추천시스템의 종류
1. Collaborative Filtering
□ 메모리 기반 접근 (Neighborhood-based)
□ 모델 기반 접근 Explicit
☑ 모델 기반 접근 Implicit, MF-based
□ 모델 기반 접근 Implicit, Metric / Deep learning-based
2. Side Information-based Recommendation
□ 컨텐츠 기반 추천
□ 컨텐츠 기반 Collaborative Filtering
Implicit Feedback의 Model-based 접근
이제 Explicit Feedback이 아닌, Implicit Feedback을 추천 알고리즘을 만들어보자. 실제 경우를 생각해보면 사람들은 '점수에 대한 예측'보다는 '추천 목록 그 자체'에 더 많은 관심을 갖고 있다. 따라서 이번 챕터는 Implicit Feedback 데이터를 통해 랭킹을 만드는 모델을 구축하는 것을 목표로 한다.
1. MF-based
랭킹을 만들기 위해서는 어떻게 해야 할까? 우선 유저 의 아이템 에 대한 점수를 예측함으로써 그 점수를 기반으로 줄을 세우는 방법을 생각할 수 있다 (이 방법은 Pointwise 방법). 하지만 점수를 일일히 계산하기 보다, 그냥 랭킹을 바로 학습할 수는 없을까? 이 문제는 loss의 종류에 따라 Classification의 일종으로 생각할 수 있다.
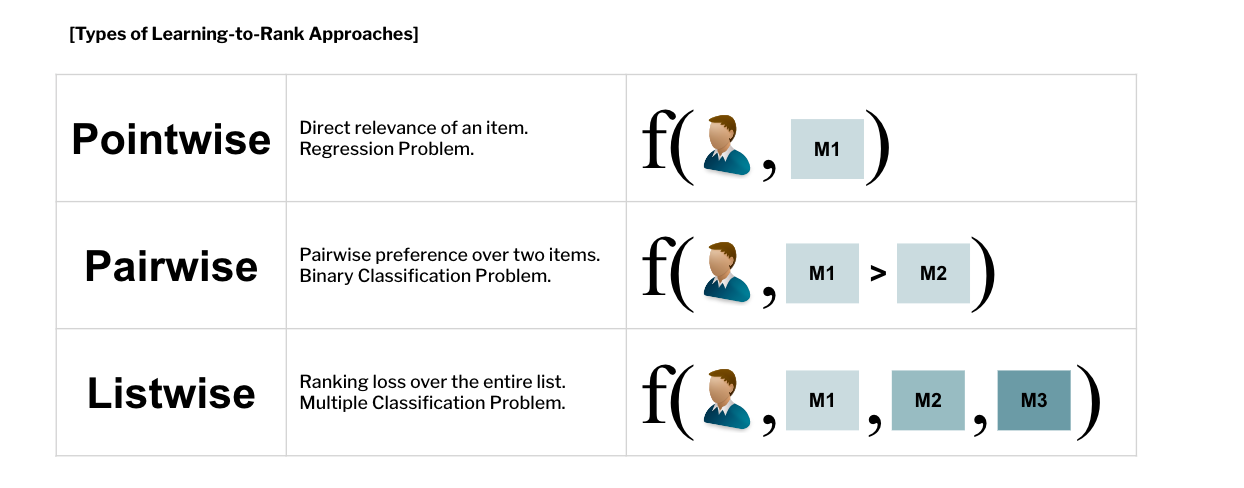
(1) Pointwise, One Class Collaborative Filtering
Pointwise 방법은 하나의 유저, 하나의 아이템을 기본 단위로 loss를 계산한다. 위에서 다뤘던 MF, SVD++, PMF와 같은 맥락이다. 이 꼭지에서 소개할 방법은 One Class Collaborative Filtering으로, 관측된 유저행동에 confidence 개념을 도입한다.
- : 유저 가 아이템 를 소비했다면 , 는 를 선호한다.
- : 유저 가 아이템 를 소비한적이 없다면, 선호도가 없다고 가정한다.
- 단순 0과 1로 분리해 생각하는 것에서 나아가 아이템을 소비한 횟수인 Confidence Level을 반영한다.
- 이전의 Explicit Feedback 모델들과 달리, 관측된 데이터와 아닌데이터 모두를 반영해 계산한다.
때문에 최적화 과정에서 SDG를 쓰지 않고 ALS(Alternating Least Squares)를 사용한다.
Loss Fucntion
Confidence on interaction :
Alternating Least Squares
[Hu, Yifan, Yehuda Koren, and Chris Volinsky. "Collaborative filtering for implicit feedback datasets." ICDM 2018]
[Pan, Rong, et al. "One-class collaborative filtering." 2008 Eighth IEEE International Conference on Data Mining. ICDM 2018]
(2) Pairwise, BPR
이번엔 한 유저가 소비한 두 아이템의 쌍을 기본 단위로 loss를 계산하는 Pairwise 방법인 BPR이다 (Bayesian Personalized Ranking from Implicit Feedback, Rendle, Steffen, et al.(2009)). 이 방법의 기본 전제는 '경험한 아이템이 아직 경험하지 못한 아이템보다 선호도가 높다' 다.
