[Voice AI Challenge 2021 대회 참가 리뷰] MAIC Voice AI Challenge

간단한 소개
우연한 계기로 이전에 VoxSRC21 대회에 참가했던 박동건, 박경완 학생과 함께 Voice AI 2021 Challenge 에 참여했습니다.
평소에 AI를 메디컬에 접목하려는 시도가 늘어나고 있으며 코로나 진단을 목소리로 진단할 수도 있다는 소문을 듣긴 하였지만 크게 관심을 가지지 않았습니다.
하지만, 이번 대회와 같은 경우 성대 질환으로 보컬에도 많은 관심을 가지고 있어서 흥미가 생겼고, 소리로 정말 진단이 가능한지에 대한 궁금증이 생겨 참여했습니다.
아무래도 적은 데이터 상황에서 효과적으로 학습 및 generalization를 하는 것이 정말 어려웠고 매번 아이디어를 뽑아내는 것도 정말 어려웠습니다.
또한, 처음부터 끝까지 모두 시스템을 구현하고 검증하는 경험은 처음이여서 python과 pytorch에 있어서도 많은 공부가 될 수 있는 시간이었습니다.
마지막에 시간이 없는 상황에서 극적으로 도움을 주었던 박동건 학생의 Data augmentation... 파뿌리 잡는 듯이 시도해본 앙상블 알고리즘들... 우리를 제외한 모든 팀들이 ResNet 구조를 사용했다는 소식... 등 저희 시스템에 아쉬움과 부족함이 많지만 다 이러면서 배우는 거라고 생각이 들었습니다.
이번기회에 다양한 Loss Function, Objective Function, 모델들을 사용해보고 비교해보는 좋은 경험이었습니다.
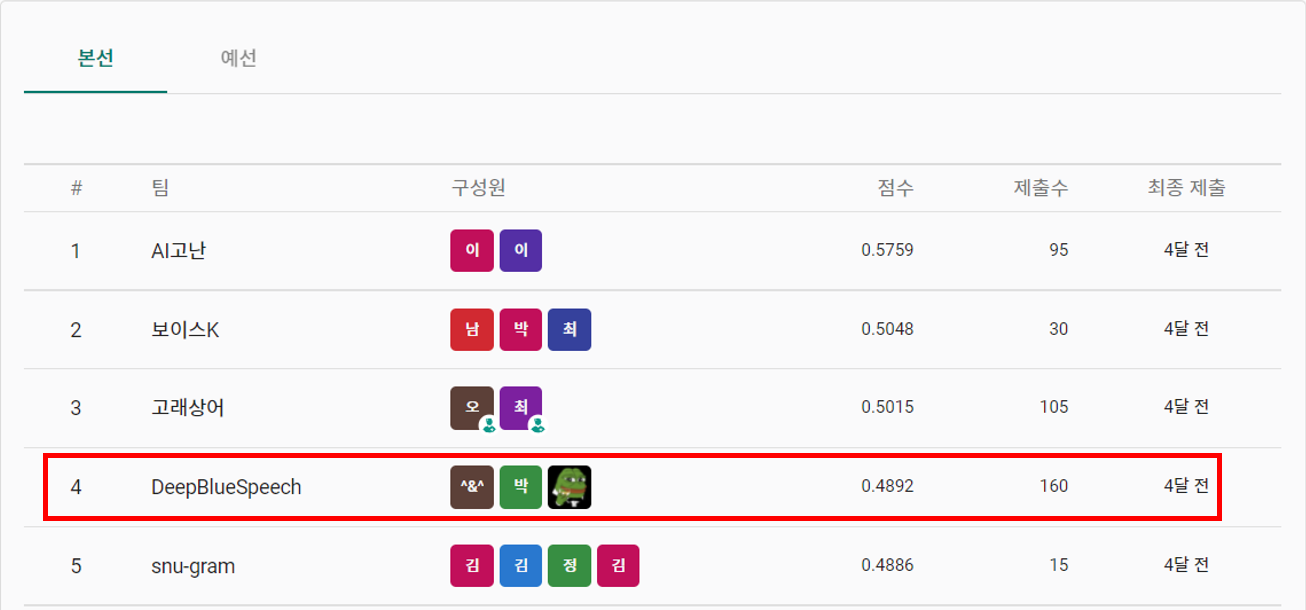
최종적으로 4등으로 좋은 마무리를 할 수 있어서 기뻣습니다👏👏
대회 소개
서울대학병원에서 MAIC 라는 대회 플랫폼으로 다양한 질병 관련 대회를 진행하고 있습니다.
이 중에서 Voice AI Challenge 는 정상과 5종류의 질병[악성/성대마비/성대결절/풀립 및 물혹/기능성발성장애]을 음성 데이터(Mel-Spectrogram)으로 분류하는 테스크입니다.
데이터 셋 소개
데이터 구조 정보
이 대회 데이터는 각 검진자들은 15개의 음절과 2개의 모음을 순차적으로 말하며 이에 대한 발화 지점 정보 annotation을 제공합니다.

