[VoxSRC22 대회 참가 리뷰] VoxSRC Challenge 2022 Task 4: Speaker Diarization (Rank #3)

v0. 2022/12/25
머릿말
제가 연구했던 화자 분류(Speaker Diarization) 대회 중 하나인 VoxSRC 2022 Challenge 대회 후기에 대한 포스팅입니다.
대회 소개
VoxSRC에서 제공하는 Voxconverse 데이터셋은 유명 인사 연설, 기사 등 다양한 종류의 대화들을 담고 있습니다. 이 데이터는 다양한 길이의 음원 길이와 많은 화자 수를 가지고 있고 대부분 높지 않은 Overlap Speech 비율을 가지고 있다는 것이 특징입니다.
공개된 Voxconverse 데이터(라벨이 같이 있는)는 450개 정도의 많지 않은 데이터 개수와 다양한 길이의 음원 길이를 가지고 있습니다.
이러한 점이 대회를 참여하는 많은 사람들이 EEND 방법보다는 Clustering-Based Diarization 방법을 사용있습니다. 이후, Overlap Speech르 다루기 위해서 TS-VAD 또는 Overlap Speech Detection(OSD)를 이용한 후처리하는 방법으로 접근하고 있습니다.
저희 또한 EEND 보다는 Clustering-Based Diarization 방법을 중심으로 시스템을 구성했습니다.
Voxconverse 데이터는 크게 3가지로 볼 수 있습니다.
-
Dev set, Test set
- 라벨이 존재하고 Eval set 제출에 앞서 검증을 위해 사용합니다.
-
Eval set
- 음원만 제공되고, 실제 대회 결과에 사용됩니다.
- rttm 파일 형태로 제출됩니다.

- ref : VoxSRC 2021
Baseline (BUT team - VBx) 😋
Clustering-Based Diarization Pipeline 으로는 VoxSRC20 대회에서 2등을 차지한 BUT 팀 VBx 코드를 기반으로 진행했습니다.
작년 VoxSRC21 과 동일합니다.
