했다.
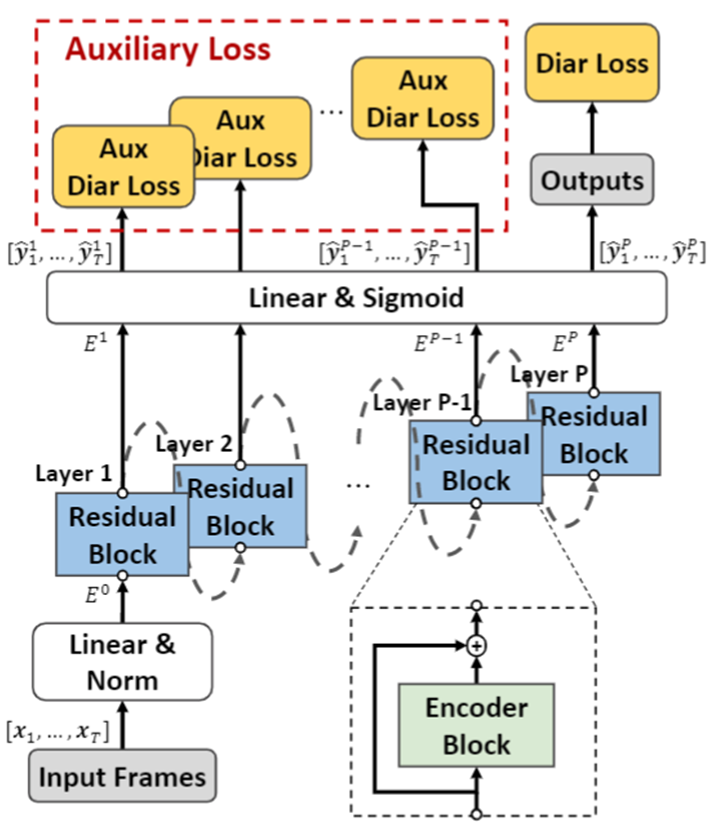
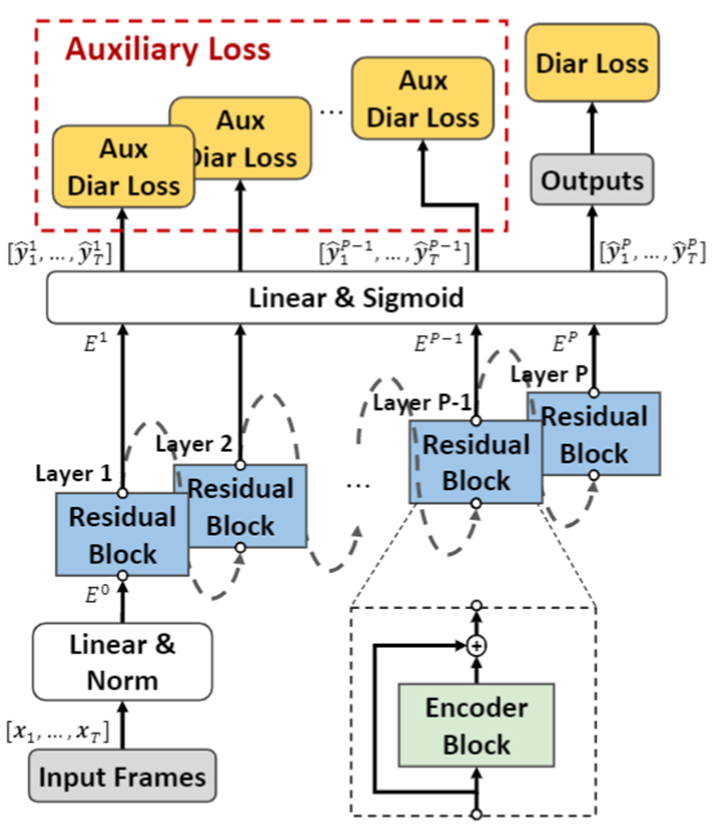
Main Proposal
- Auxiliary Loss for Diarization
- Additional Residual Connection in Encoder Block for generalization
Proposed Method
Intro
- 전반적인 구조
- 아래 2가지 부분을 제외하고는 RX-EEND는 SA-EEND와 동일하다.