또한 각 음절 또는 모음이 skip 또는 pronounce(뭉개짐) 되었는지도 구분되어 있습니다. (특정 발음에서 skip 또는 pronounce 되는 경향이 있는지 보려고 했다고 했음)
meta 데이터로는 남/여 정보와 나이를 제공해 주었는데, 여기서 성별 정보가 생각보다 중요한 부분으로 판단했습니다.
데이터의 질병 & 남/여 분포
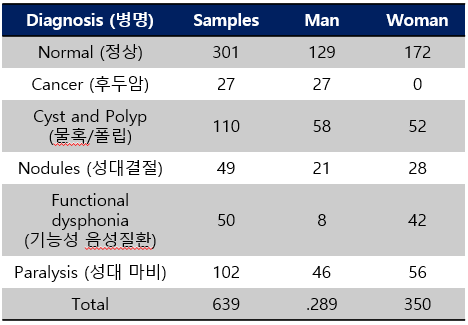
데이터는 총 639개의 recoding이 존재하고 각 질병 및 남/여 분포는 아래와 같습니다.
- 질병이
굉장히 unbalanced 한 데이터 분포를 가지며 수 또한 굉장히 작습니다. - 남/여 불균형 같은 경우
후두암은 남자만 존재하며,기능성 음성질환은 여성이 많은 것으로 확인했습니다.
데이터의 skip/pronounce 분포
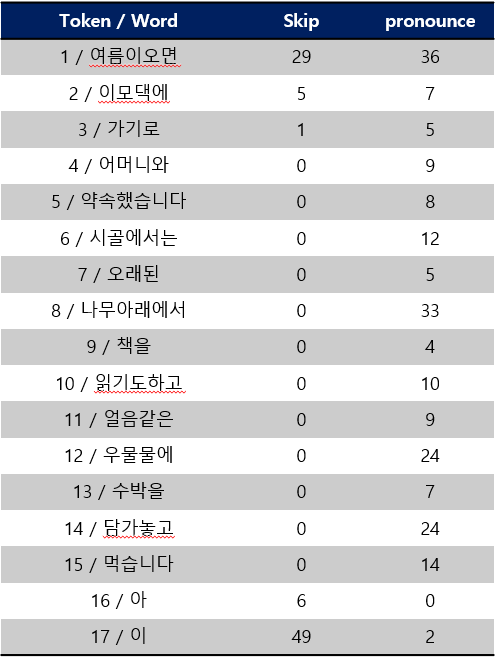
- 음절, 모음에 대한 skip과 pronounce 분포는 아래와 같습니다.
- 우선 음절, 모음 총 17개에 대해서 각각을
token으로 지칭하겠습니다. - skip 과 같은 경우 앞/뒤로 다수 존재하고 token 4~15 에서는 없는 것을 확인할 수 있습니다.
- pronounce 같은 경우 특정 단어에서 틀린 경우 정상과 질병임을 구분하는 지표로 사용할 수도 있었지만 네트워크를 학습하는 입장에서 이런 정보를 별도로 제공하지는 않았습니다.(일반화에 방해가 될것 같아서 제외)
데이터의 token 별 frame 길이
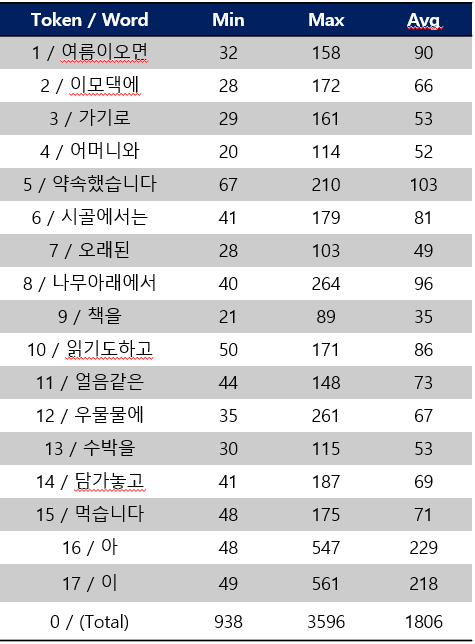
Token 별 Frame 길이는 아래 표와 같습니다. 각 음절에서 단어 개수에 따라서 Frame(시간) 길이 차이를 보이는데, 길이 차이에 따른 질병 분석을 진행하지는 않았습니다.