전반적인 시스템 구성도
일반적인 Clustering-Based Diarization 파이프라인을 사용했습니다.
추가적으로 VoxSRC21 2등 ByteDance 팀이 사용했던 Multi scale 앙상블 기법을 참고하였고, VAD와 OVD 모델은 VoxSRC21 1등 DKU 팀 방법을 참고하여 사용했습니다.
- Dataset
- Speech Enhancement (optional)
- VAD (Voice Activity Detection)
- Embedding - Embedding Extractor (Speaker Verification)
- Feature Enhancement (optional)
- Scoring - PLDA (probabilistic linear discriminant analysis)
- Clustering - AHC (Agglomerative Hierarchical Clustering), SC (Spectral Clustering), Auto-tune SC
- Post Processing - SDF (Short Duration Filter), VBx (Bayesian HMM clustering)
- OSD (Overlap Speech Detection) - Heuristic (closest speaker assign)
- Ensemble
- VBx 전반적인 파이프라인
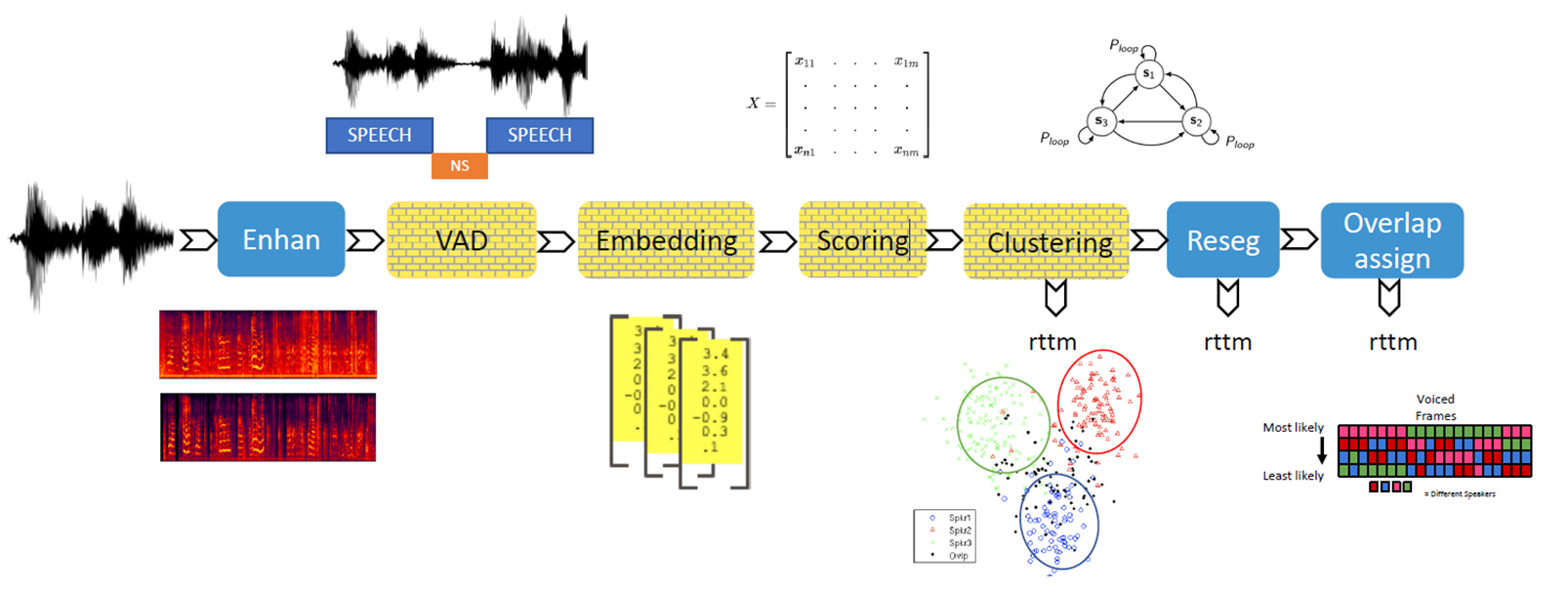
- 우리의 전반적인 파이프라인
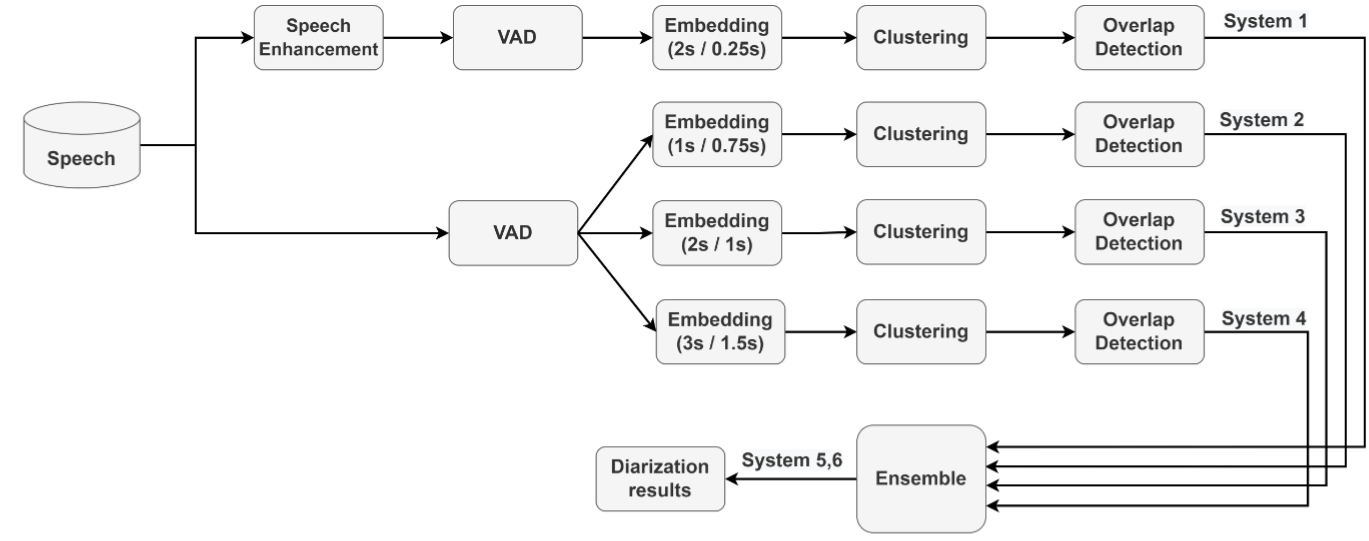
구체적인 시스템 설명 및 변경 사항
0. Dataset
VAD / OVD datset
-
Mixed Training sets
- AMI, AISHELL-4, CALLHOME, DIHARD I, DIHARD II
- 혹시 가지고 있다면, DIHARD III, ICSI, ISL, NIST Meeting, SPINE1&2 도 추가로 사용하면 좋을 것 같습니다.
