
Sementic segmentation
✔️ Sementic segmentation이란?
기존은 CNN모델은 하나의 이미지 인풋에 대하여 분류하는 Task를 수행하는 것이였더라면 Sementic segmentation은 각각의 pixel을 카테고리 형식으로 분류하는 것이다.
Sementic segmentation architectures
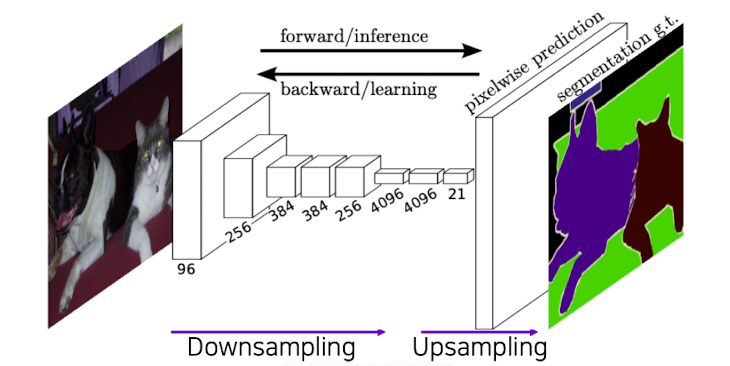
✔️ Fully convolutional Network
- 가장 처음 semantic segmentation의 end-to-end architecture이다.
- 임의의 사이즈의 input값을 넣고 input과 같은 사이즈의 segmentation map을 반환한다.
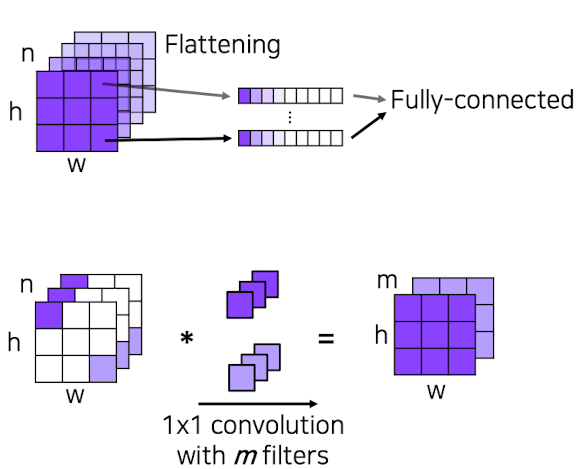
- Fully connected layer VS Fully convolutional layer
Fully connected layer : Output이 고정된 사이즈의 벡터로써 출력이 되어지며 공간 정보를 잃어버리게 된다.
Fully convolutional layer :Output이 classification map으로써 나오게 되고 공간 정보를 담고 있다.
출처 : Naver BoostCamp AI Tech - edwith 강의
- 각각의 부분들이 큰 receptive field를 가지고 있기 때문에 몇몇 공간 정보가 Upsampling으로 인해 전개가 되어짐
❓ Upsampling
layer를 통해 정보가 함축되어지지 않으면 receptive field가 작아 공간 정보를 파악하기 어려워진다. 따라서, 작은 activation map에서 Upsampling을 통해서 input사이즈 만큼 키워주게 된다.
출처 : Naver BoostCamp AI Tech - edwith 강의
Upsampling의 종류
1, Unpooling
2, Transposed convolution
3, Upsample and convolution
최근에는 2,3번이 많이 사용이 된다.
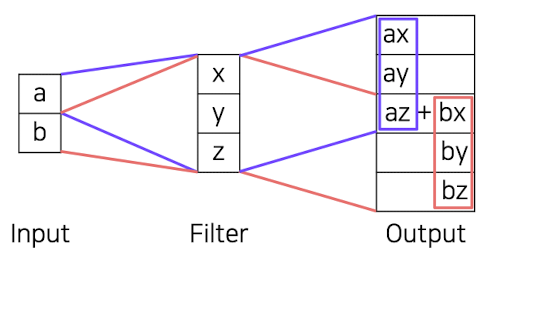
👉 Transposed convolution
출처 : Naver BoostCamp AI Tech - edwith 강의
convolution의 forward와 backward가 바뀐 방법으로 작동이 된다.
