NLP
1.[NLP] 텍스트 데이터 전처리
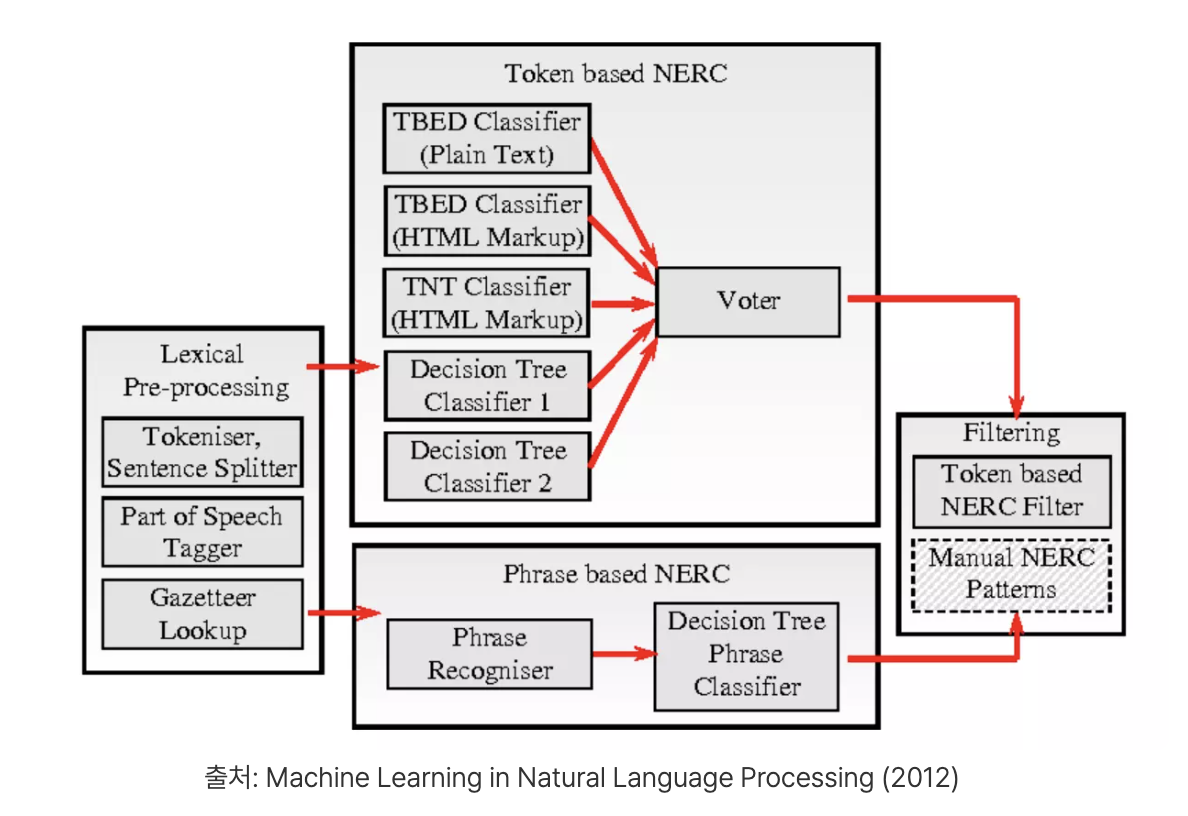
💬 텍스트 데이터 전처리 이미지 출처 🌬️ 특수 문자 및 숫자 제거 (Removing Special Characters and Numbers) 정규표현식(Regular Expression)을 사용하여 특정 패턴에 일치하는 불필요한 문자열을 삭제하거나 대체 >
2023년 11월 21일
2.[NLP] TF-IDF 텍스트 분류 실습
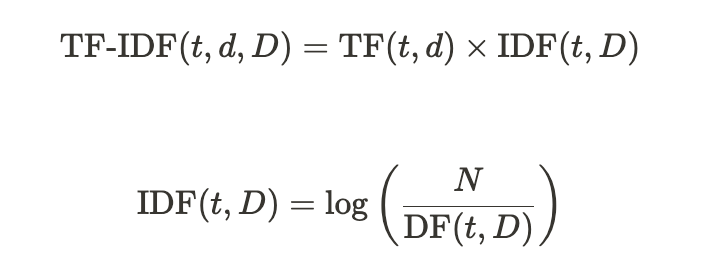
TF-IDF는 "다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 단어를 찾아내 문서 내 중요한 단어의 가중치를 계산하는 방법"TF-IDF는 문서의 특징을 숫자화(벡터화)하고자 활용되는 방법문서를 벡터화하고 나면 문서 분류, 문서 간 유사도 등 다양한 작업
2023년 11월 21일
3.[NLP] 워드 임베딩
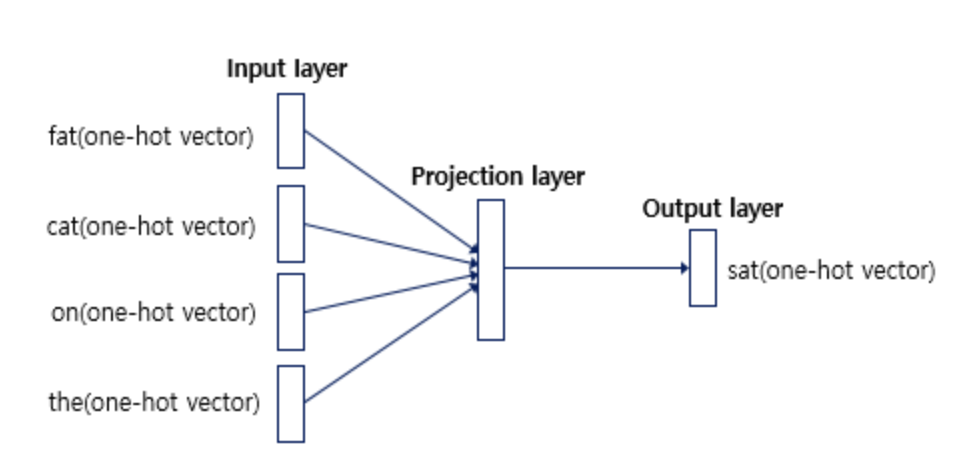
