관련 논문 링크
Separating the "Chirp" from the "Chat" 논문 링크
T-VSL 논문 링크
MIMOSA 논문 링크
1. T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
2024 CVPR
Video Sound Source Localization 기존 방법
소리와 영상 간의 관계(audio-visual correspondence)를 이용하는데, 여러 소리가 섞이면 성능이 저하되어 각 소리가 나는 물체의 위치를 정확하게 구분하는 데 어려움
(모델이 각각의 소리 나는 source를 구별하고, 개별 소리 source 없이도 cross modal 연관성을 학습하지 못해서 성능이 떨어짐)
논문에서의 해결 방법
이 논문은 소리와 영상외에도 텍스트를 새로운 가이드로 추가하여 이 문제를 해결함, AudioCLIP이라는 모델을 이용하여 소리, 영상, 텍스트를 함께 학습함
여러 소리가 섞인 상태에서 어떤 소리들이 나는지 예측한 후, 각 소리나는 물체에 해당하는 텍스트를 사용하여 소리와 영상의 관계를 더 명확하게 구분함
=> 좀 더 구체적으로 설명하자면
text modality를 사용하여 혼합물에서 범주별 오디오-비주얼 대응을 분리하는 것 (오디오와 비주얼은 잡음이 많을 수 있지만, 텍스트는 명확하게 구분됨)
여기서 어려움은 오디오 및 시각적 특징을 텍스트와 일치시키는 것임
AudioCLIP의 삼중 모달 임베딩 공간(tri-modal joint embedding space)을 활용하여 일대일 오디오-비주얼 대응 분리함
과정
- AudioCLIP 모델 사용해서 비디오에서 이미지와 소리 정보를 받아 소리나는 물체가 무엇인지를 찾아냄(ex.피아노, 드럼)
- 이 물체의 정보를 텍스트로 변환함
- 텍스트를 활용하여 각 소리 나는 물체에 해당하는 소리와 이미지 정보를 분리함