- 1) Auxiliary Loss
- 모든 Transformer의 출력을 동일한 Linear 를 사용하여 추가적인 Diarization Loss 사용
- 2) Residual Connection 추가
- Transformer 의 입출력 간에 Residual Connection 추가
Architecture
- 0) Stacked-Frame Sub-Sampling:
- 50초 기준 raw Audio
- 0.1) STFT and Log-mel:
- STFT: Window size: 25ms, Hop size: 10ms
- log-mel: 23 dim
- 0.2) Stacked-Frame:
- Context Size(CS): 15
- 0.3) Sub-Sampling:
- Sub-Sampling Factor:
10
- 1) Encoder Layer(Linear):
- SA-EEND와 동일
- 2) Encoder Blocks(Transformer):
- 기존 SA-EEND의 Encoder와 거의 동일
- 추가적으로 이전 Encoder 입력과 출력에 대한 Residual Connection 추가
- 3) Diarization Loss
- 기존 PIT Loss 와 동일
- 4) Auxiliary Loss
- 2가지 종류의 Auxiliary Loss 실험 진행
- 4.1) Share Label
- 마지막 출력 layer에 대한 Label Permutation를 나머지에 모두 공유(Share)하여 사용하는 방법- 4.2) individual Label loss
- 각 레이어 출력 별로 다른 permutation 형태를 허용하는 것을 의미한다.
- 이는 한 입력의 화자 2명 A, B가 마지막 레이어에서 각각A->1-slot, B->2-slot에 매칭 되었다고 하자. 하지만 첫번째 레이어 출력은A->2-slot, B->1-slot에 대응 될 수 있는 것을 의미한다.- 최종적으로 individual Label loss를 사용했다.
- 5) Total Loss
- Auxiliary의 Loss 비율을 조절하는 것도 가능했지만, 그렇게 큰 차이를 보지 못했다.
- 논문에 기재된 실험 결과는 =1 기준이다.
Experiments Result
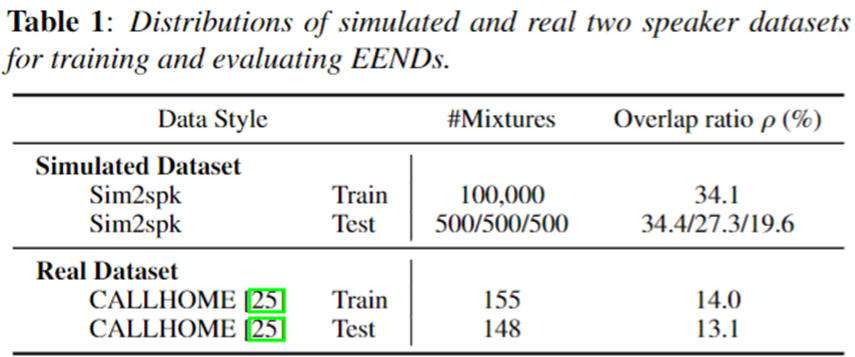
Dataset
- 데이터 셋은 기존 SA-EEND와 동일하게 진행했다.
Training Strategy
- SA-EEND와 동일
- 1) Training
- Training Sim2spk dataset 100 Epoch.
- Norm Scheduler: 100k
- 2) Adaptation
- 100 epoch, lr: 1e-5
- 3) Model Weight Average
- last 10 epoch weight mean (After Training / Adaptation)
Experiment Results
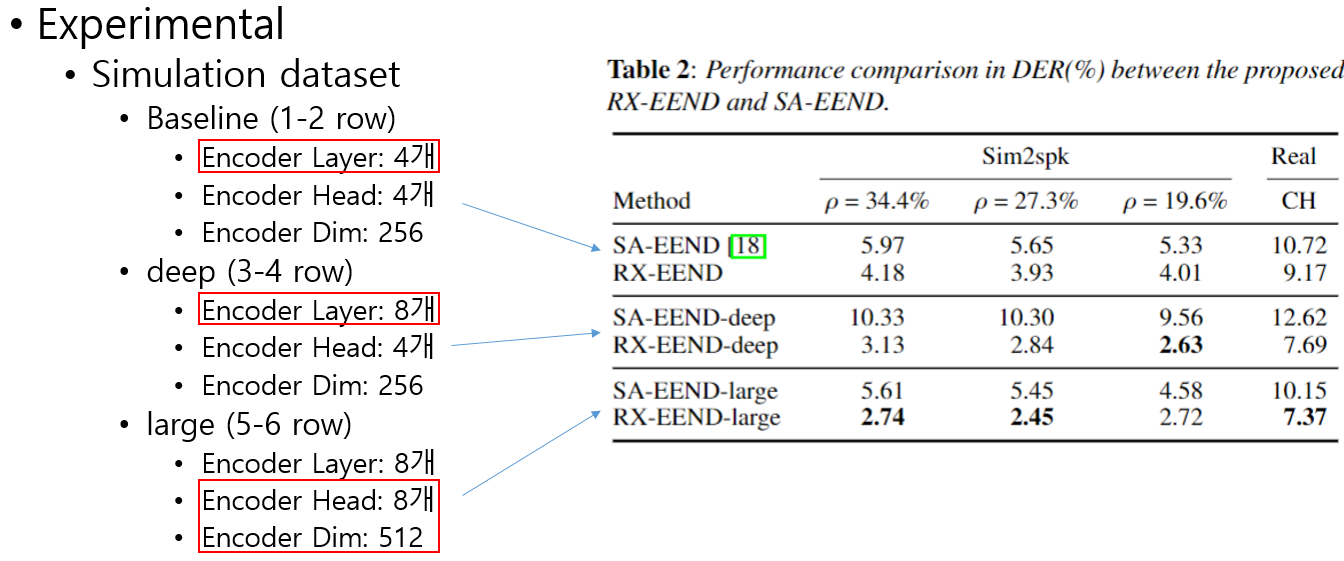
Sim2spk와CALLHOMEDataset 에 대한 실험 결과이다.- 모델 크기는 아래와 같이 3가지 종류를 사용했다.