📂 워드임베딩 (Word Embedding) 목표는 주변(Context window)에 같은 단어가 나타나는 단어일수록 비슷한 벡터 값을 가지게 하는 것이다. 🌻 TF-IDF TF-IDF는 문서 내에서 단어의 빈도와 중요성을 측정하는 기법으로서, 수치로 표현됩니다
2023년 11월 22일
4.[NLP] 언어 모델
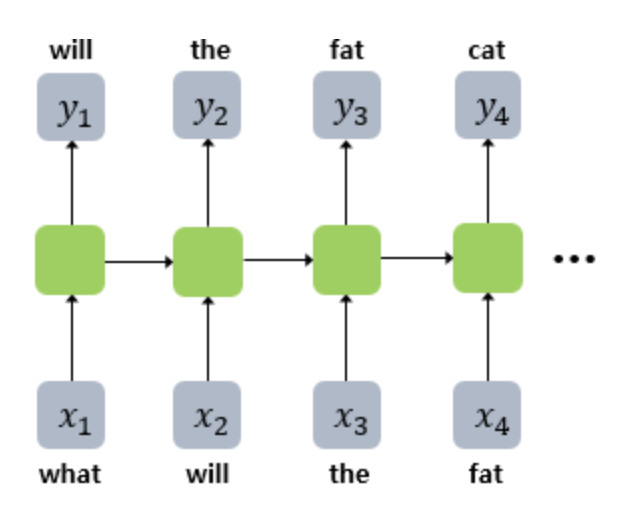
📂 언어 모델과 워드 임베딩 이미지 출처 | 워드임베딩이란? 언어 모델(Language Model)은 특정한 단어의 시퀀스에 대해서 그 시퀀스가 일어날 가능성이 얼마나 되는지, 또는 주어진 단어들 다음에 어떤 단어가 나올지를 예측하는 모델입니다. 워드 임베딩(W
2023년 11월 22일
5.[NLP] BERT 실습 예제: 네이버 영화 리뷰 감정 분류
💡 BERT를 활용한 네이버 영화 리뷰 감정 분류 허깅페이스(Hugging Face)에서 제공하는 transformer 라이브러리를 활용하여 한국어 BERT로 네이버 영화 리뷰의 감정을 분류해보도록 하겠습니다. 허깅페이스 참고 GitHub 🔗 1. 데이터 전처
2023년 11월 23일