❗️ 이때의 문제는 겹치는 부분이 발생하는 overlap현상이 일어난다는 것이다. => 이러한 문제점을 해결하기 위해 Upsample and convolution을 사용하게 된다.
👉 Upsample and convolution
convolution을 이용한 보간(interpolation)이 이용이 되면서 사용되는 알고리즘으로는 Nearest-neighbor(NN), Bilinear등이 있다.(중첩되지 않고 골고루 영향을 받게함)

출처 : Naver BoostCamp AI Tech - edwith 강의
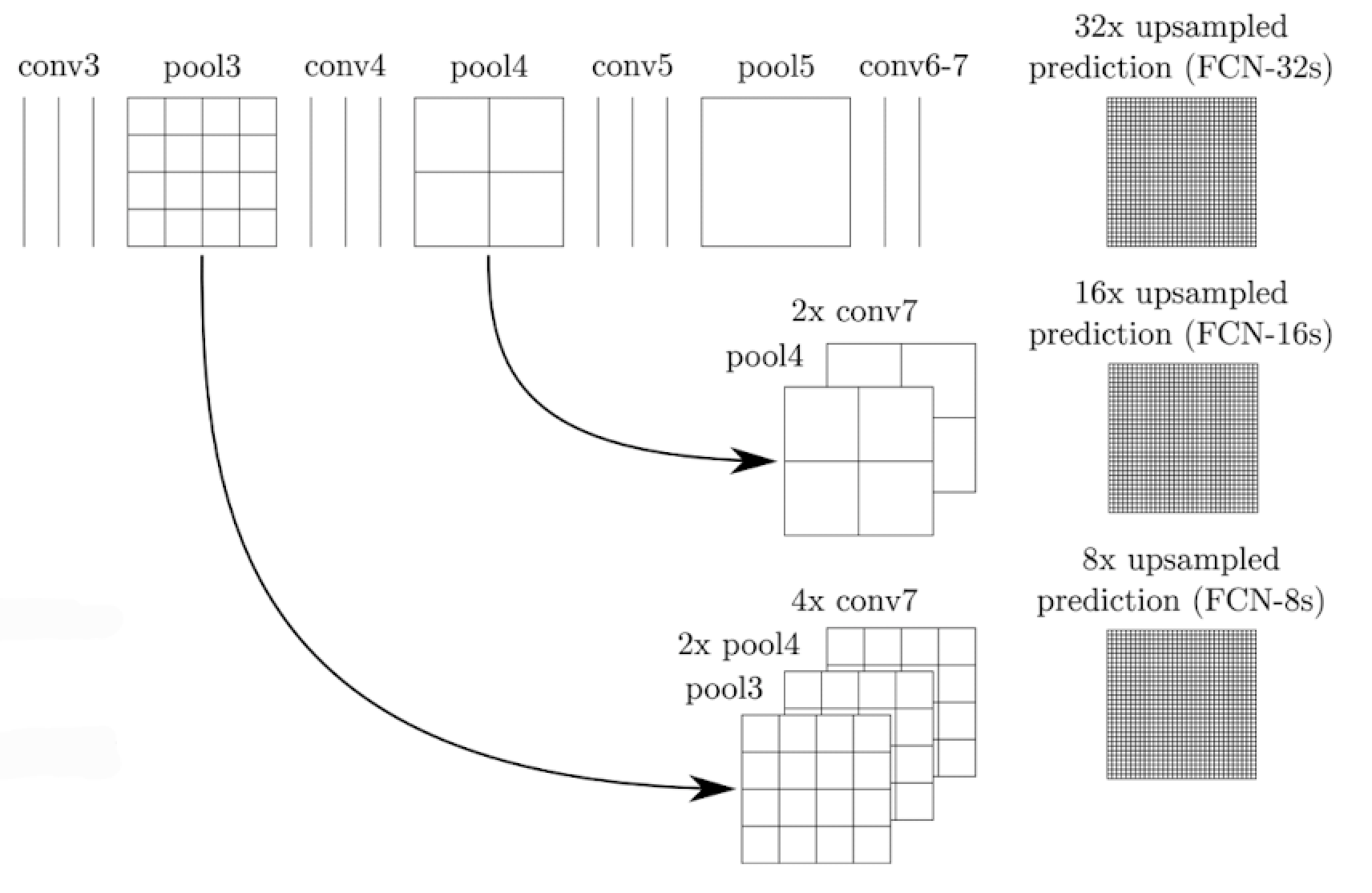
- FCN을 적용하게 되면 낮은 layer에서는 낮은 layer에서는 Receptive field가 작고 작은 변화에도 민감한 반면 높은 layer에서는 해상도는 낮지만 Receptive field가 크고 의미론적인 정보를 받을 수 있는데 semeantic segmentation을 수행하기 위해서는 모두 필요하다.(각 픽셀별 의미 파악(low level), 현재 하나의 픽셀이 경계를 기준으로 물체 안쪽 픽셀인지 바깥쪽 픽셀인지(high level -> 경계 부분을 디테일하게 파악))
출처 : Naver BoostCamp AI Tech - edwith 강의
중간층을 Upsampling하여 가져옴(낮은 층의 layer일 수록 가장 많은 activation map을 사용)
FCN-32s...등은 각각 모델을 지칭
