
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
publish 한 곳은 없고, eprint arXiv에 올라온 논문입니다.
EEND와 관련하여 Post-Processing 접근 방식을 다루어서 간단하게 정리하겠습니다.
(Paper)
Citation
@misc{horiguchi2020endtoend,
title={End-to-End Speaker Diarization as Post-Processing},
author={Shota Horiguchi and Paola Garcia and Yusuke Fujita and Shinji Watanabe and Kenji Nagamatsu},
year={2020},
eprint={2012.10055},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Introduction
Clustering-based method
- Clustering은 End-to-end 학습이 아닌, VAD(Voice Activity Detection), Embedding Extract, Clustering 등의 Multi-Stage 과정을 가집니다.
- 1) VAD(Voice Activity Detection): 유성음가 무성음을 분류하여, speech activity region 를 찾습니다.
- 2) Embedding Extract: VAD로 구해진 음성 구간과 사전에 학습된 화자 인식 모델을 이용하여 화자의 Embedding 정보를 추출합니다.
- 3) Clustering: 추출된 Embedding을 기반으로 clustering을 적용합니다.
- ex) AHC(Agglomerative Hierarchical Clustering), SC(Spectral-Clustering)
- Embedding에는 한 화자만이 존재한다고 가정한다. 즉 speech overlap을 다루지 못한다.
- 위 가정으로 speaker diarization은 set partitioning problem으로 정의한다. 즉, 하나의 embedding은 하나의 화자 set에 대응된다.
- 이러한 단점에도 불구하고, DIHARD II에 대해서 여전히 강력한 baseline 이다.
EEND-based method
- 대표적인 Method
- SA-EEND
- 이들은 speaker 수가 4명이상인 경우 좋지 않은 성능을 보인다.
- 많은 수의 speaker mixture 를 얻는 것은 희귀하다. 즉 training 데이터가 부족하다.
- PIT loss
- 여전히 많은 수의 mixture에 대해서는 계산적 어려움을 가지고 있다.
Proposal Method
- 많은 화자 수 상황에서 보다 좋은 성능을 보이는 Clustering-Based method(x-vector clustering method)와 Overlap Speech를 다룰 수 있는 EEND method 두 가지 방법을 효과적으로 함께 사용하는 방법을 제안한다.
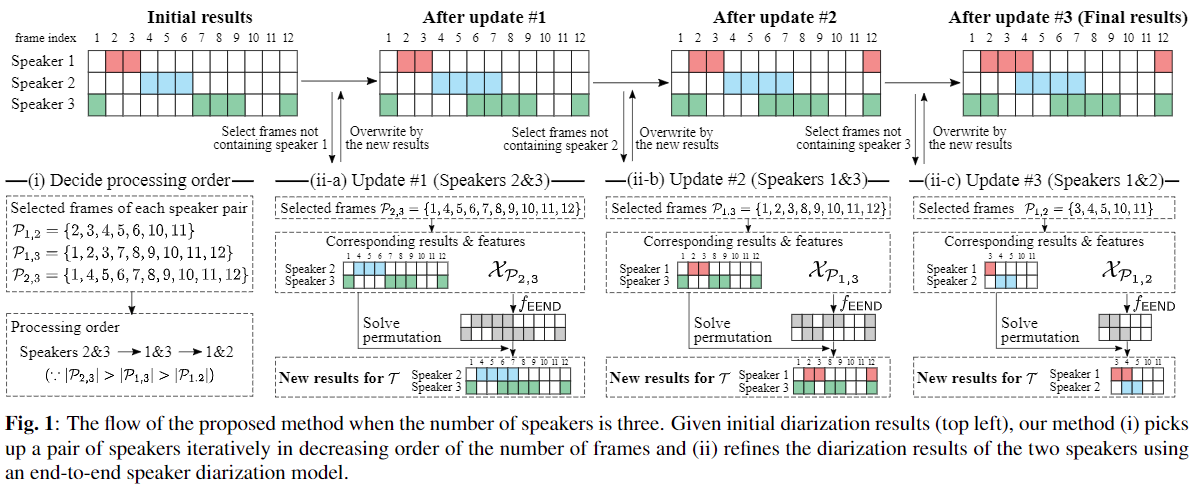
- 본 Post-Processing(후처리) 알고리즘은 다음과 같다.
- 1) x-vector clustering method를 이용하여 초기 speaker diarization 결과를 얻는다.
- 2) 모든 speaker중 2명을 선택하는 모든 조합에 대해 아래를 반복한다.
- i) 위에서 선택한 2명 화자 + silence 구간을 선택한다.
- ii) EEND model를 이용하여 overlap 구간을 찾아내고 update합니다.
Related Work
Clustering-based Method
- 기본적으로, x-vector clustering을 사용한다.
- 추가로 Probabilistic Linear Discriminate Analysis (PLDA) rescoring 적용
- 추가로 Variational Bayes(VB) Hidden Markov model(HMM) resegmentation 적용
- Overlap processing
- Clustering-based Method 는 overlap 를 처리하지 못하므로 이를 보안하기 위한 추가적인 작업 존재
- Heuristics
- 1) speech overlap 이 존재하는 구간을 탐지
- 2) 위에서 찾은 구간에서 대해서 2번째로 큰 값을 가지는 화자까지 추가로 포함시킨다.
