파인튜닝을 시도해보니 Raw데이터 정제에 너무 많은 리소스가 들어가고 있으며
그마저도 잘 되지 않는 것이 사실이였다.
Redis나 Java 정보와 같이 내가 학습시키려는 데이터와 공통적으로 가지고 있는 데이터에 비해 학습 데이터가 너무 적기 때문에 AI모델의 생성에 영향을 미치지 못하기도 하고
도메인 특화 또는 업무와 관련된 private한 데이터의 경우 질문할 경우 LLM의 고질적인 문제인 Hallucination이 발생하기도 했다.
이를 위해서는 AI가 알아듣기 쉽고 정확하게 데이터를 정제해야 했는데 문서마다 형식이 다르고 이를 일련의 Text형식으로 질의-답변의 포맷으로 정제하는 것이 쉽지 않았다
어쩌면 파인튜닝을 통해 GPT에게 학습시키는 것이 아닌 문서 그 자체를 유저에게 전달하면 어떨까 하는 꼼수를 고민 하던 무렵 발견한 것은 바로…
RAG(Retrieval Augmented Generation, 검색 증강 생성)
LLM의 문제와 파인튜닝의 단점을 보완하기 위한 고민은 이미 수많은 석박사들 선생님들이 해왔고
이 과정에서 탄생한 것이 RAG 아키텍쳐이다
아래의 RAG 아키텍쳐를 살펴보며 프로세스를 이해해보자면
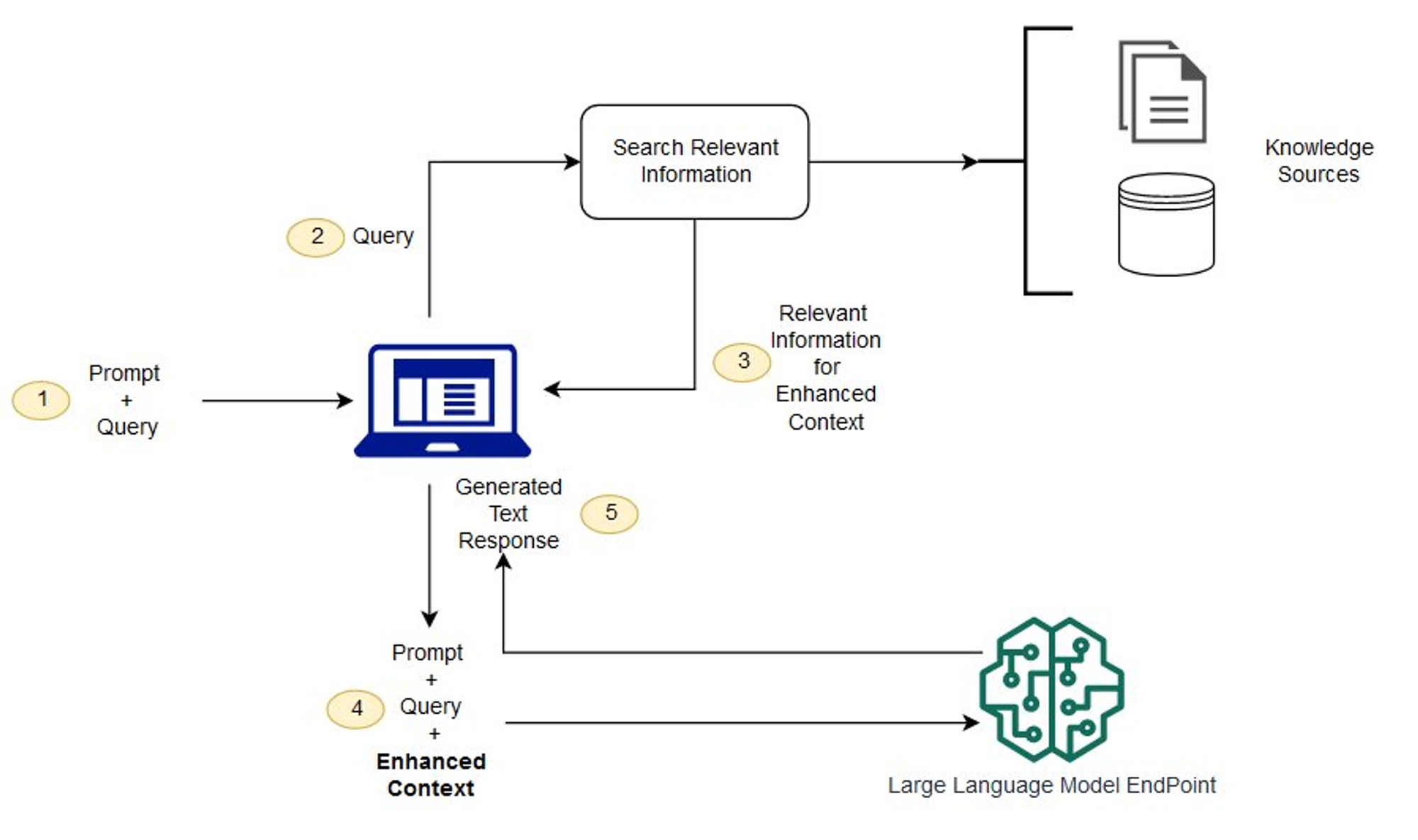
- 사용자가 질문을 보냅니다. 이 정보는 Prompt와 함께 시스템에 전달됩니다.
- 시스템은 질문과 가장 관련성이 높은(그래서 답을 가지고 있을 것 같은) 정보(문서, 데이터 덩어리 등)를 검색하고 꺼냅니다(Retrieval).
- 시스템은 기존 Prompt에 앞에서 찾은 정보를 추가(Augmented)합니다.
- 시스템은 이렇게 보강된 Prompt를 LLM에게 보냅니다.
- LLM은 사용자 질문과 관련된 정보를 고려해 답을 생성합니다.
