CLIP 논문 리뷰
1. Introuduction
- 이 논문은 기존의 컴퓨터 비전 모델과 언어 모델의 한계를 넘어서려는 새로운 시도
- 2023년 현재에는 GPT-4, LLaVA등 다양한 Large Multimodal Model (LMM)들이 발표되고 있는데요.
- CLIP은 이러한 LMM들의 시초 연구라고도 할 수 있는 모델
- 과거의 컴퓨터 비전 모델들은 주로 이미지만을 학습하여 성능을 향상시켜왔음
- 하지만 이러한 접근 방식은 모델의 강건함과 일반화 능력에 한계
- 반면, 언어 모델들은 대규모 언어 데이터를 학습하며 급속도로 발전
- 이러한 배경에서, 저자들은 언어 모델처럼 대규모 데이터셋을 학습하는 방식이 이미지 인식 분야에서도 중요한 역할을 할 수 있다고 생각
- CLIP은 대규모 이미지-자연어 쌍 데이터셋을 제작하고, contrastive learning 방법을 활용하여 학습
2. CLIP 이전에 존재했던 방법들의 문제점
- CLIP이 발표된 시점이 2021년이니까, 이 시점을 기점으로 크게 두가지 카테고리(Vision Model과 Language Model)로 구분하여 기존 방법들의 발전 방향을 생각해보자.
2021년 이전의 Vision Model 발전 방향
- Vision Model은 전통적으로 이미지를 입력받아 어떻게 모델을 구성하면 더 좋은 표현을 학습하는지를 고민해왔음.
- Inception[1], ResNet[2] 등은 효율적인 모듈을 구성하여 깊은 모델을 만드는 방법을 고민
- SENet[3], BAM[4], CBAM[5] 등은 Attention 모듈을 적용하는 방법을 제안
- 또 2021년 당시 Vision Model의 트렌드는 Transformer[8] 구조를 적용하는 것
- 이러한 트렌드에 맞추어 발표된 모델이 ImageGPT[6], Vision Transformer[8]
- 하지만 이미지만 학습한 모델은 고질적으로 일반화 능력이 부족하고 작은 노이즈에도 취약한 약점
2021년 이전의 Language Model 발전 방향
- Language Model은 Vision Model 보다 한 발 앞서 나아가는 형태로 발전했었음
- Vision Model이 Inception[1], ResNet[2] 등 다양한 CNN 모델을 발표하며 발전하던 시기, Language Model은 seq2seq 방식의 한계로 인해 크게 나아가지 못하고 있었죠.
- 이후 2017년 Transformer[8]의 발표를 기점으로 큰 변화가 생김
- 마치 Vision Model이 CNN 발명에 힘입어 크게 도약한것 처럼, Language Model도 Transformer[8] 구조의 발명에 힘입어 한 단계 도약
- Transformer[8]는 seq2seq 구조와 달리 긴 문장도 효과적으로 처리할 수 있기 때문
- 이후 GPT 시리즈들 (GPT-1[9], GPT-2[10], GPT-3[11]), BERT[12] 등 다양한 초거대언어모델 (LLM)이 발표
- 이때부터 Language Model은 LLM의 시대가 열리게 되죠.
- 자, 이 시점에서 CLIP 저자들은 이런 생각을 합니다.
- Vision Model도 LLM과 같은 방향으로 간다면 한 단계 더 발전할 수 있지 않을까?
- LLM에는 크게 두가지 조건이 있는데요.
- 첫 번째는 큰 모델이고,
- 두 번째는 큰 데이터
- 당시 Vision Model의 대표 데이터셋은 ImageNet
- 데이터의 양이 적은편은 아니지만, 각 이미지에 대해 사람이 직접 Label을 달아놓은 형태의 데이터셋
