
벡터 스토어란?
LangChain은 초거대언어모델(LLM)을 쉽게 활용할 수 있도록 돕는 프레임워크다. 챗GPT, Meta의 LLaMA 등 다양한 LLM에 적용할 수 있으며, 대표적으로 로컬 DB로는 faiss나 chromadb가 클라우드 네이티브로는 pinecone 같은 벡터 데이터베이스를 활용해 정보를 효율적으로 저장하고 조회한다.
벡터 스토어는 비정형 데이터를 고차원 벡터로 변환해 저장하고, 벡터 간 유사도를 기반으로 데이터를 빠르게 조회하는 데이터베이스다. 기존의 관계형 데이터베이스(RDBMS)와는 달리 이미지, 텍스트 등의 비정형 데이터를 효과적으로 처리할 수 있다. 이들은 자연어 처리나 추천 시스템 등에서 널리 사용되며, 벡터 간의 유사도나 거리를 기반으로 데이터를 검색한다.
임베딩(Embedding)과 벡터 스토어
임베딩은 텍스트나 이미지를 고차원 벡터로 변환하는 과정이다. Word2Vec, GloVe, FastText 같은 알고리즘을 사용해 단어나 문장을 벡터로 변환하며, 유사한 의미의 단어나 문장은 벡터 공간에서 가까운 위치에 위치한다.
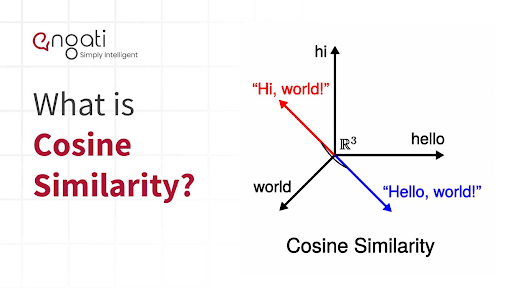
코사인 유사도는 두 벡터 간의 유사도를 측정할 때 많이 사용되는 방법으로, 특히, 자연어 처리 분야에서 텍스트의 임베딩 벡터 간의 유사도를 측정할 때 자주 활용된다. 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다. 두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖기 때문이다.
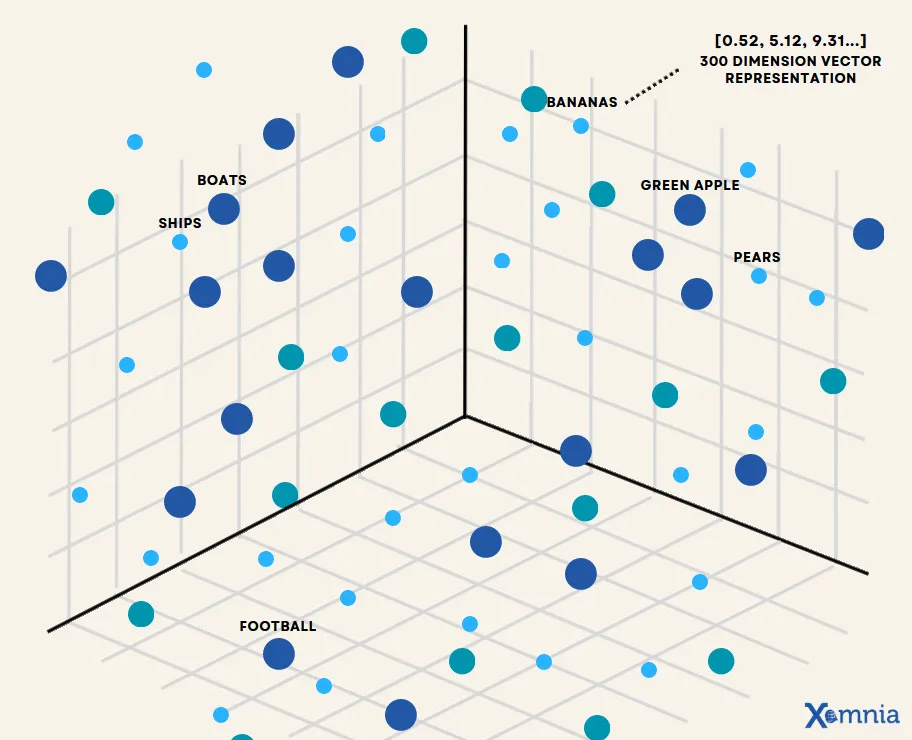
예를 들자면 “Green Apple” 이라는 단어를 임베딩 작업 이후 코사인 유사도 검색을 실행할 경우 “apple”, “pears” 과 같이 유사함의 척도가 가장 높은 Top-K값에 따라 결과 값을 조회할 수 있다
벡터 저장소의 종류
벡터 저장소는 Faiss(Facebook AI Similarity Search), Chroma, Elasticsearch, Pinecone 등 다양한 오픈 소스 및 상용 솔루션이 있으며, 각각의 특성과 성능이 다르기 때문에 사용 목적에 따라 적합한 도구를 선택해야 한다.
| 벡터 저장소 | 장점 | 단점 |
|---|---|---|
| Pinecone | - 관리형 서비스로 설정이 쉬움- 높은 확장성 및 안정성 제공- 빠른 검색 속도 | - 유료 서비스로 비용 발생- 완전한 On-premise 배포 불가능 |
| Chroma | - 오픈소스 & 로컬 실행 가능- 간단한 Python API 지원- LangChain 등과의 좋은 통합성 | - 대규모 데이터에서 성능 저하 가능- 클러스터링 및 분산 처리 기능 부족 |
| FAISS | - Facebook AI가 개발한 고성능 라이브러리- GPU 가속 지원- 대용량 데이터에서 우수한 성능 | - 실시간 삽입/삭제 기능 부족- 클러스터링 기능이 없어 대규모 확장 어려움 |
| Weaviate | - 실시간 검색 & 메타데이터 필터링 지원- 클라우드 및 자체 호스팅 지원- 그래프 기반 검색 기능 제공 | - 설정이 복잡하고 러닝커브 있음- 작은 데이터셋에서 오버헤드 발생 |
결론
- Pinecone: 관리형 서비스가 필요하고 빠른 배포를 원한다면.
- Chroma: 로컬에서 간단한 AI 앱을 구축할 때.
- FAISS: GPU 가속을 활용한 대용량 벡터 검색에 적합.
- Weaviate: 메타데이터 필터링과 실시간 검색이 필요한 경우.
Reference:
