
빠르게
기본 컨셉 코드
import numpy as np
import time
size = 1000000
# list excution time
lst = range(size)
initial_time = time.time()
result_list = [(a * b) for a,b in zip(lst,lst)]
print(round(time.time() - initial_time, 4), "seconds")
#numpy array execution time
array = np.arange(size)
initial_time = time.time()
result_array = array * array
print(round(time.time() - initial_time, 4), "seconds")0.1292 seconds
0.0247 seconds💡 Numpy와 List의 차이
numpy는 데이터가 연속적으로 배열 & numpy는 저장공간에 해당 값이 저장되어 있으나 list는 data가 저장되어 있는 주소값이 저장되어 있음으로 연산 속도의 차이가 난다.
정리 링크 - https://velog.io/@ganta/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EA%B8%B0%EC%B4%886
✔️ 파이썬은 C언어로 만들어진 언어(CPython)
참고자료
https://medium.com/@trungluongquang/why-python-is-popular-despite-being-super-slow-83a8320412a9
⭐️ 경량화에서도 불필요한 계산 과정을 없애고 모델을 가볍게 하면서 속도를 빠르게 하는데 그 목표가 있다.
Acceleration
✔️ 컴퓨터의 연산속도에 영향읠 주는 요소들
- Bandwith(CPU register크기 관점) : Bandwith는 통신 링크가 처리 할 수 있는 시간에 따른 데이터의 양과 용량을 측정한 것이다.
- Throughput(병렬 처리 관점) : Throughput은 통신링크를 통해 성공적으로 전송/ 수신 된 실제 데이터 양이다.
- Latency(메모리의 종류에 따라<캐시, 메인메모리 등...>) : Latency는 패킷이 소스에서 대상으로 네트워크를 통과하는데 걸리는 시간이다.
참고 자료
https://www.techspot.com/article/1821-how-cpus-are-designed-and-built/
Hardwares(chip)
✔️ 컴퓨팅 작업의 구현의 Hardware관점에서 acceleration은 latency를 줄이고 Troughput을 늘리는 것이다.
✔️ AI가속화기의 종류
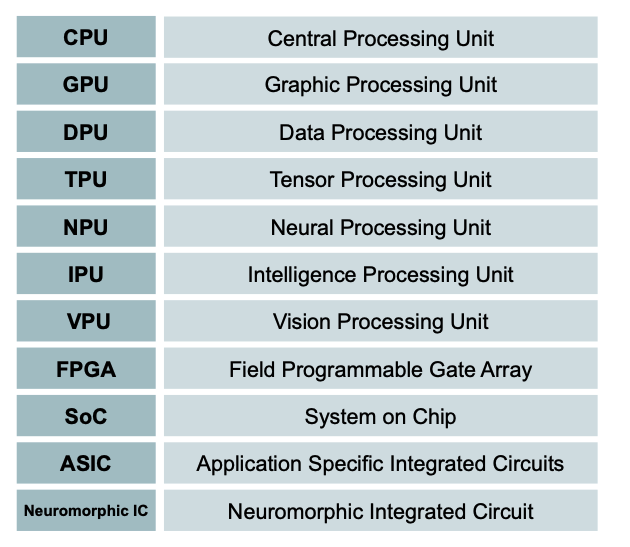
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ IPU : 코어랑 메모리간의 물리적인 거리가 GPU보다 작기 때문에 ML모델 학습 시 GPU보다 속도가 빠르다고 알려져 있다.
✔️ SoC(System on Chip) : 적은 Capacity안에 CPU, Cameram, Wifi등 다양한 기능을 넣음(애플 - m1 core)
✔️ FPGA : ASIC는 어떤 특수한 목적을 위해 만들어졌다면 FPGA는 약간 느슨한 형태로써 목표에 따라 조립하여 사용이 가능(아두이노 같은 것이라고 생각해도 된다.)
참고 자료
AI 가속화기 - http://www.hellot.net/new_hellot/magazine/magazine_read.html?code=202&sub=002&idx=52620
CPU VS GPU - https://www10.mcadcafe.com/blogs/jeffrowe/2017/03/16/the-continuing-importance-of-gpus-for-more-than-just-pretty-pictures/
SoC- https://www.techspot.com/article/2167-apple-m1-why-it-matters/
✔️ ARM : 모바일을 위한 CPU의 한 종류로써 설계도로써 존재한다.
Compression & acceleration
acceleration
✔️ Hardware(chip)성능은 accleration에 초점을 둠
✔️ 보통 "사람 (설계, 입력) → software (구현) → compile (번역) → hardware (실행) → output (출력)"순으로 이뤄지기에 Hardware를 새롭게 구현하기 보다는 많은 경우 software를 구현하고 hardware는 구현된 계산을(가능한 빠르게)수행을 해 준다.