- 그 말은 아무래도 데이터의 개수에 한계가 있다는 뜻
3. CLIP 의 해결방안!
- 대용량 Image-Text 데이터는 기존 Vision Model로 학습할 수가 없는데요.
- 어떻게 모델을 구성하여 효과적으로 Image-Text 데이터셋을 학습할 수 있었는지 살펴보겠습니다.
3-1. 자연어 Supervision 학습하기
- CLIP 저자들은 우선 대용량의 데이터셋을 확보하기 위해 인터넷에서 데이터를 모으는 방법을 선택
- BUT, 인터넷상에서 모은 데이터는 이미지별로 Label이 달려있지 않을 뿐더러, Label이 있는 데이터를 찾는다고 해도 그 정확도를 보장할 수 없는 문제
- 또 애초에 대용량 데이터셋을 구축해야 한다는 전제가 있기 때문에, 사람이 직접 Label을 달아준다는 생각이 모순
- 해결책: 자연어 (Natural Language)를 Supervision으로 사용하는 방법을 선택
- Supervision은 지도, 지시, 감독 등의 뜻을 갖는 단어
- Supervision은 모델에게 이미지를 설명해주는 역할
- 기존 ImageNet으로 학습하는 모델들에게는 Label 정보가 Supervision
- 인터넷상에서 이미지마다 달려 있는 자연어 문장을 그대로 Supervision으로 사용하자는 아이디어

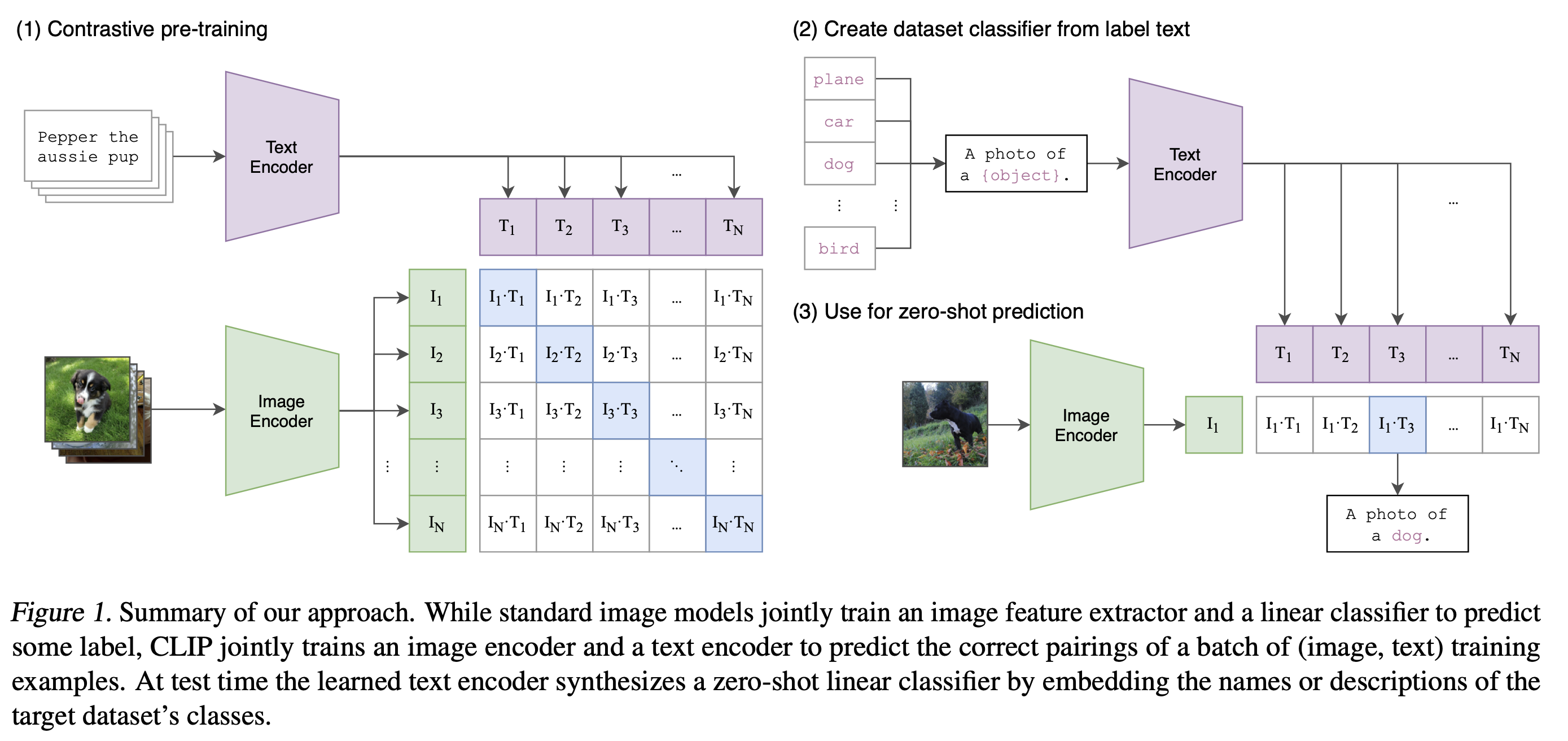
- 왼쪽 이미지의 가장 위에는 강아지 이미지
- 오른쪽 뭉터기 가장 위에는 이 이미지를 설명하는 자연어 (Pepper the aussie pup)
- CLIP은 인터넷으로부터 4억장의 이미지-자연어 매칭 데이터셋을 구축
3-2. 효율적인 학습 방법 선택하기
- 대용량 데이터셋을 어떻게 학습해야 할까요?
- 기존 ImageNet 데이터셋처럼 Cross Entropy Loss로 학습할 수는 없습니다.
- 왜냐하면 자연어는 Label과 달리 특정 개수로 구분되지 않기 때문
- 이미지 마다 매칭되어 있는 설명 문장은 전부 다를거잖아요.
- 따라서 Softmax로 구분하는 방식의 학습 방법은 가능하지 않습니다.
- 이를 해결하기 위해, 저자들이 선택한 방법은 Contrastive Learning
- Contrastive는 ‘대조하는’ 이라는 뜻을 가진 단어
- 따라서 Contrastive Learning은 매칭되는 데이터 Feature들끼리는 가까워지도록, 나머지 Feature들 끼리는 멀어지도록 학습하는 방법
- 데이터를 대조해가며, 나랑 매칭되는 데이터는 가까워지도록, 다른 데이터는 멀어지도록 모델을 학습하는 방법
- Contrastive Learning 학습 방법은 Self Supervised Learning에서 그 진가를 발휘
- Label 정보가 없어도 어떠한 기준으로 나와 매칭되는지만 설정해주면 학습을 할 수 있기 때문
- 이렇게 Contrastive Learning을 사용한 대표적인 Self Supervised Learning 모델은 SimCLR[13]
- 입력 이미지에 Augmentation을 적용하여 동일한 이미지 버전끼리는 가까워지도록, 다른 이미지 버전과는 멀어지도록 학습
- 놀라운건 이렇게 Label 정보 없이 학습했음에도 Label 정보로 학습한 모델에 버금가는 표현력을 학습했음을 실험적으로 증명했다는 점
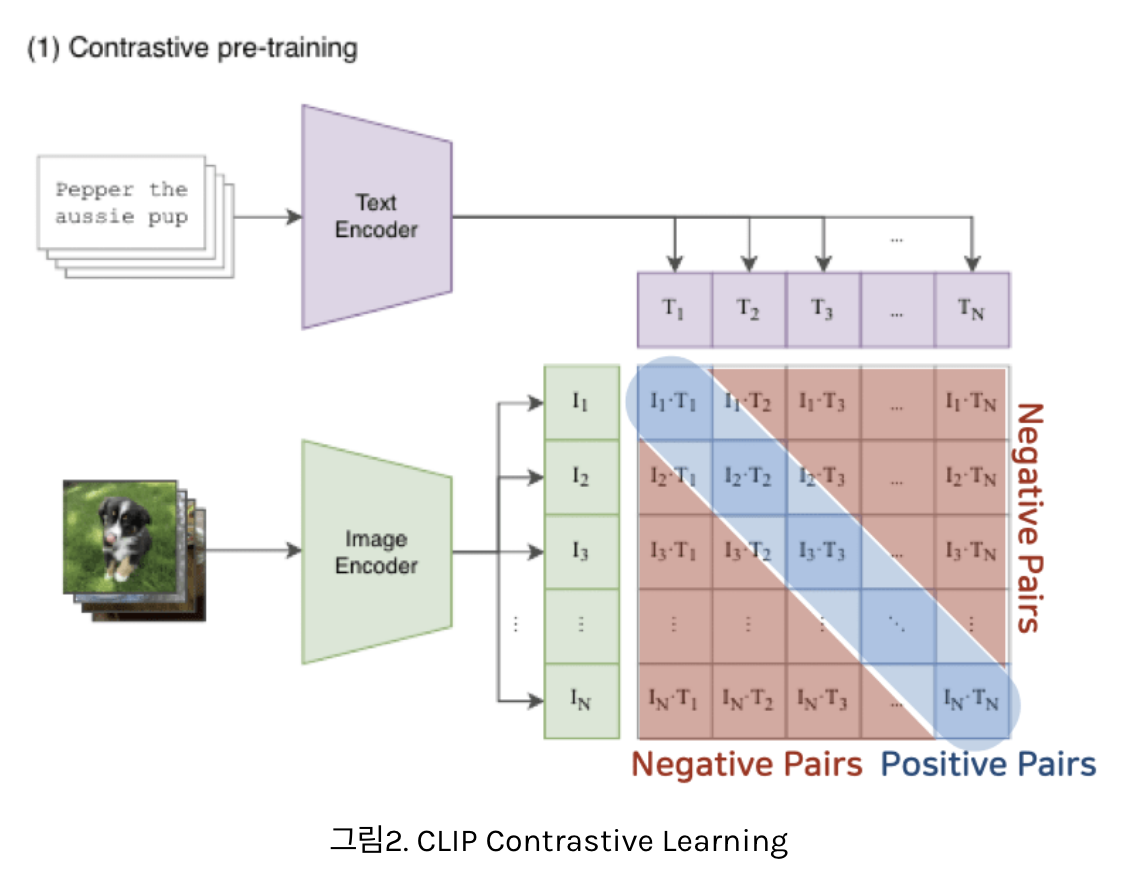
- 그럼 총 N개의 Image Feature가 있고, 마찬가지로 N개의 Text Feature가 추출되어 있는 상황이죠.