- Token 별 평균 길이
- Token 1~15: 80~90 Frames
- Token 16~17: 220 Frames
데이터 Format
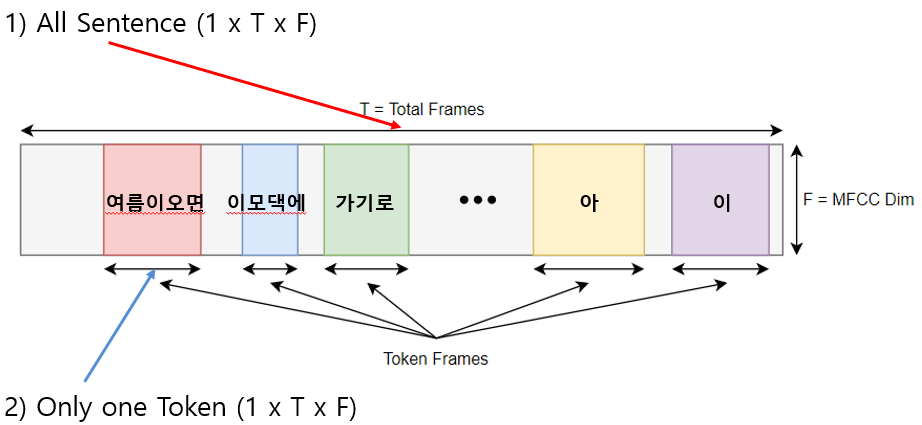
- T=Frames, F=MFCC Dim(13/26/40), K=Number of Token(17)
우리는 총 4가지의 형태를 실험해 보았습니다.
1) All sentence
- 그대로 사용하는 방법으로 다 때려 넣는 방법
2) Only one Token
- 각 token를 하나의 입력으로 보는 방법
3) All Token Stacked
- 각 Token를 순차적으로 feature dimension에 쌓아서 사용하는 방법
- skip 또는 길이가 안맞으면 zero padding 했습니다.
4) All Token to Channel
- 각 Token을 다른 channel에서 담당하도록 했습니다.
- 이는 CNN과 같은 구조를 위해서 사용하였고 3번 과 동일하게 zero padding 했습니다.
최종적으로 3) All Token Stack 구조를 사용했습니다.

네트워크 모델
들어가기 앞서, 검증 실험은 Voice Disorder용 오픈 데이터인 SVD(Saarbruecken Voice Database) dataset 를 사용했습니다.
링크
데이터 다운 및 질병 정보는 web crawling 했습니다.
아래 실험은 모음 a, normal tone 인 single token 기준임을 전해드립니다.
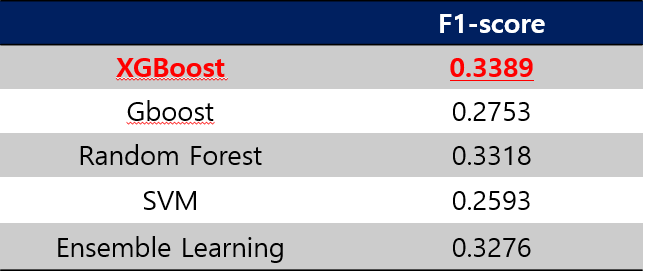
ML Method
- 많은 Voice pathology, disorder detection에서 ML 기법을 전통적으로 많이 사용했습니다.
- 저희 또한 자주 사용되는 다양한 ML 기법들 실험했습니다.
- 이 파트는 같은 랩실 동료 박동건 학생이 담당해 주셨습니다😎
역시나 XGBoost가 가장 좋은 성능을 보입니다.
CNN architecture
-
대회 발표때 저희를 제외한 상위권 팀이 모두 CNN (ResNet) 를 사용했습니다...(나 뭐하냐 ㅠㅠ)
-
제가 담당했는데 데이터 사용에 있어서 아쉬움이 있었던거 같습니다😥
-
Data format
- 4) All token to channel
- MFCC 40 dim
-
Architecture
- CNN 2D Block: 4 Blocks
- Conv2D, Batch Norm, Dropout, ReLU, Pooling
- MLP (FC layer) or Attention
- CNN 2D Block: 4 Blocks
구조는 [1]를 참고했습니다.
[1] H. Guan and A. Lerch, "Learning Strategies for Voice Disorder Detection," 2019 IEEE 13th International Conference on Semantic Computing (ICSC)
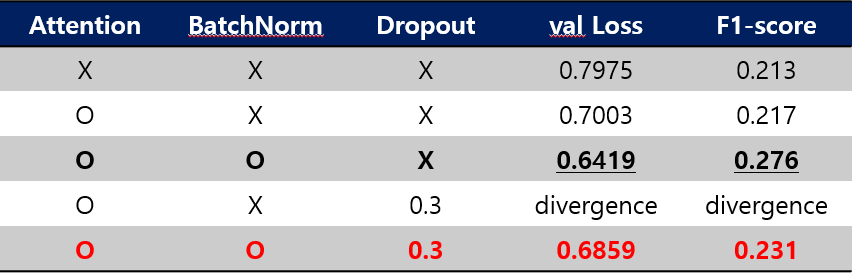
- 결과
- SVD 데이터셋 기준 결과 입니다.
