[VoxSRC21 대회 참가 리뷰] VoxSRC Challenge 2021 Task 4: Speaker Diarization

간단한 소개
제가 연구하는 화자 분류(Speaker Diarization) 대회 중 하나인 Voxconverse 2021 Challenge 대회 후기에 대한 포스팅입니다.
화자분류란, "Who Spoke when" 인 누가 언제 말하고 있는지를 알아내는 테스크입니다.
화자분류는 "DIHARD Challenge(2년 마다 진행)"와 "VoxConverse Challenge(1년 마다 진행)"가 있습니다.
그 중 DIHARD III Challenge 는 2020 겨울에 진행되었는데 미쳐 알지 못하고 참가하지 못해서 아쉬웠습니다.
대신, 매년 8~9월에 진행되는 Voxconverse Challenge 2021 에 참여하게 되었습니다.
이미 19, 20년에 진행되어오던 대회이기도 하고 처음으로 대회를 참여하다 보니 매년 참가하던 연구자들의 뒤를 쫓아가다보니 밤을 지새우기도 하고 미숙한 부분도 많았고 중요한 기간에 청천벽력 같이 코로나로 격리를 당하기도하고 다양한 일이 있었지만 개인적으로 많은 것을 배우고 랩실 동료들과도 좋은 경험과 추억을 만들 수 있던 것 좋은 기회였습니다.
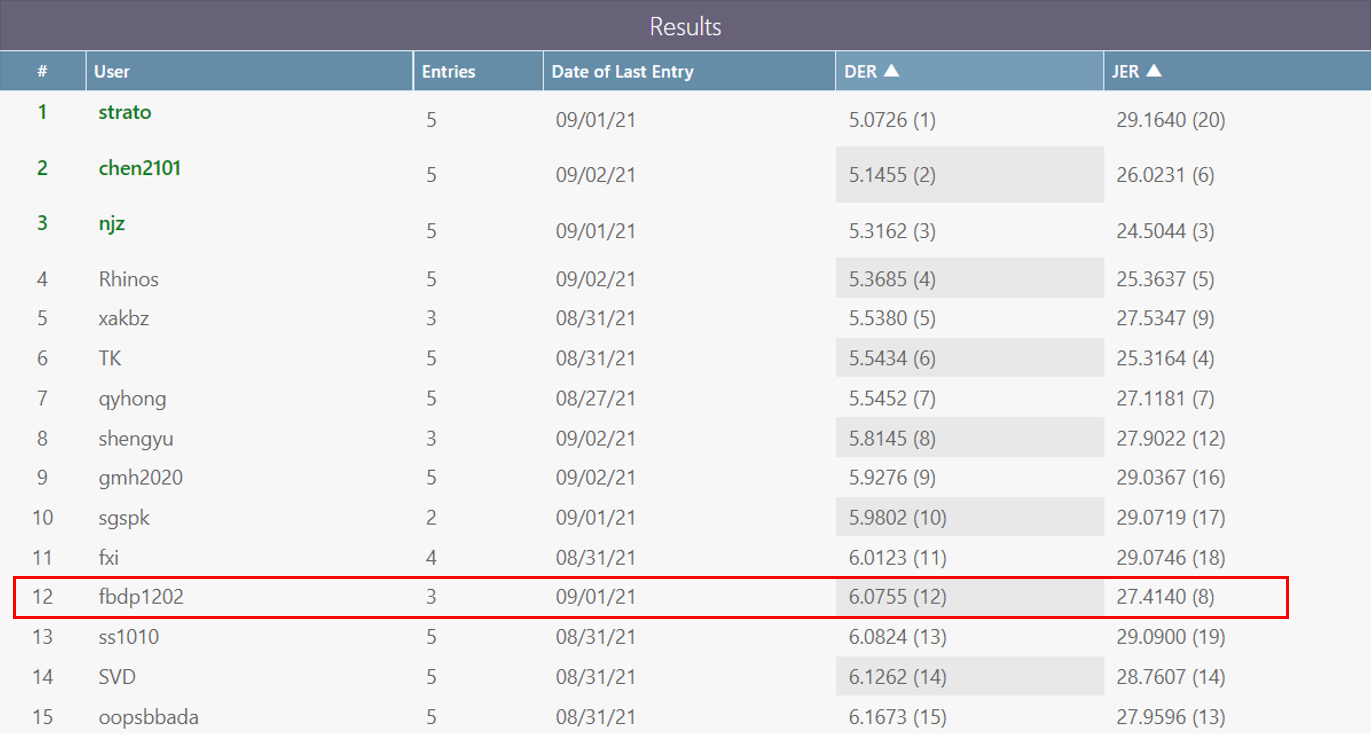
아쉽게도, 저희의 시도들이 좋은 성적을 내진 못했지만(#12) 준비했던 것들을 글로 남겨보고자 합니다.
대회 소개
Voxconverse는 Youtube 데이터로 유명 인사 연설, 기사 등 다양한 종류의 대화들을 담고 있습니다.
화자들의 발화가 겹치는 정도는 그렇게 심하지 않고 (심한 것도 있음), 음원별 길이는 짧은 경우부터 20~30분이 넘어가는 긴 음원도 존재합니다.
화자 수는 발화 내 없는 경우 부터 해서 20명이 넘는 경우도 존재하는 데이터 입니다.

- ref : VoxSRC 2021
본 대회는 일반적으로 많이 사용하는 Diarization Error Rate (DER)를 메인으로 하고 Jaccard Error Rate(JER)도 따로 보여주긴 합니다.(동점 가르기 용인듯?)
DCASE와 같은 학습 데이터 제한이 존재하지는 않습니다.
테스트(eval) 데이터 셋은 사전에 제공되며 음원 별 생성된 출력 rttm 파일들을 알집으로 Colab platform에 제출하는 형태로 대회가 진행되었습니다.
Baseline (BUT team - VBx) 😋
선정 이유!
본래 저자가 연구하던 End-to-End Neural speaker Diarization(EEND) 은 음원 내 발화의 overlap ratio가 높은 경우 좋은 성능을 보이지만, 화자 수의 제한, inner-block label permutation problem, 같은 환경 학습 데이터셋 부족과 같은 문제로 본 대회에서 Baseline으로 사용하는 것이 어렵다고 판단했습니다.