- 이들 각각을 매칭해보면 총 NxN개의 조합이 나오는데요.
- Contrastive Learning은 나와 매칭되는 조합은 가까워지도록, 그 외의 조합은 멀어지도록 학습하는 방법이라고 했죠.
- 이때 가까워진다는 의미는 여기서는 두 Feature의 Cosine Similarity가 커지는 방향
- 두개의 Feature가 공간상에서 가까운 각도에 위치할수록 Cosine Similarity는 큰 값을 갖기 때문이죠.

- 반대로 나머지 쌍과는 멀어지도록 모델을 학습
- 여기서 모델은 Image Encoder와 Text Encoder를 의미

3-3. 적절한 Encoder 선택하기
- Image Encoder는 다양한 Vision Model들이 가능
- 대표적으로 ResNet[2], ViT[7]
- ResNet[2]은 조금 더 표현 추출 능력을 강화하기 위해
- 마지막 Global Average Pooling 부분을 수정
- 여기에 Attention 모듈을 추가한 Attention Pooling으로 적용
- ViT[7]는 기존 구성 거의 그대로 사용
- Text Encoder는 Transformer[8]를 사용
- 마지막 Token에서 추출된 Feature를 Linear Projection 해주어 Image Feature와의 차원을 맞춰줌
설명 문장의 길이가 어떻게 되건, Image Feature와의 차원을 맞춰줌- TODO: 이것이 어떻게 가능한지? 공부해야함
- 아마
BERT구조를 자세히 뜯어보면 나올듯
- 아마
- 마지막 Token에서 추출된 Feature를 Linear Projection 해주어 Image Feature와의 차원을 맞춰줌
3-4. Zero Shot 예측 방법
- 기존 Vision Model과 달리 이미지만을 학습하지 않고 이미지-자연어 쌍을 학습했으니 뭔가 다른 기능도 가능할것 같은데요.
- CLIP의 최고 장점: Zero Shot Prediction(말 그대로 한번도 학습하지 않은 문제를 맞추는 방법)이 가능
- 이러한 기능은 기존 ImageNet으로 학습한 모델에서는 기대하기 어려웠는데요.
- 왜냐하면 Supervised Learning 방식으로는 학습하지 않은 클래스를 예측하는게 태생적으로 불가능하기 때문이죠.
- CLIP이 Zero Shot Prediction을 어떻게 하는지 그 방법을 먼저 살펴볼게요.
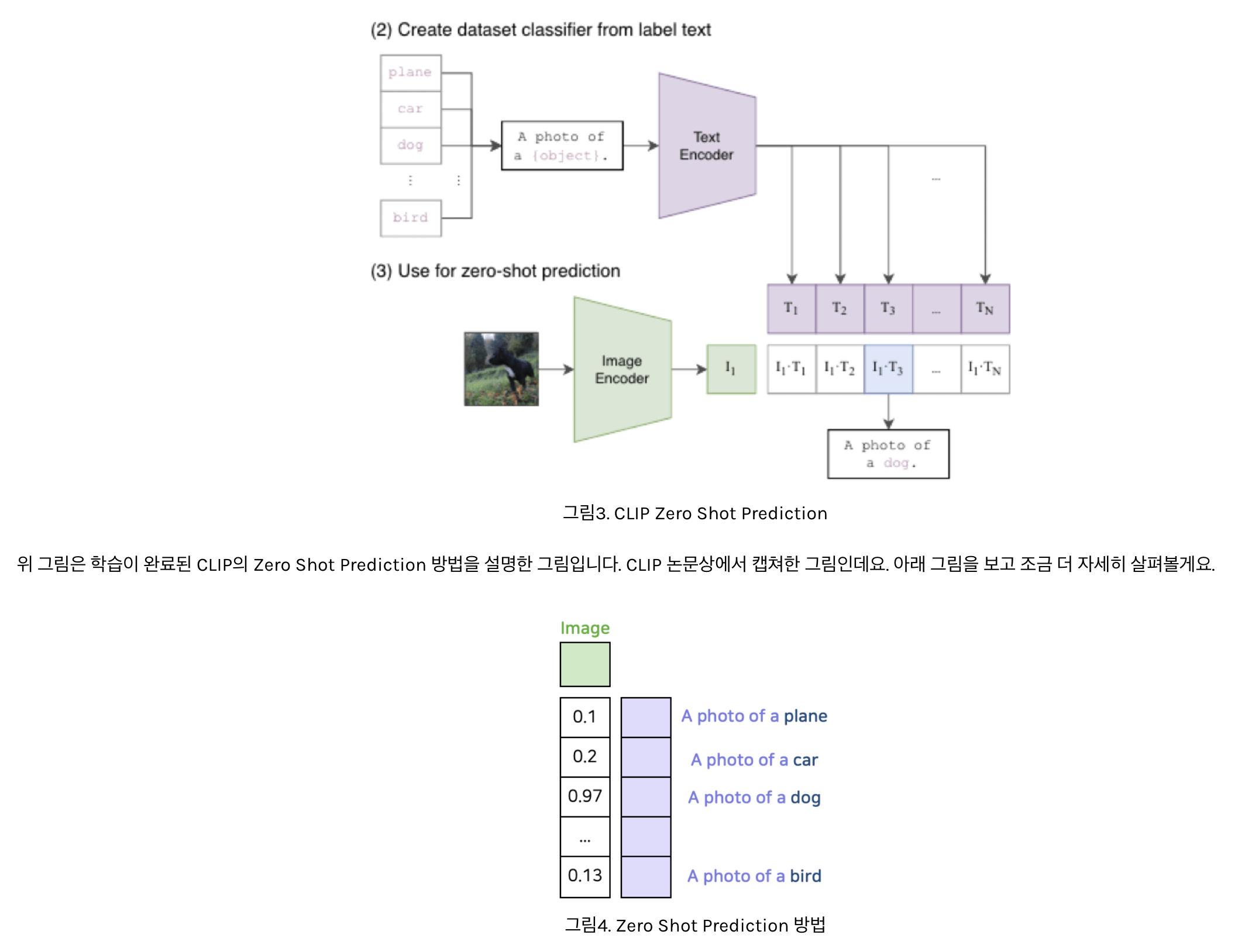
- 위 그림은 Zero Shot Prediction을 구성하는 Feature 연산 부분만 도식화한 그림
- 그럼 해당 이미지를 가장 잘 설명하는 Text Feature와의 Cosine Similarity 값이 가장 크게 나올겁니다.
