Object pop-up: Can we infer 3D objects and their poses from human interactions alone? [CVPR 2023]
논문 리뷰
목록 보기
6/16

0. Abstract
-
Human Object Interaction(HOI) 분야에서 많은 사람들이 가장 흔하게 초점을 두는 것은 Object임
-
예를 들어서, 의자가 있으면 앉아야하고, 컵이 있으면 손으로 쥐어야하는 것처럼 대부분 Object에 따라서 사람의 포즈를 매칭시키려고 함
튀빙겐(Tubingen) 대학의 Real Virtual Human 연구소에서는, 기존의 관점과 다르게, 사람의 포즈에 초점을 두고, 그에 맞게 Object를 배치하거나, 필요에 따라, 특정 Object를 추정하는 방법을 제안함 -
최근 Human pose의 연구 분야가 HOI로도 많이 확장되었다는 것이외에도, Point Cloud를 많이 활용함
-
이전에는 하드웨어 기술이 부족하거나, 또는 데이터 취득의 어려움등으로 Point Cloud관련 연구가 많지 않았음
-
하지만 요즘은 이러한 문제들이 많이 보완되어서, RGB 단일 이미지보다 3D 좌표를 얻기 용이하고, 객체간의 상대적인 위치 관계를 좀 더 쉽게 알 수 있음
1. Introduction