Compression
✔️ hardware/model co-designs
압축은 보통 hardware와 software를 같이 디자인하여 model compression을 효과적으로 수행하는 쪽으로 진행이 된다.
참고 차료
https://arxiv.org/pdf/2007.00864.pdf
Deep learning compiler
✔️ 머신러닝 라이브러리(TF, Pytorch...)에서도 다양한 컴파일러가 존재한다.
✔️ 번역의 과정
"프레임 워크 사용한 코드 → 계산 그래프 생성기 → IR(Intermediate Representation)생성기 → 벡엔드 코드 생성기"
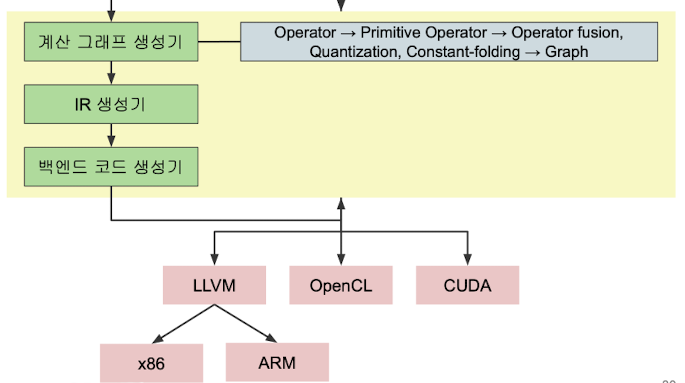
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️LLVM(Low Lwvwl Virtual Machine)
오픈소스 컴파일러 개발용 종합 패키지
출처 https://insalat.tistory.com/36
LLVM을 사용함으로써 다양한 언어와 다양한 Target device에 대하여 매칭 쌍 마다 컴파일러가 필요한 것이 아닌 input에 대한 컴파일러와 output에 대한 컴파일러가 있으면 되게 되었다.(곱을 합으로 바꿔 적은 수의 컴파일러가 필요하도록 바꿔줌)
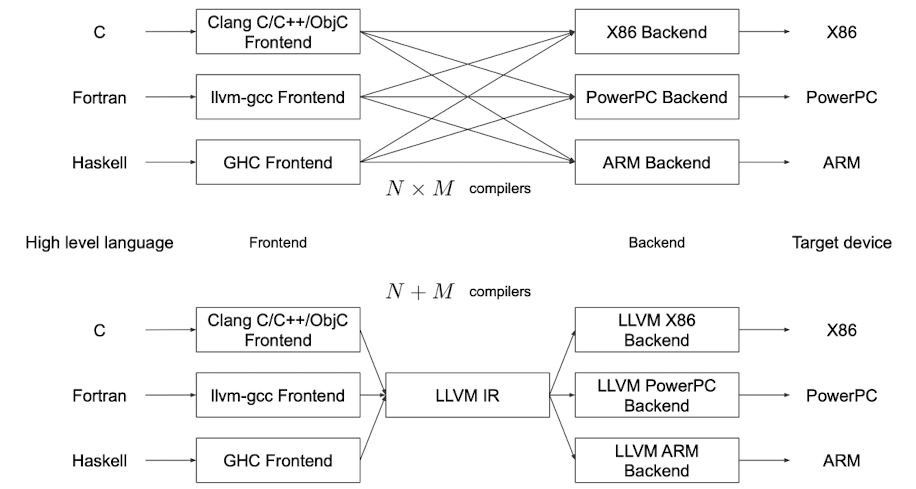
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ ML에서도 위와 같은 상황이 발생하게 되는데(라이브러리 사용 후 벡엔드 코드 생성과정) 중간의 복잡한 상황을 통합해 주기 위해 구글에서 개발한 MLIR이 최근에도 연구중에 있다.