우선 이전 Voxconverse 2020 대회의 참가 팀들의 전략을 확인했습니다. 대부분 팀이 EEND가 아닌 Clustering-Based Diarization 방법을 사용하는 것을 확인했습니다.
이런 점에서 Clustering-Based Diarization 이후에 EEND를 다양한 후처리 방법으로 성능을 향상시키는 것을 계획으로 잡고 진행했습니다.
Clustering-Based Diarization 으로는 VoxConverse 2020 대회에서 2등을 차지한 BUT 팀 VBx 코드를 기반으로 진행했습니다.
전반적인 시스템 구성도
VBx의 전반적인 시스템 구성도는 다음과 같습니다.
- Speech Enhancement
- VAD (Voice Activity Detection)
- Embedding - Feature Extract (Speaker Verification)
- Scoring - PLDA (probabilistic linear discriminant analysis)
- Clustering - AHC (Agglomerative Hierarchical Clustering)
- Resegmentation - VBx (Bayesian HMM clustering)
- Reclustering - Global Speaker Embedding 추출 후 Speaker Clustering
- Overlap assign - Heuristic / 2nd label assign
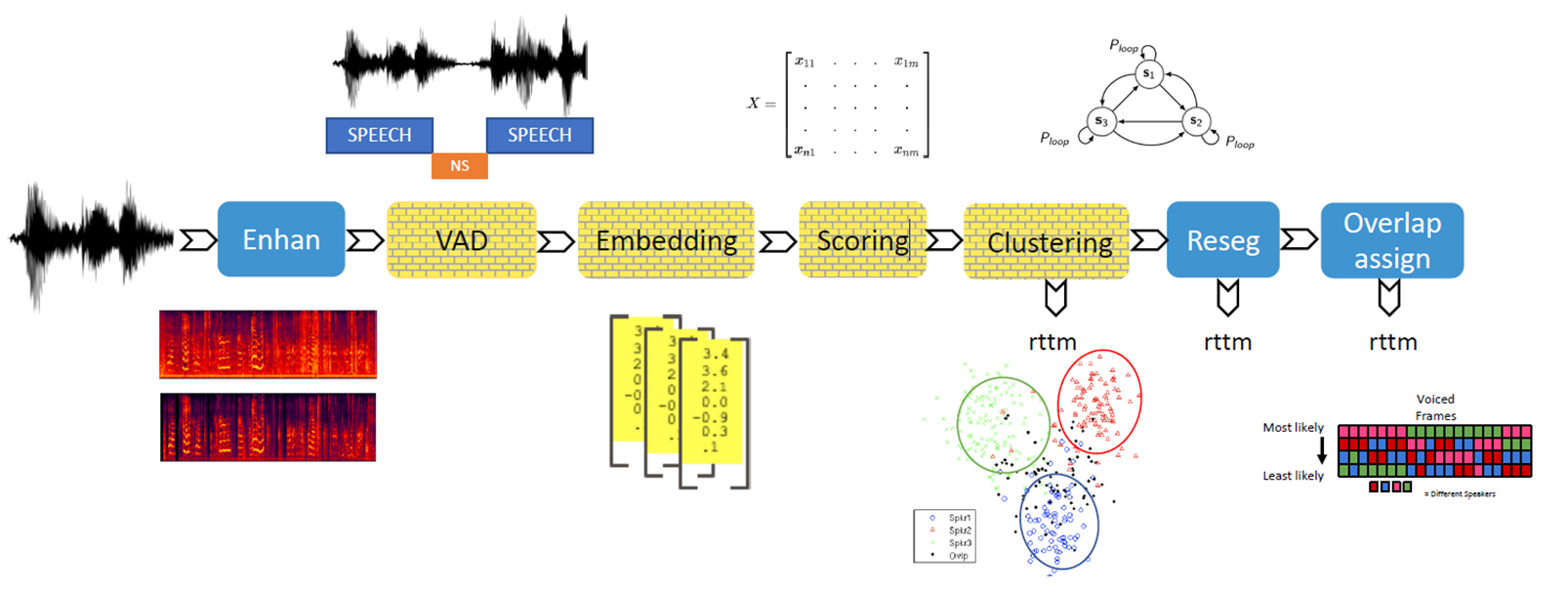
정말 감사하게도 BUT team에서 Speech Enhancement, VAD(일부만 제공)와 OV(Overlap detection)를 제외한 나머지 부분에 대한 코드와 모델을 공개해 놓으셔서 시작하는데 있어서 정말 큰 도움이 되었습니다.
구체적인 시스템 설명 및 변경 사항
구체적인 셋업 작업은 기억에 나지 않지만 중요한 부분만 집고 넘어가겠습니다.
1. Speech Enhancement
- 이 부분은 같은 랩실 동료인 박경완 학생이 담당해 주었습니다🤩
- 기본적으로 제공되지 않습니다. 저희는 DNS 2020 Challenge에서 좋은 성적을 보인 FullSubNet 을 사용하였습니다.
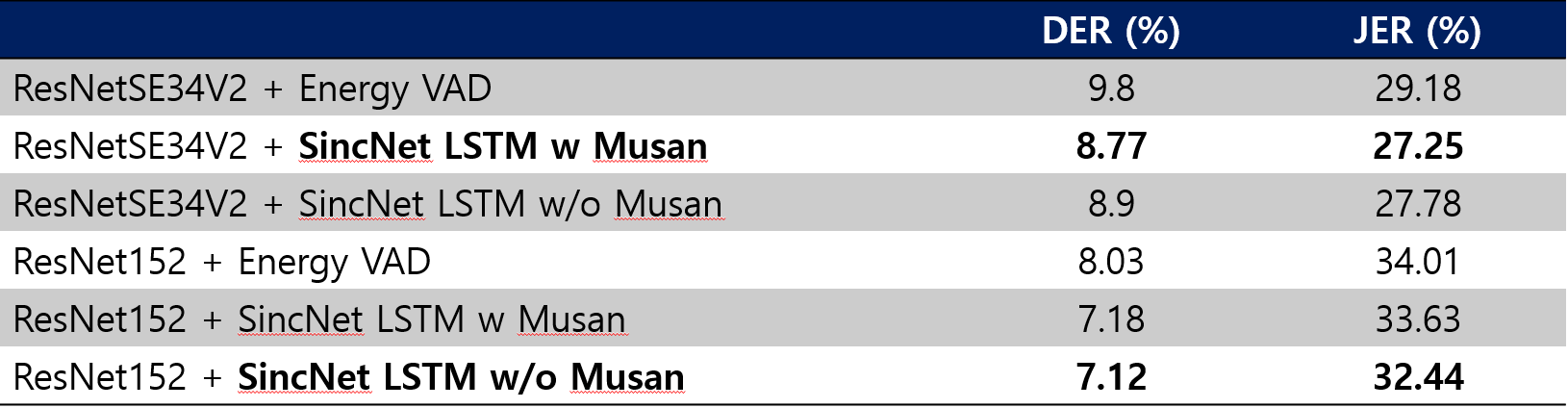
2. VAD
- 이 부분은 같은 랩실 동료인 박동건 학생이 담당해 주었습니다😎
- 기본적으로 HMM 기반의 Energy VAD 코드를 제공합니다.