👉 FCN은 손으로 만든 별도의 알고리즘을 사용하지 않고 모두 뉴럴넷 네트워크로 구성되어 있기 때문에 GPU로 병렬처리도 가능하고 하기에 굉장히 빠르다. 또한, 모델이 해당 테스크에 맞춰 학습되기 때문에 더 좋은 성능을 보내고 low level과 high level전체를 고려하여 정확도가 높다.
✔️ Hypercolumns for object segmentation
- FCN과 거의 동시에 나왔으며 1 X 1 convolution을 사용하는 내용도 포함이 되어 있는데 차이점은 낮은 layer에 있는 feature와 높은 layer에 있는 feature를 사용하는 부분을 사용하는 데에서 차이가 발생(강조된 부분)
-> 1 X 1 convolution부분과 FCN부분이 강조된 부분은 아니였다.
-> 해상도를 맞춰 학습하는 부분을 강조
- hypercolumn을 이용 : CNN단위로 픽셀에 쌓여 벡터를 이룸

출처 : Naver BoostCamp AI Tech - edwith 강의
=> 낮은 layer에 있는 feature와 높은 layer에 있는 feature를 사용 - end-to-end가 아닌 다른 third part 알고리즘을 사용하여 각 물체에 bounding박스를 추출한 뒤 적용하는 모델로 소개가 되었다.

<참고>
Hypercolumns for object segmentation도 인용이 많이 되었지만 FCN에 비해서는 많이 인용이 되어지지는 못하였다.
출처 : Naver BoostCamp AI Tech - edwith 강의
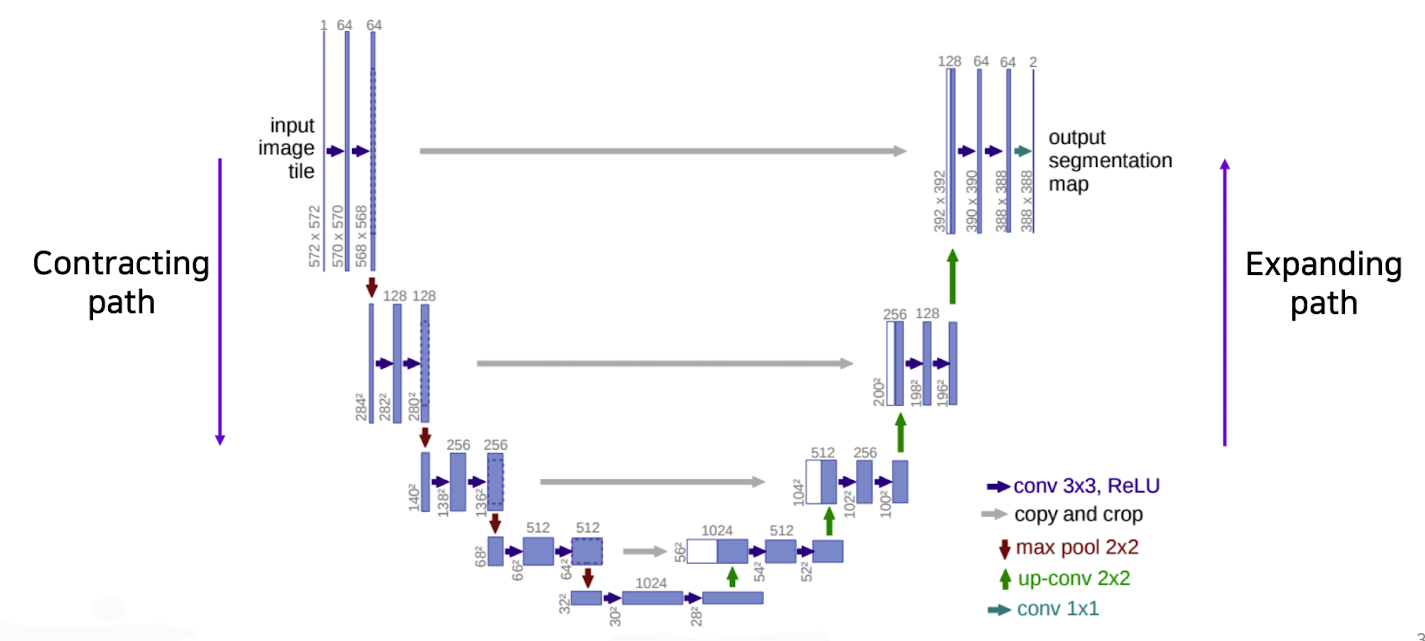
