[TDCN-SA 리뷰] End-to-End Diarization for Variable Number of Speakers with Local-Global Networks and Discriminative Speaker Embeddings
EEND
목록 보기
6/10
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
ICASSP 2021 논문입니다. (Paper)
Citation
@misc{maiti2021endtoend,
title={End-to-End Diarization for Variable Number of Speakers with Local-Global Networks and Discriminative Speaker Embeddings},
author={Soumi Maiti and Hakan Erdogan and Kevin Wilson and Scott Wisdom and Shinji Watanabe and John R. Hershey},
year={2021},
eprint={2105.02096},
archivePrefix={arXiv},
primaryClass={cs.SD}
}Introduction
Background
- SA-EEND 이전 포스팅 참고!
SA-EEND Limitation
- 1) Can't handle local cues (e.g. at speaker changes)
- 기존 SA-EEND의 Transformer는 CNN, RNN같은 Inductive Bias가 존재하지 않기 때문에, 주변
지역 정보를 다루지 못한다.- 즉, transformer의 attention은
모든 Frame(Token)을 Full Attention한다.- 이 정보는,
speaker changes지점과발화의 연속성등을 모델이 다루지 못하는 단점을 가지고 있다.- 2) Degradation of Performance in more than three speaker
- SA-EEND는 3명 이상인 경우, x-vector 보다 성능이 좋지 않음. 여러 명의 경우 Relation information 을 잘 해석하지 못함
- 3) Global 화자 특성 정보 부재
- 화자의 Global 특성이 네트워크에 모델링 되지 않는다.
Main Proposal
- 1)
Time-dilated convolutional neural network (TDCN)for local features
- SA-EEND는 Encoder block 앞단에 간단하게 Linear block을 사용했다.
- 단 하나의 Linear block은 여러 명의 화자의 Global한 특성을 담는 local feature을 만들기에 어려움이 있었다.
- 저자는 Speech Separation(SS) Task에서 2020년 SOTA를 달성한
Conv-tasnet으로부터 영감을 받아 Linear 대신TDCN을 제안한다.- 2)
Auxiliary lossfor local TDCN module
- Encoder block 앞단에 사용하는 local TDCN 출력에 대해서 추가적인 Auxiliary loss를 도입한다.
- 단순히 Local TDCN에 출력에 최종 출력과 동일하게 Permutation-free loss 를 추가한다.
- 3)
Multi-task learningwith Speaker Identification
- 화자의 Global 특성을 네트워크에 모델링하기 위해서 화자 인식 task를 추가로 학습하는 Multi-task learning을 제안한다. (globally discriminable)
- 4)
Linear approximationof full-attention
- 더 깊은 Transformer encoder block 을 사용하기 위해서, 기존 Self-attention softMax의 Quadratic complexity 를 linear approximation 한 방법을 제안한다.
- 5)
Sequential model
- 개별적인 2개의 모델에 대해서 첫 번째 모델 출력을 두 번째 모델 입력에 함께 concat 하여 사용하는 방법이다.
- 6)
Many speaker condition(8 speaker)
- SA-EEND는 2명의 speaker 에 대해서 만 실험 되었다.
- 저자는 8명의 화자를 해석하는 새로운 모델 제안한다.
