📂 언어 모델과 워드 임베딩
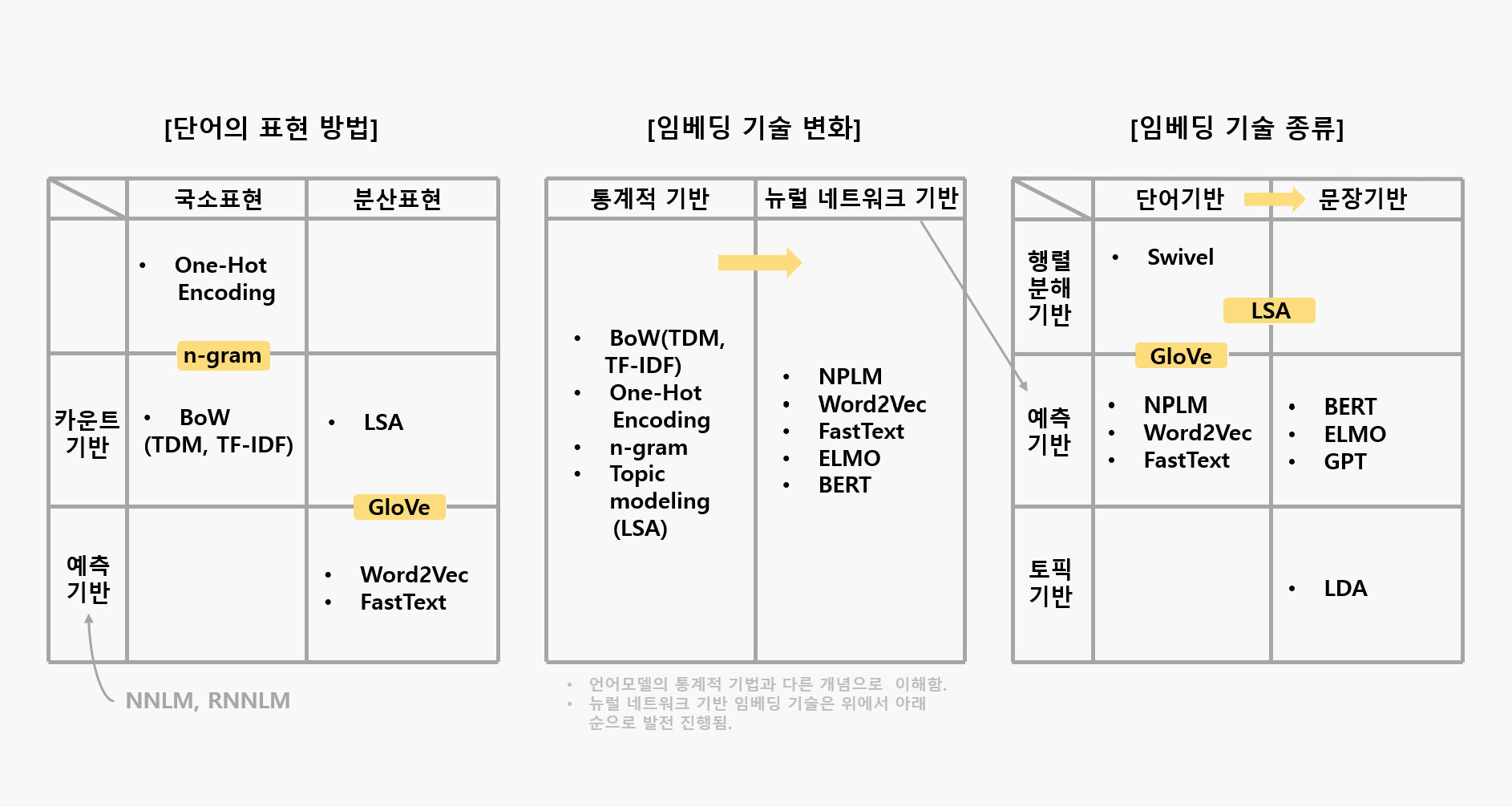
언어 모델(Language Model)은 특정한 단어의 시퀀스에 대해서 그 시퀀스가 일어날 가능성이 얼마나 되는지, 또는 주어진 단어들 다음에 어떤 단어가 나올지를 예측하는 모델입니다.