- 저희는 별도로 pyannote platform 기반 SincNet-LSTM 를 이용하였습니다.
- Energy VAD로도 충분히 괜찮은 성능을 보입니다. 그냥 이걸 사용해도 나쁘지 않습니다.
- BUT 팀은 ASR에서의 시작과 끝 정보를 사용했다는 내용이 있긴 한데 저희는 시도하지 않았습니다.
- 결과적으로 음원 내에 발화(utterance)의 시작과 끝 시간을 'lab' 파일에 저장합니다.
3. Embedding - Feature Extract
- 제가 담당한 부분입니다😋
- Clustering Diarization에서 가장 흔히 사용되는 x-vector, d-vector 와 같은 deep embedding 방식입니다.
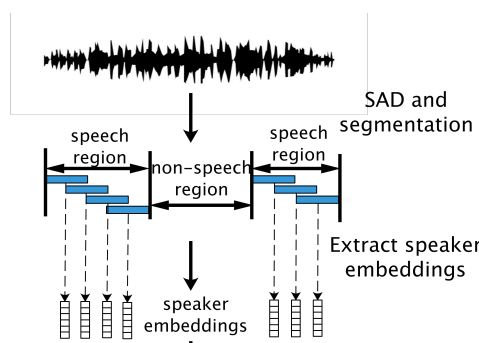
- VAD 결과로 Speech Region인 각 발화를 우선 일정한 간격으로 잘라내 Segment를 만듭니다.
- 각 발화를 화자 인식으로 학습된 모델의 입력으로 넣고 분류기(Classifier)의 전 (또는 전전) 출력 embedding 값을 입력된 시간에 대한 대표 화자 embedding으로 사용하는 방법을 말합니다.
- ref: RPNSD
- Deep Embedding 네트워크는 크게 2가지로 TDNN(Time delay neural network, 1D conv)과 ResNet(2D conv)이 존재합니다.
- 본 대회에서는 BUT 팀에서 제공하는 ResNet152 16kHz 모델을 기준으로 진행했습니다.
- NOTE💣: pytorch 버전이 맞지 않는 경우 feature extract 시 성능 문제 발생함!!
- 추가적으로 CLOVA가 제공하는 voxceleb trainer 코드와 ResNetSE34 모델을 사용하였습니다. (빠른 inference time을 이용한 빠른 후처리 튜닝이 가능하다는 점과 DIHARD III 대회에서 좋은 결과를 얻은 점에서 사용해보았습니다!)
- 구체적인 모델 Configuration은 아래와 같습니다.
(1) ResNet152
- Input feature: 64 MFCC (window size 25ms, hop size 10ms)
- Chunk size 144(1.44s), Step size 24 (0.24s)
- Embedding dim: 256
- Scoring: PLDA
(2) ResNetSE34L (Light) / ResNetSE34V2 (Large)
- Input feature: 40 / 64 MFCC (window size 25ms, hop size 10ms)
- Chunk size 144(1.44s), Step size 24 (0.24s)
- Embedding: 512
- Scoring: Cosine Similarity4. Scoring (Cosine Similarity / PLDA)
- 각 Segment 별로 생성된 Embedding을 이용해서 각 segment별로 같은 화자인지 아닌지를 분류해 내기 위한 기준(Scoring)이 필요합니다.
- 각 Segment 별로 어느정도 유사한지를 계산하기 위한 방법으로 크게 Cosine Similarity 와 PLDA를 사용합니다.
- Cosine Similarity는 가장 흔히 사용하는 방법으로 두 embedding vector 간의 각도 값을 cosine에 넣은 결과 값을 나타냅니다. 이 값은 1과 -1 사이의 값을 가지며 서로 가까울 수록 (각도가 작을 수록) 큰 값을 가집니다.
- PLDA는 각 embedding 차원 별 분포(평균, 분산)를 사전에 학습하고 이 가우시안 분포를 생성하고 이에 대한 정보를 이용하여 Scoring이 이루어 집니다. (자세한 내용은 다른 블로그 내용 참고). 각 차원별 다른 분포를 가지며 이에 따라 중요도를 다르게 주는 것으로 이해하였습니다.(정확한 이해가 아님).
- BUT 팀에서 제공한 ResNet152는 PLDA 기반으로 scoring 를 제공하였고, 별도로 진행한 ResNetSE34 와 같은 경우 Cosine Similarty를 사용했습니다.
- 각 segment 별 similarty score를 visualization 한 결과는 아래와 같습니다.