- 소리와 이미지 정보를 다시 맞춰서 비디오 정확히 어디에서 소리가 나는지 찾음
즉, T-VSL 방법은 다양한 소리의 개수에도 유연하게 대응, 학습하지 않은 새로운 종류의 소리에도 zero-shot 방식으로 잘 대응함
Method
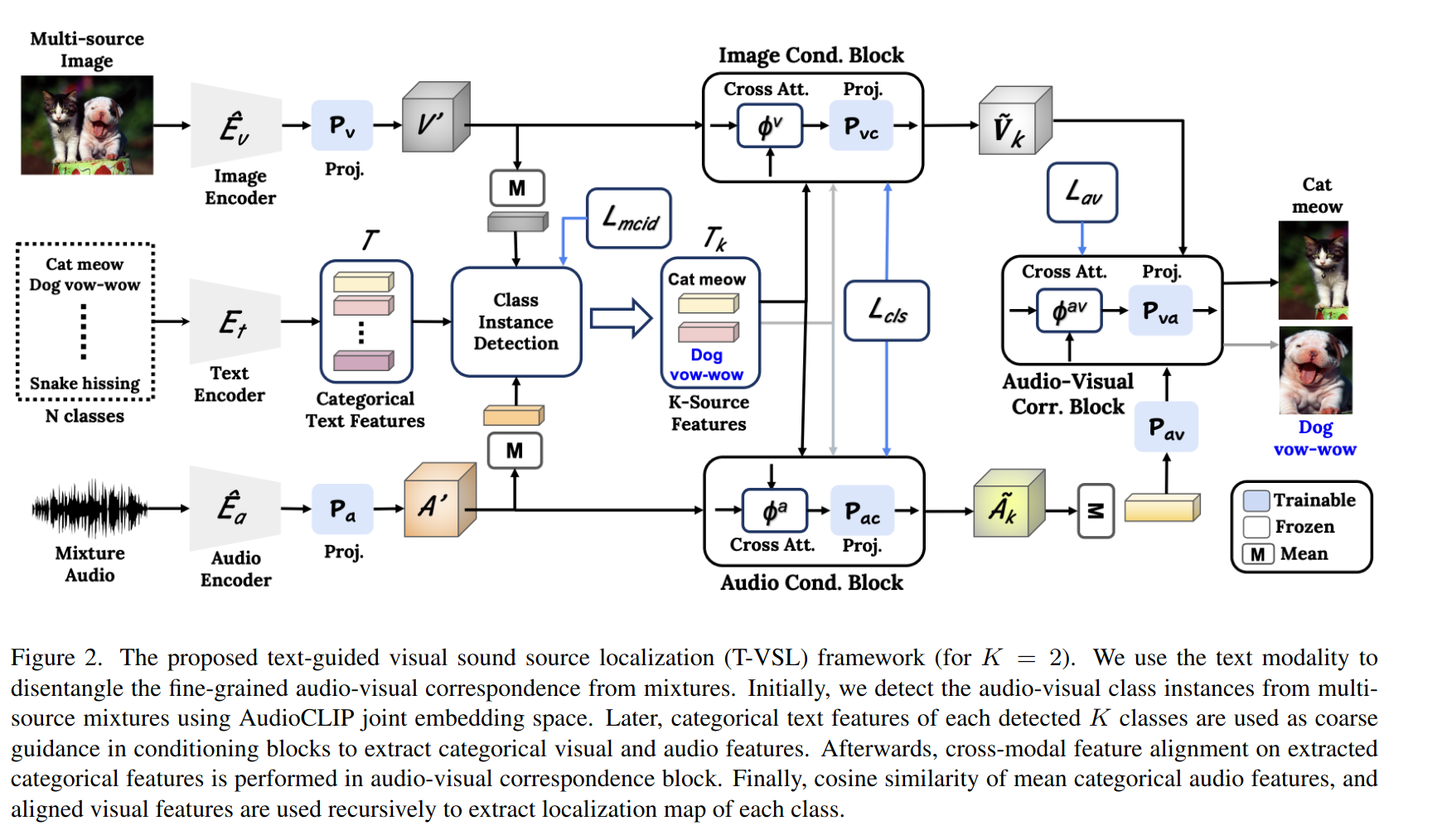
AudioCLIP의 encoder를 이용하여 여러개의 물체 중에서 소리가 나는 k개의 물체를 찾음
(단일 source 샘플 없이 각각의 source에 대해 일대일 오디오-비주얼 대응을 찾아내야함)
text를 이용해 k개의 소리 나는 물체에 대한 표현 생성
AudioCLIP의 다중 모달 기능을 통해 각 소리 나는 오디오 및 시각적 특징 추출
각 소리 나는 물체의 오디오 특징과 일치된 시각적 특징의 코사인 유사도를 계산해 semantic localization map 생성함
Evaluation
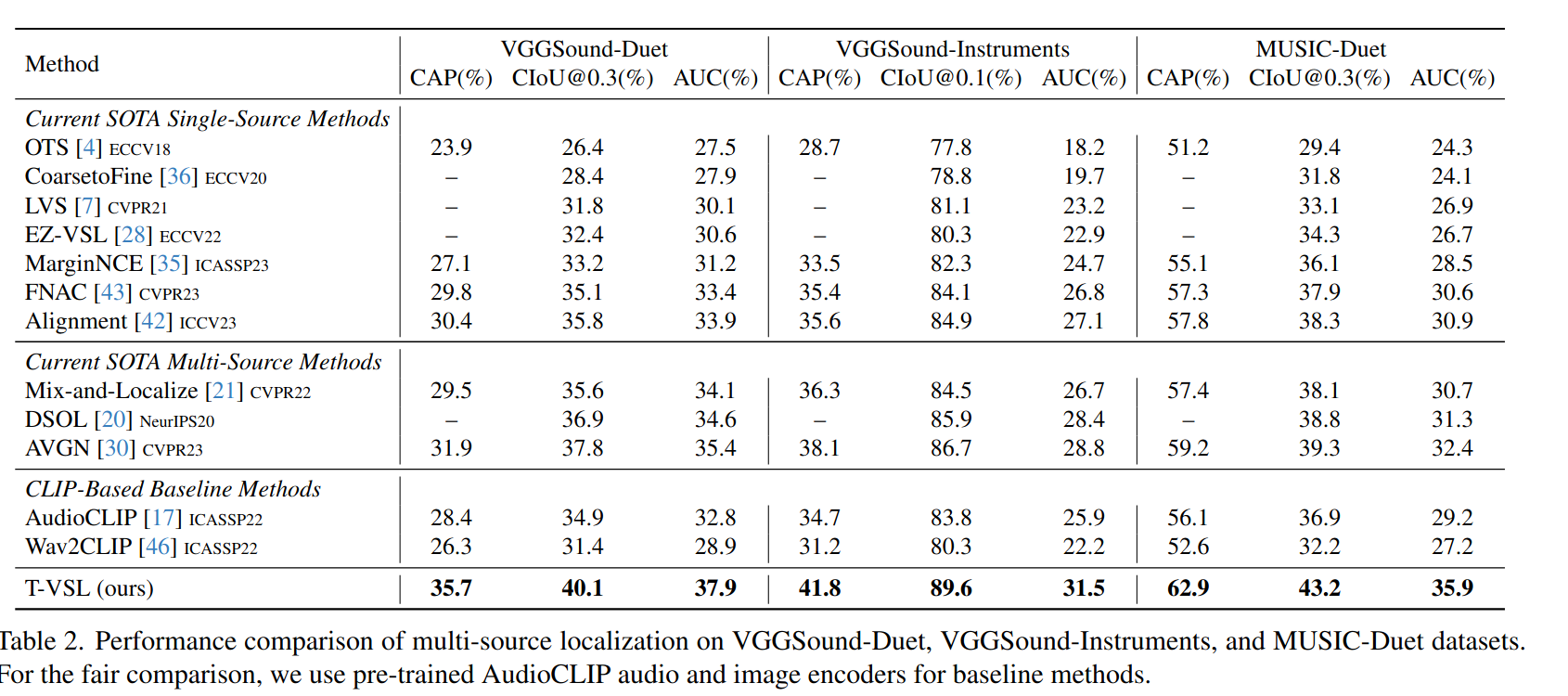
