K-Nearest Negihbors
기본개념
- 지도 학습 (Supervised Learning)
- 데이터에 대한 Label(명시적인 답)이 주어진 상태에서 컴퓨터를 학습시키는 방법
- 비지도 학습 (Unsupervised Learning)
- 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법
- 데이터의 숨겨진 특성이나 구조를 파악하는데 사용
- 분류 (Classification)
- 미리 정의된 여러 클래스 Label 중 하나를 예측하는 것
- 속성 값을 입력, 클래스 값을 출력으로 하는 모델
- 붓꽃(iris)의 세 품종 중 하나로 분류, 암 분류 등
- 이진 분류, 다중 분류 등이 있다
- 회귀 (Regression)
- 연속적인 숫자를 예측하는 것
- 속성 값을 입력, 연속적인 실수 값을 출력으로 하는 모델
- 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득 예측
- 예측 값의 미묘한 차이가 크게 중요하지 않다
- 일반화 (Generalization)
- 훈련 세트로 학습한 모델이 테스트 세트에 대해 정확히 예측 하도록 하는 것
- 과대적합 (Overfitting)
- 훈련 세트에 너무 맞추어져 있어 테스트 세트의 성능 저하
- 과소적합 (Underfitting)
- 훈련 세트를 충분히 반영하지 못해 훈련 세트, 테스트 세트에서 모두 성능이 저하
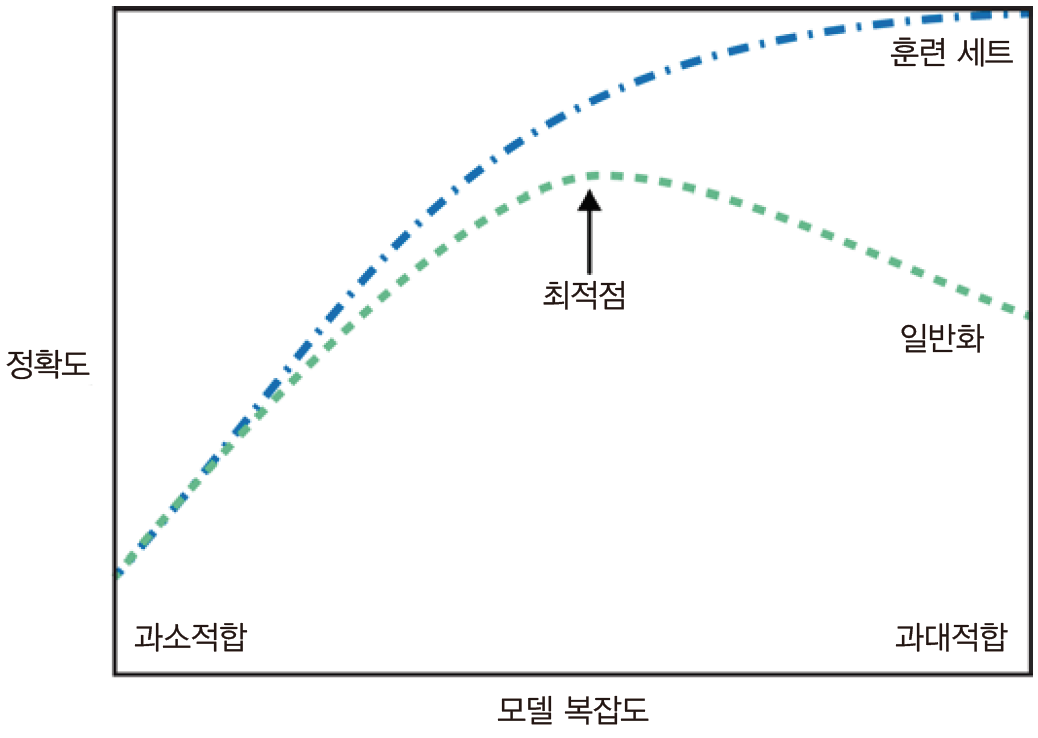
- 해결 방법
- 주어진 훈련 데이터의 다양성이 보장되어야 한다(다양한 데이터 포인트를 골고루 나타내야 한다)
- 일반적으로 데이터 양이 많으면 일반화에 도움이 된다
- 편중된 데이터를 많이 모으는 것은 도움이 되지 않는다
- 규제(Regularization)을 통해 모델의 복잡도를 적정선으로 설정한다
K-Nearest Neighbors(K-NN)
- k-최근접 이웃 알고리즘
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
- k 값에 따라 가까운 이웃의 수가 결정
- 분류와 회귀에 모두 사용 가능
- 입력 값과 k개의 가까운 점이 있다고 가정할 때 그 점들이 어떤 Label과 가장 비슷한지 (최 근접 이웃)판단하는 알고리즘
- 매개 변수 : 데이터 포인트 사이의 거리를 재는 방법 (일반적으로 유클리디안 거리 사용), 이웃의 수
- 장점 : 이해하기 쉬운 모델, 약간의 조정으로 좋은 성능을 가진다
- 단점 : 훈련 세트가 크면 속도가 느리고 많은 특성을 처리하기 힘들다
- 유클리디안 거리(Euclidean distance) : 두 점 사이의 거리를 계산할 때 쓰이는 방법
- 두 점 (p1, p2)와 (q1, q2)의 거리
=> ((p1-q1)^2 + (p2-q2)^2)^0.5
- 두 점 (p1, p2)와 (q1, q2)의 거리
- KNeighborsClassifier()
KNeighborsClassifier(n_neighbors, weights, algorithm, leaf_size, p, metric, metric_params, n_jobs)- n_neighbors : 이웃의 수 (default : 5)