워드 임베딩(Word Embedding)은 단어를 고차원의 벡터로 표현하는 기법을 의미하며, 이는 각 단어들 간의 유사도를 계산할 수 있도록 해줍니다.
- 워드 임베딩은 단어 간의 유사성을 포착
- 언어 모델은 주어진 시퀀스 다음에 어떤 단어가 올지를 예측
🚨 언어 모델은 종종 워드 임베딩을 사용하여 입력을 나타내지만, 워드 임베딩 자체는 언어 모델이 아님
- 언어 모델링은 주어진 단어나 문장이 얼마나 자연스러운지를 판단하거나, 다음에 올 단어를 예측하는데 사용됨
- 언어 모델링 기법은 초기에
N-gram모델에서 시작해 점점 더 진보한RNN을 통해 발전됨
🧩 N-gram 언어 모델
- N-gram 언어 모델은 단어의 시퀀스에 확률을 할당하는 작업을 수행하는 모델임
- N이라는 매개변수는 시퀀스 내의 연속적인 단어의 수를 결정
EX] 예를 들어 "나는 카페에서 일을"이라는 문장에 대해 N-gram을 적용해봅시다.
[CASE 1 | Bigram] N = 2
- ("나", "는")
- ("는", "카페")
- ("카페", "에서")
- ("에서", "일")
- ("일", "을")[CASE 2 | Trigram] N = 3
- ("나", "는", "카페")
- ("는", "카페", "에서")
- ("카페", "에서", "일")
- ("에서", "일", "을")📎 N-gram 단점
- N-gram 모델은 주어진 문맥(N-1 개의 단어)에서 다음 단어가 무엇일지를 예측하려고 하는 모델임
- 이 모델의 예측은 훈련 데이터 내에서 해당 문맥과 다음 단어의 동시 출현 빈도에 기반함
1. 주어진 문맥에 대한 정보가 과거 (N-1)개의 단어로 제한된다
예를 들어 문장에서 중요한 의미를 가지는 단어가 N개 단어보다 더 멀리 떨어져 있다면, N-gram 모델은 그 사이의 연결을 학습하지 못합니다.
2. 희소성 문제
- 훈련 데이터에서 등장하지 않는 단어 조합에 대해서는 확률을 추정하기 어려움
- 이를 극복하고자
스무딩이나백오프와 같은 기술들이 사용
-> 일시적인 해결책일 뿐이며, 이 문제를 근본적으로 해결하지는 못함
단어 제한과 희소성 문제가있어, 더 발전된 언어 모델인
RNN이나Transformer기반의 모델들이 개발되었습니다. 이런 모델들은 훨씬 긴 문맥을 다룰 수 있으며, 더 정교한 확률 모델을 학습할 수 있습니다.