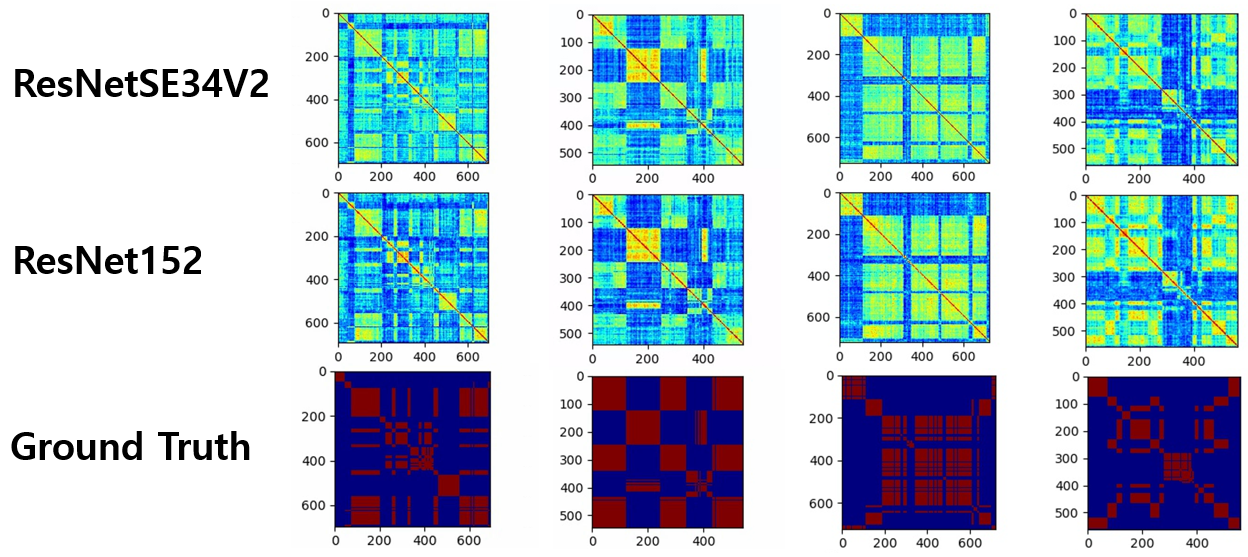
- VoxSRC20 의 test set에 대한 시각화 결과
- Scoring 관련 다른 시도들은 아래 따로 정리하도록 하겠습니다.
5. Clustering - AHC
- Segment 간의 Scoring를 통한 Affinity(distance) matrix가 생성되면, 각 화자 내에 존재하는 화자수 를 알아내야 합니다.
- 화자 분류에서는 Clustering 방법으로 AHC와 SC(Spectral Clustering)를 사용하며 BUT team은 AHC를 사용 했습니다.
- 현재 Task에서는 각 화자 수를 알아낼 수 있는 방법이 없으므로 아래 그림과 같이 적절한 Threshold값으로 화자를 분류해 내야합니다.
- 이를 찾는 것은 굉장히 heuristic 합니다. BUT team 에서는 이를 위해 affinity matrix의 energy 분포를 이용하여 적절한 threshold 값을 계산해 내는 방법을 이용했습니다. 완벽하진 않지만 고정해서 사용하는 것 보다는 안정적인 결과를 보여줍니다.
- 여기까지 되면 Speaker diarization 결과가 출력됩니다. 이후 보다 나은 결과를 위한 후처리 작업들이 이어집니다.
- Note🎁: BUT team에서 구현한 AHC 파이썬 코드보다 sklearn AHC가 속도가 빠름니다.
6. Resegmentation - VBx
- 사실 구체적인 방법은 모르지만, AHC에서 분리된 화자 결과와 PLDA 분포 값을 이용하여 화자 수를 다시 예측합니다. fa, fb, loop 3개의 변수에 대한 튜닝 작업이 필요합니다. 일반적으로 AHC에서 예측한 화자 수보다 줄어드는 것을 관찰했습니다.
- 시스템 중 가장 많은 inference time을 요구합니다 (CPU로 계산해야 하는 부분이 많음, 최적화 하기 애매했음...)
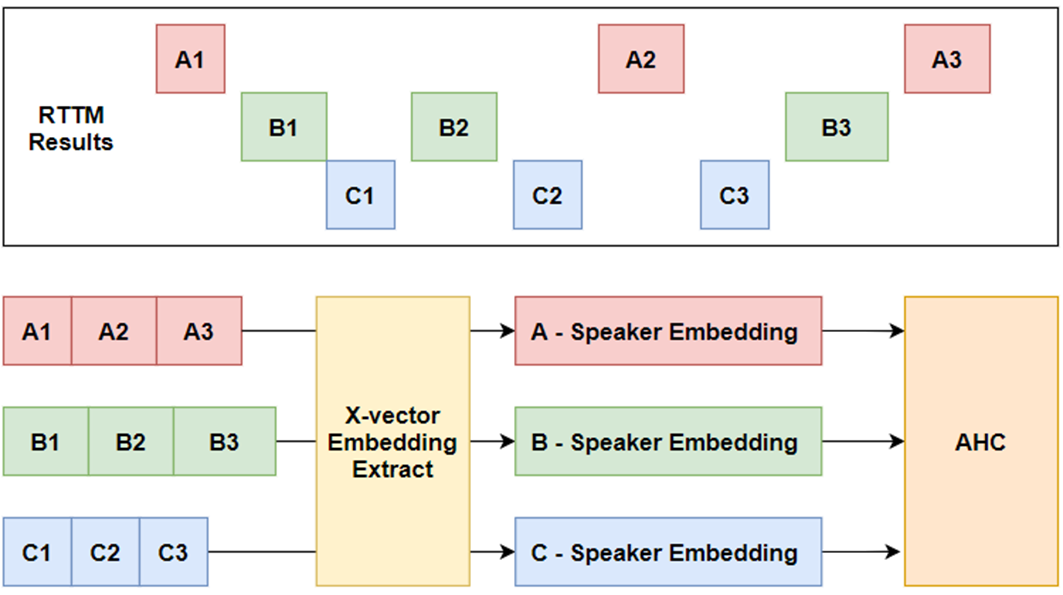
7. Reclustering
- 각 화자 발화 길이가 짧거나 noise에 의해서 화자가 잘 합쳐지지 않은 경우가 발생할 수 있습니다.
- BUT team 에서는 이를 위한 reclustering 이라는 기법을 제안합니다.
- reclustering은 Resegmentation에서 생성된 rttm 각 화자의 결과를 이용하여 각 화자별 global speaker embedding를 만들고 화자를 대표하는 speaker 들끼리 scoring/clustering 를 진행합니다.
- BUT team 에서 이를 설명하기로는, 화자 인식 시에 일반적으로 speaker diarization에서 넣어주는 입력 길이(1.44s)보다 긴 2s~4s 사이의 길이로 학습이 진행되어 화자 인식 길이와 다르다는 의견도 있으며, 개인적으로 보다 긴 화자 발화를 넣어주어 보다 일반화 된 speaker embedding를 추출하려 시도한 것으로 보입니다.
