논문 원문 링크 : https://arxiv.org/abs/2103.00020
배경지식
Domain Shift
- 딥러닝 모델이 인간보다 성능이 낮은 이유 : train dataset에서 in-distribution performane’를 향상시키도록 학습하기 때문
- Domain(Distribution) Shift : train data와 test data의 분포 차이
Robustness
- 도메인 변화에 효과적인 모델 → robustness 높다
- Effective robustness : Distribution shift 하에서 정확도의 개선
- Relative robustness : Out-of distribution에서의 정확도의 개선
- Zero-shot CLIP 모델은 Effective robustness을 개선함
Introduction
- 과거의 컴퓨터 비전 모델들 - 주로 이미지만을 학습하여 성능 향상시킴 ⇒ 모델의 robustness와 일반화 능력에 한계
- 반면 언어 모델들은 대규모 언어 데이터를 학습하며 급속도로 발전
⇒ 언어모델처럼 대규모 데이터셋을 학습하는 방식이 이미지 인식 분야에서도 중요한 역할을 할 수 있다고 생각함
- CLIP : 대규모 이미지-자연어 쌍 데이터셋을 제작하고, contrastive learning 방법을 활용하여 학습함
당시 vision model의 대표 데이터셋은 ImageNet : 각 이미지에 대해 사람이 직접 라벨을 달아놓은 형태임 → 데이터 개수에 한계가 있음
CLIP의 해결방안
모델 개요 정리
- 인터넷에서 얻은 image-text pair 대규모 데이터셋을 이용하여, 이미지와 연관된 caption으로 pretrain시킴