Main Contributions
- 해당 분야의 기존 연구들이 취했던 관점을 바꾸어 새로운 문제를 공식화하고, 아직 개척되지 않은 연구 방향을 제시함
- input된 human point cloud로부터 물체를 예측할 수 있는 방법을 소개
- human-object relationship의 다양한 구성 요소를 분석함
- interaction에서 다양한 pieces(hands, body, time sequence)의 기여도
- input point의 포인트별 중요도
- 유사한 기능을 가진 object들간의 confusion을 분석
2. Related Work
2.1. Object Functionality
- 사물에 대한 인간의 perception(지각)의 핵심은 functionality(기능성)는 physical appearance(물리적 외관)를 보완하여 우리의 지각을 향상시킴
- Gibson ; 사람은 perception을 위해 objects의 affordances를 이용한다는 아이디어 소개
- 이때 Affordance는 다음과 같이 정의됨
- "an intrinsic property of an object, allowing an action to be performed with the object" - 컴퓨터 비전의 관점에서 object functionality는 scene analysis, object classification, object property inferring와 같은 여러 작업 지원함 & 2D images로부터 object-specific human interaction models을 학습하는 것도 가능함
=> 이는 action과 object 간의 밀접한 관계가 있다는 것을 의미함
2.2. Human-Object interaction
- environment-aware human & 그들의 interaction을 3D로 모델링하는 것은 virtual human을 제작하는 데 있어 가장 최근의 challenge 중 하나임
- 2 main lines
- hand-focused
- full-body
Hand-Object Interaction
- motion을 위해 잘 설계된 priors을 적용하는 것이 유망해 보임
- 이러한 작업에 관련된 객체 클래스는 주로 graspable한 객체로 제한됨
- 우리는 다양한 신체 부위와 관련된 상호작용은 일상 생활에서 흔히 볼 수 있고, 적용 관점에서 더 매력적이며, 더 도전적이라고 주장합니다.
- 또한, 몸의 자세에는 물체의 속성에 대한 정보가 포함되어 있기 때문에, 파악 가능한 상호작용을 재구성하는 데에도 전신 컨텍스트가 매우 중요
- 예를 들어 망치로 두드리는 동작은 전체 자세에 영향을 미쳐서 동작을 지원함
Fully-Body Interaction
- 사람과 장면 간의 상호 작용에 초점을 맞춘 work가 여러 개 있음
- prior들은 모션을 regularize하는 데 사용 가능
- human & single object 간의 상호작용을 연구하기 위해 여러 데이터셋도 사용 가능
- 예를 들어, 최근의 BEHAVE, GRAB, InterCap은 다양한 물체와의 전신 상호작용을 포착함 - 이러한 작업은 single image, video, and multiview capturing와 같은 다양한 종류의 데이터 소스로부터 인간 상호작용을 재구성하고 이를 합성하는 작업을 다루고 있습니다.
- 그러나 이러한 모든 작업에서 우리는 일반적인 object-centric perspective으로 관찰함 : 장면이나 사물이 주어지면 그 사물과 상호작용하는 인간을 재현하는 것을 목표로 함
우리는 훨씬 덜 탐구된 보완적인 관점이 일상 생활, 특히 인간이 시스템의 중심이 되는 VR/XR 맥락에서 더 구체적으로 적용될 수 있다고 주장합니다.
2.3. Human-centric perspective
Contributions
- 우리는 새로운 문제를 공식화하여 해당 분야의 이전 연구에서 취한 관점을 바꾸고, 아직 개척되지 않은 아직 개척되지 않은 연구 방향을 제시합니다;
- 입력된 사람 포인트 클라우드로부터 물체를 예측할 수 있는 방법을 물체를 예측할 수 있는 방법을 도입합니다;
- 인간-사물 관계의 다양한 구성 요소를 분석합니다. 관계: 다양한 상호작용(손, 몸, 시간 순서)의 기여도, 입력 포인트의 포인트별 입력 포인트의 중요도, 그리고 유사한 기능을 가진 객체들이 혼란을 분석합니다.
3. Method
3.1. Object Pop-Up
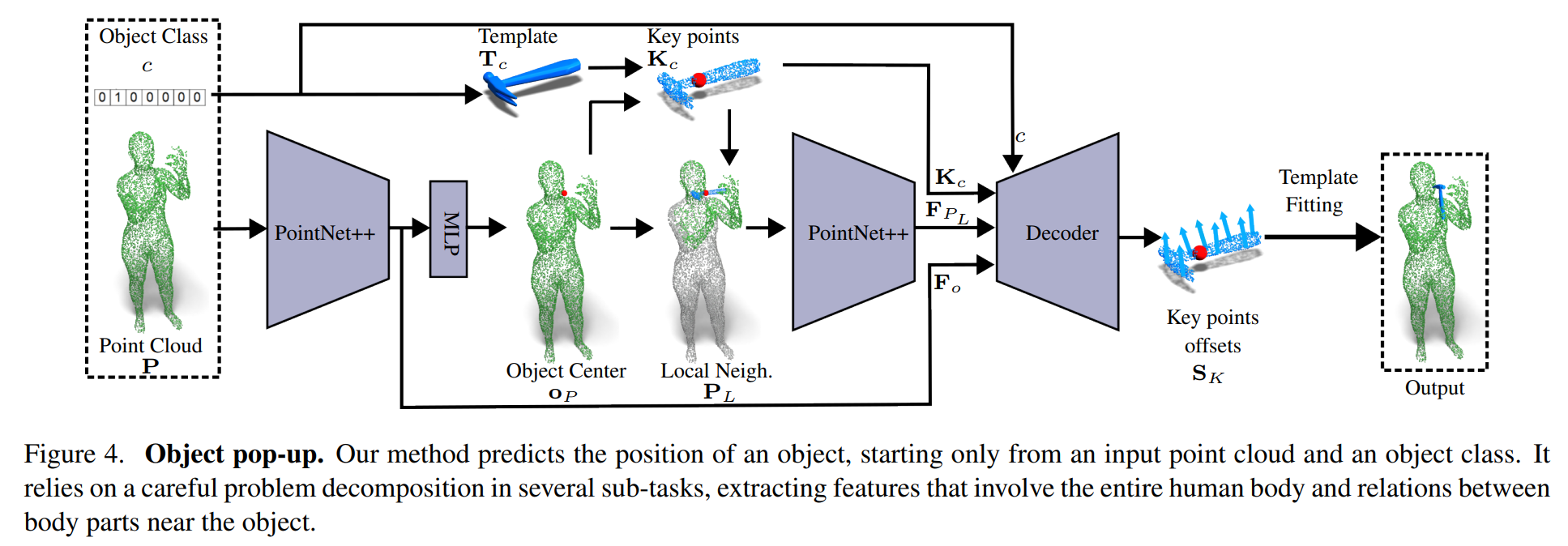
Input
single human point cloud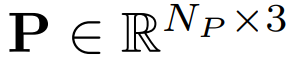
NP points and a hot-encoded object class c
- point cloud source에 관계없이 포인트의 3D 좌표 외에는 추가 정보를 사용하지 않음
- 각 object를 템플릿 메시에서 uniformly 샘플링된 1500개의 key point Kc로 나타냄
Object Center
human point cloud로부터 object pose를 예측하는 모델을 훈련하는 데는 몇 가지 어려움 있음
- 네트워크가 다양한 신체 부위의 위치와 미묘한 relationship를 이해하는 동시에 인간과의 spatial relationship에 대한 감각을 함께 개발해야 함
- 경험적으로, 우리는 문제를 신중하게 분해하고 학습 과정을 용이하게 하기 위해 다양한 기능을 설계해야만 이 작업이 가능하다는 것을 관찰
이 문제를 분해하기 위해
1단계. PointNet++ 아키텍처를 훈련하여 P에서 시작하는 object center oP를 예측 - training time에서 ground truth center oP^과 비교했을 때의 L2 loss로 supervise됨
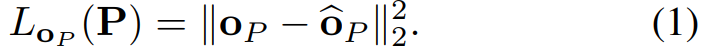
Local Neighbourhood
center prediction module은 가장 가까운 인체 영역을 사용하여 더욱 활용 가능
- 직관적으로, 가장 가까운 신체 부위를 고려하는 것은 접촉 관계뿐만 아니라 신체의 영향도 유추 가능
- 물체와 직접 닿지 않는 부분(e.g. 쌍안경을 사용하는 동안의 머리 방향)의 영향도 고려해야 함
=> 이러한 연결 관계를 학습하기 위해 centered key points & input human point cloud의 가장 가까운 3000개 포인트를 함께 고려함
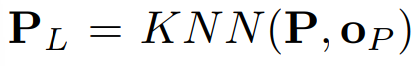
Main Figure

안녕하세요😊 컴퓨터비전을 공부하고 있는 대학원생입니다 🙌