단일 source 위치 추정은 Intersection over Union(IoU), Average Precision(AP), Area Under Curve(AUC)을 사용
다중 source 위치 추정은 Class-aware Average Precision(CAP), Class-aware IoU(CIoU), AUC를 사용
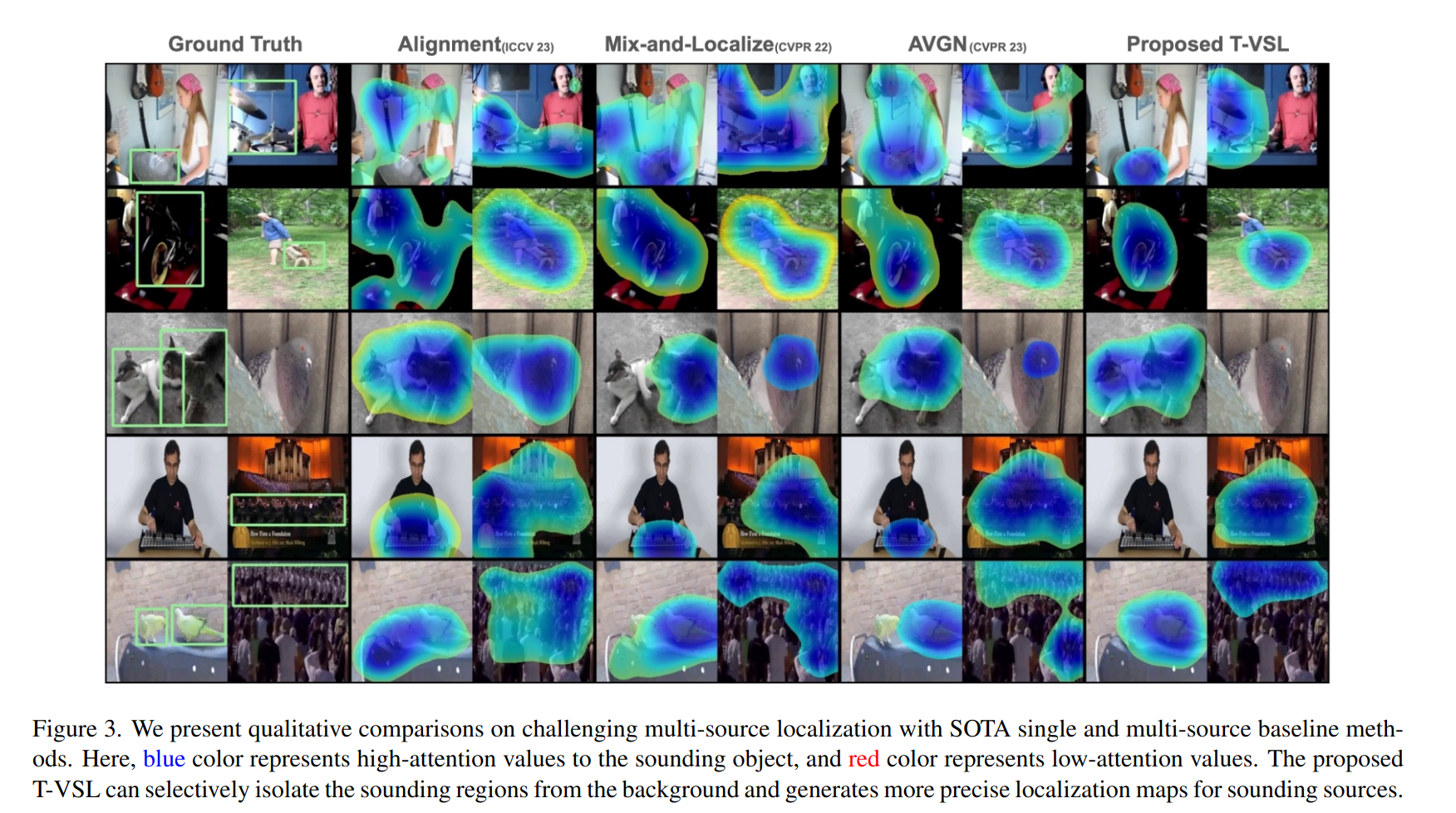
Multi-source 특징을 잘 분리하는 localization map을 만듦
2. MIMOSA: Human-AI Co-Creation of Computational Spatial Audio Effects on Videos
간단 정리
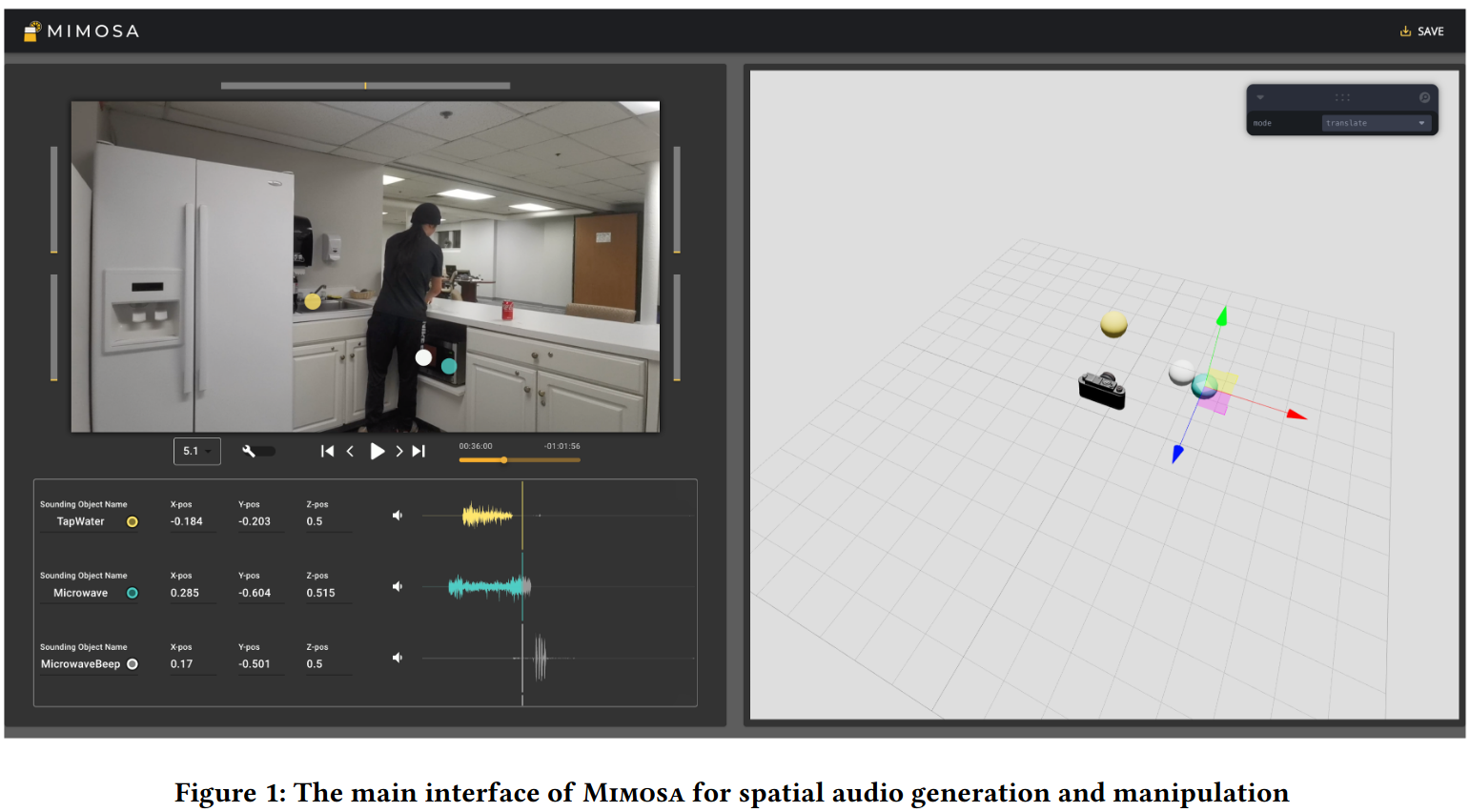
Mimosa는 일반 비디오에 몰입감 있는 spatial 오디오 효과를 생성할 수 있도록 돕는 Human-AI 협업 도구