- 그리고 자연어 지시문을 주면, zero-shot으로 모델을 downstream task에 적용 가능함
- 자연어를 supervision으로 주어 학습하여 대량의 이미지 데이터셋 라벨링 작업을 피할 수 있음 & 이미지 뿐만 아니라 자연어의 representation까지 얻을 수 있음
자연어 Supervision 학습하기
- 우선 대용량 데이터셋을 확보하기 위해 인터넷에서 데이터를 모으는 방법 선택
- but 인터넷 상에서 모은 데이터는 이미지별로 라벨이 안 달려있고, 정확도 보장도 안 됨
- 또 대용량 데이터셋 구축해야한다는 전제가 있어서, 사람이 직접 라벨 달아준다는 게 모순임
⇒ 해결책 : 자연어를 Supervision으로 사용하는 방법을 선택
- Supervision = 지도, 지시, 감독 의미함
- Supervision은 모델에게 이미지를 설명해주는 역할을 함
- 기존 ImageNet으로 학습하는 모델들에겐 Label 정보가 Supervision임
⇒ 인터넷 상에서 이미지마다 달려있는 자연어 문장을 그대로 Supervision으로 사용하자는 아이디어!
→ 4억장의 이미지-자연어 매칭 데이터셋 구축함
효율적인 학습 방법 선택
- 대용량 데이터셋 어떻게 학습시킬까?
- 기존 ImageNet 데이터셋처럼 Cross Entropy Loss로 학습할 수 없음 → why? 자연어는 label과 달리 특정 개수로 구분되지 않기 때문임, softmax로 구분하는 방식 불가능함
- 따라서 Contrastive Learning 방식 선택
Contrastive Learning 개념
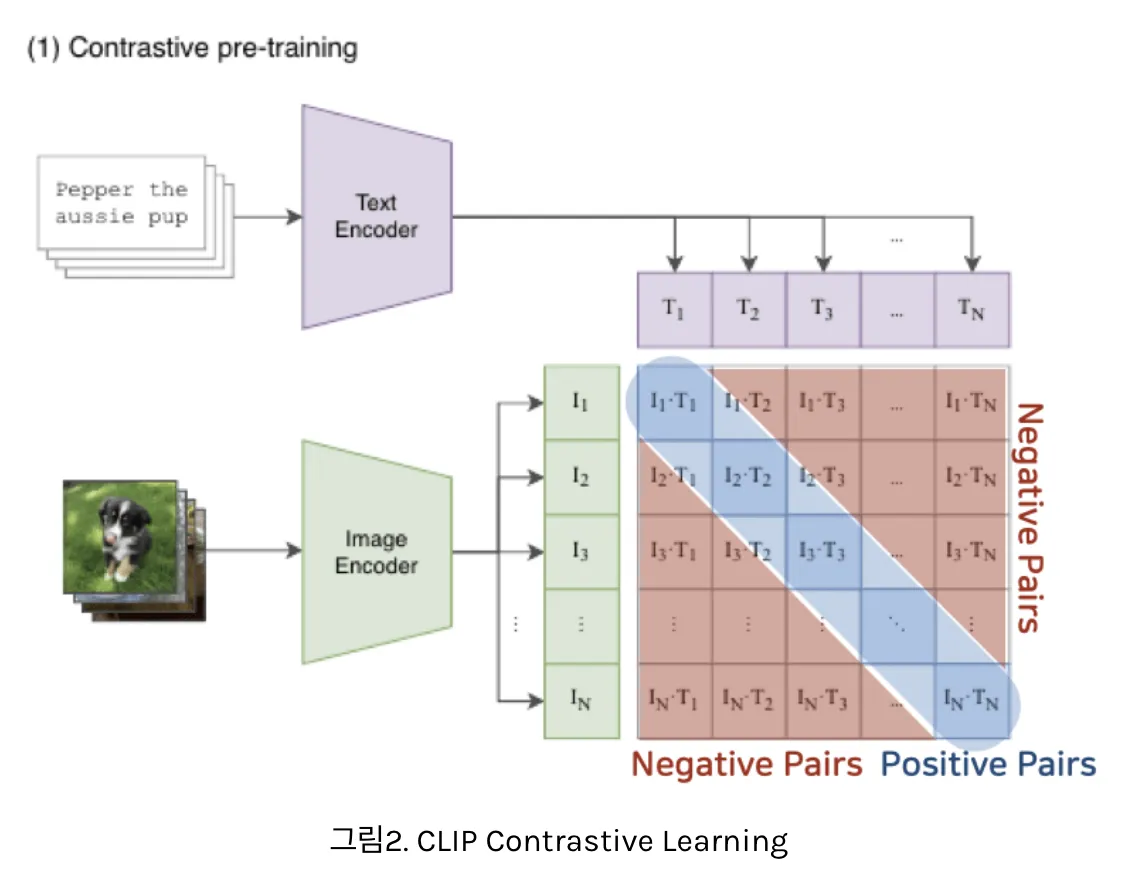