✔️ U-Net
- Fully convolutional network사용(FCN의 특징을 가져옴)
- 이전 path에 있는 것과 특징 map을 concatenating을 하여 dense map을 생성한다.(FCN의 skip connections이용)
- 보다 정확한 segmentations사용
출처 : Naver BoostCamp AI Tech - edwith 강의
- Contracting Path
👉 3 X 3 convolutions을 반복적으로 사용
👉 채널의 수가 점점 2배로 증가함
👉 전체 맥락을 포착하는데 사용
👉 feature map의 크기는 반으로 감소하는 방향으로 진행됨
- Expanding Path
👉 2 X 2 convolutions을 반복적으로 사용
👉 contracting path(수축경로)로부터 corresponding feature maps(현재 특징 map들)을 concatenating한다.
👉 채널의 수가 점점 2배로 감소
👉 feature map의 크기는 반으로 증가하는 방향으로 진행됨
❗️ contracting path(수축경로)로부터 corresponding feature maps(현재 특징 map들)을 concatenating하는 것은 localized information을 제공한다.(공가누적으로 높은 해상도와 입력이 약간 바뀌는 것 만으로도 민감한 정보를 제공하기 때문에 경계선이나 공간적으로 중요한 정보들을 뒷쪽 layer에 바로 전달하는 중요한 역활을 한다.)