Proposed Method
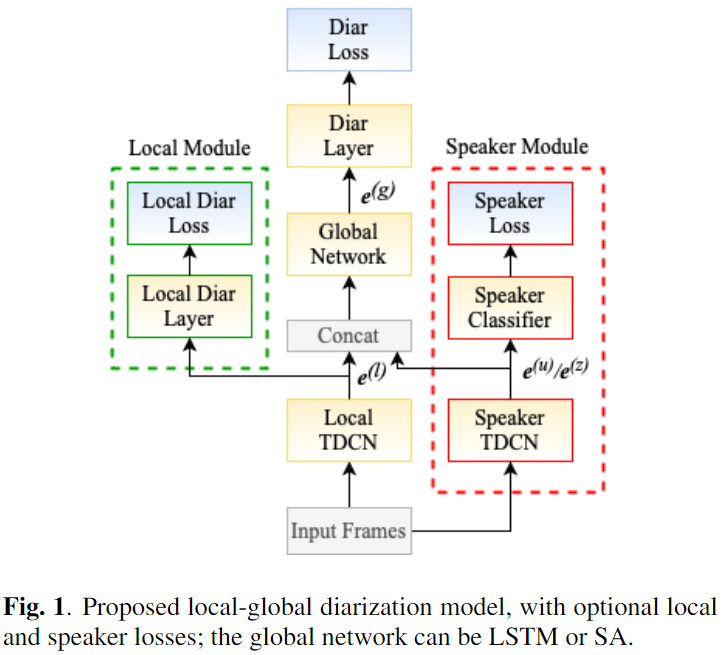
TDCN-SA
Intro
- 1) Local feature을 위한 앞단
Linear layer -> local TDCN변경- 2)
local TDCN의 학습을 증진하기 위한 Auxiliary loss 도입- 3) 화자 인식 multi-task을 위한 Speaker Module 추가
- 4) Transformer의 Self-attention을 linear approximation 방법 도입
- 5) Sequential model
Variable
T: number of frames (Time: 900~1200 (90~120sec))F: Audio feature dimension (1344)TDCN_D: hidden dimension of TDCN (512)S: Fixed number of speakergiD: hidden dimension of global input
- Without Sequential mode:
1024- With Sequential mode:
1032(1024 + 8)D: hidden dimension of Global Network (512)
Architecture
- 0) Input:
raw input -> T x F(1344)
- 0.1) STFT and Log-mel:
raw input -> 10T x 64
- window size: 40ms
- hop size: 10ms
- log-mel: 64 dim
- 0.2) Stacked-frame:
10T x 64 -> 10T x F(64 x 21)
- context length:
21samples (previous 10 samples, current 1 sample, next 10 samples)- 0.3) Sub-sampling:
10T x F -> T x F
- Step size:
10(hop size 10ms x10= 100ms, 10 sample per sec)
- 1) TDCN: Local Feature
- 1.1) Local TDCN:
T x F -> T x TDCN_D(512)
- 1.1.1) Bottleneck conv 1x1:T x F -> T x TDCN_D
- 1.1.2) TDCN:T x TDCN_D -> T x TDCN_D
- for 1:Repeat(
R: 4)
- for 1:M(
M: 8) (#Dilation layer)
- TemporalBlock
- 1) Conv 1x1
- 2) PReLU
- 3) Global Layer Norm
- 4) Depthwise Separable Conv (with dilation, non causal)
- Residual connections
- 1.2) Speaker TDCN:
T x F -> T x TDCN_D
- Same 1.1
- 2) Concat
- 2.1) local, Speaker TDCN concat:
[e^l, e^u] -> T x giD(1024)- 2.2) use sequential mode:
[T x giD, T x S] -> T x giD(1032 = 1024+8)
- 3) Global Network (SA-EEND encoder block)
T x giD -> T x D(512)
- 3.1) SA-EEND Encoder Block
P: Number of Encoder Block (10)D: Hidden dimension of Transformer (512)H: Number of Header (8)d_ff: point-wise FF internal unit (2048)- Multi-head attention
- 1) self-attention (original)
- SoftMax 를 이용한 Self-Attention 방식
- Time and memory Complexity O(N^2)
- Frame 길이가 긴 경우와 네트워크가 깊어짐에 따라 속도가 저하가 심하다.