- weights : 예측에 사용된 가중 함수 (uniform, distance) (default : uniform)
- algorithm : 가까운 이웃을 계산하는데 사용되는 알고리즘 (auto, ball_tree, kd_tree, brute)
- leaf_size : BallTree 또는 KDTree에 전달 된 리프 크기
- p : (1 : minkowski_distance, 2: manhattan_distance 및 euclidean_distance)
- metric : 트리에 사용하는 거리 메트릭스
- metric_params : 메트릭 함수에 대한 추가 키워드 인수
- n_jobs : 이웃 검색을 위해 실행할 병렬 작업 수Iris 데이터를 이용한 KNN 분류 실습
- 데이터 특성 파악
# 데이터 가져오기
from sklearn.datasets import load_iris
import sklearn.datasets
iris_dataset = load_iris()
# 훈련 데이터와 테스트 데이터 준비
from sklearn.model_selection import train_test_split
X = iris_dataset.data
y = iris_dataset.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 75% : 25% default
# 데이터 조사
# 산점도 행렬 : 3개 이상의 특성을 표현
# 4개의 특성을 갖는 붓꽃
import pandas as pd
iris_df = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_df, c=y_train)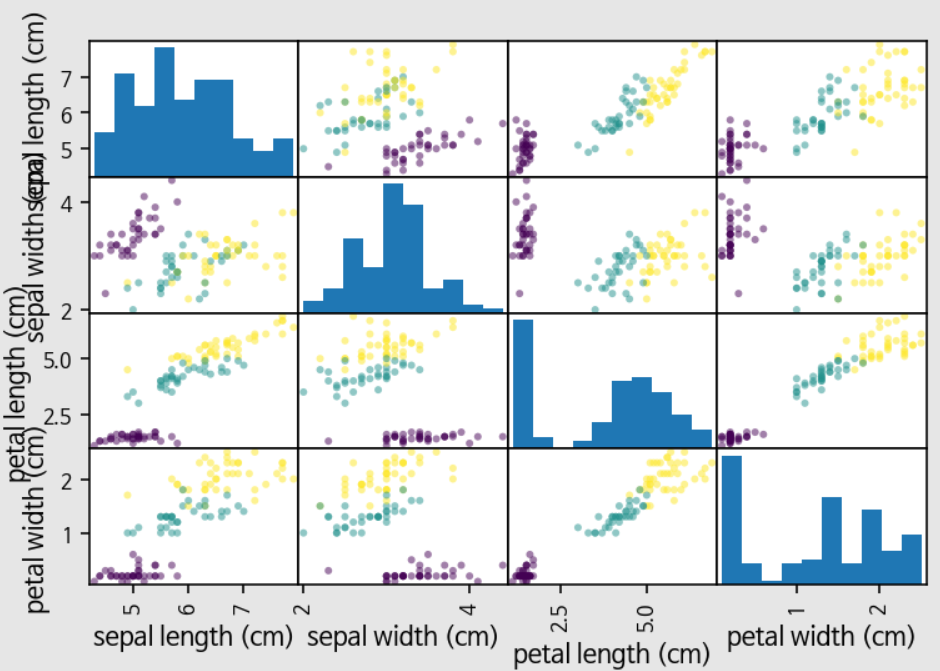
- 학습 및 예측 결과
#학습
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=1)
model.fit(X_train, y_train)
#예측
from sklearn import metrics
pred = model.predict(X_test)
ac_score = metrics.accuracy_score(y_test, pred)
ac_score

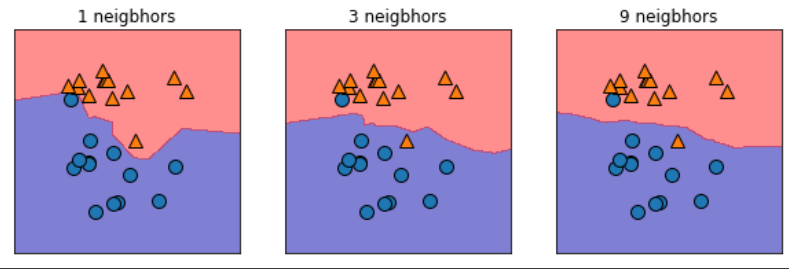
- 결정경계 (decision boundary)
- 이웃의 수를 늘릴수록 결정경계는 더 부드러워진다
- 이웃을 적게 사용하면 모델의 복잡도가 높아지고, 많이 사용하면 복잡도는 낮아진다
# KNeighborsClassifier 분석
import mglearn
import matplotlib.pyplot as plt
X, y = mglearn.datasets.make_forge()
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n, ax in zip([1, 3, 9], axes):
model = KNeighborsClassifier(n_neighbors=n)
model.fit(X, y)
mglearn.plots.plot_2d_separator(model, X, ax=ax, fill=True, alpha=0.5)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title(f'{n} neigbhors')