- Clustering-based
- 1) Region Proposal Network(RPN)를 이용하여 overlap segment를 찾아낸다.
- 2) 각 overlap segment 에서 추출된 embedding 들에 대해서 clustering를 따로 진행함
- 하지만, 여전히 EEND method에 비해서 성능이 좋지 않다.
End-to-end diarization for overlapping speech
- Encoder-Decoder-based Attractor calculation modules (EDA)
- Speaker-Conditional EEND (SC-EEND)
- RSAN
- 각 speaker들에 대한 time-frequency 에 대한 residual mask를 구해냅니다.
- EEND와 RSAN은 acoustic feature 만을 입력으로 받습니다.
Proposed Method
Algorithm
- 1) x-vector Clustering Method로 사전에 결과를 계산한다.
- 2) x-vector Clustering 에 화자가 K명 있다고 할때, K명 중 임의의 2명의 화자를 선택한다.
- 3) 선택된 2명 화자 와 무음인 Frame 만을 선택하여 EEND의 입력으로 사용한다.
- 4) 이때, 2명 화자 출력에 대해서 변경된 부분을 수정한다. (Overlap 또는 VAD 구간)
- 5) 위를 모든 화자 조합에 대해서 반복한다.
Processing order determination
- Algorithm의 Step 2 에서
서로 다른 두 화자를 선택하는 순서는 성능에 큰 영향을 미친다.- 여기에서는 두 화자에 대한 모든 경우의 수를 생성한 뒤에,
이들 중 가장 많은 Frame 이 선택된, 즉 내림차순으로 선택했다.
Iterative update of diarization results
- EEND의 출력을 업데이트 하는데 있어서
출력 화자 Permutation Align및EEND 출력의 신뢰성에 판단 알고리즘은 다음과 같다.
출력 화자 Permutation Align 알고리즘
- 여기서 이에 대한 출력은 2명에 대한 출력인 각각 , 라고 하자.
- EEND 각 Frame 출력이 0.5 이상 경우 speech activity 영역으로 간주한다.
- 여기서 입력으로 준 두 화자 가 EEND 화자 출력 중 어디에 대응되는지 알 수 없다. 이를 위해
본래(x-vector 결과) frame 과 가장 많은 overlap 영역을 가지는 번호로 휴리스틱하게 매핑하는 방법을 사용했다.

EEND 출력의 신뢰 및 Update
- Update 와 같은 경우 아래와 같은 룰을 따른다.
- 첫번째 식은
새롭게 예측한 i의 영역과 기존 영역간의 교집합 영역이 a=0.5, 즉50%보다는 큰 경우에 업데이트를 진행한다는 뜻이다.- update가 가능하다면 전체 화자 수에 따라 2가지 경우로 나뉜다.
- 인 경우 화자가 2명인 경우로 입력으로 넣은 부분을 그대로 업데이트 하면 된다.
- 인 경우에는 좀다르게 진행한다. 인 경우처럼 모두 업데이트하는 경우 불순물로 인해서 성능 저하가 발생한다.(정확한 이유 설명안함) 때문에 마지막 식처럼
두 출력의 overlap 에 대해서만 업데이트를 진행한다.

전반적인 알고리즘 도약도 및 예시는 다음과 같다.
Experiment
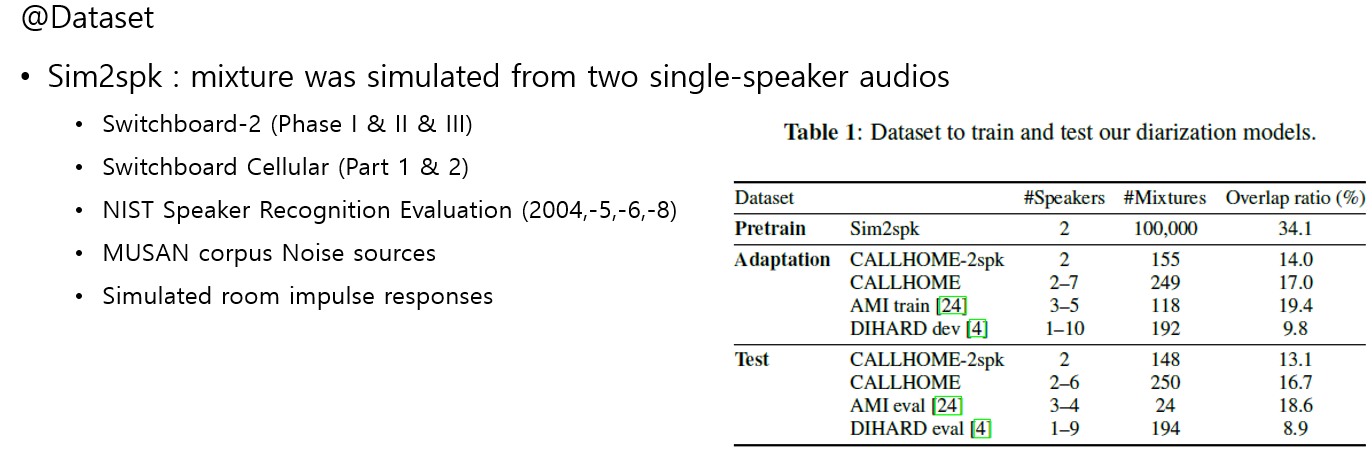
Dataset
- 데이터 셋은 아래와 같다.