- 좋은 아이디어로 생각하고 VoxSRC20 test 데이터에 대해서는 소폭 성능 향상을 보였는데, VoxSRC21 eval 데이터에 대해서는 오히려 소폭 성능 저하를 보였습니다🤣
- Overlap assign
- 이 부분은 같은 랩실 동료인 박동건 학생이 담당해 주었습니다😎
- Clustering diarization 은 각 segment에 대한 set problem으로 정의되며 각 segment 별로 한 명의 화자로 mapping 됩니다. 즉, overlap segment를 표현하지 못합니다. 게다가, embedding 추출기는 화자인식으로 학습되어 multi-speaker embedding representation를 담당하지 못합니다.(단일 화자로 학습되었기 때문입니다.)
- 하지만, 이를 해결하지 못하면 발화 내 모든 overlap 부분에 대해 Miss Error (미탐)가 발생하게 됩니다.
- 이러한 점에서 VAD와 비슷하게 음원 내 overlap 구간를 탐지 하는 모듈을 학습한 뒤에 overlap 구역을 찾아내고 이 구간에 대한 후처리를 사용합니다.
- overlap 과 같은 경우 VAD 와 동일하게 SincNet-LSTM 네트워크 를 사용하였습니다.
- BUT team은 overlap으로 찾아낸 구역에 대한 2종류의 알고리즘을 제안합니다.
- heurstic algorithm (구체적으로 읽어보지 않고 사용만 해봄)
- 2nd label assign [1]
- 말 그래도 overlap으로 판단한 frame에 대해서 각 화자에 대한 similarty score가 존재할텐데 2번째로 높은 화자가 overlap 되었다고 할당하는 방법입니다.
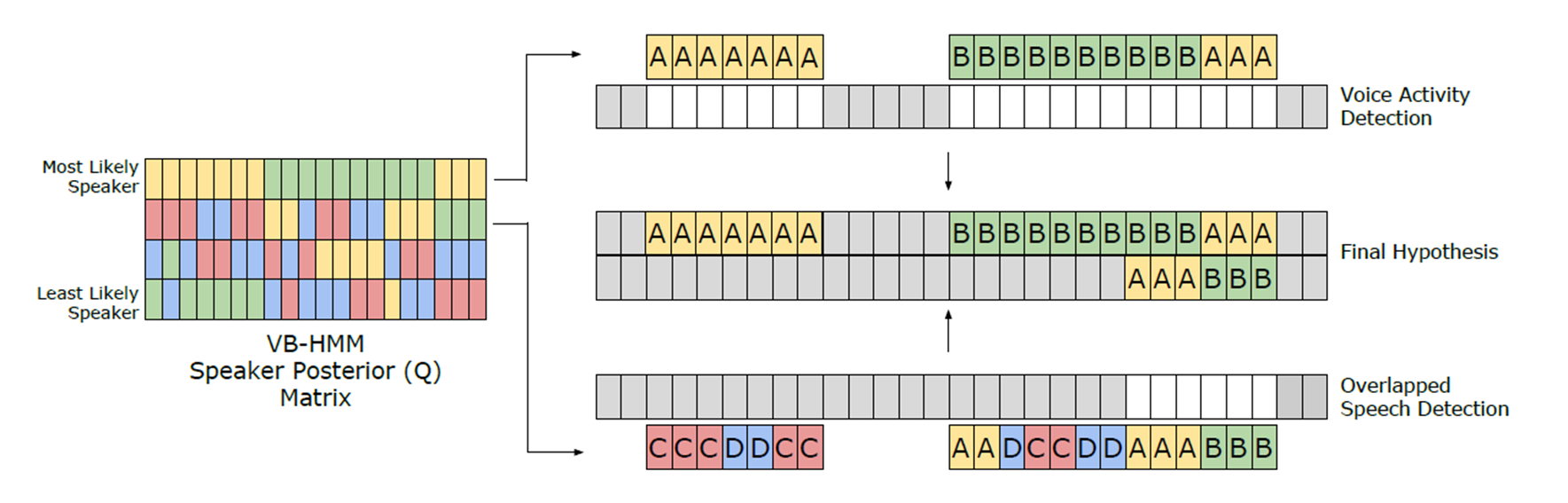
- refer: [1] overlap-aware
[1] Bullock, L., Bredin, H., & Garcia-Perera, L. P. (2020, May). Overlap-aware diarization: Resegmentation using neural end-to-end overlapped speech detection. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7114-7118). IEEE.
Baseline 결과
Speaker Enhancement & Feature Extractor 결과
- ResNet 152
- 기존 비교 실험 진행 시에 VAD는 Energy VAD로 진행하였습니다.
- Speech Enhancement가 성능에 있어서 굉장히 효과적이었습니다.
- VBx 후처리 까지 사용했을때 DER의 성능 향상을 보입니다.

- ResNetSE34
- Light (L) 버전 보다는 V2 버전이 diarization 에 있어서 훨씬 좋은 성능을 보였습니다.
- Speech Enhancement가 또한 좋은 성능 향상을 보였습니다.
- Energy 분포를 이용한 threshold 보다 고정된 best threshold가 좋은 성능을 보였습니다.

Reclustering 결과
- VoxSRC20 Test set에 대해서 소폭 성능 향상을 보였습니다.

VAD 결과
-
Training DB set
- AMI (with train, dev, eval set)
- Meeting dataset
- DIHARD I
- AMI (with train, dev, eval set)
-
Adaptation DB set
- processd using speech enhancement module for finetuning
- Training set
- VoxConverse 20 dev set 90%
- Validation set
- VoxConverse 20 dev set 10%
-
Data Augmentation
- MUSAN Noise DB
-
Network Structure
- pyannote framework 로 구현되었습니다.