- 왜냐하면 CLIP이 바로 그렇게 학습했기 때문이죠.
- 이러한 방법을 통해서 CLIP은 고정되지 않은 개수의 클래스에 대해 예측이 가능합니다.
- 이는 기존의 Label을 사용하여 이미지의 클래스를 구분하는 방식이 아닌, 이미지와 자연어의 정렬 (Align)을 학습한 덕분
4-1. Zero Shot Transfer
- 이번 실험에서 살펴보고자 하는건 결국 ‘CLIP이 얼마나 좋은 표현을 학습했는지
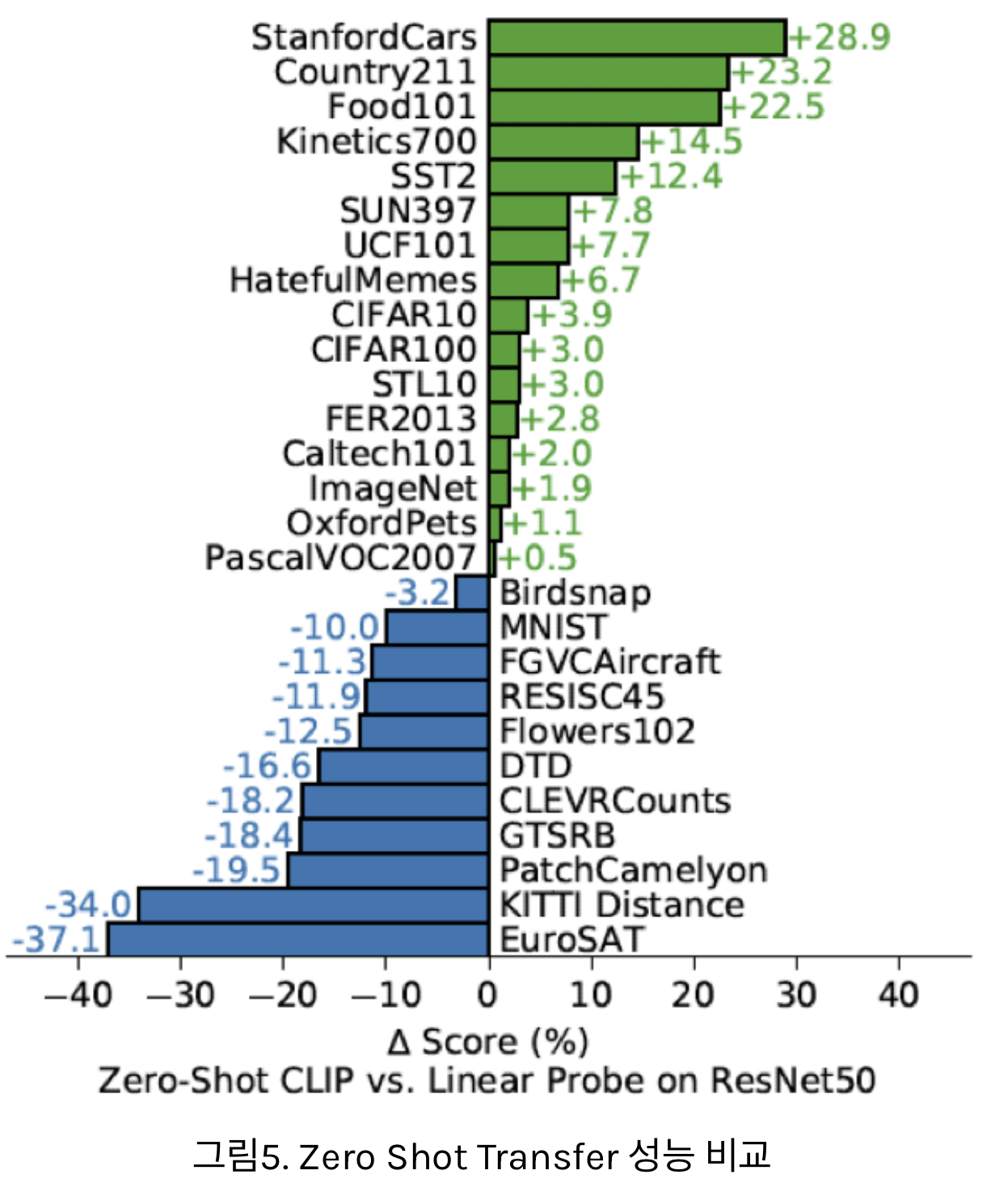
- 각 데이터셋에 대해 CLIP의 Zero Shot Prediction 성능과 Linear Probe 성능을 비교한 그래프
- Linear Probe란 학습이 완료된 Encoder를 가져와 Supervised Learning으로 Classifier만 재학습해주는 방법
- 만약 Encoder가 좋은 표현을 잘 학습했다면, 단순히 Classifier만 재조정 해주어도 높은 성능이 나올 것이라는 전제가 깔려있는 방법
- 결과
- 위의 절반에 가까운 데이터: CLIP의 Zero Shot > Linear Probe (일반적인 표현 학습만으로 풀 수 있는 데이터셋에서는 성능이 좋은 모습을 보이고 있습니다. )