LSTM Architecture
-
랩실 동료인 박경완 학생이 담당한 파트입니다😍
-
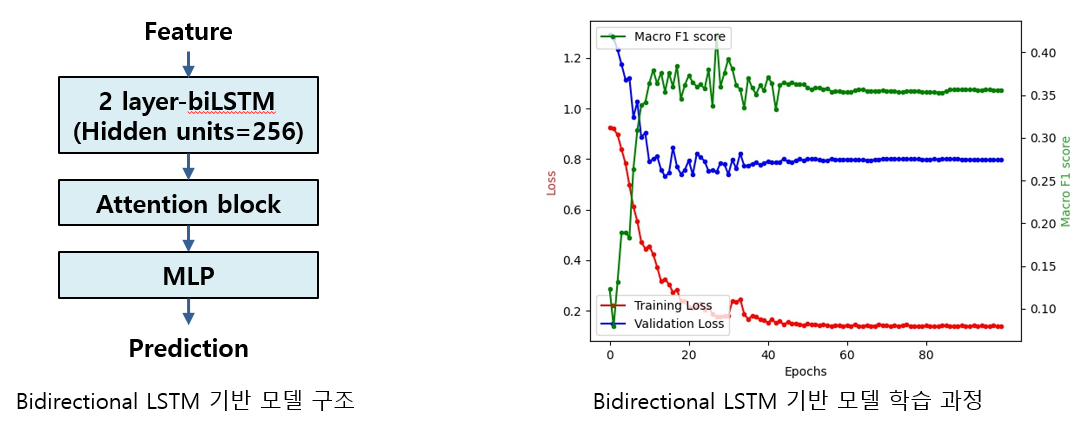
Bidirectional LSTM
- RNN 계열 신경망 기반 모델로 feature의 contextual information을 학습
- 정상 및 병적 음성 신호 스펙트로그램의 음성 구조의 temporal pattern 변화 차이
- 음성 기반 질병 탐지(voice disorder detection) 논문 [2] 등을 참고
- LSTM 기반 모델의 딥러닝 모델을 이용하는 연구를 차용해 bidirectional LSTM 기반 모델 설계
- RNN 계열 신경망 기반 모델로 feature의 contextual information을 학습
[2] Gupta, Vibhuti. "Voice disorder detection using long short term memory (lstm) model." arXiv preprint arXiv:1812.01779 (2018)
Attention Aggregation
- Attention with Linear [3]
- Feature의 일정 차원을 선택한 후 해당 차원 별로 데이터를 Linear layer를 거쳐 weight 계산하는 방식으로 전체 데이터에 대한 weight vector를 도출
- 계산된 attention weight vector를 데이터에 적용하면서 데이터 내 중요한 부분에 대한 원활한 학습 효과
- 모델의 기본적인 Attention Block 으로 사용함
- Feature의 일정 차원을 선택한 후 해당 차원 별로 데이터를 Linear layer를 거쳐 weight 계산하는 방식으로 전체 데이터에 대한 weight vector를 도출
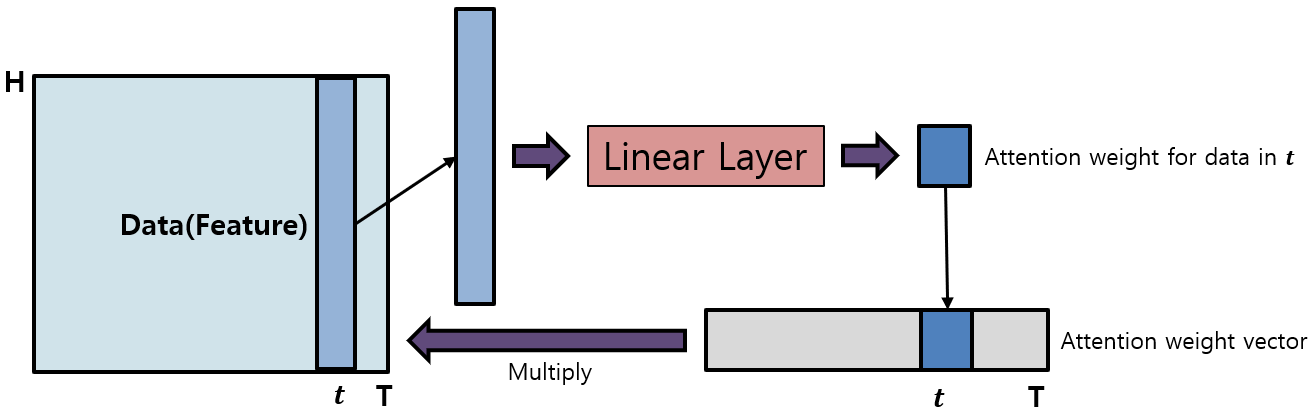
[3] Luong, M.-T., Pham, H., and Manning, C. D. “Effective approaches to attention-based neural machine translation.” In Conference on Empirical Methods in Natural Language Processing(2015).
Training Strategies
Loss Function
Cosine Loss [4]
이미지 분류에서 적은 데이터 셋에 대해서 좋은 성능을 보임
아래 그림과 같이 Loss 값에 분포가 보다 넓게 분포되어 있어 적은 데이터 셋에 대해 보다 좋은 학습 지표를 보였습니다.
코드는 [5] 블로그를 참고하였습니다.
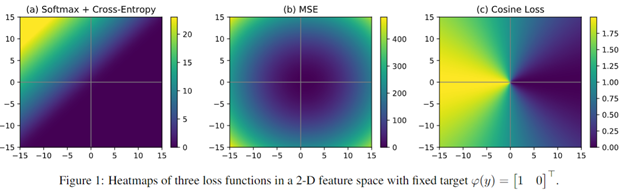
[4] Barz, Björn & Denzler, Joachim. (2020). Deep Learning on Small Datasets without Pre-Training using Cosine Loss. 1360-1369.