-
Voxconverse datasets
- DEV402 (Training set)
- voxconverse 2020 dev + voxconverse 2020 test (앞쪽 subset) : 402 개 음원
- VAL46 (Validation set)
- voxconverse 2020 test (뒤쪽 subset) : 46 개 음원
- DEV402 (Training set)
Speaker Verification dataset
- VoxCeleb 1 & 2 dataset
Data Augmentation
- MUSAN Noise dataset
- RIR (Room Impluse Response) Noise dataset
1. Speech Enhancement
- 이 부분은 같은 랩실 동료인 박경완 학생이 담당해 주었습니다🤩
- 기본적으로 제공되지 않습니다. 저희는 DNS 2020 Challenge에서 좋은 성적을 보인 FullSubNet 을 사용하였습니다.
- Segment size 30s, Step size 5s 를 사용하였다고 합니다.(틀렸을 수도...)
- 사실 Speech Enhancement 적용시 오히려 화자 분류 성능이 떨어지는 경우가 존재했습니다. 특히, Speaker Extractor의 Segment Size가 짧은 경우 (1.5초 이하) 많은 성능 감소를 보였습니다. 이러한 점에서 앙상블로 사용했습니다.
2. VAD
- 발화(utterance)가 존재했던 시간을 찾아냅니다.
- 결과적으로 음원 내에 발화의 시작과 끝 시간을 'lab' 파일에 저장합니다.
- VAD를 위해 크게 Pyannote 2.0 framework (SincNet+LSTM)와 직접 구현한 VAD 시스템(ResNetSE34+LSTM)을 구현하였고, 실제 대회에는 Pyannote 만을 사용하였습니다. (앙상블시 오히려 성능 저하, Speech Enhancement 차이일 수도 있음).
- 전반적인 데이터 및 학습 방법은 2021 DKU 팀의 VAD에서 사용한 방법을 그대로 사용하였습니다.
2.1 Pyannote 2.0 (SincNet+LSTM)
- 이 부분은 박동건 학생 담당해주었습니다.
Pre-trained: 사전에 3개의 subtask (VAD, OSD, Speaker Change)로 사전에 학습된 모델을 그래로 사용합니다.Finetuning: Voxconverse의 DEV402 without SE 데이터를 사용하여 학습했습니다. VAD에 대해서만 학습했습니다.post-processing: on/off threshold, on/off min duration 를 Pyannote 프레임 워크를 이용하여 찾아냅니다.
2.2 ResNetSE34+LSTM
- 제가 담당한 부분입니다.
- 모델은 ResNetSE34 를 사용하였고, DKU VoxSRC 2021 시스템의 VAD ResNet 모델의 Channel 수를 동일하게 사용하였습니다.
Pre-training: Mixed Training set with SE 데이터 셋으로 10 epoch 학습을 진행했습니다. 데이터는 Segment size 10s, Segment step 5s 를 기준으로 사용하였습니다.Fine-tuning: Voxconverse의 DEV402 with SE 데이터를 사용했습니다. 10 epoch 중 Acc. 기준으로 선택하여 사용하였습니다.Ensemble: ResNetSE34의 8 pooling 이후 (80ms per frame) 추가적으로 시간 축에 대한 GSP를 각각 1, 2를 적용하여 각각 학습 후 각 posterior 확률 값의 평균 값을 사용했습니다.
2.3 Ensemble (Fusion)
- 각 두 모델의 출력의 각 프레임별 출력 확률 값의 평균을 사용하였습니다.
3. Embedding - Embedding Extractor (Speaker Verification(SV))
-
제가 담당한 부분입니다😋
-
Clustering-based Speaker Diarization에서는 SV로 학습된 모델을 이용하여 하나의 frame에 대한 Speaker Embedding을 생성하고 각 frame 간의 유사도를 이용하여 화자 분류를 진행합니다. 이는 Set problem 으로 overlap speech 를 모델링하지 못합니다.
-
Embedding Extractor 알고리즘
- 각 Record에 대한 VAD 결과를 이용하여 일정한 간격으로 Uniform Segmentation 합니다.