- 허나, 세부적인 표현 학습이 필요한 Fine Grained Classification 데이터셋에서는 Zero Shot < Linear Probe
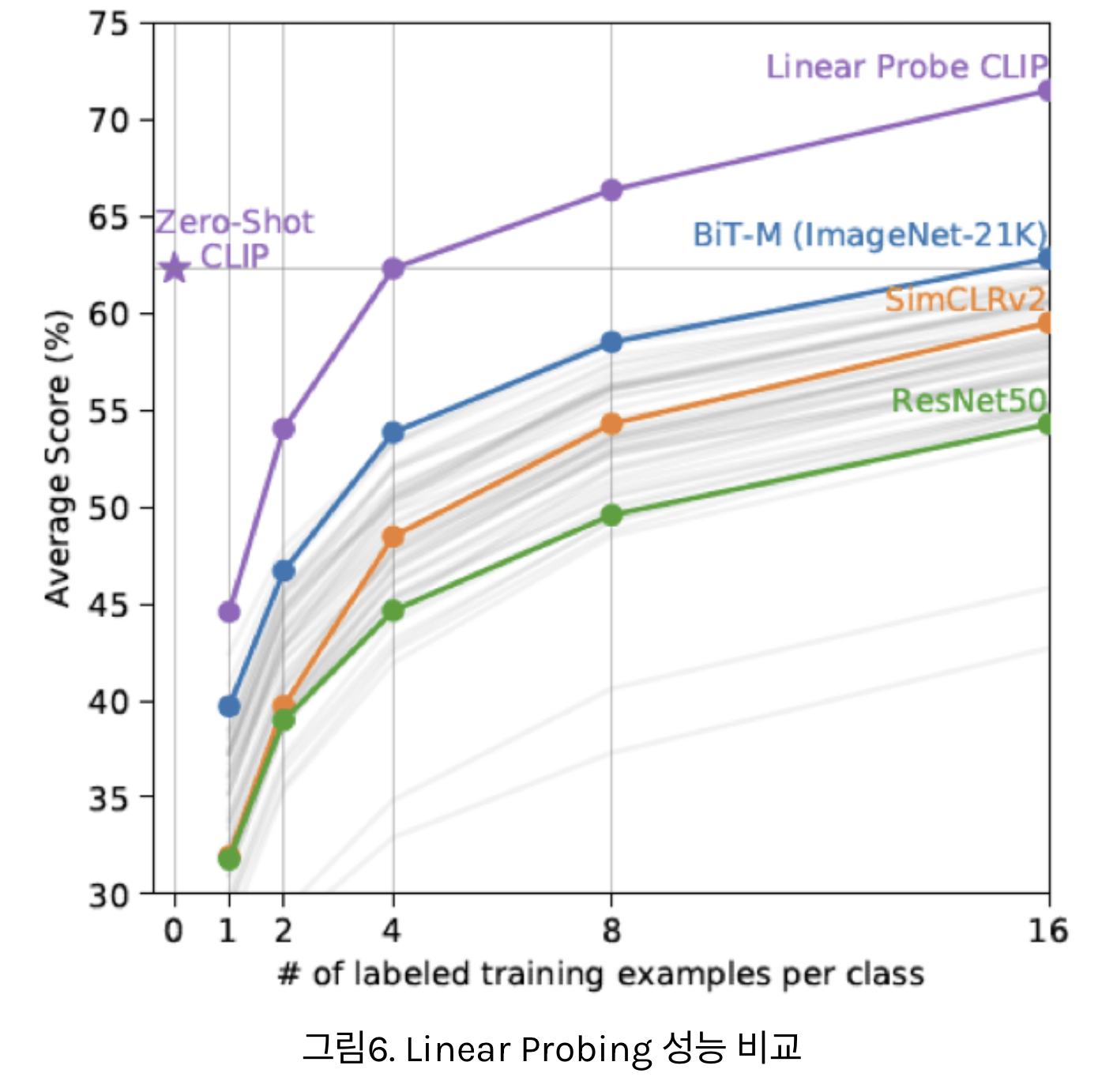
- 위 실험은, CLIP과 다른 모델들의 Linear Probing 성능을 비교한 그래프
- x축은 Linear Probing에 사용한 클래스당 데이터 개수를 의미
- 사전 학습이 완료된 상태에서 몇개의 대표 데이터만을 사용하여 Classifier를 학습했을때 누가 더 성능이 좋은지를 비교한것
- 흥미로운 점은 우선 CLIP 모델이 모든 면에서 다른 모델들보다 Linear Probing 실험에서 좋은 성능을 보인다는 점
- 기존의 SimCLR[13], BiT 등 좋은 표현을 학습한다고 알려진 다른 방법들보다 좋은 표현을 학습한다는 점이 검증된 것
- CLIP의 Zero Shot 성능은 클래스당 4개의 데이터를 학습한 CLIP 모델과 비슷한 수준
- 이를 통해 CLIP의 Zero Shot 성능이 상대적으로 얼마나 좋은지를 알 수 있습니다.