[5] https://byeongjokim.github.io/posts/Cosine-Loss
Binary Loss (Auxiliary Loss)
6종류의 Class가 아닌 병의 존재 유무 정보를 이용한 2종류의 Class 형태의 추가적인 Loss 사용했습니다.
별도의 Fully connect를 생성하는 것이 아닌 단순히 summation으로 사용했습니다.
둘다 해보았지만 큰 성능 차이를 보이지 않았습니다.
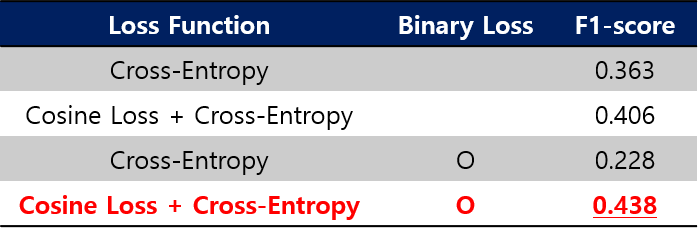
Cosine Loss, Binary Loss 성능 비교
- Cosine Loss가 보다 안정적인 학습을 가능하도록 하였습니다.
- 즉, 데이터 불균형으로 인해서 출력이 편향되는 경향이 있었는데 보다 줄어들었습니다.
- Binary Loss는 Cosine Loss와 함께 사용했을때 성능향상을 보였으며, 실제 대회에서도 Binary Loss를 사용했을때가 test 데이터에 대해서 보다 안정적인 성능을 보였습니다.
Balanced Sampler
Class-Unbalanced 데이터는 모델 학습에 있어서 Class 편향을 일으킬 수 있습니다.
큰 데이터 셋인 경우 클래스 비율을 맞춰주면 되지만 작은 데이터 셋은 이러한 방법이 어렵습니다.
이를 방지하기 위한 수단으로 학습 시에 각 클래스 별 Sampling 비율을 맞춰주는 방법인 Balanced Sampler을 사용했습니다.
코드는 [6]를 참고했습니다.
[6] https://discuss.pytorch.org/t/balanced-sampling-between-classes-with-torchvision-dataloader/2703
- 결과
- SVD dataset 에서는 Balanced Scheduler가 오히려 성능 감소를 보였지만, 대회에서는 효과적이였습니다.

Augmentation
Random Crop & padding
이미지 분류 및 컴퓨터 비전 분야에서 효과적으로 사용되는 Augmentation 기법을 적용
- Spectrogram으로 주어지기 때문에 pitch shifting과 같은 augmentation 기법은 사용하지 않음
계산적으로 유리하고 단순한 random crop과 random padding 을 사용
질병은 어느정도 전반적으로 존재한다고 생각하고 사용을 하였습니다.

Token Shuffling
Token의 순서를 랜덤으로 Shuffling 해서 증강 시도했습니다.
큰 효과를 보지는 못했지만 잘 쓰면 좋을꺼 같습니다. (비슷한 발음 길이 위주로)
Frame Reversing
입력 Feature를 시간에 대해서 좌우 반전 시켜 데이터 증강 시도했습니다.
정방향이나 역방향이나 질병의 유무는 다르지 않다고 생각하였습니다.
아무래도 이미 뽑혀진 mel-spectrogram 을 reverse 하다보니 성능 감소를 보였습니다. raw audio 데이터에 대해서 바로 time reverse를 적용해보는 것이 더 좋아보입니다.
SpecAugment [7]
simple data augmentation method for speech recognition
- Time Warping (optional)
- 임의의 점이 선택되고, 해당 선을 따라 0에서 시간 왜곡 parameter W까지의 uniform에서 선택한 거리 w로 왼쪽 또는 오른쪽으로 warping 함
- Frequency Masking
- 주파수 채널 이 Masking
- 는 0에서 parameter F까지의 uniform distribution에서 선택
- 주파수 채널 이 Masking
이미지에서 random erasing과 비슷하게 볼 수 있습니다.
[7] Park, D. S., Chan, W., Zhang, Y., Chiu, C. C., Zoph, B., Cubuk, E. D., & Le, Q. V. (2019). Specaugment: A simple data augmentation method for automatic speech recognition. arXiv preprint arXiv:1904.08779.
SpecAugment++ [8]
SpecAugment에 더 나가아서 3가지 추가적인 Masking 방법 및 Hidden space 에 대한 Masking 실험을 추가했다.
대회에서는 Hidden space 까지 Masking을 적용하진 않았고 3가지 추가적인 Masking 방법을 적용했다.