- 각 Segment를 사전에 학습된 Speaker Verification 모델을 이용하여 Speaker Embedding을 추출해 냅니다.
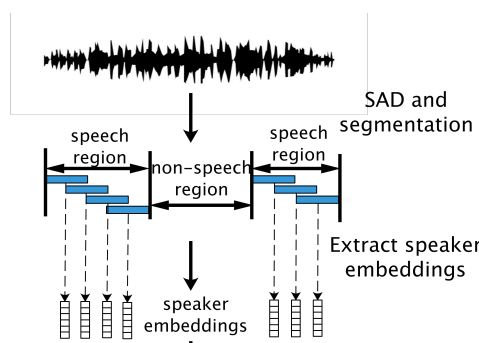
- 각 Segment를 사전에 학습된 Speaker Verification 모델을 이용하여 Speaker Embedding을 추출해 냅니다.
- ref: RPNSD
-
Speaker Verification 모델 선정 관련
- 일반적으로 Conv 1D 기반의
ECAPA-TDNN과 Conv 2D 기반의ResNet모델들을 많이 사용하지만, 개인적으로Transformer기반의 화자 분류 모델을 사용하고 싶은 마음에 저희는MFA-Conformer기반 모델을 사용하였습니다. ECAPA-TDNN (x-vector), ResNetSE34(r-vector), MFA-Conformer3가지의 모델에 대해서 학습 후 비교를 진행했는데, MFA-Conformer가 Score 상에서 더 좋은 분리도를 보였습니다.SKA-TDNN msSKA도 좋은 성능을 보이긴 했지만, 소폭 성능 향상에 비해굉장히 느린 속도로 튜닝이 쉽지 않을 것 같아 사용하지 않았습니다.
- 일반적으로 Conv 1D 기반의
(1) MFA-Conformer (transformer)
- Input feature: 80 MFCC (window size 25ms, hop size 10ms)
- Embedding dim: 192
(2) ECAPA-TDNN-large (x-vector, C=1024)
- Input feature: 80 MFCC (window size 25ms, hop size 10ms)
- Embedding: 192
(3) ResNetSE34V2 (r-vector, clova)
- Input feature: 64 MFCC (window size 25ms, hop size 10ms)
- Embedding dim: 256
(4) ResNet101 (ResNet, VBx)
- Input feature: 64 MFCC (window size 25ms, hop size 10ms)
- Embedding dim: 512- Speaker Verification (SV) 학습 관련
Segment 길이별 경향- Segment 길이가 짧은 경우 (0.5s, 0.75s, 1.0s) ECAPA-TDNN 보다
Transformer 기반 모델의 심각한 성능 저하를 보았습니다. - Speaker Verification (SV) 학습 시에 앙상블에
다양한 발화 입력 길이 (1.0s, 2.0s, 3.0s)에 대하여 학습을 진행하여 SV 성능을 저하되지만전반적인 화자 분류 성능의 향상을 보았습니다.
- Segment 길이가 짧은 경우 (0.5s, 0.75s, 1.0s) ECAPA-TDNN 보다
데이터 Augmentation(Mixup,Two uttrance concat)- 추가적으로
Mixup (alpha=0.1)과Two uttrance concat (5:5)방법을 사용해보았는데, 두 방법 모두오히려 성능저하 또는 비슷한 성능을 보여 사용하지 않았습니다.
- 추가적으로
Low Dimension Speaker Embedding- 보다 낮은 차원 크기에 Speaker Embedding (128-d) 을 학습하여 사용해 보았지만 눈에 띄는 성능 차이가 보이지 않아 사용하지 않았습니다.
MFA-Conformer 구조적인 접근- ECAPA-TDNN에서는 다양한 레이어 출력을 임베딩 생성시 직접적으로 이용하여 SV 성능 향상을 보였으며, MFA-Conformer 또한 동일하게 진행됩니다.
- 저희는 이러한 Multi-Scale Input Aggregation 오히려 다른 Task나 데이터 상황에 따라서 악영향을 주지 않을까 걱정했습니다.
- 이러한 점에서 2가지 방법으로 실험해봤습니다.
1. Weighted Layer Summation- SUPERB 정책에서 사용하는 방법과 동일하게 Weighted Summation 을 이용하여 접근했습니다.
- 저희가 실험한 결과, 학습된 Weighted 파라미터는 마지막 레이어와 1번째 layer에 높은 값으로 학습되었습니다.