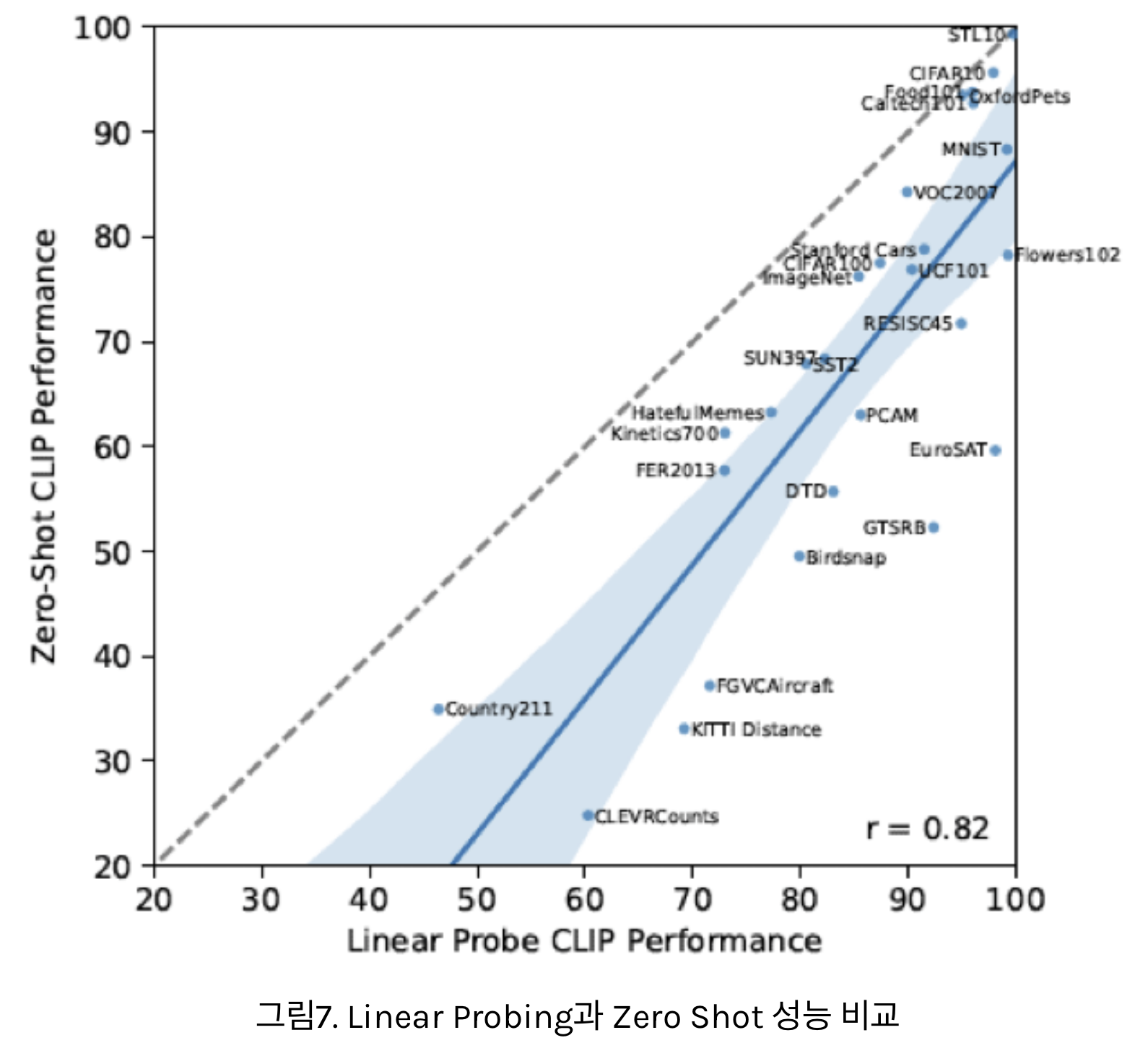
- 위 그림은 CLIP 모델만을 사용하여 Zero Shot 성능과 Linear Probing 성능을 비교한 그래프
- 아무래도 동일한 사전학습을 한 모델에서는 Linear Probing의 성능이 더 좋은 모습을 보이고 있음
4-2. Representation Learning
- 하지만 이렇게 Zero Shot Prediction 성능으로 해당 모델이 좋은 표현을 학습했는지를 검증하는 방법은 익숙하지 않은데요.
- 보통은 Fine Tuning 성능과 Linear Probing 성능을 통해, 학습한 표현력을 비교하기 때문이죠.
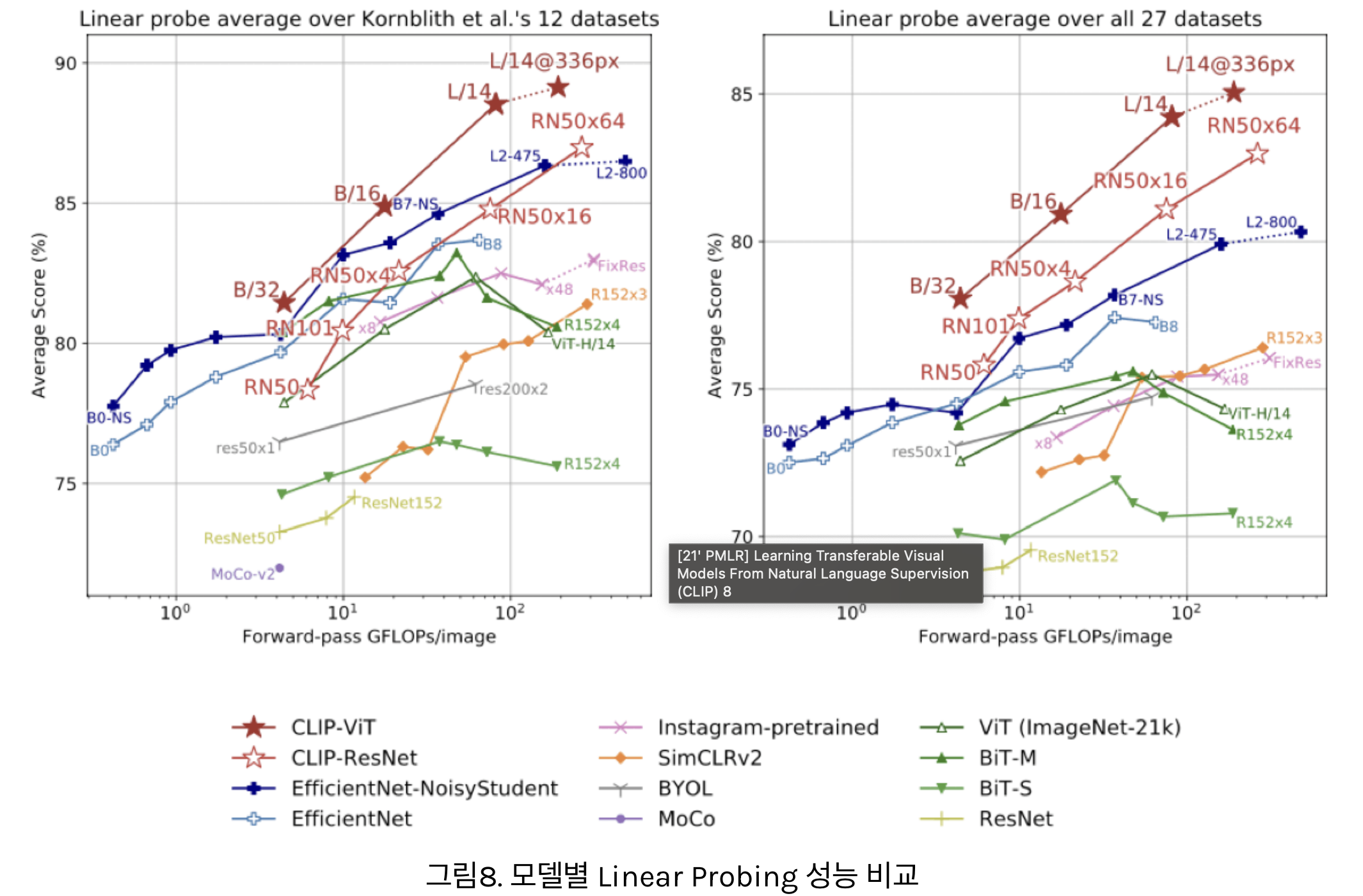
- 위 그림은 다양한 데이터셋에 대해, 다양한 모델들의 Linear Probing 성능을 비교한 그래프입니다.
