DataFrame, Series의 정렬 - sort_values()
주요 파라미터 : by, ascending, inplace
- by : 특정 칼럼을 입력하면 해당 칼럼으로 정렬을 수행함.
- ascending : True로 설정하면 오름차순, False면 내림차순, 기본은 True
- inplace : False로 설정하면 sort_values()를 호출한 DataFrame 그대로 유지, True면 정렬 결과를 그대로 적용, 기본은 False
titanic_sorted = titanic_df.sort_values(by=['Pclass', 'Name'], ascending=False)
titanic_sorted.head(10)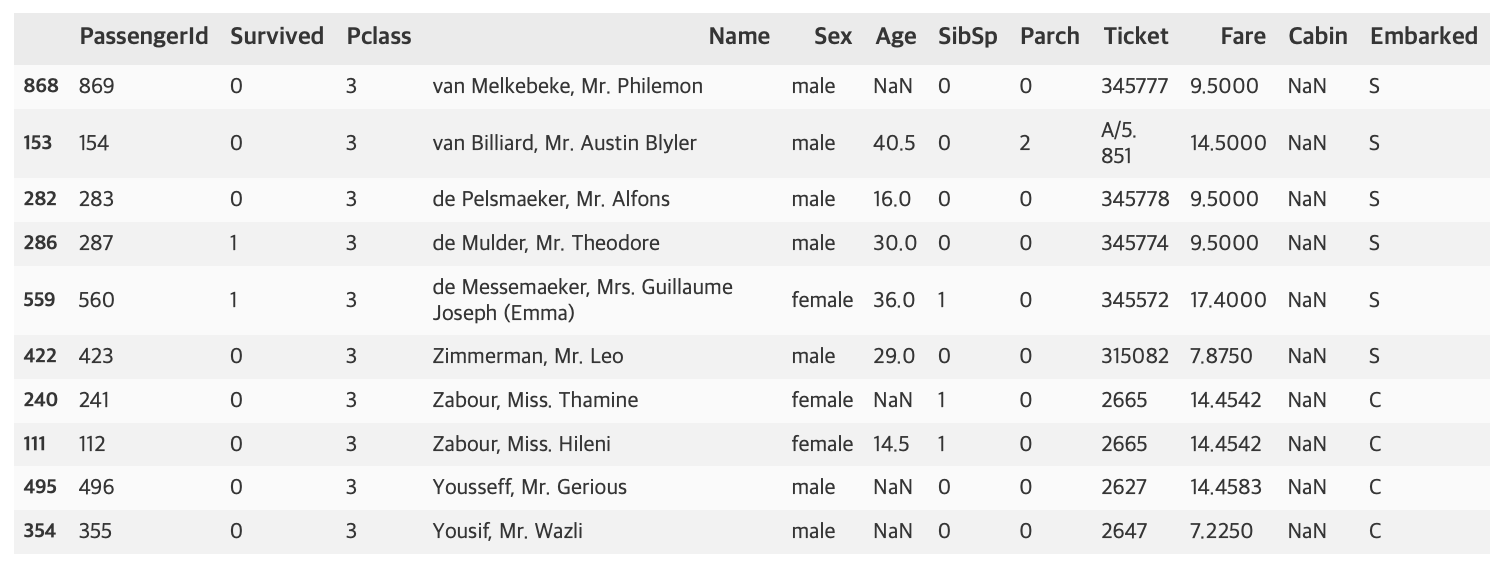
Pclass로 먼저 정렬한 후 만약 Pclass가 동일하다면 Name을 차순위로 정렬한다. ascending=False이므로 내림차순으로 정렬이다.
Aggeregation 함수 적용
count
titanic_df.count()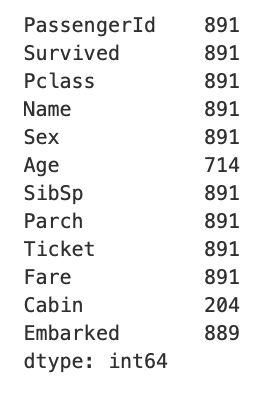
mean
titanic_df[['Age', 'Fare']].mean()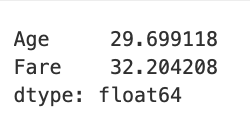
groupby 적용
titanic_groupby = titanic_df.groupby(by='Pclass')
print(type(titanic_groupby))[Output]
<class 'pandas.core.groupby.generic.DataFrameGroupBy'>
이렇게 친절하게 DataFrameGroupBy라고 나타난다.
titanic_groupby = titanic_df.groupby(by='Pclass').count()
titanic_groupby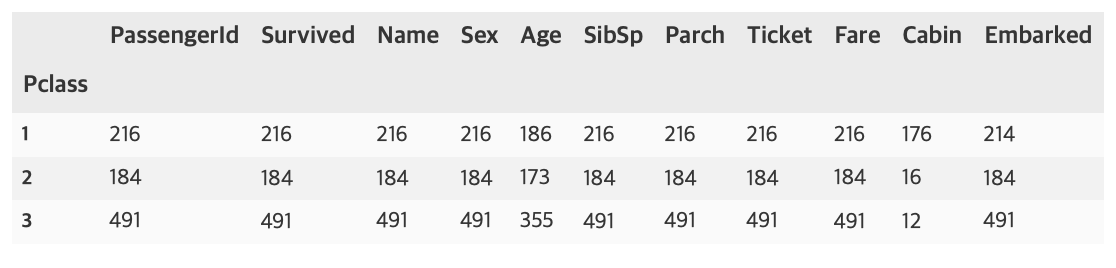
이렇게 Pclass별로 count도 가능하다.
agg_format = {'Age':'max', 'SibSp':'sum', 'Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)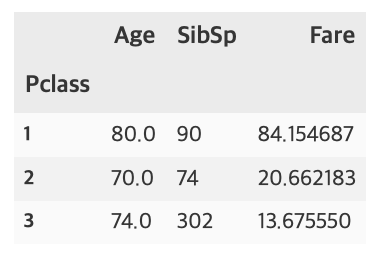
aggeregation함수와 응용해서 사용할 수도 있다.
Source: 파이썬 머신러닝 완벽 가이드 / 위키북스

데이터 분석 공부용 벨로그