참고 자료
https://medium.com/tensorflow/mlir-a-new-intermediate-representation-and-compiler-framework-beba999ed18d
✔️ DL 컴파일러에 적용된 하드웨어 별 최적화 개요

출처 : Naver BoostCamp AI Tech - edwith 강의
출처 : Naver BoostCamp AI Tech - edwith 강의
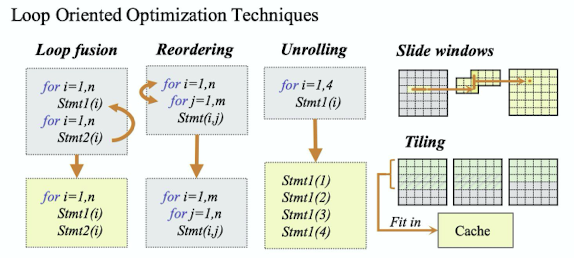
출처 : Naver BoostCamp AI Tech - edwith 강의
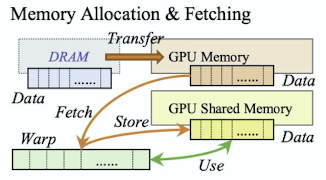
➡️ Slide windows
메모리 allocation하기 전 Slide window안에 있는 것들을 먼저 찾아 있으면 새롭게 메모리 할당을 하지 않음
➡️ Tiling
inner loop이 타일마다 배치가 되어 있고 outer loop가 왔다갔다 하면서 수행이 되어짐
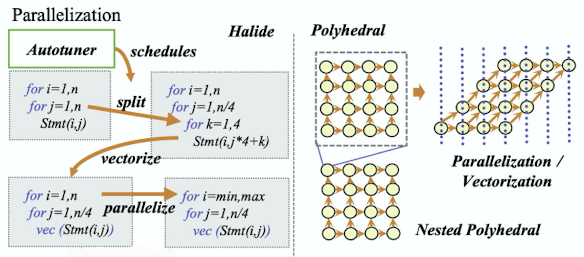
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ 루프로 인한 병렬처리 불가하여 병렬처리가 가능한 로직들로 바꿔주
참고 자료
https://arxiv.org/pdf/2002.03794.pdf
✔️ Polytope method
식을 병렬처리화되게 만들어 주는 방법
참고자료
https://en.wikipedia.org/wiki/Polytope_model#:~:text=The_polyhedral_method_treats_each,polytopes_into_equivalent,_but_optimized_(
✔️ Locality of reference
- Temporal locality : 한번 쓰인 코드는 짧은 시간안에 다시 쓰일 확률이 높다.
- Spatial locality : 내가 어느 위치의 코드를 참고하면 그 주변에 있는 것들도 참고하게 된다.(하나만 가져오는 것이 아닌 묶음 단위로 메모리에 올림)
- Branch locality : branch(if문)개수는 지금 찍고있는 point에 dependent하고 branch는 무한한게 아니라 유한하기 때문에 그 제약안에 있는것만 뽑아 미리 가져다 놓고 쓰자는 개념
- Equidistant locality : 어떤 패턴(for loop돌때) 이 루프는 멀리 떨어져 있는 메모리더라도 사용이 자주 되는 경우가 있어 이러한 점을 고려하여 메모리에 올림
참고자료
https://en.wikipedia.org/wiki/Locality_of_reference#:~:text=Temporal_locality_refers_to_the,within_relatively_close_storage_locations.
⭐️ 이러한 아이디어들을 이용하여 속도측면 성능을 올릴 수 있다!
✔️ Hardware-aware compression
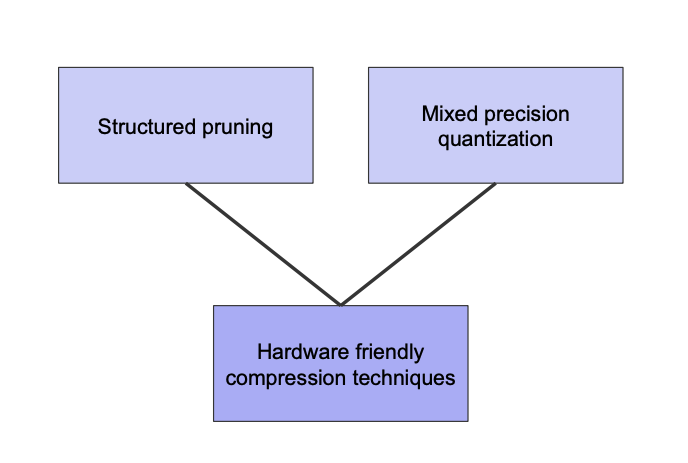
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ pruning, quantization같은 방법을 써서 DL컴파일러를 잘 알고 있으면 Hardware friendly하게 compression할 수 있다.
💡 하드웨어마다 model의 layer 에 대하여 좀 더 적은 precision으로 혹은 높은 precision으로 adaptive하게 만들 수 있다는 개념도 존재한다.
참고 자료
https://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_HAQ_Hardware-Aware_Automated_Quantization_With_Mixed_Precision_CVPR_2019_paper.pdf
✔️ trend와 미래 방향
1, Hardware-aware compression기술 사용
2, hardware accelerators의 실행 모델을 활용하는 압축 기술 개발
3, Joint and automated exploration of sparsity, precision, and value-similarity
4, Value-aware neural architecture search (NAS)와 hardware/model co-designs
5, 희소 행렬모양의 텐서에서의 구조 연산 촉진
Reference
Naver BoostCamp AI Tech - edwith 강의