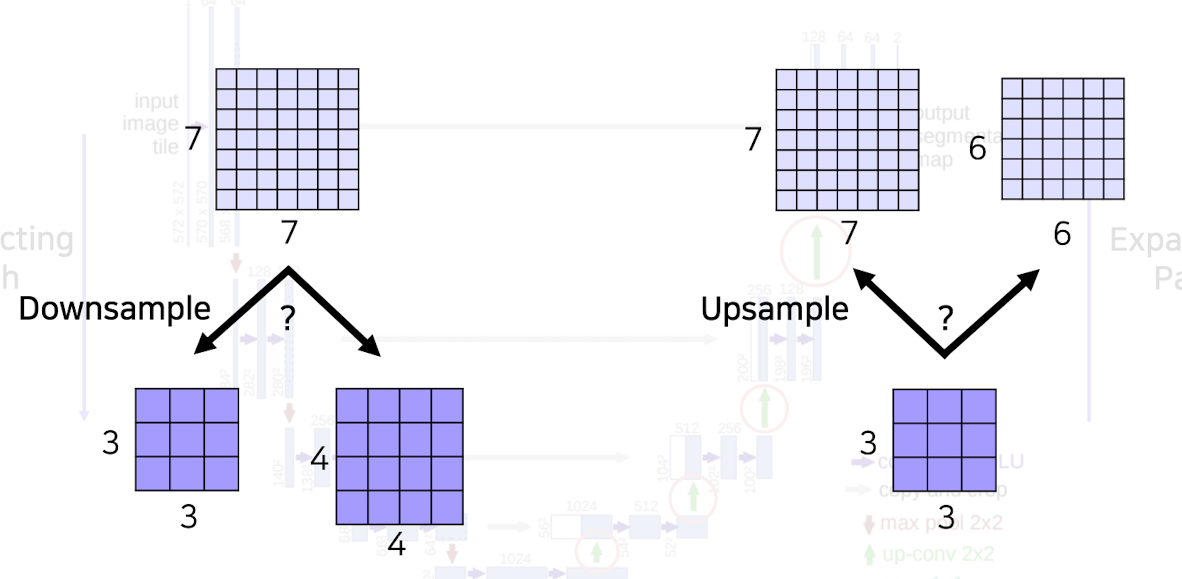
❗️ input과 feature size는 짝수의 크기를 가져야 하는 이유는 홀수가 되어 버리면 수축과 증폭 과정에서 애매한 상황이 발생하기 때문에 크기 고려를 잘 해 주워야 한다.
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ DeepLab
-
Conditional Random Fields(CRFs)
후처리로 사용되는 trick으로써 기술적으로는 graph modeling이다.=> 픽셀과 픽셀 관계를 다 이어줌
CRF는 segmentation map에서 이미지 경로를 따르도록 다듬는 역활을 한다.(처음 sementic segmentation을 수행하게 되면 blurly한 이미지를 받아오게 됨)
pixel을 그래프로 나타내고 이미지 score와 실제 이미지에서 배운 경계선(엣지 등...)을 찾아 score map이 경계선에 잘 들어맞도록 해 줌
-
Dilated convolution
Atrous convolution이라고도 함
커널 요소 사이에 공백을 삽입하여 커널을 팽창(Dilation factor만큼)
receptive field를 확장시킬 수 있다. -
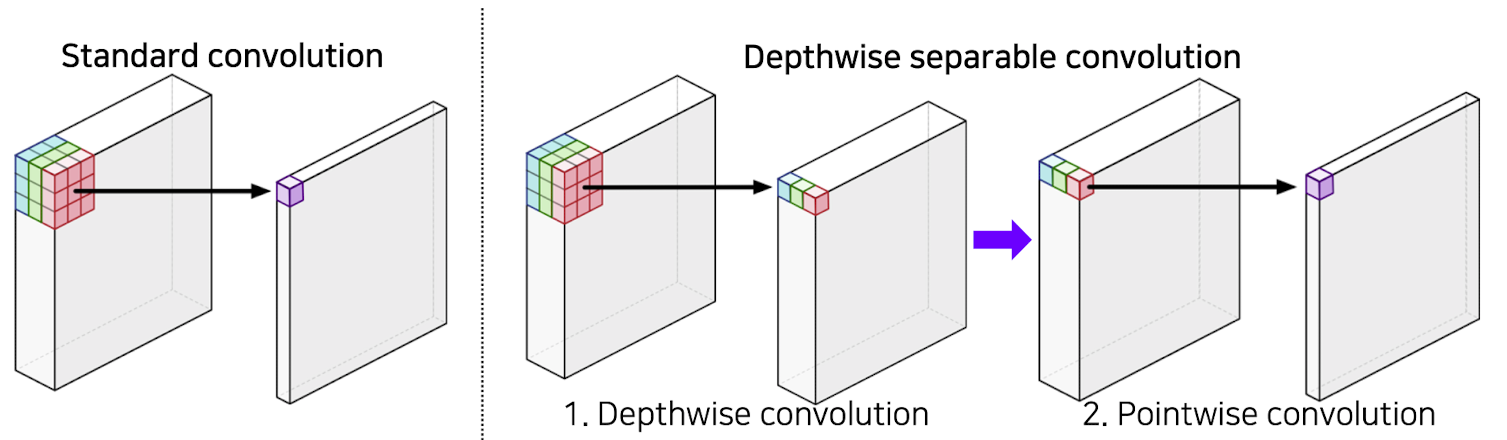
Depthwise separable convolution
Standard convolution의 과정을 두번에 걸쳐서 하게 된다.