🧩 RNN 언어 모델
RNN(Recurrent Neural Network)은 순차적인 데이터를 처리하는 데 특화된 인공 신경망의 한 종류RNN은 시퀀스의 원소들을 차례대로 보면서, 각 단계에서 현재의 입력과 이전 단계의 '상태'를 기반으로 새로운 상태를 계산함.RNN은 각 시점에서 이전 상태를 기억하기 때문에, 앞부분의 문맥을 통해 뒷부분의 단어를 예측하는 Process
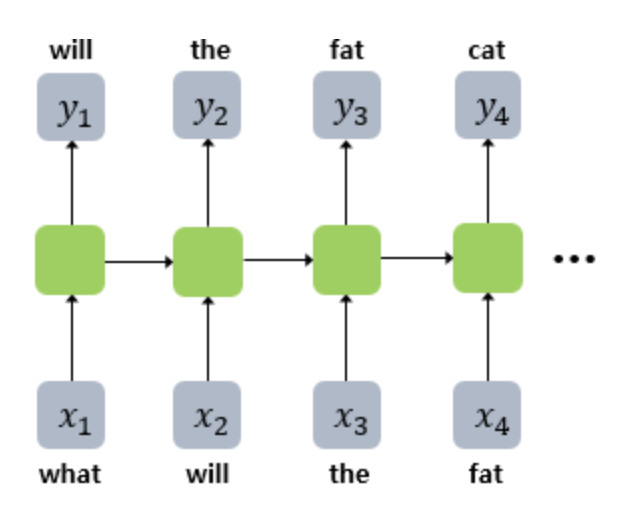
📎 RNN 동작 수식 요약
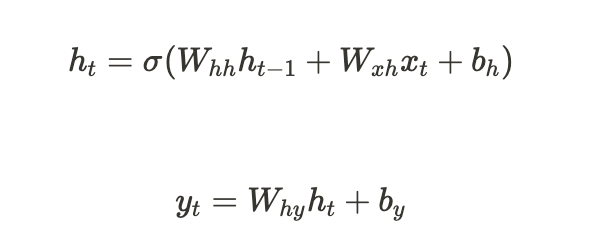
ht: 시간 t에서의 hidden state(=은닉상태)
xt: 시간 t에서의 입력
yt: 시간 t에서의 출력
Whh, Wxh, Why: 학습 가능한 가중치 행렬
bh, by: 편향(bias)
sigma는 비선형 활성화 함수(예: Tanh 또는 ReLU)- 각 시점에서 RNN이 이전상태와 현재 입력을 어떤식으로 결합하여 새로운 상태를 생성하는지 알 수 있음
- 새로운 상태 생성 후, 출력을 생성하는 과정도 알 수 있음
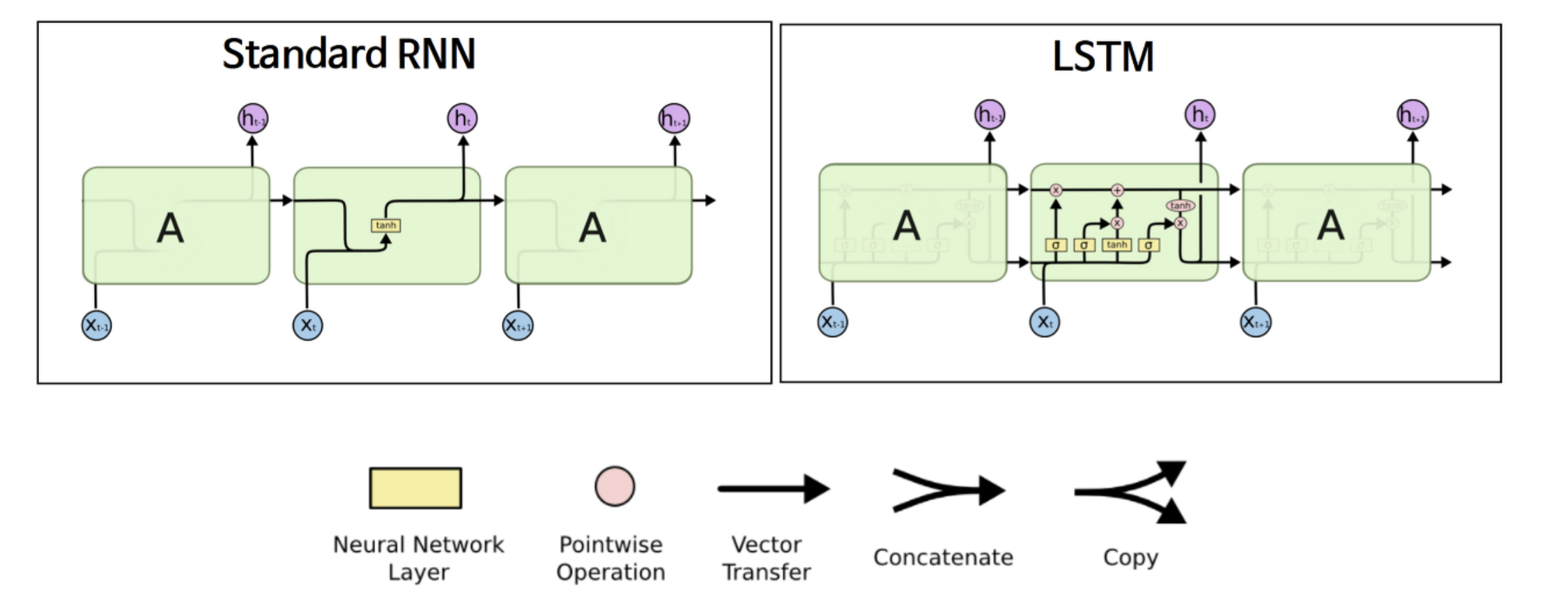
📎 RNN의 '장기의존성' 문제
RNN에는 '장기 의존성(Long-term Dependency)' 문제가 있음.
