📂 워드임베딩 (Word Embedding)
목표는 주변(Context window)에 같은 단어가 나타나는 단어일수록 비슷한 벡터 값을 가지게 하는 것이다.
🌻 TF-IDF
TF-IDF는 문서 내에서 단어의 빈도와 중요성을 측정하는 기법으로서, 수치로 표현됩니다.
이는 문서 분류나 정보 검색 등의 작업에 유용하지만, 단어의 의미나 문맥 정보를 직접적으로 포착하지 못한다는 단점이 있습니다.
🌻 워드 임베딩(Word Embedding)
워드 임베딩은 단어의 의미와 문맥 정보를 고차원 벡터로 표현합니다.
이때 각 단어는 다른 단어와 어떤 관계에 있는지를 나타내는 실수값 벡터로 표현됩니다.
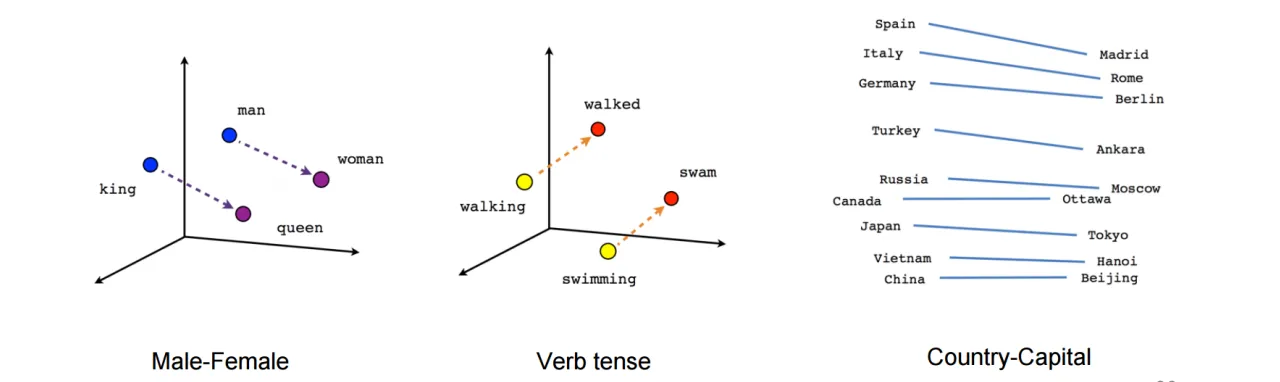
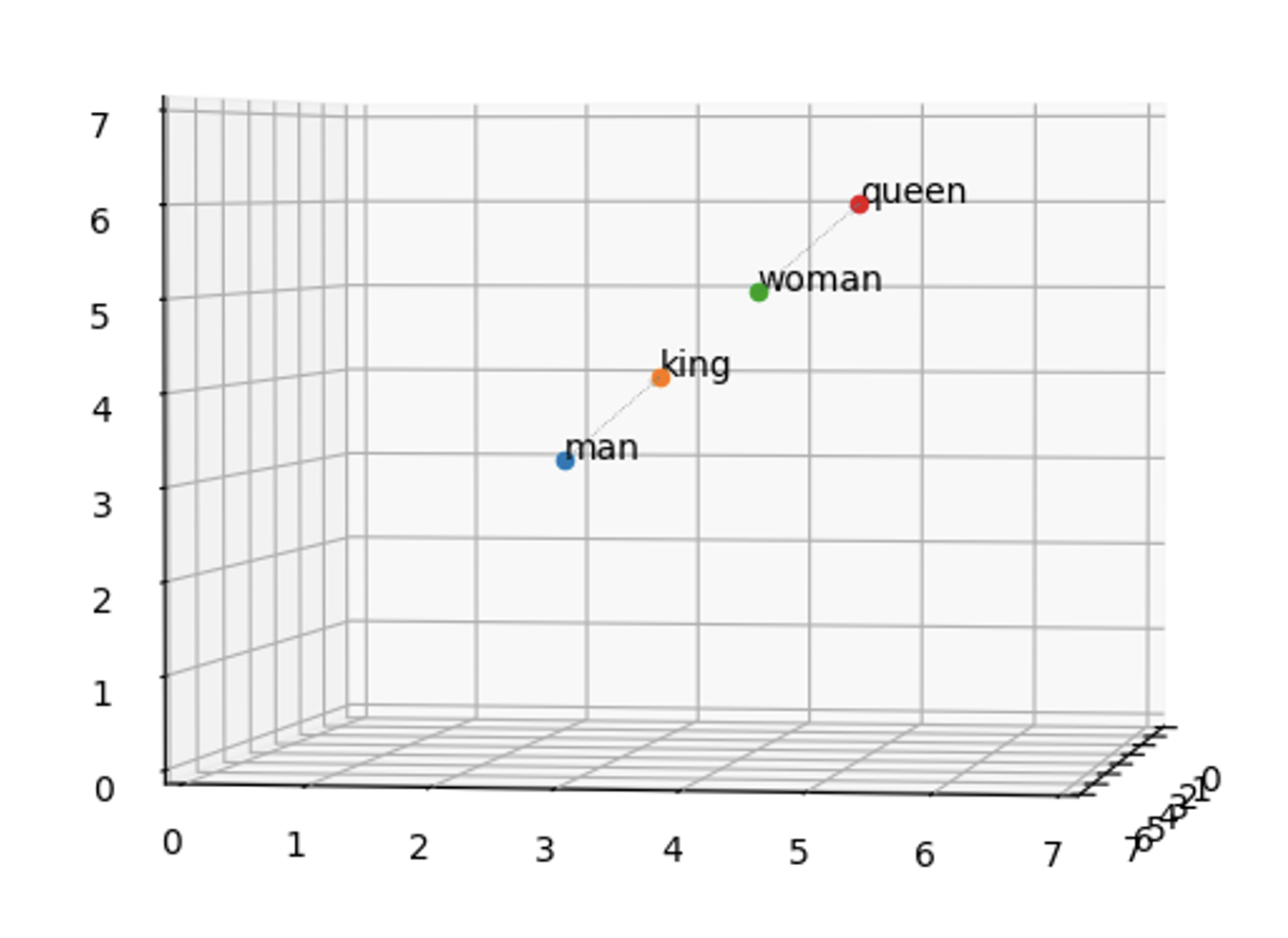
더 나아가, 비슷한 의미를 가진 단어들은 벡터 공간에서 가깝게 위치하게 됩니다.
🎈 워드 임베딩 장점
1. 단어 간의 관계를 수학적으로 표현 가능
- '의미'를 직접적으로 모델링2. 자연어 처리의 많은 문제에 대해 뛰어난 성능을 보임
- 감성분석에서는 문장의 단어들의 임베등을 평균내거나 합산하여 문장의 임베딩을 얻음
➡️ 문장의 긍정/부정을 판단하는데 사용 가능🎈 워드 임베딩 단점
1. 'OOV(Out-of-Vocabulary)' 문제
- 학습데이터에서 본 적 없는 새로운 단어에 대해서는 임베딩을 만들 수 없음
2. 동음이의 관계의 단어 파악 X
한계점 보완 모델
Word2Vec: 문맥을 고려한 워드 임베딩 방법론BERT언어모델 제안
📂 Word2Vec 원리
Word2Vec은 텍스트 데이터로부터 단어 임베딩을 학습하는 비지도 학습 모델입니다.
이 모델은 2013년에 구글에서 발표했으며, 단어의 의미를 벡터 공간에 매핑하는 것을 가능하게 합니다.
Word2Vec에는 두 가지 주요 학습 알고리즘 Continuous Bag-of-Words(CBOW)와 Skip-gram이 있습니다.
먼저, 아래와 같은 간단한 문장을 가지고 Word2Vec의 작동 원리를 살펴보겠습니다.
"나는 동그라미를 정말 좋아해.”
이 문장을 토큰화하면 다음과 같이 나눌 수 있습니다.