- 몇몇 레이어만 사용하는 방법을 채택하였을때 오히려 성능저하를 보였습니다.
2. Auxiliary Loss- 다양한 계층의 출력을 사용하는 점에서 각 계층별 Auxiliary Loss를 주어 학습을 진행해보았습니다.
- 아쉽게도 성능 향상을 보지 못했습니다.
- 추가적인 학습 데이터 관련
- 추가적으로
CN-Celeb 1 & 2데이터를 추가하여 학습하였을때 오히려 성능 저하를 보였습니다.
- 추가적으로
4. Feature Enhancement
-
Dimension Reduction Method
- 우리는 화자 인식으로 학습된 모델을 다른 데이터와 테스크로 사용하게 됩니다. 이때에 speaker embedding에
화자의 특징 값 이외에 다른 정보들이 담겨 있을 수 있으며 다른 데이터 또는 테스크로 사용될때에 성능 저하를 줄 수 있습니다. 이러한 정보들을 제거하기 위한 부가적인 방법중 하나입니다. - 네이버 clova 팀은 DIHARD III 대회에서
Auto Encoder를 이용하여 효과적으로 speaker embedding의 차원을 줄이면서최대한 중요한 정보만 남기도록하여 성능 향상을 보였다고 했습니다. 이후 발전된DDRI라는 방법으로VAD 정보와 Speech/Noise Embedding 방식으로 성능 향상을 보였습니다. - 저희는 위 2가지 방법을 모두 구현하여 성능 테스트를 했습니다. 논문에 구체적인 dropout 값이 기제 되있지 않아 우선 0.1, 0.2, 0.3, 0.4, 0.5 값을 모두 테스트하여 선정하여 사용했습니다.
- 저희는 non-speech speaker 를 따로 학습하지 않은 것을 고려해도 Auto-Encoder 방법을 심각한 성능 저하를 보였습니다. 화자 임베딩의 차원이 작아짐에 따라 유사도 측면에서 전반적으로 높은 값을 보였습니다.
- DDRI의 경우 Auto-Encoder에 비해서 굉장히 좋은 성능을 보였지만, 그대로 사용하는 방법과 비슷하거나 더 낮은 성능을 보였습니다.
- 추가적으로, AP(Angular Proto) 정보를 로스 함수에 추가하여 학습을 진행하여 기존 DDRI 보다 좋은 성능을 보였지만 기존 PLDA 방법을 뛰어 넘지 못했습니다.
- 우리는 화자 인식으로 학습된 모델을 다른 데이터와 테스크로 사용하게 됩니다. 이때에 speaker embedding에
-
Attention Aggregation
- 일반적으로 생성된 Score Matrix는 많은 경우 Noise를 가지고 있습니다. 이러한 Noise가 Clustering 과정에 심각한 성능 저하를 일으킬 수 있습니다. 이 문제를 대응하기 위해서 clova 팀에서는 Scoring 전에 Attention 기법을 이용하여 주변의 비슷한 Speaker Embedding 정보들을 Aggregation 했습니다. 이 방법을 통해서 비슷한 Embedding 들 간에 점점 가까워지도록 하여 깨끗한 Score Matrix를 생성할 수 있도록 정제해줬습니다.
- 일반적인 Attention Aggregation 은 크게 Temperature와 Repeat 2가지 변수를 조절하여 사용하게 됩니다. Repeat 변수의 경우 어느정도 값이 커지게 되면 더이상 성능에 영향을 미치지 않을 정도로 수렴하게 됩니다. 따라서 어느정도 높은 값에 Repeat 값을 설정한 이후에는 Temperature 값이 중요한 요소로 볼 수 있습니다. Temperature 값에 따라서
어디까지 비슷한 임베딩이라고 간주할 것인지에 대한 범위를 나타나게 됩니다. 이때, 모든 Score Matrix의 분포가 비슷하지 않기 때문에 이 부분에서 고민을 하였습니다. 예를 들어 어떤 음원에서는 두 화자 간의 유사도가 0.9와 같이 높은 점수를 가지는 경우도 있지만, 두 화자가 같지만 0.7의 유사도를 가지는 경우도 존재합니다. 이러한 다양한 분포 정보를 AA가 반영하여 Temperature를 설정하기 어렵다고 판단했습니다. 따라서, 저희는 다양한 Temperature에 대해서 Repeat 하여 생성된 Embedding들을 Summation 하여 사용하여 보다 안정적이지만 Attention Aggregation 효과를 주도록 할 수 있었습니다. - 위와 같은 방법이 특정 길이에서 최적화 하였을때는 좋은 성능을 보였지만 다양한 길이에서 실험하여 최적을 찾기에는 어려웠고 불안정하여 본 시스템에는 사용하지 않았습니다.