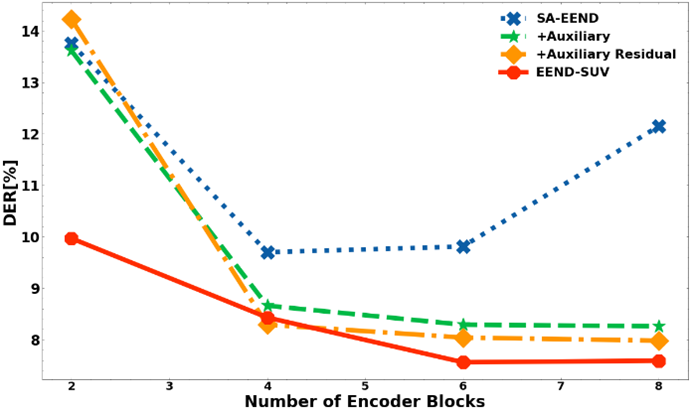
- SA-EEND는 모델 깊이가 깊어짐에 따라 급격한 성능 하락을 보여준다.
- 반면 RX-EEND 기존 SA-EEND와 같은 layer 개수에 대해서도 보다 나은 성능을 보일뿐 아니라, 깊은 레이어 개수에서도 좋은 성능을 보인다.
- 모델 크기를 키웠을때도 꾸준한 성능 향상을 보인다.
- 학습시간
- Baseline은 V100 Single-GPU로 2일 정도 걸린다.
- large 모델 같은 경우 V100 Single-GPU로 8일정도 걸렸던거 같다.
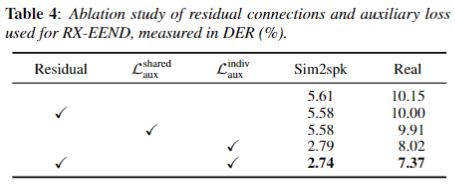
Ablation Study
- Residual Connection 만 추가한 경우 거의 성능 향상을 보이지 못한다. (row 1-2)
- shared Aux Loss와 indiv Aux Loss를 보면, shared aux는 거의 성능향상을 보이지 않고, indiv Aux Loss가 굉장한 성능 향상을 보이는 것을 볼 수 있다. (row 1,3-4)
- indiv Aux Loss와 Residual Connection를 같이 사용했을때 Real(CALLHOME) 데이터에 대한 성능이 상승하는 것을 볼 수 있다. 우리는 이를 일반화와 residual connection의 앙상블 효과라고 해석했다.
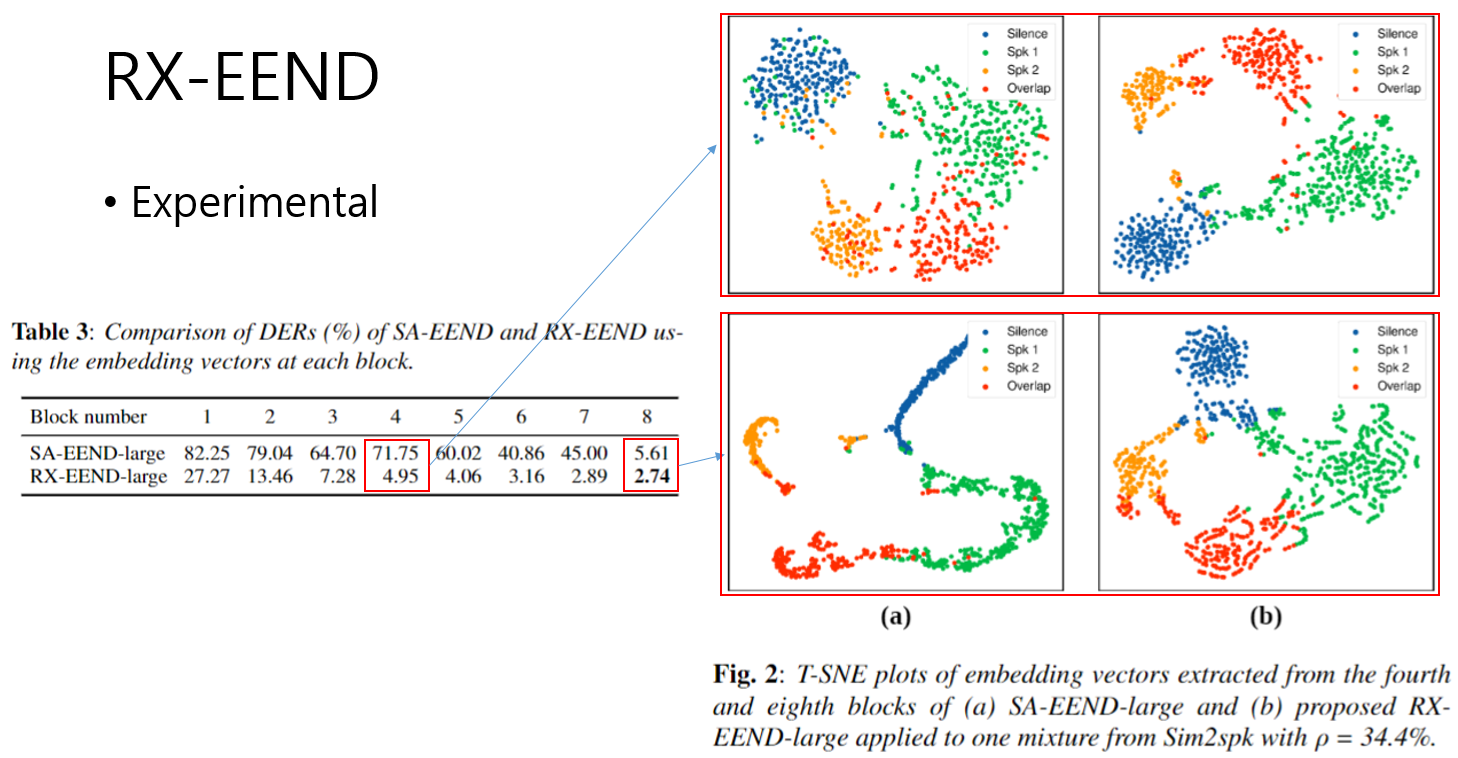
Visualization: PCA Embedding
- 레이어별 PCA 결과는 다음과 같다.
- 사실 Table 3은 SA-EEND 마지막 이전 레이어들에 대해서 같은 Local Attractor로 학습이 진행 되지 않아서 각 계층별 Diarization DER를 정확하게 비교하기는 어렵다.
- 하지만 PCA 결과를 보았을때, 같은 layer에서의 PCA 결과를 비교해 보았을때, RX-EEND가 보다 분명하게 분리가 되고 있는 것을 볼 수 있다.
- 또한 마지막 레이어 결과를 보았을때, 기존 SA-EEND는 overfit 되는 경향성이 보이지만 RX-EEND는 일반화가 잘 된 Embedding Representation을 보여준다고 생각된다.
