데이터 전처리 개요
데이터 전처리 종류
- 데이터 클린징
- 결손값 처리 (Null/NaN 처리)
- 데이터 인코딩(레이블, 원-핫 인코딩)
- 데이터 스케일링
- 이상치 제거
- Feature 선택, 추출 및 가공
여기서 데이터 인코딩, 데이터 스케일링에 대해 알아보자
데이터 인코딩
인코딩: 문자열 값을 숫자값으로 변경해주는 작업
인코딩을 왜 하는데?
머신러닝 모델은 문자열 값을 허용하지 않음
따라서 모든 문자열 값을 숫자값으로 바꾸기 위해서 사용!
레이블 인코딩
Label Encoding
문자열 Unique 값을 각각 숫자형으로 바꿔주는 것
예시로 쉽게 이해해보자
[TV, 냉장고, 전자레인지, 컴퓨터, 선풍기, 믹서] -> [0, 1, 4, 5, 3, 2]
이런 식으로 변환이 된다!
scikit-learn에서 숫자 순서는 아마 알파벳순으로 정렬 되는 것 같음
scikit-learn에서 어떻게 사용하는지 확인해보자
LabelEncoder 클래스, fit(), transform() 이용하여 변환
fit_transform() 함수를 사용하면 fit과 transform을 동시에도 가능
그런데 fit과 transform 대상을 분리해야 하는 경우가 있어서 이렇게 나눠져 있는 것
아래에 스케일링 할 때 언급함
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체로 생성한 후, fit( ) 과 transform( ) 으로 label 인코딩 수행
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:',labels)인코딩 변환값: [0 1 4 5 3 3 2 2]classes_, inverse_transform 기능 확인
print('인코딩 클래스:',encoder.classes_)
print('디코딩 원본 값:',encoder.inverse_transform([4, 5, 2, 0, 1, 1, 3, 3]))인코딩 클래스: ['TV' '냉장고' '믹서' '선풍기' '전자렌지' '컴퓨터']
디코딩 원본 값: ['전자렌지' '컴퓨터' '믹서' 'TV' '냉장고' '냉장고' '선풍기' '선풍기']그런데 레이블 인코딩은 숫자 간의 대소 관계 때문에 의도하지 않은 의미가 부여될 수 있음!
예를 들어 아래 문장
냉장고보다 전자레인지가 4배 더 크다.
이런 잘못된 의미가 생길 수 있음
이걸 보완 해주는 것이 원-핫 인코딩
원-핫 인코딩
One-Hot Encoding
문자열 Unique 값 만큼 칼럼을 만들어서 해당하는 칼럼에만 1을 표시하고, 나머지 칼럼은 0을 표시하는 방식
예시로 쉽게 이해해보자
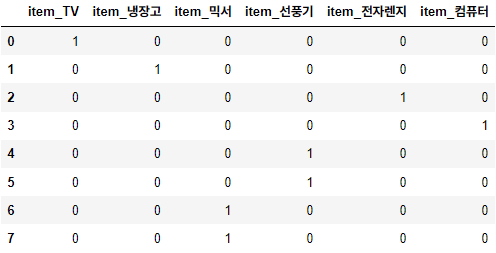
첫 번째 칼럼은 제거해서 Unique 값 개수 - 1 만큼만 칼럼을 만들기도 함
원-핫 인코딩은 scikit-learn으로 할 수도 있고, Pandas의 get_dummies() 함수를 이용할 수도 있음
scikit-learn에서 어떻게 사용하는지 확인해보자
OneHotEncoder 클래스, fit(), transform() 이용하여 변환
인자로 2차원 ndarray 입력 필요, Sparse 배열 형태(행렬 값의 대부분이 0인 행렬)로 변환되므로 toarray()를 적용하여 다시 Dense 형태로 변환되어야 함
2차원 ndarray 말고 DataFrame 넣어도 잘 되는 것 같음
좀 복잡해보임, 코드로 확인해보자
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# 2차원 데이터로 변환
items = np.array(items).reshape(-1,1)
# 원-핫 인코딩을 적용합니다.
oh_encoder = OneHotEncoder()
oh_encoder.fit(items)
oh_labels = oh_encoder.transform(items)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)원-핫 인코딩 데이터
[[1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]]
원-핫 인코딩 데이터 차원
(8, 6)과정이 드럽게 복잡하다.
그래서 나는 보통 Pandas의 get_dummies()를 사용함
Pandas를 이용해서 원-핫 인코딩하는 방법을 살펴보자
import pandas as pd
df = pd.DataFrame({'item':['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서'] })
pd.get_dummies(df)<출력 결과>
굉장히 간단하게 원-핫 인코딩을 수행할 수 있음
get_dummies() 인자로 drop_first=True 를 주면 첫 번째 칼럼은 삭제하고 출력함
scikit-learn은 결과가 ndarray로 나오고, Pandas는 DataFrame으로 나오는데,
진행할 나중에 모델 적합할 때는 둘다 상관 없다고 함
데이터 스케일링
피처(Feature)에 대해서 스케일링을 하는 것이라 피처 스케일링이라고 함
피처 스케일링을 왜 하는데?
피처마다 단위가 서로 다를 수 있음
단위를 통일화하는 과정이라고 생각하면 됨!
보통 아래에서 다루는 표준화, 정규화 정도만 알고 있으면 됨
표준화 (Standardization)
데이터의 피처에 대해 각각 평균이 0이고, 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것
아래 식처럼 변환하면 된다.
SVM, 선형 회귀, 로지스틱 회귀는 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현됐기 때문에 사전에 표준화를 적용하는 것이 예측 성능 향상에 중요한 요소가 될 수 있음!