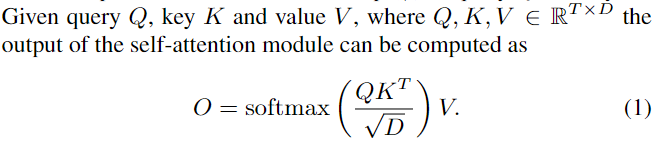
- 2)
Linear Approximationof full-attention (proposed)
- 기존 Self-attention을
Transformers are RNNs논문에서 제안한 linear approximation of full-attention 으로 변경하여 large model 실험을 진행하였다.- 여기서는 self-attention이 아니라 각 Q와 K에 대해서 kernel 함수를 이용하여 각각 full-attention을 진행한다.

- 4) Local Diarization layer:
T x TDCN_D -> T x S(8)
- 4.1) Linear:
T x TDCN_D -> T x S- 4.2) Sigmoid:
T x S -> T x S
- 5) Diarization layer:
T x D -> T x S(8)
- 5.1) Linear:
T x D -> T x S- 5.2) Sigmoid:
T x S -> T x S
- 4-5) Diarization loss
- SA-EEND의 permutation-free loss 와 동일
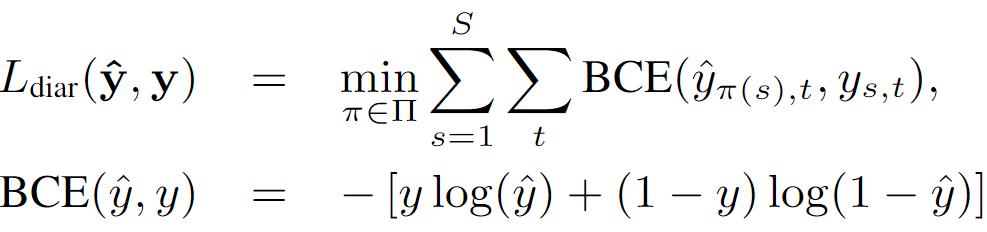
- 6) Speaker Module: (Choose
joint or individualmode)
- 6.1)
joint speaker embeddings():T x TDCN_D -> T x C
- 6.1.1) Linear:
T x TDCN_D -> T x C- 6.1.2) Sigmoid:
T x C -> T x C- 설명
C: Training set의 전체 Speaker 수- 각 Frame 에 대해서
1 x C의 0~1 사이 값의 vectoru_t를 생성한다.- 각 vector의 index는 Training set 화자의 ID을 나타낸다.
- :
0: Frame t에서 i번째 화자가 없는 경우- :
1: Frame t에서 i번째 화자가 있는 경우- Binary Cross Entropy 진행
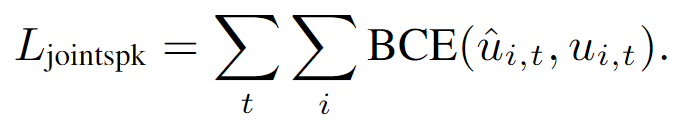
- 6.2)
individual speaker embeddings():T x TDCN_D -> T x S x C+1
- 6.2.1) Split:
T x TDCN_D -> T x S x TDCN_D/S
- 각 speaker slot 별 embedding space를 나눈다. (이래서 individual 인것 같다.)
- Split 후 L2 norm 적용한다. (NOTE: Global Network에 Concat 하는 Speaker Module Embedding은 l2 norm 전 값이다.)
- 6.2.2) Linear:
T x S x TDCN_D/S -> T x S x C+1
C: Training set의 전체 Speaker 수, C+1 (1은 silence speaker)S: Fixed-number of speaker slot (8)- 각 slot에 들어갈 speaker 확률을 계산해 낸다.
- 6.2.3) SoftMax:
T x S x C+1 -> T x S x C+1(dim 2)
- 화자를 나타내는 2번째(C+1)에 SoftMax 활성화 함수를 적용한다.
- Permutation-invariant softmax cross entropy speaker identification loss
- 각 slot 를 배치할 모든 경우에 대해서 minimum loss를 가지는 경우를 사용한다.
