[EEND-VC 리뷰] Integrating end-to-end neural and clustering-based diarization: Getting the best of both world
EEND
목록 보기
8/10
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
[1] ICASSP 2021, [2] Interspeech 2021 에 올라온 논문입니다. (Paper1, Paper2, github)
Citation
[1]
@misc{kinoshita2021integrating,
title={Integrating end-to-end neural and clustering-based diarization: Getting the best of both worlds},
author={Keisuke Kinoshita and Marc Delcroix and Naohiro Tawara},
year={2021},
eprint={2010.13366},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
[2]
@misc{kinoshita2021advances,
title={Advances in integration of end-to-end neural and clustering-based diarization for real conversational speech},
author={Keisuke Kinoshita and Marc Delcroix and Naohiro Tawara},
year={2021},
eprint={2105.09040},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Introduction
Background
- SA-EEND 포스팅 참고
Limitation
inter-block label permutation problem
- Long recording, Online method의 경우 Chunk 단위로 inference를 할 필요성이 제기된다.
- long recording 에 대해서는 메모리 부족 및 시간 복잡도 문제가 존재한다.
- 사전의 inference 결과와 이후 inference 결과의 label의 permutation 매칭을 찾아야하는 문제가 발생하며 이를
inter-block label permutation problem이라고 한다.- Fixed number of speaker
- SA-EEND는 입력 내
고정된 화자 수만 찾을 수 있다화자 수 증가에 따른 성능 저하존재한다
Main Proposal
Multi-task learningwith speaker identification
- 화자 분류와
화자 인식(speaker identification)을 동시에 학습을 진행한다.- 입력 내 화자를 대표하는 speaker embedding을 생성하여 화자 인식 학습을 진행한다.
Speaker Embedding Clustering
- 각
inter-block으로 부터 대표speaker embedding을 생성하고, 이 embedding으로 clustering 을 적용해 inter-block label permutation problem을 해결함Constraint Clustering
- 이전 COP-Kmeans 에서 motivated 됨
- 각 inter-block내 speaker가 다른 경우 같은 화자로 clustering 되지 않도록 제약을 주는 방법을 제안했다. 즉,