tokens = ["나", "는", "동그라미", “를", "정말", "좋아해"]
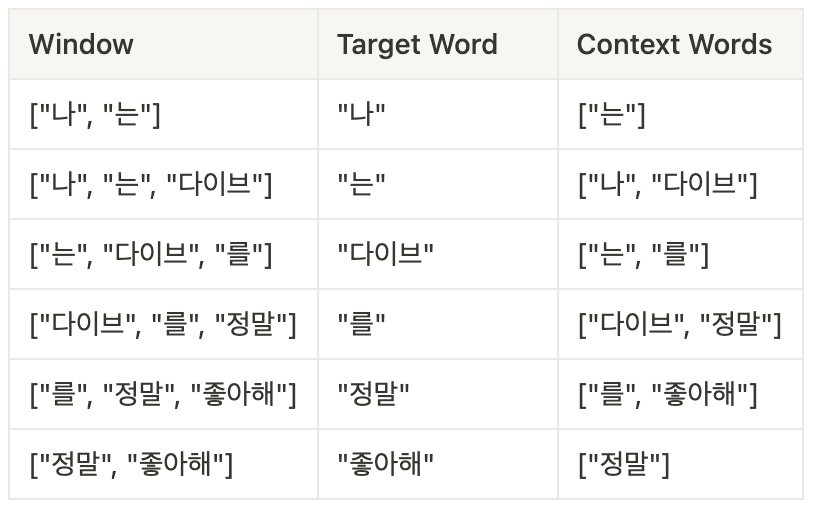
🔗 Sliding Window
- Sliding Window는 말뭉치에서 학습 데이터를 추출하는데 사용
- Window는 타깃 단어 주변에 단어를 포함할 범위를 의미
- 문장을 Sliding하면서
주변단어(Context Word)와목표단어(Target Word)의 쌍을 생성 - Window의 크기가 1일때, 위의 토큰화된 문장에서 추출되는 단어 쌍은 다음과 같음
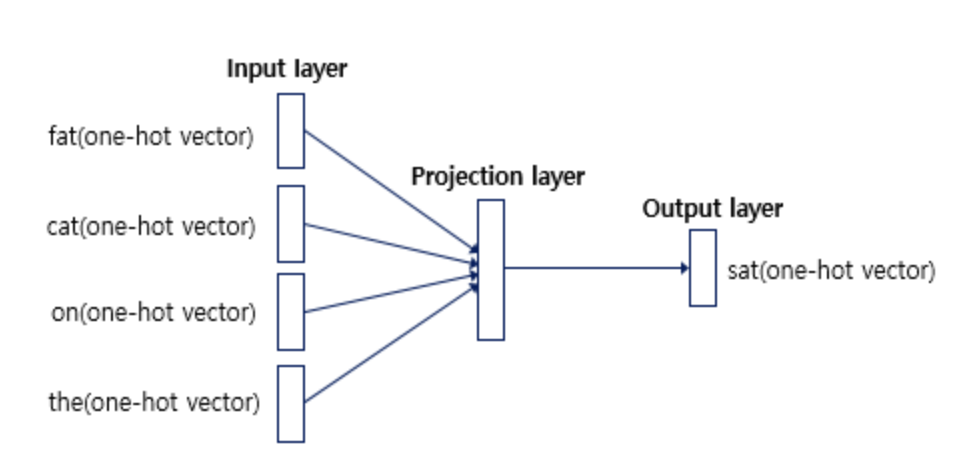
🔗 CROW (Continuous Bag-of-Words)
- CBOW 모델 아키텍처는 주변 문맥 단어에 기반하여 대상 단어를 예측함
- CBOW 모델의 학습 목표는 문맥 단어가 주어졌을 때 대상 단어를 정확하게 예측하는 확률을 최대화 하는 것
[ CROW의 인공신경망 ]
[ CROW의 원리 ]
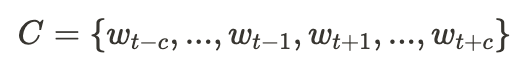
(Wt: 대상단어:, C: 문맥단어집합, C: 문맥 윈도우의 크기)- CBOW 모델은 문맥 단어 벡터를 숨겨진 레이어로 매핑하여 단어 임베딩을 나타냄
- CBOW 모델의 입력 레이어는 문맥 단어를 One-hot 인코딩된 벡터로 받음
- CBOW 모델의 히든 레이어는 문맥 단어 벡터를 임베딩으로 매핑하는 가중치 행렬로 구성됨
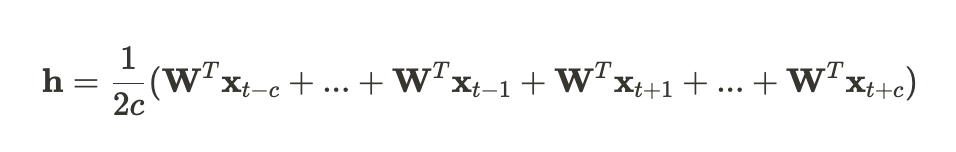
(h: 문맥 벡터, V: 어휘 크기, N: 단어 임베딩의 차원)- CROW 모델의 출력 레이어는 대상 단어 예측을 위해 softmax 활성화 함수를 사용하여, 어휘에 대한 확률분포(y)를 계산함
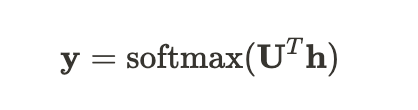
(U: 히든 레이어와 출력레이어를 연결하는 가중치 행렬)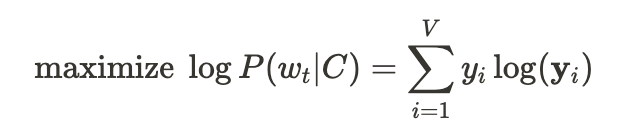
- 문맥 단어가 주어졌을 때 대상 단어를 정확하게 예측하는 확률 최대화
Word2Vec 모델의 CBOW 아키텍처는 문맥 단어 벡터를 임베딩으로 매핑한 후 softmax 출력 레이어를 통해 대상 단어를 예측합니다. 모델은 문맥 단어를 기반으로 대상 단어를 정확하게 예측하도록 학습합니다.
🔗 Skip-gram
- Skip-gram 모델은 반대로, 목표 단어를 가지고 주변 단어들을 예측
Skip-gram의 인공신경망
📎 Word2Vec Skip-Gram 전체 코드
1. 데이터 불러오기
import numpy as np
# 샘플 말뭉치
corpus = [
"나는 축구를 좋아합니다",
"나는 농구하는 것을 즐겨합니다",
"축구는 제가 가장 좋아하는 스포츠입니다",
"테니스 경기를 보는 것을 정말 좋아합니다.",
]2. 단어 전처리
Okt라이브러리를 불러와 어휘 사전 생성
# 전처리: 단어 어휘와 매핑 생성
from konlpy.tag import Okt
# 형태소 분석기 초기화
okt = Okt()
# 어휘 사전 생성
word_vocab = set()
for sentence in corpus:
words = okt.morphs(sentence, stem=True)
word_vocab.update(words)
vocab_size = len(word_vocab)3. 입력 및 출력 데이터 생성