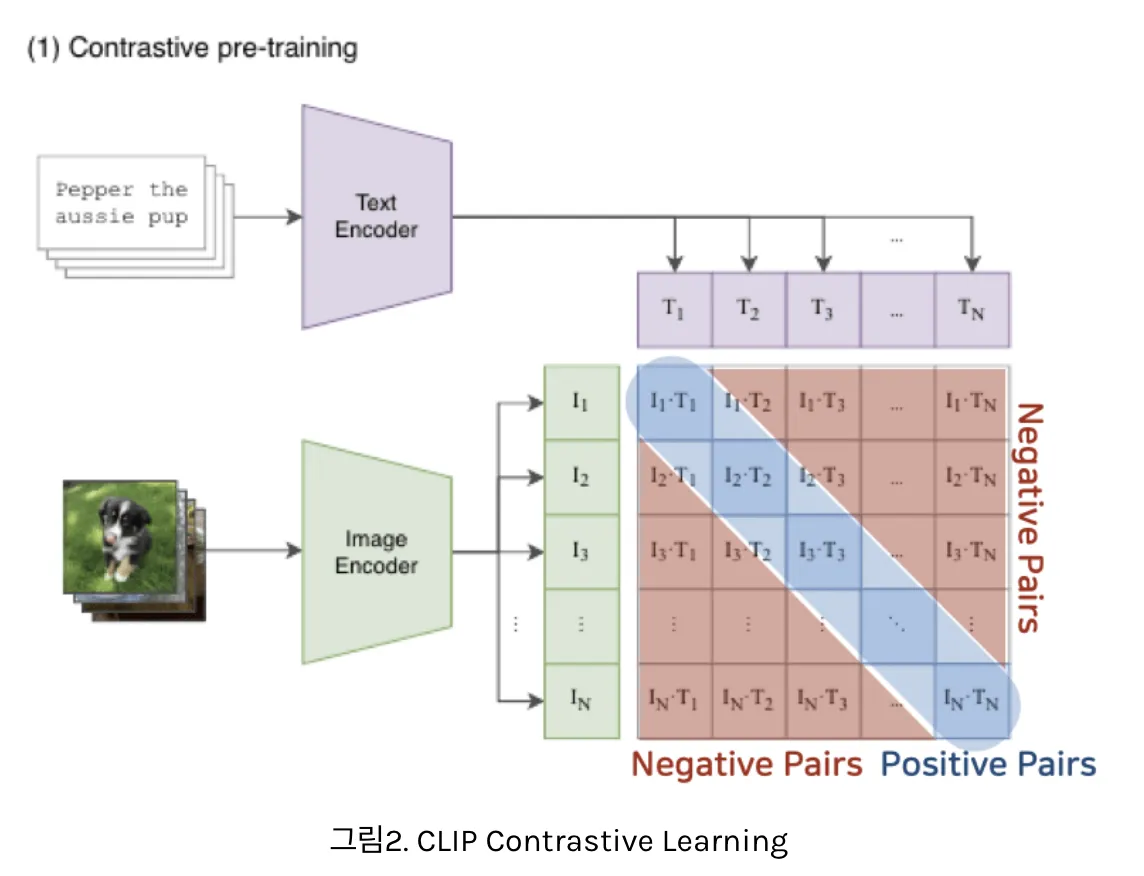
- 매칭되는 데이터 feature들끼린 가까워지도록, 매칭되지 않는 데이터 feature들끼린 멀어지도록 학습하는 방법
- 데이터를 대조해가며, 나랑 매칭되는 데이터는 가까워지도록, 다른 데이터는 멀어지도록 모델을 학습하는 방법
- Contrastive Learning 학습 방법은 Self Supervised Learning에서 진가를 발휘함 : label 정보가 없어도 어떠한 기준으로 나와 매칭되는지만 설정해주면 학습할 수 있기 때문임
- 입력 이미지에 증강 적용하여 동일한 이미지 버전끼린 가까워지도록, 다른 이미지 버전과는 멀어지게 학습
1) Contrastive Pre-training
- 배치 단위로 학습하는데, 1개의 batch = N개의 (image, text) pair으로 구성
- image, text를 동일한 embedding space로 보낸 후, positive pair에서의 코사인 유사도는 최대화시키고, negative pair에서의 코사인 유사도는 최소화함
- 텍스트는 text encoder를 이용해 벡터로 표현, 이미지는 image encoder를 이용해 벡터로 표현
- N개의 텍스트 벡터 & N개의 이미지 벡터 사이의 코사인 유사도 계산
- 총 NxN=개의 유사도 계산 값이 얻어짐
- N개의 Positive pair와 개의 negative sample(다른 (image, text) pair에서 나옴) 얻을 수 있음
- 유사도 값을 이용해 Cross Entropy Loss값을 계산하여 최적화
- 코사인 유사도 참고

Choosing & Scaling a Model
Image Encoder로 사용한 두 비전 모델