- 설명
- 2가지 종류 speaker Module 제안 (둘 중 하나 선택, 결과는 joint가 더 성능 좋음)
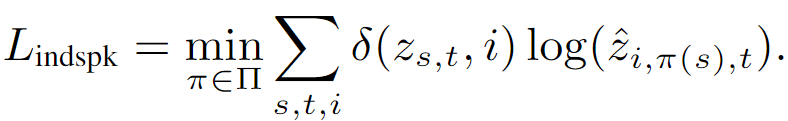
Experiments Result
Dataset
- type
- dataset
- simulation dataset
- LibriMeet-100K
- data: LibriSpeech
- number of Mixture: 100,000 utterance
- recording length: 120sec
- maximum number of speaker: 8
- overlap ratio: 20% ~ 50%
- LibriMeet-Dyn
- data: LibriTTS and on-the-fly meetings
- recording length: 90sec
- maximum number of speaker: 8
- overlap ratio: 0% ~ 40%
- condition
- no overlap same speaker
- at most be two active speaker
Model Type
- BLSTM
- BLSTM configure
- number of layer
P: 2- hidden units
D: 512
- SA
- Transformer Configure
- number of layer
P: 6- number of header
H: 8- number of dimension
D: 512
- TDCN
- TDCN configure
- repeat
R: 4- depth of dilated convolution layer
M: 8- bottleneck Dimension
D: 512- total number layer: 4 * 8 = 32
- TDCN-BLSTM
- TDCN + BLSTM
- TDCN-SA
- Small model
- TDCN
- repeat
R: 4- depth of dilated convolution layer
M: 6- bottleneck Dimension
D: 256- SA
- number of layer
P: 4- number of header
H: 8- number of dimension
D: 256- Large model
- TDCN
- repeat
R: 4- depth of dilated convolution layer
M: 8- bottleneck Dimension
D: 512- SA
- number of layer
P: 10- number of header
H: 8- number of dimension
D: 512
Training Strategy
- batch Size: 3
- 1) Training set
- learning rate: 1e-4
- optimizer: Adam
- iterations: 800K (BLSTM 200K)
Inference Configure
- Threshold: 0.7
- median filter length: 31
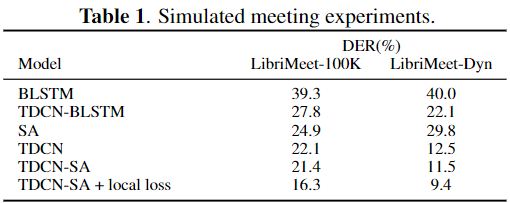
Simulated meeting experiments
- 결론
- TDCN
- 기존 EEND 대표인 BLSTM과 SA의 앞단에 TDCN을 사용한 경우 모두 성능 향상을 보였다.
- TDCN만 사용한 경우에도 성능이 좋았다. (심지어 BLTM 보다 좋았다)
- LibriMeet-Dyn 데이터에 대해서 굉장한 효과를 보였다.
- local loss
- TDCN에 대한 local loss(Auxiliary loss)는 많은 성능 향상 보였다.
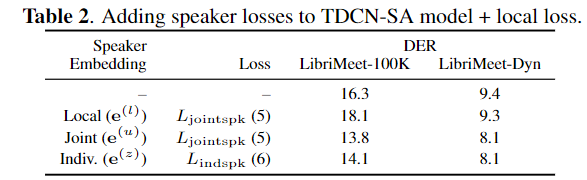
speaker loss experiments
- 결론
- speaker TDCN
- local TDCN 을 공용으로 쓰는 것 보다 따로 사용하는 것이 성능 향상에 좋았다.
- joint vs individual
- joint speaker embedding이 더 좋은 성능을 보였다.
- explicit 하게 speaker dimension representation space을 주는 것이 그렇게 효과적이지 않았다.