- 관련 논문 [pdf, slide]
5. Scoring (PLDA / COS / LSTM-based)
-
Clustering 을 위해서는 추출된 화자 임베딩들 간의 유사도 값이 필요하다. 이러하 유사도를 계산하기 위해 시도한 다양한 방법들을 소개하겠습니다.
-
Cosine Similiarity (COS)
- 가장 기본적인 방법은 임베딩 간의 Cosine similarity를 계산하는 방법입니다. 따로 사전의 학습하지 않아도 된다는 장점을 가집니다.
-
Probabilistic Linear Discriminant Analysis (PLDA)
박동건학생이 담당한 부분입니다.- 저희 시스템에서 사용된 방법입니다.
- 화자들 간의 Speaker Embedding 의 유사도 분포를 학습하여 적용하는 방법입니다.
- 화자 인식 모델을 학습하기 위해 사용한 데이터(VoxCeleb 1&2)와 VoxSRC 데이터에 대한 각각 학습 이후 두 결과를 Interpolation 하여 사용했습니다. (9:1)
- 코드는 여기를 참고했습니다. [Github]
-
LSTM-based Scoring
박경완과김지원학생이 담당한 부분입니다.- COSINE과 PLDA는 주변 지역정보을 이용하지 못하고 각각 개별간에 정보를 가지고 유사도를 계산하며 Overlap Speech 에 대한 점수 모델링 하지 못합니다.
- LSTM 기반 Scoring은 학습을 통해서 주어진 두 화자 임베딩들 간에 유사도를 계산해냅니다.
- 작년 대회 팀들과 관련 논문들을 참고하여 동일하게 모델을 구성하였습니다.
- 가장 모호했던 부분은 Sub-block 을 생성하기 위한 Chunk size 였는데, 각 데이터 별(AMI, DIHARD, VoxSRC) 마다 사용한 Chunk size가 다르고 Segment Step size도 달라서 설정하는데 고민을 많이 했습니다. 우리는 LSTM에 주어질 전체 시간인 30초를 기준 학습을 진행했습니다.
- 학습같은 경우 VAD에서 사용한 Mixed Training Set 으로 Pre-training 한 이후 VoxSRC 데이터 셋으로 Finetuning 하여 사용하였습니다.
- 앙상블로 사용할 생각으로 만들었지만 너무 성능이 저조하여 사용하지 않았습니다.
- Full Attention을 위해 추가적으로 Transformer Block을 사용하여 성능 향상을 보였지만 Ensemble로 사용하기는 어려운 수준이었습니다.
6. Clustering - (AHC / SC, Auto-tune SC)
- 개요
- Scoring 으로 생성된 Affinity(distance) matrix 를 이용하여 각 segment 들을 clustering을 진행합니다. 위 과정으로 각 segment를 하나의 set 으로 간주하여 set problem을 풀어갑니다.
- 화자 분류의 경우 아직까지는 AHC 와 SC 같은 그래프 기반의 Clustering 방법을 사용하고 있습니다.
- 다양한 분포를 가지고 있는 Score Matrix를 고정된 하이퍼 파라미터 값을 사용하여 화자 수를 찾아내는 작업(Clustering)이 이루어지기 때문에, 테스크 별로 이 하이퍼 파라미터 값(Threshold) 값을 어떻게 설정하느냐에 따라 성능이 민감하게 작용합니다. 즉, 아직까진 Hard Tuning이 필요로 합니다... ㅠㅠ
- 이러한 Hard Tuning을 완화하기 위한 Auto-tune SC 방법도 존재하지만 아직까진 아쉽습니다.