- Zero-value masking(ZM) 💕same as specaugment
- SpecAugment 과 같은 방법
- Add Gaussian Noise (Optional)
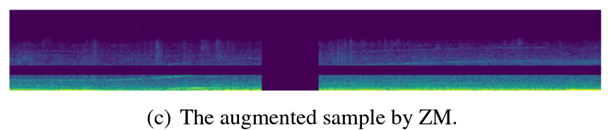
-
Mini-batch based mixture masking (MM)
- Mini-batch의 다른 sample를 가져와서 masking 영역에 mix (ratio=0.5)
- Mix-up 방법과 유사
-
Mini-batch based cutting masking (CM)
- Mini-batch의 다른 sample를 가져와서 masking 영역에 대체
- Cut-Mix 방법과 유사
[8] Wang, H., Zou, Y., & Wang, W. (2021). SpecAugment++: A Hidden Space Data Augmentation Method for Acoustic Scene Classification. arXiv preprint arXiv:2103.16858.
[9] https://github.com/WangHelin1997/SpecAugment-plus
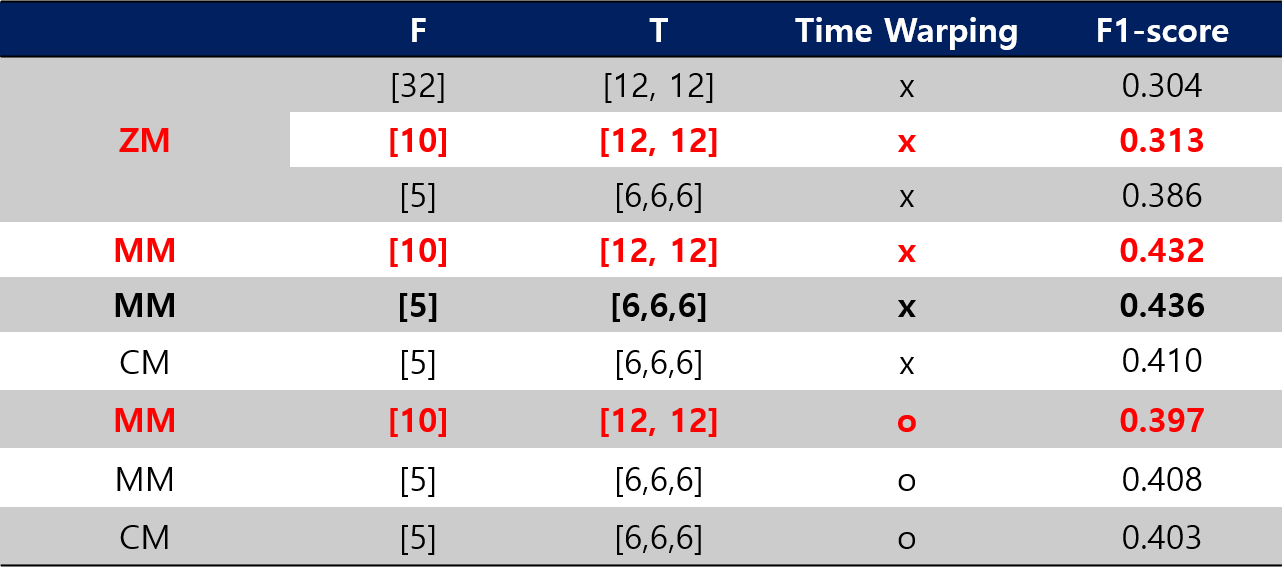
- 결과
- ZM보다 MM과 CM이 월등이 좋은 성능을 보였습니다. 대회에서도 동일했습니다.
- 대회에서는 CM에 더 좋았지만 SVD에서는 MM이 좋은 결과를 보였습니다.
- Time Warping은 오히려 성능저하 또는 비슷한 성능을 보였습니다.
Ensemble 전략
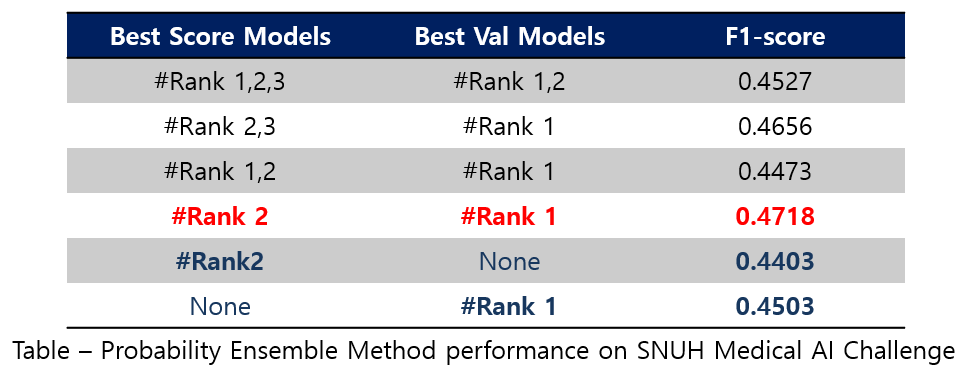
Probability Ensemble Method
- [Rank #1, 2, 3] Best F1 Score, [Rank #1, 2] Best Val
Model Ensemble
-
Three type model Ensemble
-
SpecAugment (F=10, T=[12,12])
-
SpecAugment++ (MM, F=10, T=[12,12])
-
Time stretching (W=5)

Final Configuration
-
Data format
- MFCC 40 dim
- 3) All Token Stacked
-
Architecture
- LSTM architecture
-
Training Strategy
- lr: 1e-4, Optimizer: adam
- loss function: Cosine Loss
- Balanced Sampler
-
Data Augmentation