즉, 시퀀스가 길어질수록 앞부분의 정보를 뒷부분까지 '전달'하는 능력이 저하됨
LSTM(Long Short-Term Memory) 등의 변형된 RNN 구조를 통해 어느 정도 해결 가능
N-gram과 RNN은 언어 모델링의 초기와 중간 단계를 대표하는 기법입니다. 최근에는 이러한 기법들을 뛰어넘는
트랜스포머(Transformer)기반의 모델들이 대두되었으며, 이들은 다양한 자연어 처리 문제에서 최고의 성능을 보이고 있습니다.
🧩 Transformer 기반 언어 모델
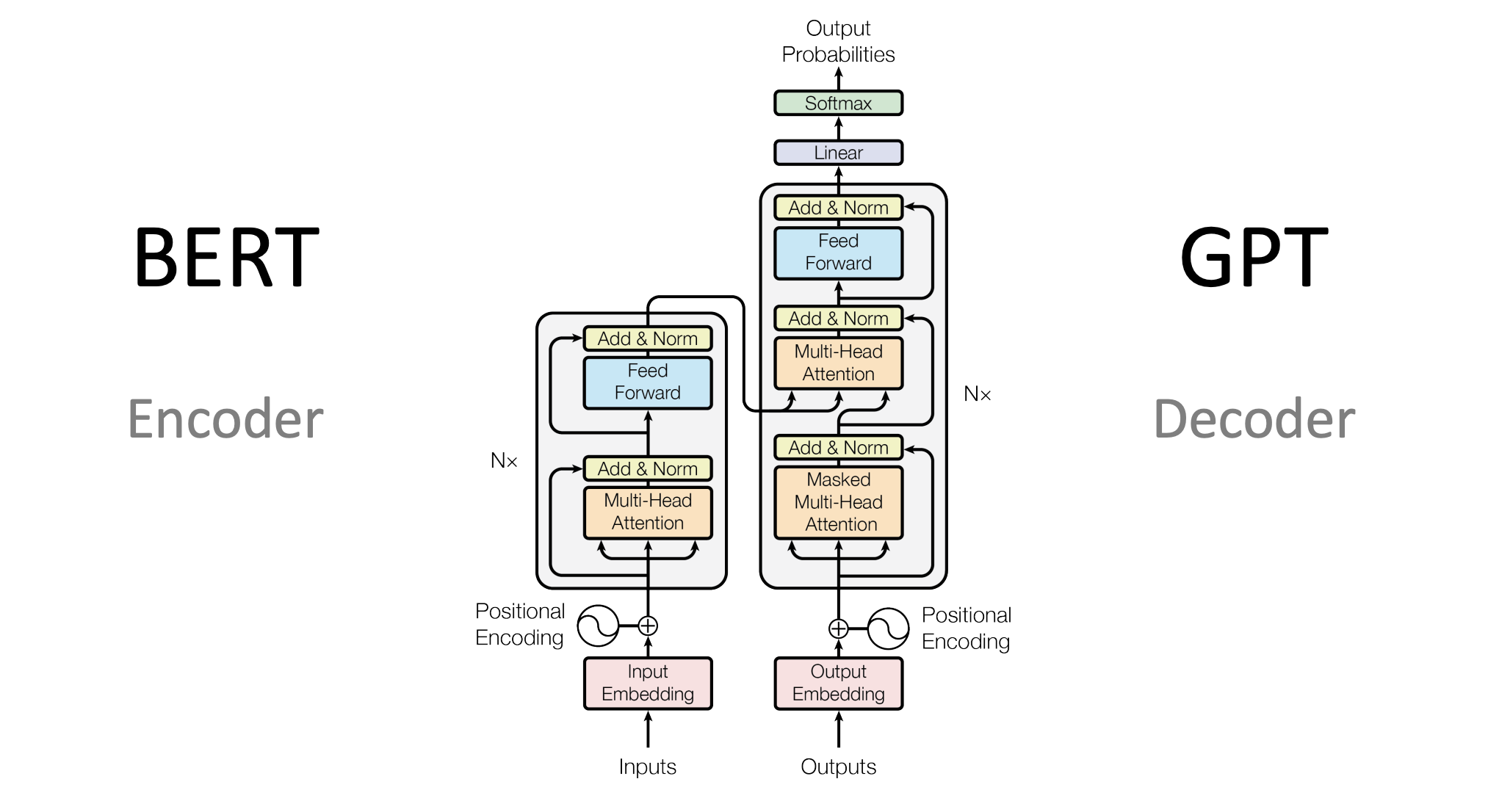
최근 몇 년 동안, NLP 분야는 크게 발전했습니다. 그 중심에는 Transformer라는 모델이 있습니다. 그리고 이 Transformer를 기반으로 한 현대적인 언어 모델들, 그 중에서도 특히 BERT와 GPT는 뛰어난 성능을 보여주며 많은 주목을 받았습니다. 차이점을 고려하여 모델을 적절하게 활용하곤 합니다.