EEND가 다르다고 한 speaker에 대해서는 같은 speaker로 clustering 되지 않도록 제약을 주는 것이다.
Proposed Method
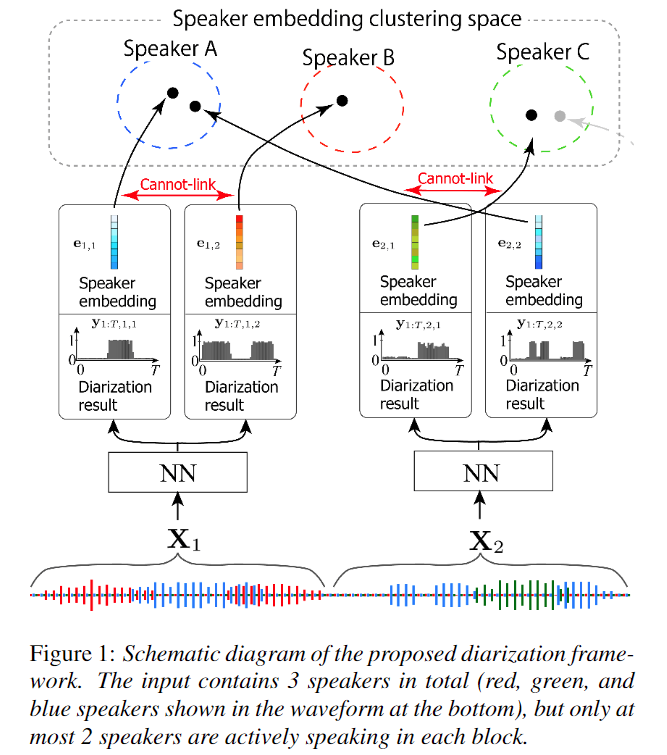
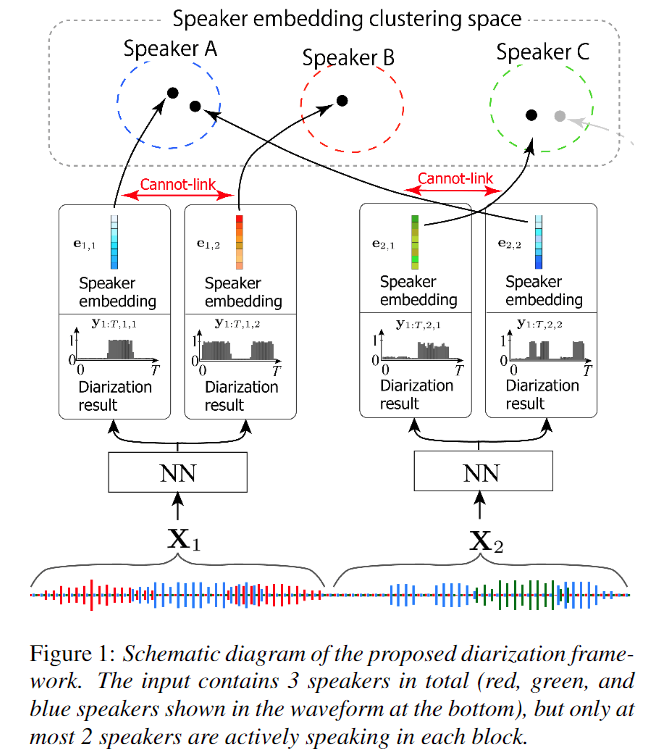
EEND-vector-clustering
Intro
- 1) SA-EEND을 동일하게 사용
- 2) 추가적으로 화자 인식과 speaker embedding 을 생성하기 위한 loss 추가
- 3) Constraint Clustering 을 통한 inter-block label permutation problem 해결
Variable
- Number of Encoder block:
P- Number of header:
H- Encoder hidden dimension:
D- Maximum number of speakers in each block:
S- Speaker embedding dimension:
C
Architecture
- 1) SA-EEND block
- 이전 SA-EEND 구조를 동일하게 사용했다.
- Input: 23 log-mel, stacked sub-sampling
- Number of header:
H(4)- hidden dimension:
D(256)- (1) Librispeech dataset
- Number of Encoder block
P(4)- maximum number of speaker in each block:
S(2)- (2) CALLHOME dataset
- Number of Encoder block
P(6)- maximum number of speaker in each block:
S(3)- Variable
- : Frame index, : chunk index, : speaker index
- : i번째 Chunk 입력 값
- 2) Speaker embedding estimation
- 본격적인 proposal 부분이다.
- 2.1) Linear:
T x D -> T x C
- SA-EEND의 output인 diarization task의 embedding를, speaker embedding인 speaker identification 을 위한 embedding space로 변경한다.- 2.2) generate speaker embedding
Clustering Method
- Constrained AHC(Agglomerative Hierarchical Clustering)
- Speaker Embedding 간의 distance matrix(Cosine Similarity)를 이용하여 score matrix를 생성한다.
- 이때, EEND와 같은 block 내의 score matrix 값인 에 대해서는 같은 speaker 로 되지 않도록 높은 값 값으로 설정한다.(예시에서는 이해를 돕기위해 inf로 설정)
- Constrainted SC(Spectral Clustering)
- SC는 score matrix 값이 0인 경우 연결되지 않은 것으로 간주하며, 으로 설정한다.

Silence speaker detection
- 한 block 내의 보다 작은 화자 수가 존재하는 경우에 Silence Speaker 를 판단하는 방법이 필요하다.
- 본 논문에서는 heuristic 하게 전체 시간 중 % 이상의 speaker activity region이 존재하지 않는 경우 silence speaker로 간주하였다.
- 본 논문에서 값은
0.05를 사용하였다.