- 추가적으로 Set Problem 변경을 통한 Overlap 문제를 다루지 못하는 부분을 완화시키기 위해서 Overlap-Aware SC도 존재합니다. 하지만 애당초 Speaker Embedding 자체가 Speaker Verification 학습 당시 Overlap Speech 에 대해서는 학습되지 않았고, 개인적으로 학습시키더라도 Embedding Space에 다루기 쉽지 않다고 생각됩니다. Score Matrix 상에서 Overlap Speech Embedding 위치에는 Noise 하게 보이며 아직까지는 이를 다루기 쉽지 않습니다. 추가적인 Overlap Speech를 다루는 방법은 OVD 파트에서 더 이야기 하도록 하겠습니다.
- AHC (Agglomerative Hierarchical Clustering)
- 일반적으로 가장 많이 사용되고 있는 방법입니다. 저희 또한 AHC를 이용하여 Clustering을 진행하였습니다.
- COS / PLDA 방법에 따라서 Threshold 설정방법이 다릅니다. 저희가 관측한 결과 COS의 경우 0.35~0.50 사이 값으로 Threshold을 사용하는 것이 적합하였습니다. PLDA의 경우 학습한 분포에 따라서 에너지 출력 값이 다르기에 (최소 최대 값 분포가 다름), VBx recipe에 있는 Score Matrix의 Energe 값을 이용하여 Threshold를 설정하는 방법을 사용했습니다.
- Clustering 시에는 VBx recipe에 구현된 코드가 아닌 Scikit-learn AHC 를 사용했습니다. 속도가 더 빠릅니다! ㅎㅎ
- SC (Spectral Clustering)
- Hierarchical, Kmean 방법과 다르게 Decomposition 이후 Eigen vector 와 Eigen value를 구하고, Sorting된 Eigen value 사이의 비율(또는 차이) 값에 대해서 Threshold 을 적용하는 방법으로 Clustering이 진행됩니다.
- 즉, 각 Cluster의 중심 거리를 이용하는 것이 아니라 Eigen gap 을 이용하여 Clustering이 이루어 집니다.
- 사실 이론적인 자세한 내용은 다른 글을 참고하는 것이 좋을 것 같습니다.
- 우선, SC의 경우 Score Matrix에 존재하는 Noise에 굉장히 민감한 것으로 알려져 있습니다. 따라서 Attention Aggregation 또는 LSTM-based Scoring 와 같은 방법으로 Noise가 상당부분 제거된 경우 많이 사용하는 것 같습니다. 저희에 경우 시간 부족으로 정교한 튜닝에 힘을 쏟지 못해서 AHC 성능을 넘기지 못했습니다. (CPU 도 너무 많이 사용...)
- Scikit-learn SC를 사용하였습니다.
- Auto-tune SC에 경우 논문 저자의 github 소스 코드를 수정하여 사용하였습니다. SC 보다는 좋은 성능을 보이는 것을 확인했지만, AHC 성능을 이기지 못했습니다.
7. Post-Processing - SDF (Short Duration Filter), VBx
박동건학생이 담당한 부분입니다.- Re-segmentation은 말그래도 Clustering 이후 후처리 방법으로 생각하시면 됩니다. 저희는 크게 SDF와 VBx를 사용하였습니다. 각 2가지 방법은 서로의 하이퍼 파라미터의 영향을 미치게 되어 적절하게 사용하였습니다.
- SDF (Short Duration Filter)
- Clustering 결과의 발화 길이가 굉장히 짧은 경우가 존재할 수 있습니다. 이러한 짧은 발화 들에 대한 화자 임베딩과 긴 발화에서 생성된 발화 간에 추가적인 Clustering을 진행합니다. 이때, Threshold를 그전보다는 여유있는 값을 주어 어느정도 비슷한 경우 합쳐지도록 하는 방법입니다.
- VBx
- 위에서 생성된 Clustering 결과와 PLDA에 파라미터 값을 이용하여 Re-Segmentation을 진행하는 방법입니다. 크게
loop, fa, fb하이퍼 파라미터 값을 조절하여 Hard tuning 을 진행하게 됩니다. - 코드의 경우 VBx recipe 을 그대로 사용하였습니다.
- 위에서 생성된 Clustering 결과와 PLDA에 파라미터 값을 이용하여 Re-Segmentation을 진행하는 방법입니다. 크게
8. OSD (Overlap Speech Detection) - Heuristic (closest speaker assign)
- Overlap Speech Detection
- 앞서 말했던것과 같이 Cluster-based Speaker Diarization은 Overlap을 다루지 못합니다.