◾️ `GPT`: 이전 단어에 의존하며 다음 단어를 예측하는 데 초점
◾️ `BERT`: 양방향 모델로 문장 전체의 문맥을 파악하여 단어들 간의 관계를 이해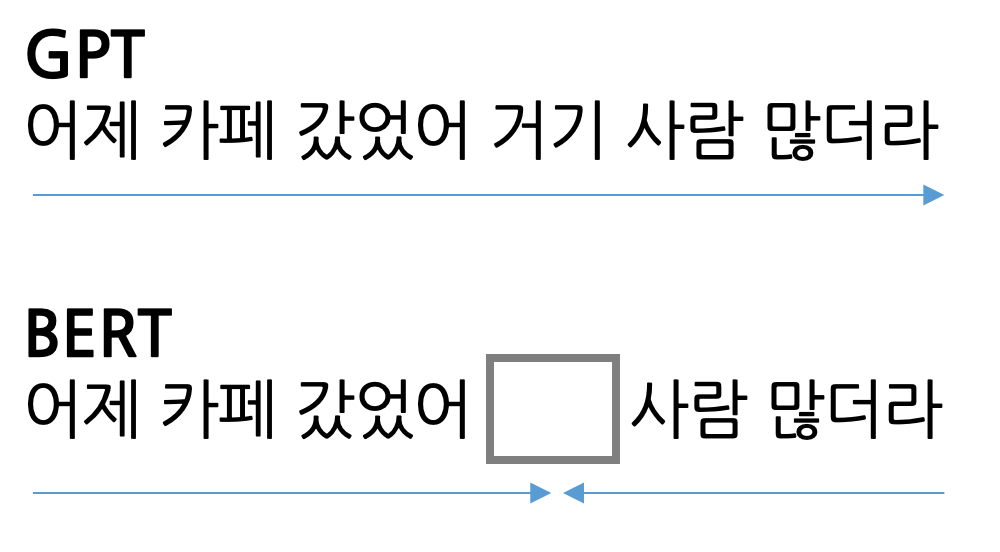
BERT는 인코더만 사용하고 GTP는 디코더만 사용
🧩 GPT | 이전 단어로 다음 단어 예측
GPT(Generative Pretraining Transformer)는 OpenAI에서 개발한 자연어 처리 모델입니다. GPT는 사전 훈련된(Pre-trained) 언어 모델을 이용해 다양한 자연어 처리 작업에 적용할 수 있습니다. GPT는 Transformer을 모두 사용하는 것이 아니라 생성 능력에 특화된 Transformer Decoder만을 활용합니다.