# 입력 및 출력 데이터 생성
data = []
window_size = 2
for sentence in corpus:
words = okt.morphs(sentence, stem=True)
for target_idx, target_word in enumerate(words):
context_words = words[max(target_idx - window_size, 0):target_idx] + words[target_idx + 1:target_idx + window_size + 1]
for context_word in context_words:
data.append((target_word, context_word))
# 단어와 인덱스 매핑
word2idx = {word: idx for idx, word in enumerate(word_vocab)}
idx2word = {idx: word for idx, word in enumerate(word_vocab)}4. 임베딩 사이즈 지정
- 임베딩 사이즈와 윈도우 사이즈는 사용자가 직접 지정해주어야하는 하이퍼파라미터임
- 데이터셋 크기에 맞는 적당한 임베딩 사이즈를 설정해야함
- 일반적으로 embedding_size는 100, 300, 500로 설정함
# 하이퍼파라미터 설정
embedding_size = 100
learning_rate = 0.001
epochs = 100
# 가중치 초기화
input_weights = np.random.randn(vocab_size, embedding_size)
output_weights = np.random.randn(embedding_size, vocab_size)5. Skip-gram
# 학습 시작
for epoch in range(epochs):
total_loss = 0
for target_word, context_word in data:
# 입력 단어 인덱스 가져오기
target_idx = word2idx[target_word]
# 입력 벡터 생성
input_vector = np.zeros(vocab_size)
input_vector[target_idx] = 1
# 입력 단어의 임베딩 가져오기
input_embedding = input_weights[target_idx]
# 예측 계산
predicted_probs = np.dot(input_embedding, output_weights)
# 손실 계산
loss = -np.log(predicted_probs[word2idx[context_word]])
total_loss += loss
# 기울기 업데이트
delta = predicted_probs
delta[word2idx[context_word]] -= 1
# 가중치 업데이트
input_weights[target_idx] -= learning_rate * np.dot(delta, output_weights.T)
output_weights -= learning_rate * np.outer(input_embedding, delta)
# 에포크별 손실 출력
print(f"Epoch: {epoch+1}, Loss: {total_loss}")🥊 CROW와 Skip-gram의 차이점
⤬ Skip-gram은 한 단어의 문맥에서 다른 단어들을 예측하는 데 반해,
CBOW는 한 단어를 그 단어의 문맥에서 예측합니다.