- SincNet-LSTM (Baseline) [2]
- learns to detect speech from the raw speech using a combination of a SincNet [2] followed by BiLSTM layers and fully connected layers
- 1D-Conv
- 1D convolution layers and fully connected layers
- TDCN
- Motivated Speech Separation Conv-TasNet module
- Sequential of Time Dilated Convolution module
- Conformer
- Motivated Automatic Speech Recognition and our speaker diarization experiments

- Table. The performances of our SAD modules on the VoxConverse20 test set
[2] Speaker recognition from raw waveform with sincnet,” in SLT 2018
- VAD 종류 별 VoxSRC 20 test set 결과비교
overlap assign 결과
- BUT Overlap aware 결과
- overlap detection 에러인지 오히려 성능 감소를 보였다🤔

추가적인 실험😆
Improving Embedding & Scoring
- DIHARD III 대회에서 CLOVA팀은 추출된 Embedding을
Auto-Encoder로 embedding 차원을 효과적으로 줄이고Attention-based Method를 통해 noise한 성분들을 효과적으로 suppresion 시키고 성능 향상을 보였습니다. - 본 대회에서도 두 가지 방법을 그대로 적용하여 성능 향상을 노렸고 여러가지 변경에도 기존 VBx 보다 좋은 성능을 보이지 못했지만 리뷰해보자 합니다.
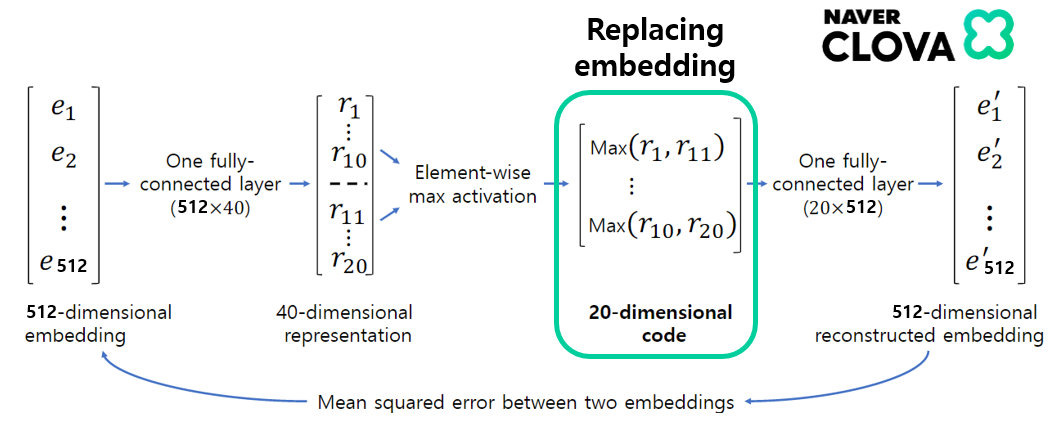
Auto Encoder
- 아래 그림과 같이 embedding dimension를 단순히 2개의 Fully-connect와 사이에 element-wise max activation를 사용하여 학습시켰습니다.
- 이후에 차원이 줄어든 20-dimension embedding를 기존 embedding 대신 사용하는 방법입니다.
- 네트워크가 복원하는데 있어서 정말 중요한 성분만 남겨 보다 잡음을 줄이려고 하는 전략입니다. 아쉽게도 본 실험에서는 Auto Encoder의 사용이 좋은 성능을 보여주지 못했습니다.
- reference
Attention-based Aggregation (ATTN AG)
- 일반적인 self-Attention 방식인데, 여기서 Temperature(T)와 Repetitions(R)를 이용하여 비슷한 embedding들의 정보들을 모아서 비슷한 embedding은 보다 가까워지도록, 애매한 거리의 embedding은 보다 멀어지도록 하는 방법입니다.
- 기존 Affinity matrix가 noisy 한 경우 AHC의 threshold 경계선을 찾기 어려운 점을 해결하고자 한 것 같습니다.
- CLOVA에서는 T=15, R=5를 사용하였는데, 어떠한 음원에서는 모든 정보를 손상시키는 것을 관찰했습니다.

Ensemble Attention-based Aggregation (ESB ATTN AG)
- 보다 안정적인 scoring enhancement 작업을 위해서 여러 temperature 상황과 repeatition 종류를 모두 사용하는 것은 어떻까? 라고 생각했습니다.