GPT의 학습 과정은 두 단계로 이루어집니다.
1. 사전 훈련(Pre-training)
대규모의 비지도학습 데이터를 사용하여 모델을 사전학습합니다. 이 단계에서 GPT는 문장의 다음 단어를 예측하는 자기회귀적(Autoregressive)인 방식으로 학습합니다. 이를 통해 모델은 텍스트의 패턴과 의미를 학습하게 됩니다.
2. 미세조정(Fine-tuning)
특정 자연어 처리 작업에 맞게 모델을 조정하는 과정입니다. 이 단계에서는 사전학습된 GPT 모델을 특정 작업에 적용하기 위해 작은 데이터셋을 사용하여 추가적인 학습을 수행합니다. 이를 통해 모델은 특정 작업에 대해 더 정확한 예측을 수행할 수 있도록 조정됩니다.
사실 많은 언어 모델의 활용 구조가
사전 훈련 - 미세조정으로 이루어져 있습니다. 그중 GPT는 문맥을 이해하고 문장을 생성하는 능력을 갖춘 강력한 모델로 자연어 처리 작업에서 널리 사용됩니다.
GPT를 활용하면 기계 번역, 챗봇, 문장 완성 등 다양한 NLP 작업을 수행할 수 있습니다. 그러나 모델의 크기와 학습에는 상당한 계산 자원과 시간이 필요하기 때문에 실제 응용에서는 이러한 측면을 고려하여 적절한 모델을 선택하고 활용해야 합니다.
🧩 BERT | 양방향 문맥 고려 예측
BERT(Bidirectional Encoder Representations from Transformers)는 이전의 방법들이 주로 한 방향으로만 문맥을 고려한 것과 달리 양방향으로 문맥을 고려 합니다. 이를 통해 양쪽 방향의 문맥을 모두 고려한 풍부한 단어 표현을 얻을 수 있습니다.
-
Masked Language Modeling(MLM)
MLM은 BERT가 양방향으로 문맥을 고려하는 핵심 기법입니다. 이 과정에서, BERT는 입력 토큰의 일부를 가리고(일반적으로 전체의 15% 정도) 이 가려진 토큰들을 주변 문맥을 바탕으로 예측하려고 시도합니다.
예를 들어, "나는 오늘 _ 피자를 먹었다"라는 문장에서, "_" 부분이 가려져 있을 때, MLM을 사용하면 BERT는 이 위치에 올 수 있는 단어를 예측하려고 시도합니다. "나는", "오늘", "피자를", "먹었다"라는 주변 문맥을 바탕으로 "_" 부분을 예측하려 하므로, 이는 양방향의 문맥을 고려한 것이라 할 수 있습니다.
가려진 토큰을 이라 하면, 을 예측하기 위한 확률 을 최대화하려 합니다. 여기서 는 가려진 토큰의 주변 문맥을 나타냅니다.
-
Next Sentence Prediction(NSP)
NSP는 두 문장 사이의 관계를 학습하는 데 사용되는 기법입니다. BERT에게는 두 문장이 주어지고, 두 번째 문장이 첫 번째 문장 바로 다음에 오는 문장인지 아닌지를 예측하게 됩니다.
예를 들어, "나는 오늘 피자를 먹었다."와 "그 피자는 치즈로 토핑되어 있었다."라는 두 문장이 주어졌을 때, BERT는 두 번째 문장이 첫 번째 문장 바로 다음에 오는 문장인지를 예측하려고 합니다. 통계적으로 표현하면 두 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장 바로 다음에 오는 문장일 확률 을 최대화하려고 합니다.
이 두 가지 기법을 통해, BERT는 양방향의 문맥과 문장 간의 관계를 모두 학습하게 되는데 덕분에 풍부한 언어 이해 능력을 얻을 수 있습니다.
[출처 | 딥다이브 Code.zip 매거진]