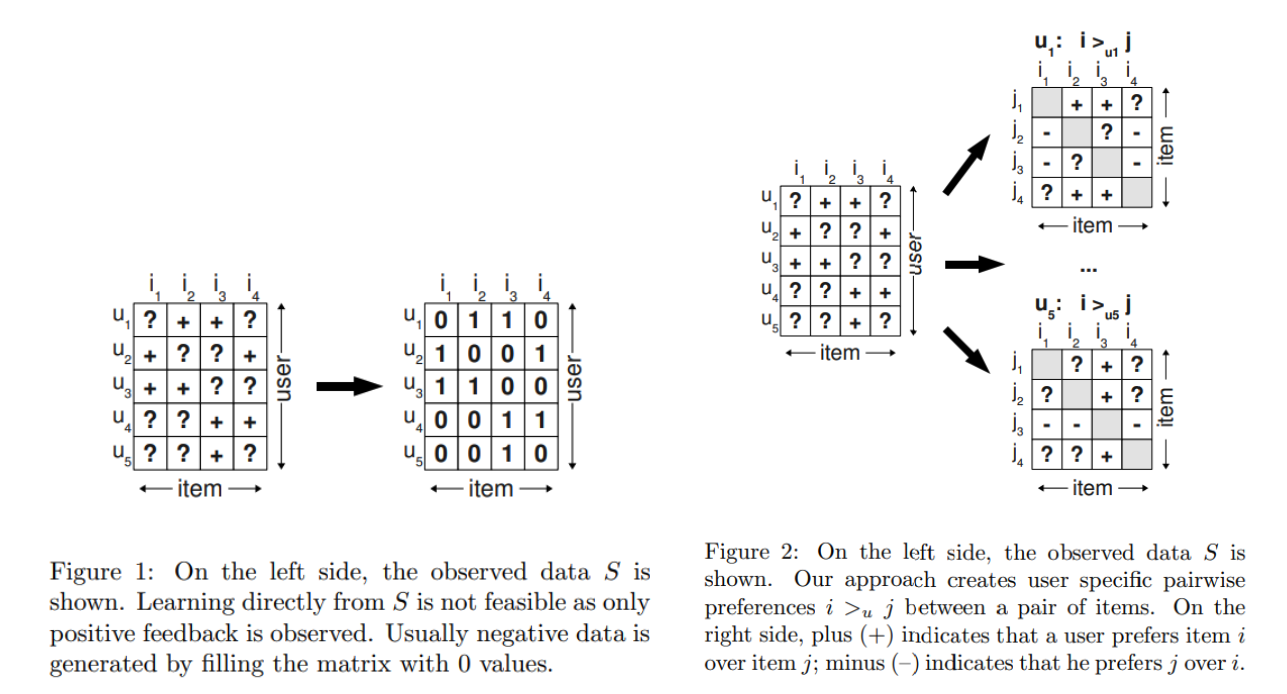
기존 Implicit 데이터를 처리하는 방식은 0과 1로 지나치게 단순화 되어 있었던 반면, 이 방법에서는 경험하지 않은 데이터에도 선호 강도를 반영할 수 있게 한 점이 특징이다. 아래 그림의 첫번째 이미지의 각 박스는 유저 가 아이템의 경험여부를 담고 있다. 아예 경험하지 못한 아이템은 '?'처리 되어 있다. 각 유저별로 뜯어 살펴보면 그 다음 이미지와 같은 방식으로 해석될 수 있다. Column의 는 Row 보다 선호하는 아이템이다. 가령 은 보다 를 좋아한다는 것을 알 수 있다. 각 행렬에는 선호도에 대한 상대적인 +-가 담겨 있고, 모든 유저에 대한 해당 데이터를 라 한다. 알고리즘은 를 학습하는 것이다.
이를 바탕으로 만든 목적함수는 선호하는 아이템 의 예측값과 선호하지 않는 아이템 의 예측값의 차이를 최대화 하는 값을 찾는 것을 목표로 한다.
Loss Fucntion
이 케이스에서
Notation
| Variable | Note |
|---|---|
| 유저 u에 대한 모든 +-쌍 | |
| 로지스틱 함수 | |
| 모델 파라미터 | |
| 유저 u의 아이템 i에 대한 예측 |
[Rendle, Steffen, et al. "BPR: Bayesian personalized ranking from implicit feedback." UAI 2009]
(3.1) Listwise, List-wise Learning to Rank with MF for CF
Listwise 방법은 한 유저와 전체 유저와의 관계를 기본 단위로 loss를 계산한다. 이때 사용되는 loss는 Cross Entroy()로, 실제 유저 평점의 확률분포와, 예측 평점의 확률분포의 차이를 계산한다. 평점이 존재하는 데이터에 한해 계산하므로 SGD를 사용하며, 평점이 존재하는 데이터들을 편의상 리스트라 부르겠다.
Loss Function
가 리스트에 존재할 확률 :
(3.2) Listwise, CLIMF
또 다른 Listwise 방법으로는 Implicit Feedback 평가지표 가운데 하나인 MRR(Mean Reciprocal Rank)을 직접적으로 최대화 하는 방법이 있다. RR은 적절한 아이템이 추천된 순위의 역수다. 따라서 추천이 적절할수록 값이 커지므로 MRR을 최대화 하는 것이다.
Loss Function
: 유저 에게 아이템가 적절성 (적절하다면 1, 아니면 0)
: 유저 에게 추천된 리스트에서 아이템 의 랭킹
RR은 Indicator Function ()으로 인해 불연속적인 함수다. 따라서 SGD 적용이 어렵다는 점이 있다.
Apporximation