쉽게 비유하자면 GPT는 도서관의 사서라고 생각하고 사용자가 질문하면 문서를 열람하여 답변해주는 것 이라고 생각하면 이해가 빠를 것..!
파인튜닝과 비교했을 때의 장점은 다음과 같다
- 데이터 효율성: 파인튜닝은 모델을 특정 작업에 맞게 조정하기 위해 대량의 데이터를 필요로 한다. 반면 RAG(Realm Augmented Generation)는 사전 학습된 모델과 검색 인덱스를 사용하여 필요한 정보만을 가져와 사용하는 방식으로, 적은 양의 데이터로도 효과적인 성능을 발휘한다
- 다양한 정보 제공: 파인튜닝된 모델은 학습된 데이터에만 의존하여 답변을 생성하지만, RAG는 검색 엔진을 통해 다양한 정보 출처에서 필요한 정보를 실시간으로 가져와 보다 정확하고 풍부한 답변을 제공한다
- 유연성: 파인튜닝된 모델은 특정 도메인에 강점이 있지만, 새로운 도메인에 대해 다시 파인튜닝이 필요하다 (비용문제로 연결됨). 반면 RAG는 검색 인덱스를 갱신함으로써 다양한 도메인에 대해 유연하게 대응할 수 있다
- 시간 및 비용 절감: 파인튜닝 과정은 시간과 비용이 많이 소요되지만, RAG는 이러한 과정을 줄이고 더 빠르게 결과를 얻을 수 있다
RAG를 구현하기 위한 단계들
- 데이터
- 도메인 또는 특정 데이터 수집 및 전처리 작업
- 검색 인덱스
- 벡터DB라고도함 Elastic, FAISS, Finecone, Chroma 등등
- 사전 학습된 언어 모델
- GPT, CLOVA, Claude등등
- 검색 및 생성 통합
- 검색 엔진과 언어 모델을 통합하여 RAG 파이프라인 구축
- API 서버 구축
- Langchain 라이브러리를 사용할 예정이라 파이썬 서버
- Flash, FastAPI와 같은 답변 생성을 위한 API 서버
Reference
Large Language Model (5) : RAG
RAG(검색 증강 생성)란? - LLM 단점을 보완하는 기술