(RandomForest, DecisionTree 같은 Tree 계열 모델은 스케일링 안 해도 큰 상관 없음)
scikit-learn 에서는 StandardScaler 클래스를 사용한다.
(StandardScaler는 표준화 방법 중 하나임)
예시 코드를 확인해보자
fit()을 하면 그 데이터에 해당하는 평균과 표준편차를 뽑는다.
transform()을 하면 fit()에서 뽑은 것을 가지고 변환을 진행한다.
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 붓꽃 데이터 셋을 로딩하고 DataFrame으로 변환
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
# StandardScaler객체 생성
scaler = StandardScaler()
# StandardScaler 로 데이터 셋 변환. fit( ) 과 transform( ) 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
print('feature 들의 원래 평균 값')
print(iris_df.mean())
print('\nfeature 들의 원래 분산 값')
print(iris_df.var())
#transform( )시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('\nfeature 들의 스케일된 평균 값')
print(iris_df_scaled.mean())
print('\nfeature 들의 스케일된 분산 값')
print(iris_df_scaled.var())feature 들의 원래 평균 값
sepal length (cm) 5.843333
sepal width (cm) 3.057333
petal length (cm) 3.758000
petal width (cm) 1.199333
dtype: float64
feature 들의 원래 분산 값
sepal length (cm) 0.685694
sepal width (cm) 0.189979
petal length (cm) 3.116278
petal width (cm) 0.581006
dtype: float64
feature 들의 스케일된 평균 값
sepal length (cm) -1.690315e-15
sepal width (cm) -1.842970e-15
petal length (cm) -1.698641e-15
petal width (cm) -1.409243e-15
dtype: float64
feature 들의 스케일된 분산 값
sepal length (cm) 1.006711
sepal width (cm) 1.006711
petal length (cm) 1.006711
petal width (cm) 1.006711
dtype: float64정규화 (Normalization)
서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 것
(0과 1사이의 범위 값으로 변환, 음수 값이 있으면 -1~1로 변환)
이상치에 민감하다는 단점이 있다.
아래 식처럼 변환하면 된다.
scikit-learn 에서는 MinMaxScaler 클래스를 사용한다.
(MinMaxScaler는 정규화 방법 중 하나임)
예시 코드를 확인해보자
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 학습 데이터는 0 부터 10까지, 테스트 데이터는 0 부터 5까지 값을 가지는 데이터 세트로 생성
# Scaler클래스의 fit(), transform()은 2차원 이상 데이터만 가능하므로 reshape(-1, 1)로 차원 변경
train_array = np.arange(0, 11).reshape(-1, 1)
test_array = np.arange(0, 6).reshape(-1, 1)
# 최소값 0, 최대값 1로 변환하는 MinMaxScaler객체 생성
scaler = MinMaxScaler()
# fit()하게 되면 train_array 데이터의 최소값이 0, 최대값이 10으로 설정.
scaler.fit(train_array)
# 1/10 scale로 train_array 데이터 변환함. 원본 10-> 1로 변환됨.
train_scaled = scaler.transform(train_array)
print('원본 train_array 데이터:', np.round(train_array.reshape(-1), 2))
print('Scale된 train_array 데이터:', np.round(train_scaled.reshape(-1), 2))원본 train_array 데이터: [ 0 1 2 3 4 5 6 7 8 9 10]
Scale된 train_array 데이터: [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]scikit-learn에서 스케일링시 주의할 점!
train에 대해서만 fit을 하고 그 fit한 것을 train / test 데이터세트에 transform을 해야 한다!
아래 코드를 봐보자
# 앞에서 생성한 MinMaxScaler에 test_array를 fit()하게 되면 원본 데이터의 최소값이 0, 최대값이 5으로 설정됨
scaler.fit(test_array)
# 1/5 scale로 test_array 데이터 변환함. 원본 5->1로 변환.
test_scaled = scaler.transform(test_array)
# train_array 변환 출력
print('원본 test_array 데이터:', np.round(test_array.reshape(-1), 2))
print('Scale된 test_array 데이터:', np.round(test_scaled.reshape(-1), 2))원본 test_array 데이터: [0 1 2 3 4 5]
Scale된 test_array 데이터: [0. 0.2 0.4 0.6 0.8 1. ]test_array에 대해서 fit을 하니까 test_array에 있는 최댓값(5)를 전체의 최댓값으로 인식해서 1을 반환해버린다.
따라서 전체 데이터세트를 대변하는 train으로만 fit을 해서 값을 뽑아야 한다.
(StandardScaler는 평균과 표준편차, MinMaxScaler는 최댓값, 최솟값)
train_array에 대해 fit한 결과는 아래와 같다.
scaler = MinMaxScaler()
scaler.fit(train_array)
train_scaled = scaler.transform(train_array)
print('원본 train_array 데이터:', np.round(train_array.reshape(-1), 2))
print('Scale된 train_array 데이터:', np.round(train_scaled.reshape(-1), 2))
# test_array에 Scale 변환을 할 때는 반드시 fit()을 호출하지 않고 transform() 만으로 변환해야 함.
test_scaled = scaler.transform(test_array)
print('\n원본 test_array 데이터:', np.round(test_array.reshape(-1), 2))
print('Scale된 test_array 데이터:', np.round(test_scaled.reshape(-1), 2))원본 train_array 데이터: [ 0 1 2 3 4 5 6 7 8 9 10]
Scale된 train_array 데이터: [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
원본 test_array 데이터: [0 1 2 3 4 5]
Scale된 test_array 데이터: [0. 0.1 0.2 0.3 0.4 0.5]잘 스케일링이 된 것을 확인할 수 있다!