- Linear Probing 테스트는 Feature Extractor 부분은 고정해 놓은채로 Classifier 부분만 재학습하여 하는 테스트입니다.
- 따라서 Linear Probing 성능은 해당 모델의 Feature Extractor가 얼마나 범용적이고 효과적인 표현을 학습했는지를 대표하는 평가방식으로 사용되어 왔습니다.
- 이러한 Linear Probing 테스트에서 CLIP 모델이 기존 모델들보다 좋은 성능을 냈다는 의미는, 그만큼 이미지-자연어 쌍을 Contrastive Learning 으로 학습하는 방법이 우수함을 입증한다고 할 수 있습니다.
4-3. Robustness to natural distribution shift
- 기존 Vision Model들의 공통적인 한계: Robustness가 현저하게 떨어진다는 점
- 예를 들어
- 학습한 데이터셋에서 노이즈가 조금 섞여 들어간다거나,
- 텍스쳐가 변한다면 성능이 아주 크게 하락
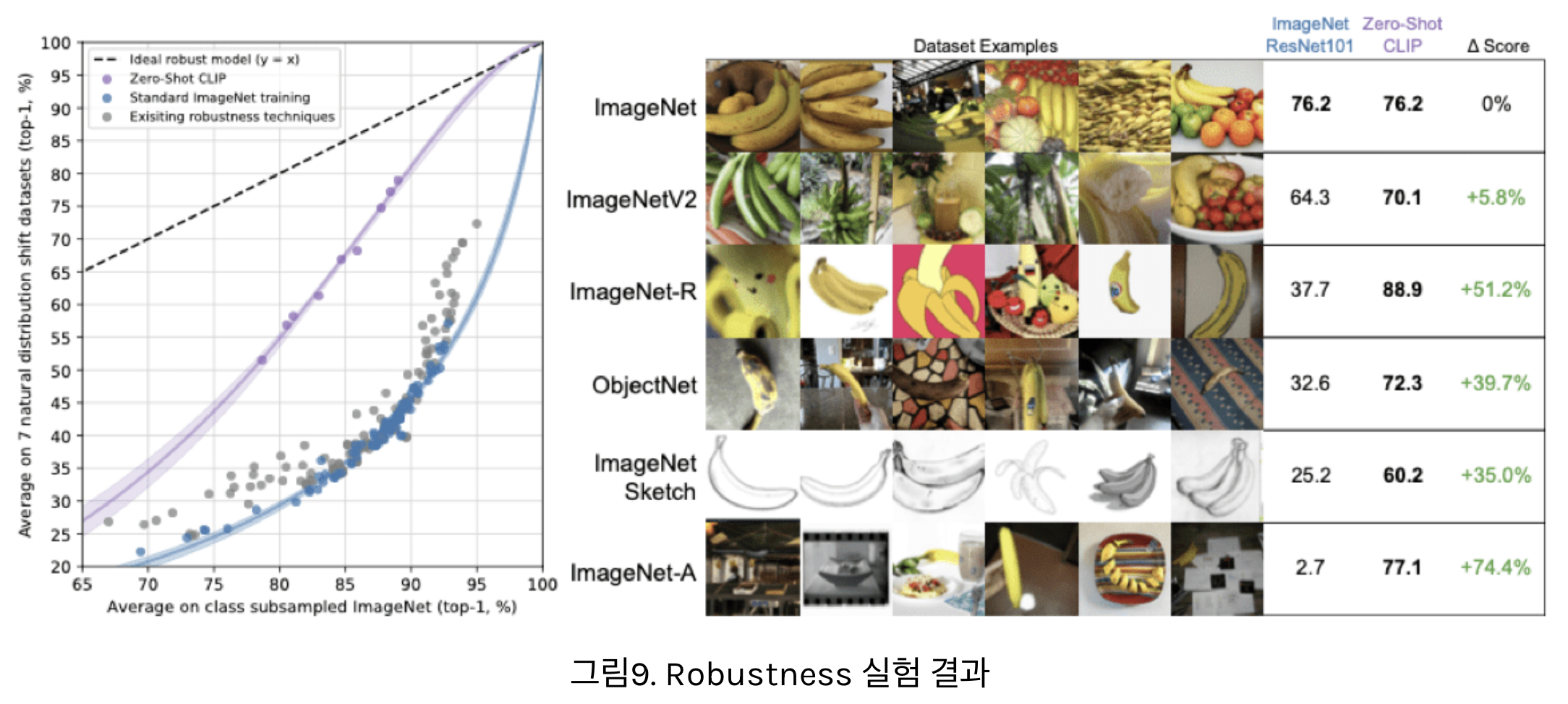
- 위 그림은 ImageNet에 약간의 변형을 준 데이터셋에 대한 성능을 비교한 자료
- 기존 ImageNet과 달리 스케치 형태의 데이터이거나 Adversarial Attack이 추가된 형태등을 확인할 수 있음
- 우선 놀라운건 모든 데이터셋에 대해 기존 ResNet[2]보다 CLIP의 Zero Shot 성능이 더 좋은 모습을 보인다는 점인데요.
- 특히 기존 ImageNet의 특성과 달라지는 데이터일 수록 더욱 큰 성능 차이를 보였습니다.
- 예를 들어 ImageNet으로 학습한 CNN은 모양(Shape)을 잘 구분하지 못하고 텍스쳐(Texture)에 편향되어 있다고 알려져 있는데요[14].
- 이에 따라 ImageNet Sketch 데이터셋에서는 기존 ResNet[2] 모델은 형편 없는 성능을 보여주고 있죠.