CBOW는 모든 문맥 단어들을 함께 고려하지만, Skip-gram은 각 문맥 단어를 개별적으로 고려합니다.
- Skip-gram 모델은 드문 단어나 큰 데이터셋에 더 적합함
- CBOW 모델은 빠르고 효율적으로 학습되어, 작은 데이터셋에 더 적합함
- 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있음
✚ 사전 훈련된 워드 임베딩(Pre-trained Word Embedding)
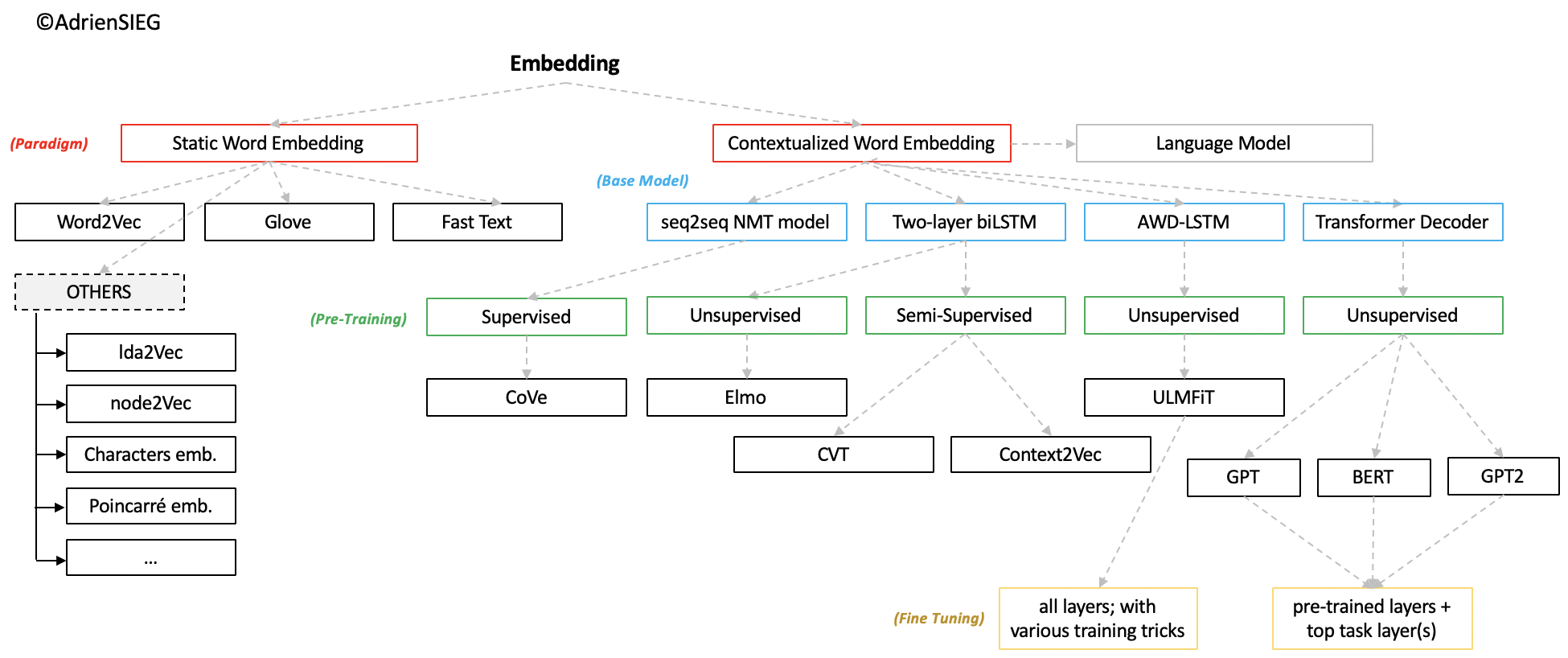
출처 | NLP 석사생 Word Embedding이란?
[출처 | 딥다이브 Code.zip 매거진]