이는 end-to-end 블랙박스 기계 학습 접근 방식을 사용하기 보다는 객체 탐지, 깊이 추정, 사운드 트랙 분리, 오디오 태깅 등으로 구성된 pipeline을 사용함
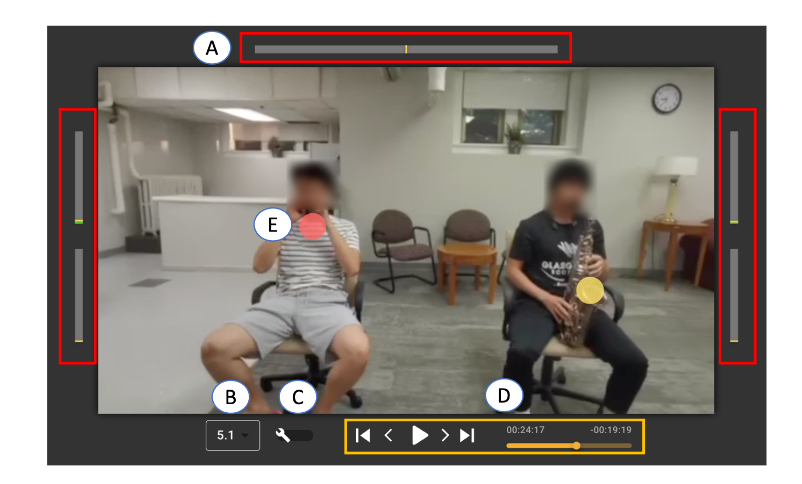
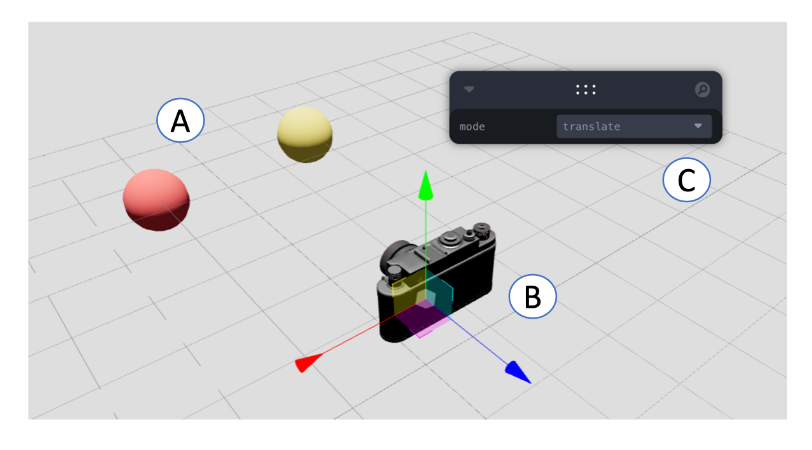
Mimosa는 비디오에서 소리가 나는 물체를 찾아 그 위치를 3D 공간에서 추정할 수 있음
과정
비디오의 각 프레임에서 객체 탐지-> 깊이 맵 사용하여 물체의 3D 위치 계산-> 소리와 물체를 연결해서 소리가 나는 위치를 시각적으로 매칭함
피드백
- multisource의 논문들 independent하게도 어려운데 dependent하게 해보자
- 비슷한 논문 있는지 찾아볼것 (손뼉이 마주쳐야지 소리가 남)
- Audio clip의 소리 annotation이 뭔지(물체 그 자체 인지, 확장된 구 인지)
- tutorial 공부하기