- Training 데이터 셋은 SA-EEND에서 사용했던 beta=2와 동일하다.
- Adaptation은 추가적으로 CALLHOME 이외에도 AMI과 DIHARD 데이터 셋을 사용했다. 또한 CALLHOME DB에 대해서 기존과 다르게 2-spk 말고 화자 수 제약이 없는 데이터도 추가 실험을 진행했다.
Preliminary evaluation of the training using frame selection
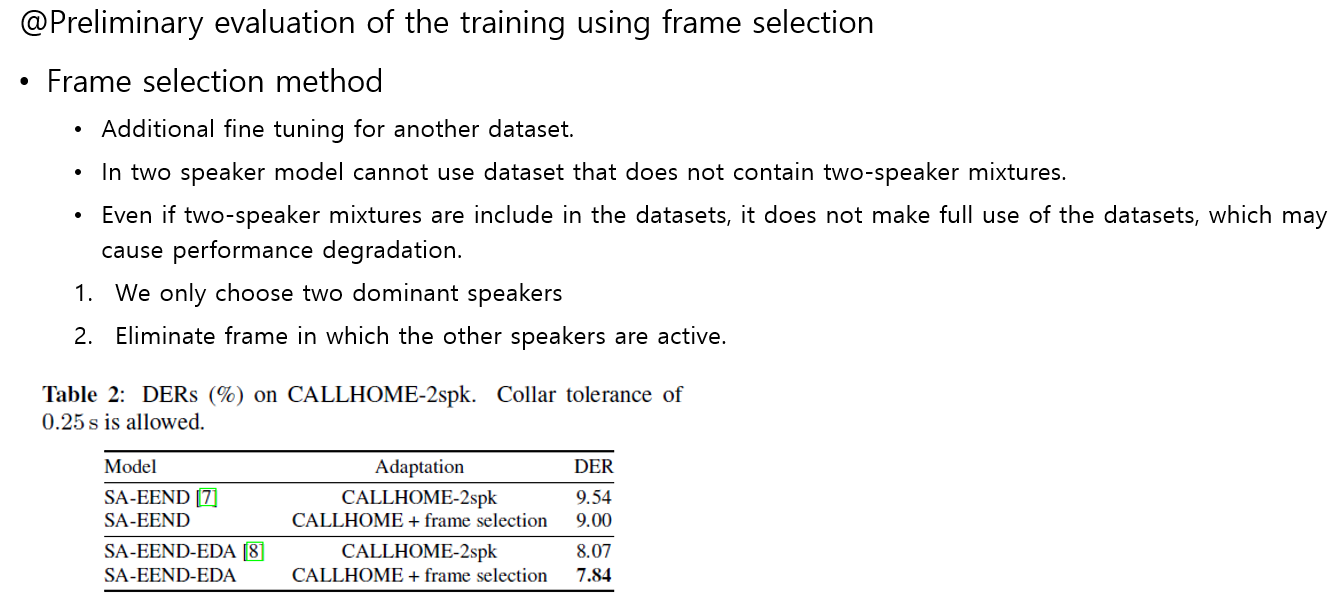
- Frame selection method
- 데이터 사용에 있어서 새로운 방법을 추가했다.
- 이전 학습에서는 데이터셋에 2명의 화자만이 존재해야만 사용할 수 있었다.
- 여기서 2-spk 데이터를 모두 사용한다고 해서 항상 좋은 것이 아니다. 오히려 잔여물들이 성능 저하를 만들수 있다.
- 또한 3명의 화자 이상 존재하는 데이터 셋에 대해서도 Frame selection 방법을 적용하여 데이터 증강을 하였다고 한다.
- 이 결과 CALLHOME 데이터에 대해서 더 좋은 성능을 가지는 것을 볼 수 있다.
Result
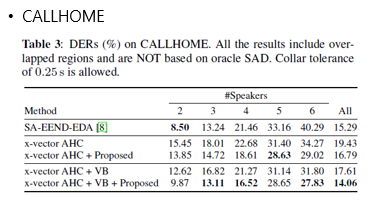
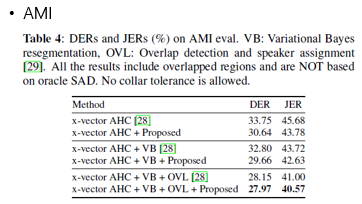
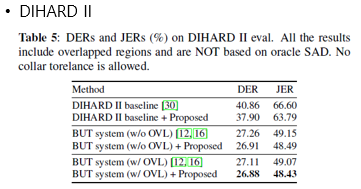
- CALLHOME, AMI, DIHARD II 데이터 셋에 대한 결과는 아래와 같다.

Audio & Speech AI Researcher 입니다.