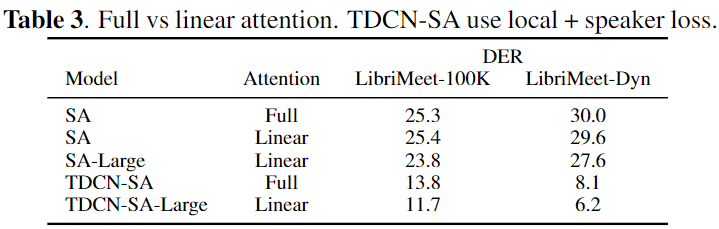
linear approximation attention experiments
- 결론
SAvsSA + linear
- Linear approximation이 그렇게 성능에 치명적이지 않았다.
- Linear approximation attention 을 통한 large 모델 사용으로 성능 향상을 보였다.
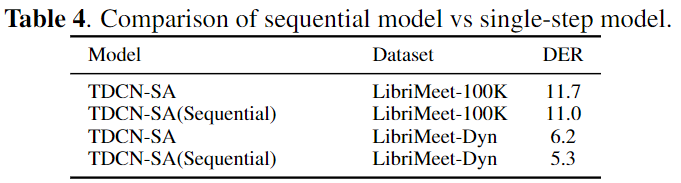
sequential model experiments
- 결론
- 각 데이터에 대해서 DER 1% 정도의 향상을 보였다.
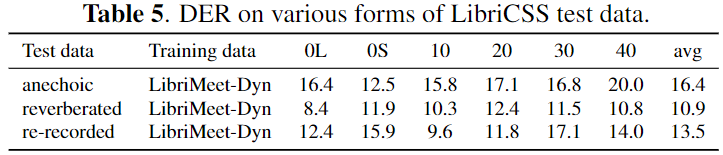
LibriCSS experiments
- 결론
- artificially reverberated version 이 가장 좋은 성능을 보였다.
- 학습 시에 사용한 RIR에 overfit 된 경향을 보인다.
- Reverberated 되지 않은 dry 한 anechoic 보다 reverberated 된 음원이 더 좋은 성능을 보인다.
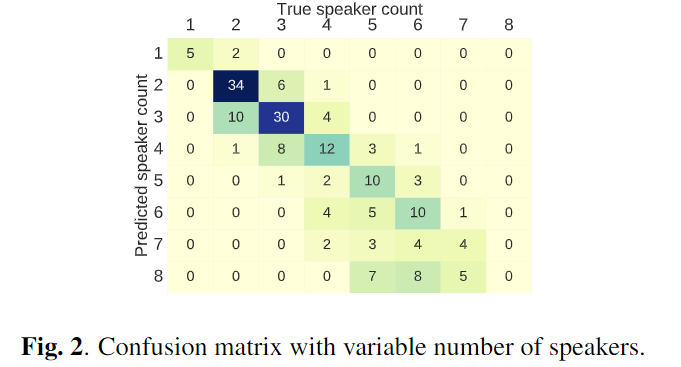
variable number of speakers
- DER 18% in LibriSpeech test data
- 화자수 4명 이하인 경우에 높은 정확도를 보였다.
Conclusion
- local-global network 을 통한 성능 향상을 보였다.
- 화자 인식을 multi-task 로 이용한 성능 향상을 보였다.
- linear approximation of full-attention을 이용하여 large model 사용과 성능향상을 보였다.
- sequential iteration 방법을 통한 성능 향상을 보였다.
- 1~8명 사이로 이전보다 많은 사람들에 대해서도 성능 향상을 보였다.
- simulated meeting data 뿐 아니라 LibriCSS dataset(real acoustic mixing)에 대해서도 좋은 성능을 보였다. (DER 18% 아직 부족하다고 보임)

Audio & Speech AI Researcher 입니다! Speaker Diarization & Speaker Verification 연구 경험을 가지고 있고, 전반적인 Speech Representation 에 대해서 관심을 가지고 있습니다!