- ResNet-50
- Vision Transformer (ViT)
Text Encoder로 Transfomer 사용
- 마지막 token에서 추출된 feature를 linear projection 해주어 image feature와의 차원 맞춰줌
⇒ 캡션의 길이가 어떻게 되건, image feature와의 차원 맞춰짐
Zero-Shot 예측 방법
- CLIP의 최고 장점 : zero shot prediction이 가능 ( 한번도 학습하지 않은 문제를 맞추는 방법)
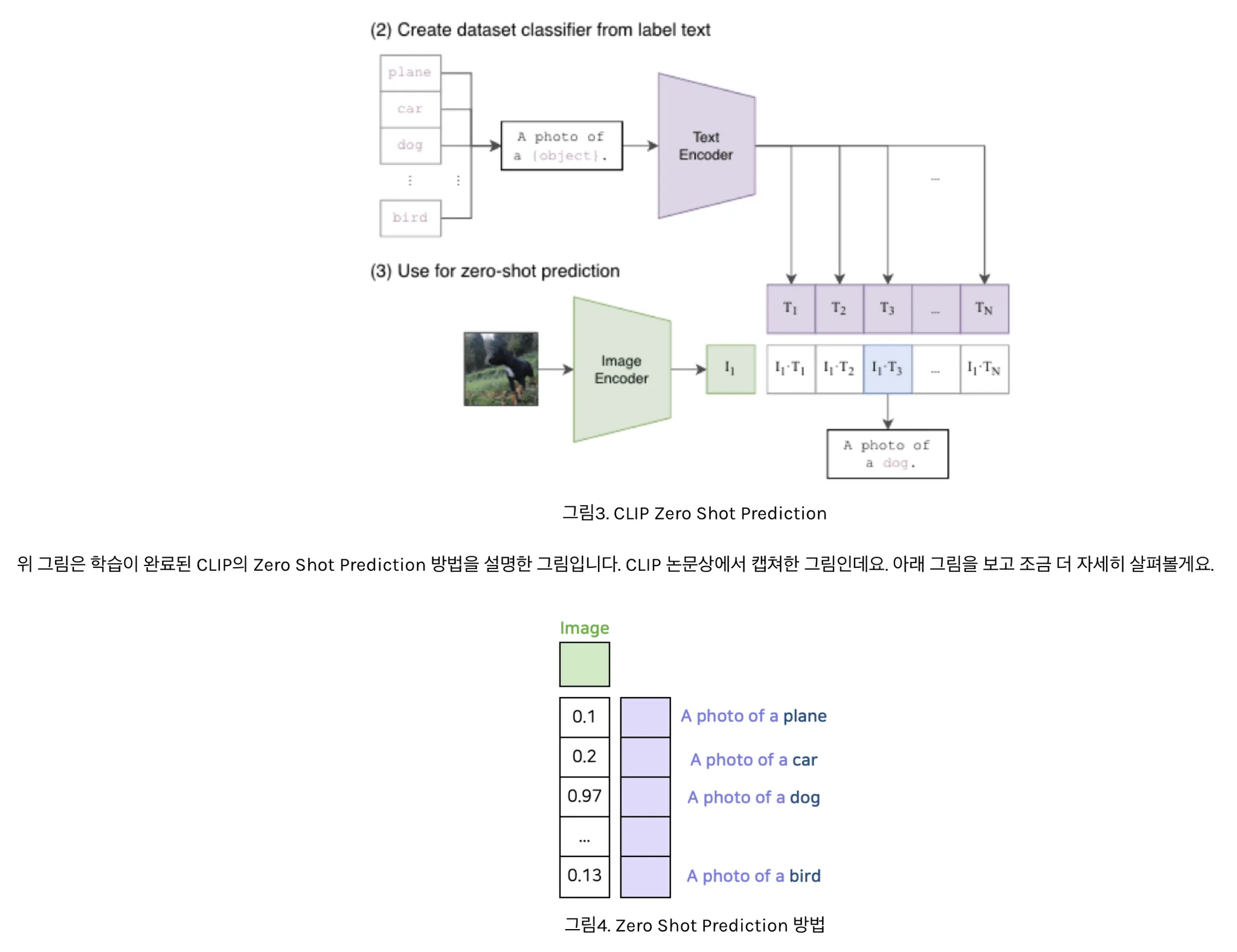
- 이미지 classification 테스크의 경우, 이미지가 주어지면 데이터셋의 모든 class와 (image,text) 쌍에 대해 유사도 측정하여 가장 그럴싸한 쌍을 출력함
- 데이터셋의 class 이름을 “A photo of a {class}” 형식의 문장으로 바꾼뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식
- class 이름은 대부분 한 단어 정도인데 비해 pretrain에 이용했던 인터넷 캡션 데이터는 그렇지 않기 때문에 이렇게 함
zero shot prediction 구성하는 feature 연산 부분만 그린 부분
- 해당 이미지를 가장 잘 설명하는 text feature와 코사인 유사도 값이 가장 크게 나옴
- 이런 방법을 통해 CLIP은 고정되지 않은 개수의 클래스에 대해 예측 가능
- 기존의 label을 사용하여 이미지 클래스 구분하는 방식이 아닌, 이미지 & 자연어의 정렬 align을 학습했기 때문임

Reference

안녕하세요😊 컴퓨터비전을 공부하고 있는 대학원생입니다 🙌