Training loss
- Total Loss
- 본 논문에서의 값은
0.01
- 1) Diarization loss ()
- 기존 SA-EEND Loss와 동일
- Variable
- : chunk index
- : frame index
- : block 내 permutation
- : ground truth
- : i번째 chunk, t번째 frame의 diarization 출력
- 2) Speaker Embedding loss
- Speaker Embedding 를 학습하기 위한 Loss
- 화자 인식 정보를 이용하기 위한 Multi-task Loss term
- Variable
- : i번째 chunk의, s번째 slot의 global speaker index
- : Diarization Loss에서 찾은 최적의 permutation
- : i번째 chunk의, s번째 slot의 speaker embedding
- : global speaker index 값 , : Training set 전체 화자 수
- : learnable speaker Embedding
- : Distance matrix의 learnable한 scaling, bias factor 값
Experiments Result
Dataset
- simulation dataset
- LibriSpeech dataset
- SWBD + SRE dataset
- real dataset
- CALLHOME dataset
Training Strategy
- batch Size: 64
- 1) Training set
- Chunk size: 15 sec
- learning rate: 1.0
- scheduler
- norm warm up: 25k
- optimizer
- adam
- epoch: 100
- 2) Average model parameters
- 마지막 10 epoch model parameter 값을 averaging 하여 사용
- 즉, 각 91~100 epoch에 checkpoint model parameter 들을 평균하여 하나의 model parameter 생성
- 3) Learned Speaker Embedding 재 생성
- Adaptation 이전에 Training speaker로 학습된 target speaker embedding을 변경할 필요성이 있다.
- CALLHOME trainging 데이터셋에 대해서 inference를 진행한다.
- 각 label에 대한 speaker embedding 출력 들을 모두 저장한다.
- CALLHOME i번째 speaker에 대한 모든 speaker embedding 들의 평균을 에 Update 한다.
- 4) Adaptation ( Dataset: CALLHOME dataset )
- 설명
- CALLHOME dataset 은 모델을 학습 시키기엔 적은 데이터 양이기 때문에, adaptation 과정을 이용한다.
- Chunk size: 30 sec
- learning rate: 1e-5
- optimizer
- adam
- epoch: 100
- 5) Average model parameters
- 4의 결과에 대해서 2와 동일하게 적용
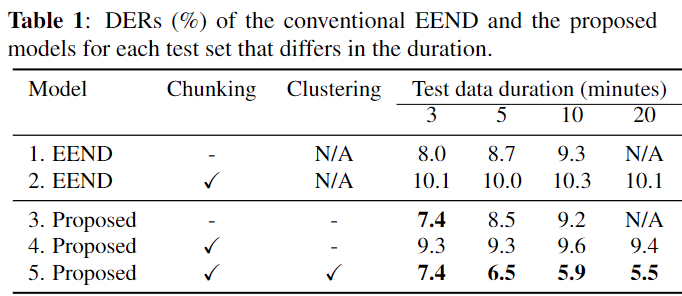
LibriSpeech Duration Experiment results
- LibriSpeech로 2명 화자의 대해서 생성된 simulation dataset 결과이다.
- LibriSpeech Dataset으로 학습 시켰을때, SA-EEND 보다 좋은 성능을 보이며, 긴 시간에 대해서도 좋은 결과를 보인다.
LibriSpeech t-SNE plot
- Speaker Embedding이 26명의 test set에 대해서도 괜찮은 분포를 가지고 있음을 나타낸다.

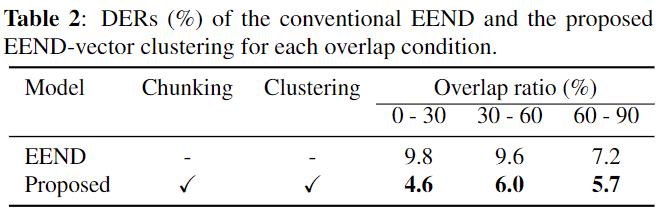
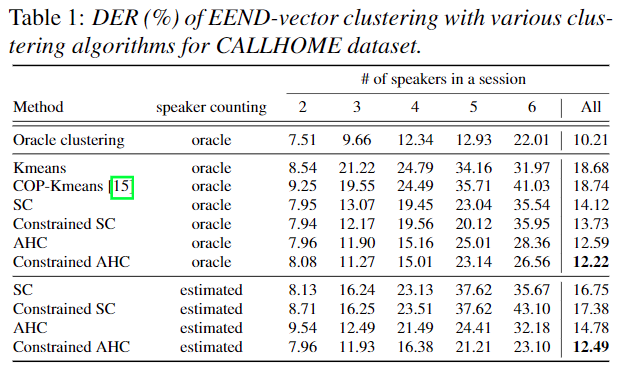
CALLHOME Clustering Method Experiment results
- Clustering Method 들 중 Constrained AHC가 가장 좋은 성능을 보임을 확인 할 수 있다.