- 이러한 문제를 완화하기 위해서 별도의 Overlap Speech Detection 이후 추가적인 후처리를 하는 방법을 사용합니다.
- 후처리 방법은 2nd-Assign 방법과 Heuristic 방법이 있는데, 저희 같은 경우 Heuristic 방법이 더 좋은 성능을 보였습니다.
- 2nd-Assign 은 Overlap Speech에 속하는 각 Segment 들에 대해서 2번째로 가까운 Cluster도 동시에 존재한다고 할당(Assign) 하는 방법입니다.
- Heuristic의 경우 Overlap Speech와 가까운 다른 화자로 mapping 하는 방법입니다.
- 실험 세팅
- VAD에서 사용한 모델과 데이터를 동일하게 사용하였습니다.
- 제가 학습한 ResNetSE34에 경우 추가적으로 Weighted BCE를 사용하였습니다. weight 값은 sqrt 값으로 하였습니다. 일반적인 경우의 overlap speech 의 비율이 굉장히 적기 때문에 학습 편중이 일어났습니다. 이를 완화하기 위해서 위 방법을 적용하여 학습을 가능하도록 하였습니다.
- OSD의 경우 Ensemble 한 결과가 가장 좋은 결과를 보였습니다.
- Post-processing 또한 VAD와 동일하게 사용하였고, Precision 가 최대가 되도록 튜닝했습니다.
추가적인 실험😆
A.1 Neural based Multi Scale Input
- 어떤 시간을 기준으로 다양한 Segment 길이에 대한 Speaker Embedding이 추출이 되었다고 할때, 한 Set(위치)를 대표하기 위한 대표 임베딩을 각각의 정보를 효과적으로 사용하여 생성하는 방법을 연구하는 분야입니다. 지금은 GAT 또는 Conv+LSTM 기반으로 각 위치에 대한 가장 적절한 Attention Weight를 계산하여 사용하는 방법이 있습니다.
- 저희는 Conv+LSTM 기반인 NVIDIA가 제공하는 NeMo 프레임워크의 MSDD 모델을 저희 모델에 사용하여 학습을 진행해보았습니다. 시간 관계상 Speaker Embedding 모델은 Freezing하여 사용했는데 생각보다 성능이 좋지 않았습니다. 좀 더 연구가 필요해 보입니다.
A.2 EEND 방법
- Interspeech 2021 에 소개된 EEND-vector Clustering 모델을 직접 학습한뒤 VoxSRC 데이터에 Finetuning 하여 사용해 보았습니다. 결과적으로는 Ensemble 또는 EEND-asp로 사용하기에도 아쉬운 성능이 나왔습니다.
소감
이미 2021년에도 마음 맞는 랩실 친구들과 함께 VoxSRC21 대회를 참여했었는데, 처음 대회를 참여하다보니 부족한 부분과 서툴렀던 부분이 많아 아쉬웠습니다.
이번에는 작년에 사용했던 Clustering-based Speaker Diarization Pipeline를 다듬고, 직접 화자 인식(Speaker Verification) 모델을 설계하여 학습하여 사용하고 PLDA도 직접 사용하면서 이전보다 저희의 시스템 다워졌다는 부분이 기뻣습니다.
이번 글에서 다룰 내용은 대회에서 사용했던 방법을 보다 자세하게 정리하고, 성능을 좋지 않았지만 대회를 준비하며 다양하게 시도했던 방법들을 정리하고 되돌아 보는 시간을 위해서 적습니다.
사실 대회에서 저희가 사용하는 방법들은 작년 VoxSRC21 대회에 참여했던 Baseline의 흐름을 거의 그대로 사용하고 있는 점에서 이전과 중복되는 내용은 조금 생략될 수 있어서 궁금하신 부분은 댓글로 문의 주시면 감사합니다.
짧은 일정동안 고된 일정, 시도했던 방법들이 잘 되지 않았을때의 아픔들과 잘 알지 못하는 부분도 각자 할일을 찾고 힘써준 팀원들에게 고맙고, 마지막까지 포기하지 않고 노력하여 함께 3등이라는 좋은 결과를 얻은 것 같아서 정말 기쁩니다. 졸업 이후지만 나름 좋은 마무리를 하게 해준 팀원들에게 감사를 돌립니다! ❤
부족한 글 읽어주셔서 감사합니다.

내년에도 같이 대회 나갔으면 좋겠네요~
수고하셨어요!