1, Depthwise convolution : 채널별로 convolution하여 값을 뽑아와 각 채널별로 activation map이 나옴
2, Pointwise convolution : 1 X 1 convolution을 통해 하나의 값으로 뽑아옴
➡️ Standard conv :
➡️ Depthwise separable conv :
출처 : Naver BoostCamp AI Tech - edwith 강의
-
DeepLab의 전반적인 아키텍처
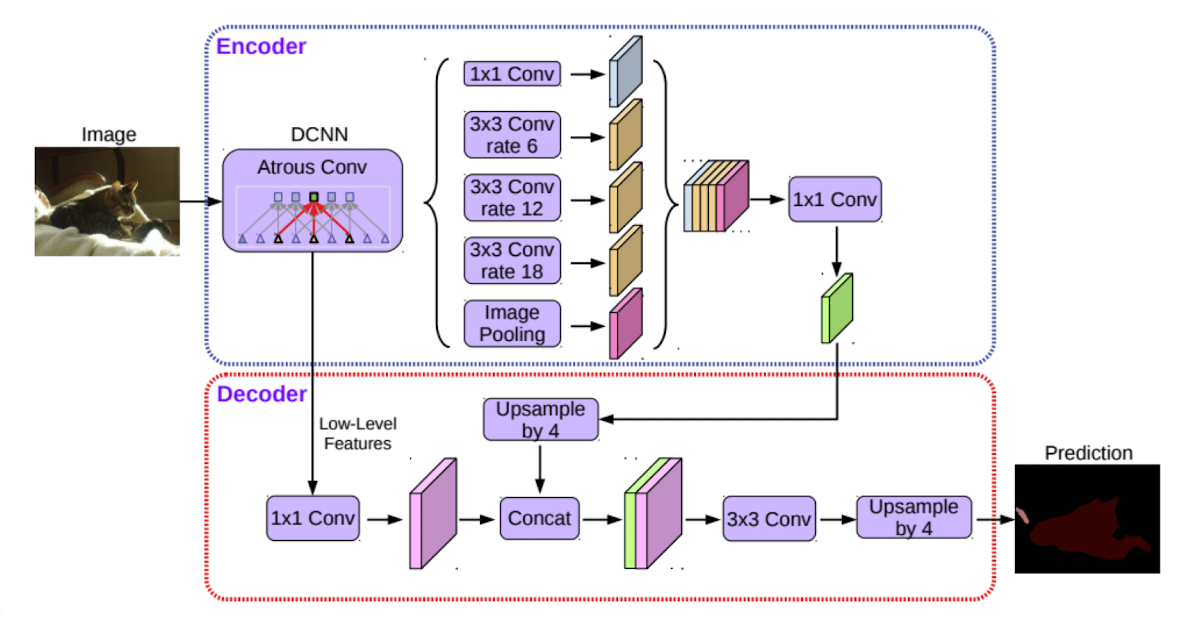
👉 처음 이미지가 들어가는 부분에서(DCNN 부분) Dilated convolution을 수행하는데 이로써 더 큰 receptive field를 가지도록 feature map을 얻어낸다.
👉 이때, DCNN부분에서 영역별로 연관된 주변물체 혹은 배경 정보의 거리가 모두 다르기 때문에 다양한 rate의 Dilated convolution을 수행함으로써 multiscale을 처리한다.이후 convolution을 통하여 합쳐준다.
👉 또 다른 특징으로는 decoder가 있는 것이 큰 특징이다.
low level의 feature와 Encoder에서 처리한 부분은 Upsampling을 통해 나온 결과물을 concat안 다음 convolution과 Upsampling을 통해 output을 도출한다.
Reference
Naver BoostCamp AI Tech - edwith 강의