- Random Crop
- SpecAugment
- SpecAugment++ (Time Stretch)
-
Ensemble
- Probability Ensemble Method
- Model Ensemble
추가 실험들
LSTM with Transposed Feature
-
이 파트는 박경완 학생이 맡아 주셨습니다 😘
-
2-branch 구조 모델
- 2개의 bidirectional LSTM과 Attention block을 이용해 얻은 feature를 같이 학습에 이용
- 각각의 branch의 결과를 동시에 MLP(Multi Layer Perceptron)를 통해 이용해 모델 출력 생성
- 각각 branch는 음성 신호 스펙트로그램의 시간과 주파수 차원 내 변화와 패턴을 학습
- 기존 baseline와 비교해 정상 및 병적 음성 신호의 정상성과 국소적 주파수 패턴을 학습 효과 기대 [10]
- 2개의 bidirectional LSTM과 Attention block을 이용해 얻은 feature를 같이 학습에 이용
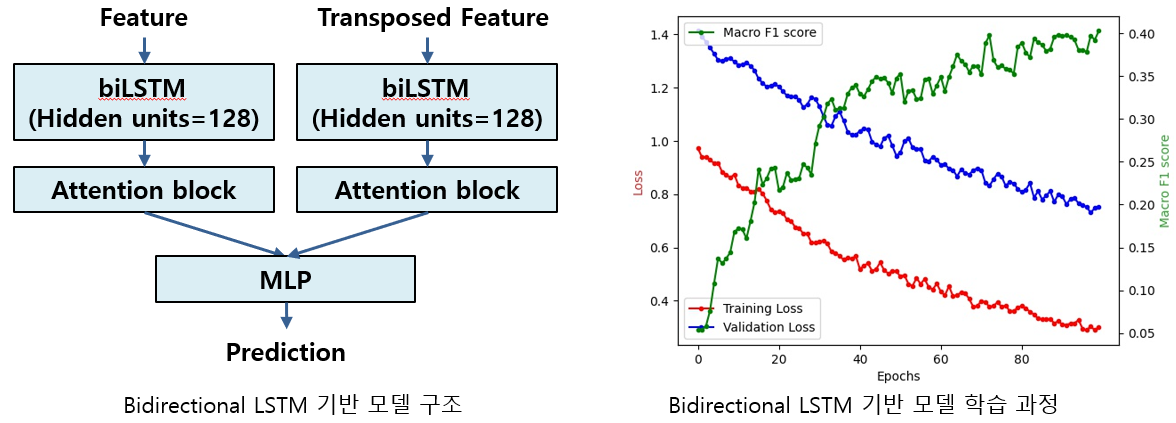
[10] Hao, Xiang, et al. "FullSubNet: A Full-Band and Sub-Band Fusion Model for Real-Time Single-Channel Speech Enhancement." ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
Multiple LSTM
- Series of bidirectional LSTM 구조 모델
- 2개의 bidirectional LSTM이 직렬 연결된 구조로 각 LSTM 별로 다른 level의 feature를 변환 및 학습 [11]
- 기존 baseline과 비교해 2개의 다른 구조를 갖는 LSTM block을 통해 정상 및 병적 음성의 Spectrogram 내 정보를 학습하고 새로운 feature를 형성 및 결과 도출에 이용함
- 2개의 bidirectional LSTM이 직렬 연결된 구조로 각 LSTM 별로 다른 level의 feature를 변환 및 학습 [11]
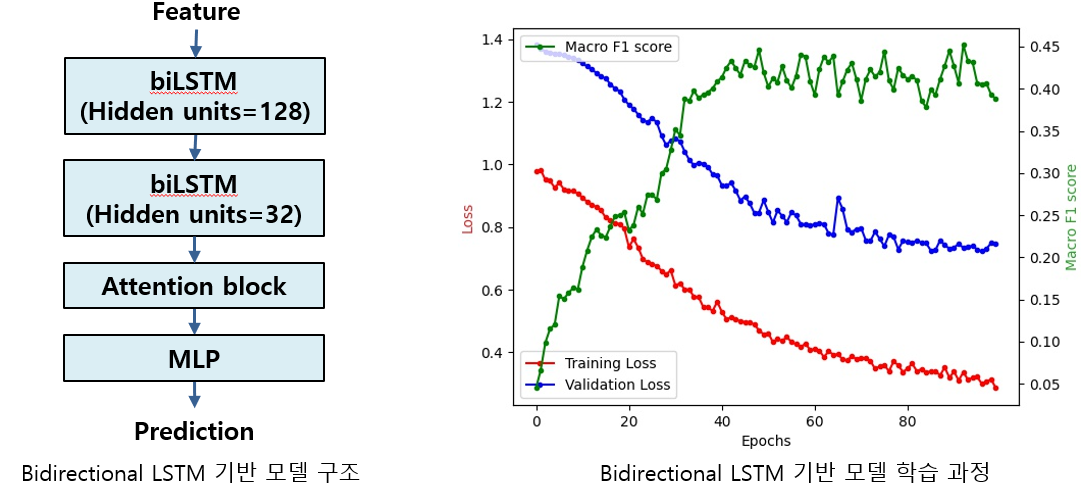
[11] Westhausen, Nils L., and Bernd T. Meyer. "Dual-signal transformation lstm network for real-time noise suppression." arXiv preprint arXiv:2005.07551 (2020).