- 확실히 Constrained 방법이 AHC에 좋은 영향을 미치는 것을 확인 할 수 있으며, 의외로 speaker counting 개수를 estimated로 사용할때 Constrained SC의 성능은 하락하는 것을 볼 수 있다.
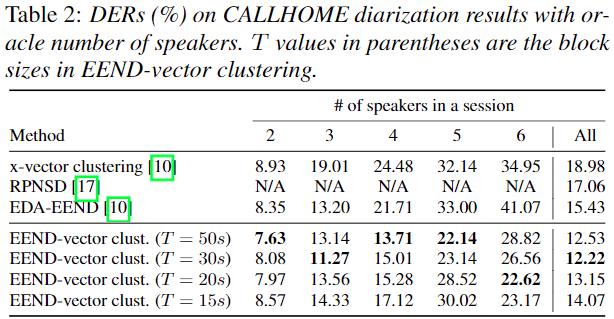
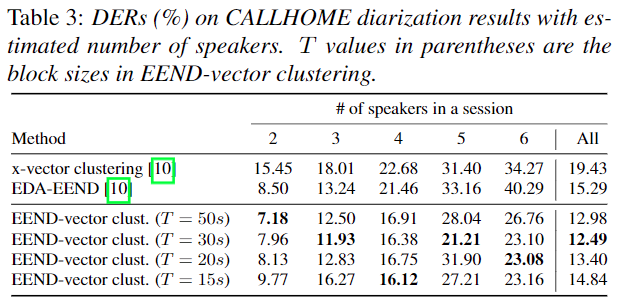
CALLHOME Comparison Other method and inter block length Experiment results
- inference Chunk 길이 Variation
- Chunk 길이가 짧은 경우
- EEND의 속도 향상
- Chunk 내 화자 수가 적을 확률이 높음
- Clustering의 부담이 늘어남
- 좋은 speaker embedding 만들어 내기 힘들어짐
- Chunk 길이가 긴 경우
- EEND의 속도 저하
- Chunk 내 화자 수가 많은 확률 올라감
- Clustering의 부담이 줄어듬
- 보다 좋은 speaker embedding을 만들기 유리해짐
- oracle & estimated number of speaker
- 거의 일관된 성능 결과를 보이며, 기존 EEND-EDA보다 좋은 성능을 보인다.
- 30초 일때 가장 좋은 성능을 보인다.
Conclusion
- Block(Chunk) 별 Speaker Embedding를 학습하고, 이를 이용한 Clustering 으로
inter block label permutation problem을 효과적으로 해결했다.- Multi-task learning with speaker identification 을 통해서 global 화자 특징 정보를 함유한 보다 좋은 embedding를 생성할 수 있었다.
- EEND의 정보를 이용하여 효과적인 Constrainted Clustering 방법을 제안했다.
- CALLHOME Dataset에 대해서 SOTA 성능을 보였다.
- Limitation
- 아직 Adaptation 시에 별도의 speaker embedding initialization 과정이 필요하다.
- 가존 SA-EEND의 Fixed-weight local speaker Attractor을 그대로 사용해 EEND-EDA와 같이 Unknown Number of speaker와 보다 나은 local speaker attractor를 추출하지 못한 부분이 아쉽다고 볼 수 있다.
- Conformer 사용시 성능 향상이 궁금하기도 하다.
- 현재 speaker Embedding 생성이 Heuristic하고, Linear Block 하나로 충분한지?에 대한 의문이 있고 이부분에 대해서 연구 진행중에 있다.

Audio & Speech AI Researcher 입니다.