- 반면 CLIP 모델은 기존 ImageNet 성능에서 크게 떨어지지 않는 성능을 보여주고 있습니다.
5. 토론
CLIP의 Zero Shot 기능VS인간의 Few Shot 기능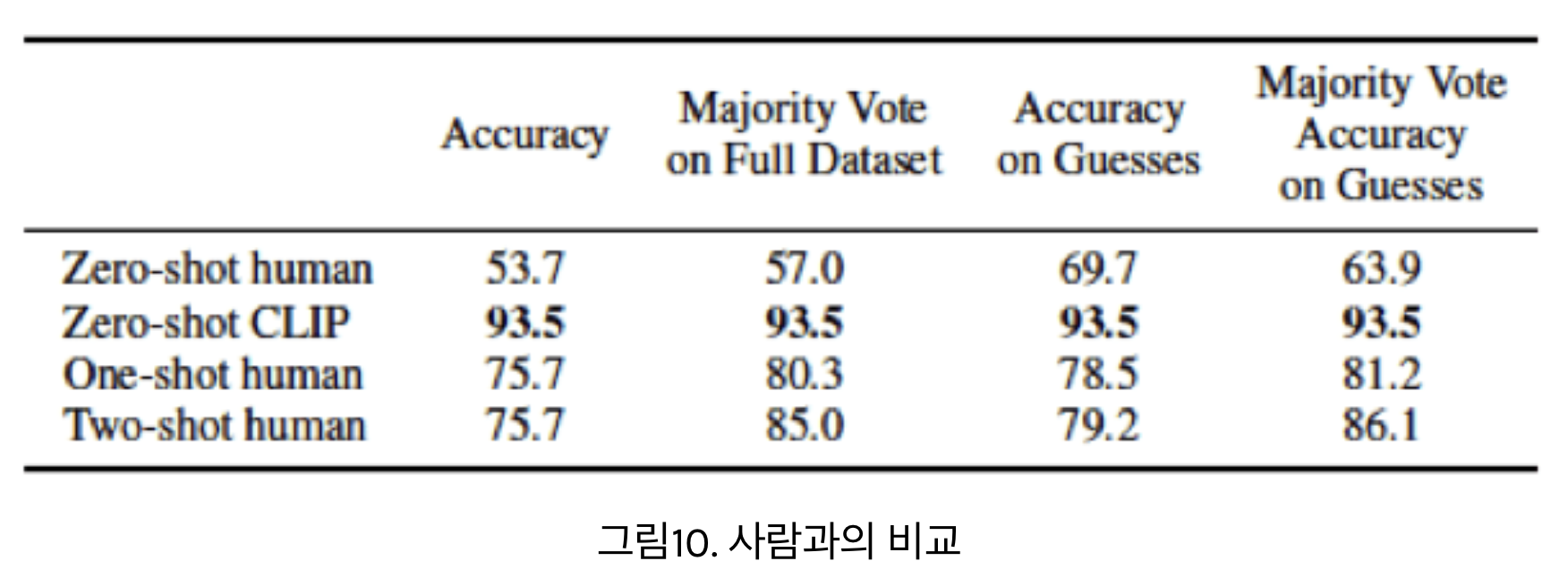
- 우선 CLIP의 Zero Shot 성능은 인간의 Zero Shot, One Shot 심지어 Two Shot 성능 보다도 높습니다.
BUT, 사람은 one-shot 능력이 엄청남!- 사람은 Zero Shot 성능은 크게 떨어지지만, 하나의 샘플을 참고하고 나면 크게 점수가 오르는데요.
- 재밌는건 사람이 두개의 샘플을 본다고 해서 성능이 더 올라가지도 않습니다.
- 반면 CLIP은 Zero Shot 성능이 좋지만, 하나의 샘플을 사용하여 재학습 했을때 오히려 성능이 하락하는 모습을 보이죠.
- 인간은 하나의 샘플만 보아도 크게 성적이 올라가죠.
- 생각해보면 우리는 무엇을 알고 있는지, 무엇을 모르고 있는지를 알고 있습니다.
- 따라서 단 하나의 샘플만 주어졌어도 기존 나의 지식과 비교해가며 새로운 정보를 잘 일반화하여 해석하죠.
- 이러한 사람의 특징을 메타 인지라고 하는데요.
- 저자들은 CLIP에는 이러한 부분이 부족함을 강조합니다. 즉 아직은 사람 뇌의 기능을 따라가려면 멀었다는 것이죠.
6. 장단점
6-1. 장점
- 첫 번째 장점은 다양한 이미지와 텍스트 데이터에 대한 robust 이해력
- 두 번째 장점은 Zero Shot 학습 능력
- 본 적 없는 새로운 데이터에 대해서도 분류 및 인식 작업을 수행할 수 있습니다.
- 세 번째 장점은 자연어 처리 모델과 이미지 인식 모델의 결합
- 이미지에 대한 설명을 자연어로 생성하거나, 반대로 텍스트를 통해 이미지를 분류하는 등의 작업을 수행할 수 있습니다.
- 네 번째 장점은 대규모 데이터셋을 효율적으로 학습할 수 있는 방법을 제안했다는 점
- 다섯 번째 장점: 다양한 태스크에 대해 유연함
- CLIP은 이미지 분류, 객체 탐지, 세그멘테이션 등 다양한 컴퓨터 비전 태스크에 적용될 수 있습니다.
6-2. 단점
- 첫 번째 단점: 제한된 Zero Shot 학습 성능
- 특히, 복잡하거나 세부적인 분류 작업에서는 제로샷 학습의 한계--------------------
- 두 번째 단점: 대규모 데이터셋에 대한 의존성
- 세 번째 단점: 계산 비용 및 자원 소모
- 이는 고성능의 하드웨어가 필요
- 네 번째 단점: 아직 특정 분야에서는 일반화가 어렵다는 점
- 다섯 번째 단점은 bias
- 인터넷에서 수집된 이미지와 텍스트 데이터를 사용하는 CLIP은 데이터에 내재된 사회적 편향을 학습할 위험
- 여섯 번째 단점: 복잡한 태스크에 대한 한계
- CLIP은 기본적인 이미지 분류나 객체 인식과 같은 태스크에는 효과적이지만, 더 복잡하고 추상적인 태스크를 수행하는 데는 한계가 있습니다.
- 예를 들어, 이미지 내 객체의 수를 세는 등의 시스템적인 태스크에서는 성능이 떨어질 수 있습니다.
CLIP 코드 사용법

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것