- 아래와 같이 간단히 concat 하는 방법도 있고 summation 하는 방법도 존재합니다.(둘다 비슷함)

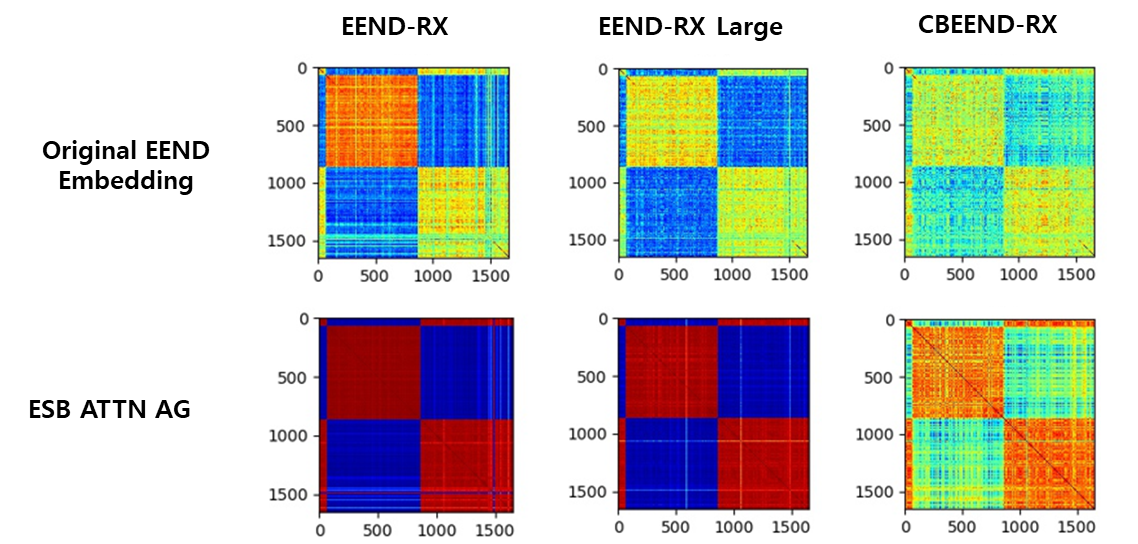
결과 비교
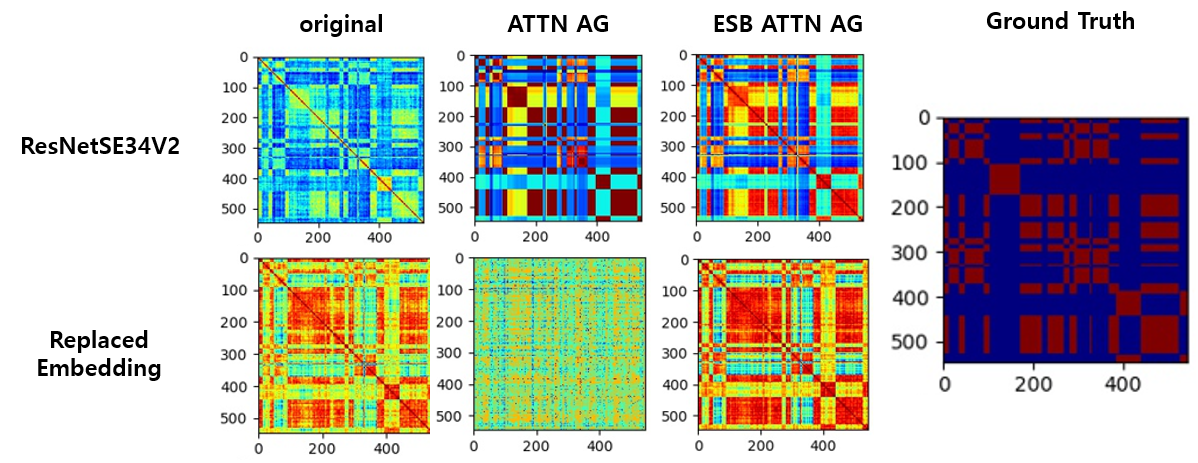
- 기존 Attinty matrix에 비해서 ATTN AG 적용시 굉장히 깔끔한 맵이 되는 것이 보입니다.
- ESB ATTN AG와 같은 경우 명확하게는 구별해 내지 않아도 어느정도 잡음이 사라지고 명확해 진 것을 확인할 수 있습니다.
- Auto Encoder (Replaced Embedding) 적용시 embedding 들 간에 전반적인 거리가 가까워 지는 것 (더 빨게짐)을 확인 할 수 있습니다.
- ATTN AG는 Temperature와 Repeat에 따라서 아래 중간 그림처럼 맵이 망가지는 현상이 발생하지만 ESB ATTN AG는 이러한 점에도 보다 안정적인 map를 보여줍니다.
- CLOVA에서는 AHC가 아닌 SC를 사용하여 본 실험에도 사용해 보았지만 아쉽게도 성능향상을 보지 못했습니다😂😂
여담
- 사실 explicit한 Attention 이 아닌 Transformer를 사용해보는 것은 어떨까? 해서 학습을 시켜보았는데 학습이 잘 되지 않았습니다.
- 다른 논문에서는 GNN으로 self-training이 잘 되었다는 이야기가 있긴 합니다.
- attention 시에 자기자신에 대해서 Cosine Similarity가 가장 높은 값을 가지는데 이것이 softmax에서 악영향을 미칠 수도 있겠다고 생각했습니다.
- 이런 점에서 softmax 값을 생성하기 전에 자기자신 값 대신 2번째로 큰 값인 나랑 가장 비슷한 embedding 간의 Cosine Similarity 값으로 Assign 하여 사용했을때 더 좋은 양상을 보였습니다. 그래도 VBx 보다는 더 좋은 성능을 보지는 못했습니다. 하😥😥
EEND Method😍
EENDasp [2]
- 이 부분은 같은 랩실 동료인 박동건 학생이 담당해 주었습니다😎
- Data loader에서 Frame selection만 제가 담당했습니다. Inference model connection과 update rule 파트는 박동건 학생이 멋지게 구현해 주셨습니다👍
- 이 블로그에 리뷰를 했습니다. 관심이 있으면! CLICK👀
- 간단하게 설명하자면 Clustering Method의 장점과 EEND의 장점을 둘다 적절하게 사용하는 방법입니다.
- Clustering Method에서의 구해진 결과 이후 EEND를 이용해서 Overlap 구간을 찾아내고 정정하는 과정을 나타냅니다.
[2] Horiguchi, S., Garcia, P., Fujita, Y., Watanabe, S., & Nagamatsu, K. (2021, June). End-to-end speaker diarization as post-processing. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7188-7192). IEEE.
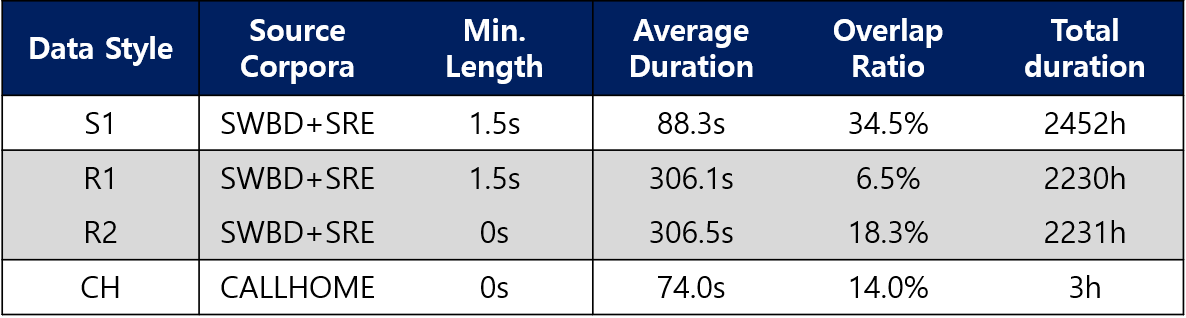
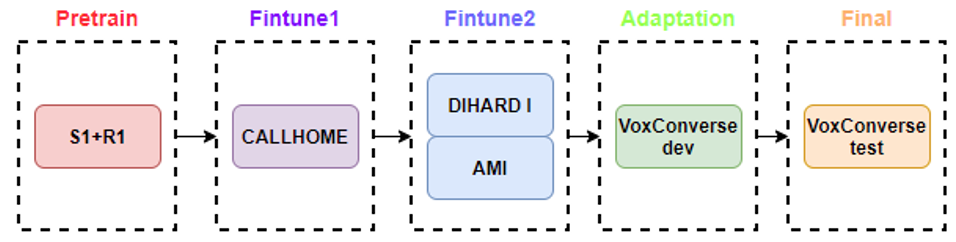
Training Dataset
- 우선 기존 SA-EEND 에서 사용하던 simulation 데이터 셋에 더해 CB-EEND에서 추가한 Real dataset인 R1 데이터를 같이 사용하여 학습을 진행했습니다.