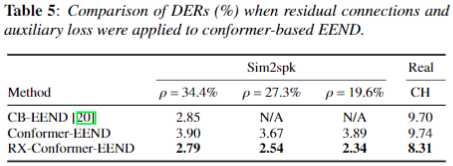
Conformer with RX-EEND
- CB-EEND에서 사용한 3가지 method (SpecAugment, Convolutinal Sub-Sampling, Conformer)들 중 Conformer에 대한 성능 비교를 진행했다.
- 시간상 Conformer 실험만 진행했다.
- 모델 크기
- SA-EEND의 Baseline 과 동일한 크기를 사용하되, FFN의 interal unit를 256으로 expansion 하지 않고 유지하고 사용했다.(CB-EEND와 동일, Transformer는 1024로 expansion 함)
- SA-EEND에 Conformer만 적용한 결과는 Conformer-EEND로 Baseline 보다 좋은 성능을 보인다. (row 2)
- 우리의 Proposal Method인 RX를 Conformer-EEND에 적용했을때도 효과적으로 성능 향상을 보인다.
Conclusion
- Auxiliary Loss가 각 Transformer Layer를 감독함으로써 높은 성능 향상을 이끌어 냈다.
- 하지만 Auxiliary Loss가 정확히 왜 좋아지는지에 대해서는 해석하지 못했다.
- 각 Transformer Layer에 출력이 레이어 별로 각기 다른 Speaker Attractor에 대응하도록 학습하는 것이 효과적인 점이 우리가 찾아낸 핵심인 것 같다.
- 각 Transformer Layer가 Auxiliary Loss로 제 역할을 하게 되면서 Residual Connection 이 보다 일반화와 앙상블 효과를 볼 수 있었던거 같다.
- 아직 연구가 더 필요해 보인다.

Audio & Speech AI Researcher 입니다! Speaker Diarization & Speaker Verification 연구 경험을 가지고 있고, 전반적인 Speech Representation 에 대해서 관심을 가지고 있습니다!