CNN + LSTM
Speech Emotion Classification에서 사용한 것과 같이 CNN과 LSTM을 직렬 병렬로도 붙여서 사용해 보았지만 잘 학습이 되지 않았었다.
[12] https://github.com/Data-Science-kosta/Speech-Emotion-Classification-with-PyTorch
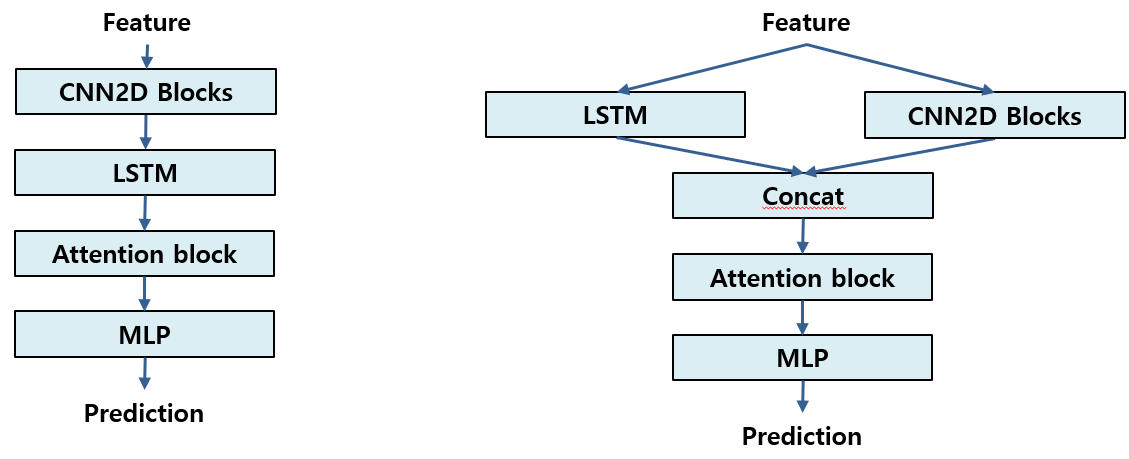
기타 여담
- 대부분 팀들은 ResNet 구조를 만들거나 pre-trained를 사용했다고 합니다.
- 팀들 중에 Balanced Sampler 외에 Weighted Cross Entropy를 사용한 팀도 있다고 합니다. 저희는 성능이 좋지 않아서 사용하지 않았습니다. 박경완 학생이 확인해 주었습니다🤞
- 입력에 White Noise라도 섞어서 증강해서 사용했으면 좋았을꺼 같습니다😂
- Meta 데이터(성별, 나이)를 normalized 이후 마지막 Fully connected 에 추가하여 실험했었는데, 다른팀들은 정확하게 어떻게 한지 모르겠습니다😂 학습시에는 Meta 데이터 추가가 좋은 성능 향상을 보였지만 테스트 데이터 대해서는 떨어진 성능을 보였습니다.
- 저흰 Training과 Test를 8:2 정도로 사용했는데 1등팀은 95:05 로 사용했다는 이야기를 듣고 데이터 쥐어짜는 것도 중요하구나 싶은 생각도 들었습니다.
- Self-Supervised Learning 를 사용했다는 팀도 있었는데 정확하게 모르겠습니다.
- Mixup를 explicit 하게 사용했어도 좋았을꺼 같다는 생각이 듭니다.
- 학습 시에 성대결절을 그렇게도 찾지 못했는데 이 부분을 잘 찾아내는 것이 이 대회에서 결정적이었다고 생각합니다. 저희도 아직까지 해결 방법을 찾지 못했는데 연구가 더 필요하다고 생각합니다.
소감
아직 발전되지 않는 분야에서 처음부터 문제를 파악하고 분석해 나가는 좋은 경험을 할 수 있었던거 같고 정말 적은 데이터 상황에서 어떻게 학습을 해야하는지에 대해서도 많은 고민을 할 수 있는 경험이었습니다.
대회에서 매번 순위가 오르락 내리락 하기도하고 애써만든 method가 좋은 결과를 보여주지 않고 매번 밤새면서 몸도 마음도 치쳐가는 와중에도 옆에서 끝까지 자리를 지켜주고 재미있는 예술 작품으로 웃음을 준 랩동료 박경완 학생에게 감사의 말을 남기고 예상치 못한 상황에 장염에 걸렸지만 말끔하게 나아서 든든하게 우리의 순위를 멋지게 책임져준 랩동료 박동건 학생 정말 멋있고 모두 감사합니다.
그니까 다음에도 같이해서 1등하자🤞😎