-
Pretrain
- S1+R2
- Training to 100 epochs and averaged 91~100 epochs
- Noam scheduler 100k
-
Finetune 1
- All CALLHOME (Frame selection) is training
- Adam optimizer smaller learning rate (1e-5)
-
Finetune 2
- AMI (train+dev+eval) + DIHARD I (dev+eval) dataset
- Using frame selection
- Adam optimizer smaller learning rate (1e-5)
-
Adaptation
- VoxConverse 20 dev set (w SE)
- VoxConverse 20 dev set (w/o SE + w SE)
- Using frame selection
- Adam optimizer smaller learning rate (1e-5)
성능 평가
-
Network Archtecture
- RX-EEND : Residual + Auxiliary Loss
- CB-EEND : Conformer
- TDCN : TDCN for local feature embedding in front-end
- Large : more layers and large dimension
-
결과 분석
- CB-EEND가 simu test 셋에 대해서 굉장히 좋은 성능을 보였습니다.
- TDCN은 Real(CALLHOME) set에 대해서 조금 성능 향상을 보입니다.
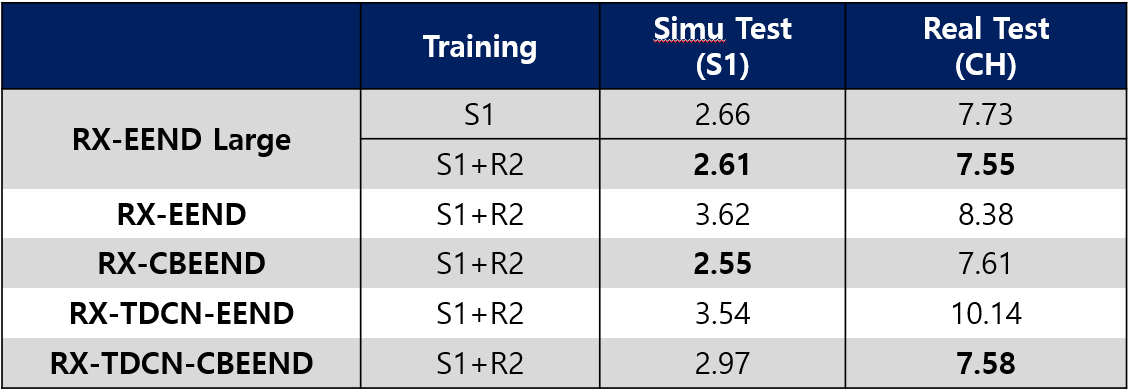
- EENDasp 최종 성능
- CB-EEND 와 RX-EEND Large가 가장 좋은 성능을 보였습니다.
- 소폭 성능 향상을 보였습니다.

EENDsplit
-
Resegmentation 방법과 같은 경우 비슷한 speaker embedding 에 대해서 합쳐주는 후처리를 적용합니다.
-
우리는 Clustering Method 가 본래 두명의 화자를 한명으로 Assign한 경우가 존재할 수 있다고 생각했습니다.
-
이러한 점에서 EEND의 입력으로 각 한 명의 VAD 영역을 입력으로 넣어주고 화자가 분리되는지를 관찰 했습니다.
-
아래 그림과 같은 경우 본래 Clustering 에서 한명으로 분류하였던 결과를 EEND에 넣었을때 아래와 같이 2명으로 구별해 내는 것을 확인했습니다.
- 이러한 부분에서 나름에 알고리즘을 설계하여 진행을 하였지만, EEND가 생성하는 False Alarm에 의한 성능 저하를 감당하지 못했습니다.
소감
진짜 대회를 진행하면서 어떻게 계획하고 시작을 할지 설계하는 것부터 해서 전반적인 시스템을 연결하고 구성하면서 shell script 도 많이 배우고 논문만 보고 알고리즘을 구현하면서 정말 많은 것을 배울 수 있었습니다. 또한 현재의 문제점을 파악하고 새로운 아이디어를 뽑아내는데 있어서 굉장한 노력, 고통과 고뇌가 필요하다는 점을 다시금 느꼈던거 같았습니다.🤣 새로운 아이디어를 제안하고 구현하고 결과를 기다리고 계속 실패하면서 많이 지치고 힘들었지만 자신의 생각을 검증하고 어떻게 나올지 기대하는 과정이 나름 재밋었습니다. 시스템도 처음에 시간적인 최적화가 많이 필요해서 많이 수정하고 고생도 하고 했지만 덕분에 많이 배우는 계기가 된거 같습니다.
이후에 2021년 9월 이후에 화자 분류(SD)와 인식(SV)에 있어서도 많은 변화들이 생기고 있는데 다음 참가때에는 ResNet 모델이 아닌 RawNet이 또는 ViT 기반에 SV 모델을 직접 학습하여 Backbone으로 사용하고 이후에 Speaker Diarization을 위한 DiFormer 사용할 준비중에 있습니다. EEND와 같은 경우에도 EEND-vector-clustering과 같이 inter-block permutation problem을 해결한 사래도 존재하기에 (이 모델도 이미 학습해놓았음🥰) 다음에 적용해볼 생각이 있습니다.
마지막으로, 항상 무엇을 맡기든 걱정 없는 박동건 학생과 선뜻 도와달라고 한 말에 쿨하게 도와준 박경완 학생에게 깊은 감사를 올리며 마무리하겠습니다.
올해도 열리면 나가자! 😎 다들 화이팅!

안녕하세요!! 저는 VoxSRC21 committee로 활동했던 허재성이라고 합니다. 포스트 정말 잘 읽었습니다. 이번년도도 높은 확률로 speaker diarisation track이 열릴거 같으니 관심 부탁드려요 ㅎㅎ