
개요
모델의 수렴을 위해서 고려해볼 수 있는 다음 3가지 방법을 알아보자.
- Learning rate
- Momentum term
- Activation functions
Learning rate
w를 업데이트 할 때 에서 가 learnin rate이다. 이는 W를 얼마나 업데이트 할지 정하는 것이다. 즉, gradient를 얼마나 신뢰하는지의 문제인 것이다. 이와 관련하여 다음 그림을 보자.
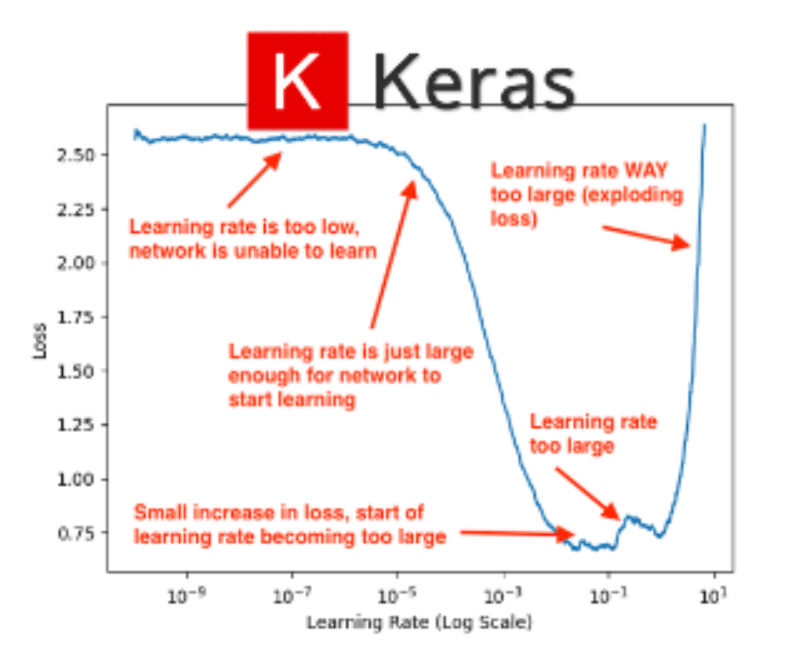
- lr이 너무 낮으면 학습이 안되므로 lr을 높여야 한다.
- lr이 너무 높으면 noise에 민감하므로, lr을 줄여야 한다.
LR scheduling
초기엔 lr을 크게 잡았다가 lr을 점점 줄이는 것이 일반적이다. 이러한 LR scheduling의 종류는 다음과 같다.
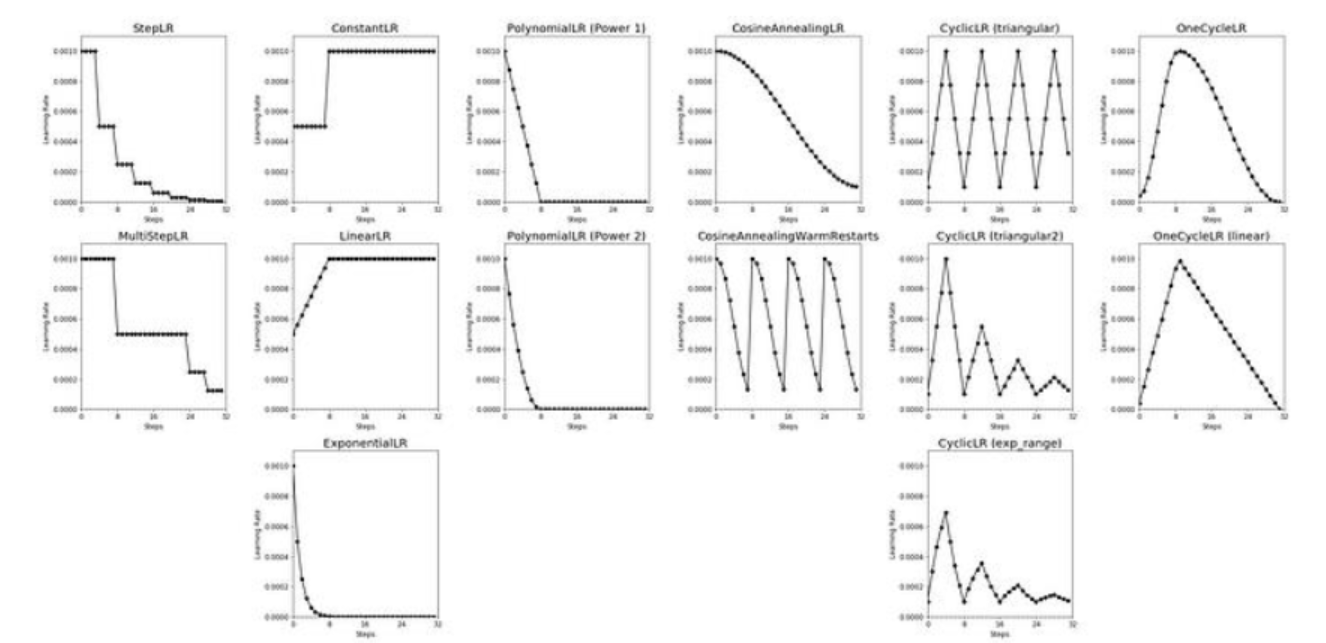
lr을 줄이는 이유는 처음에는 크게 움직여서 빠르게 학습하고, 나중에는 작게 움직이면서 정밀하게 조정하기 위해서이다.
Learning rate decay는 처음에는 빠르게, 나중에는 정밀하게 학습하려는 전략이다.
수렴을 빠르게 하고, 안정화도 시키는 핵심 기법임
이때, LR을 줄이는 방법으로 다음 두 가지 방법을 많이 사용한다.
Step decay
LR을 step function으로 낮춘다. lr을 매 5번 epochs마다 절반씩 줄여나간다.
Exponential decay
형태 지수 형태로 값을 줄여나간다.
여기서 와 는 직접 넣어야하는 hyperparameters이다.
Momentum
다음 그림을 살펴보자.
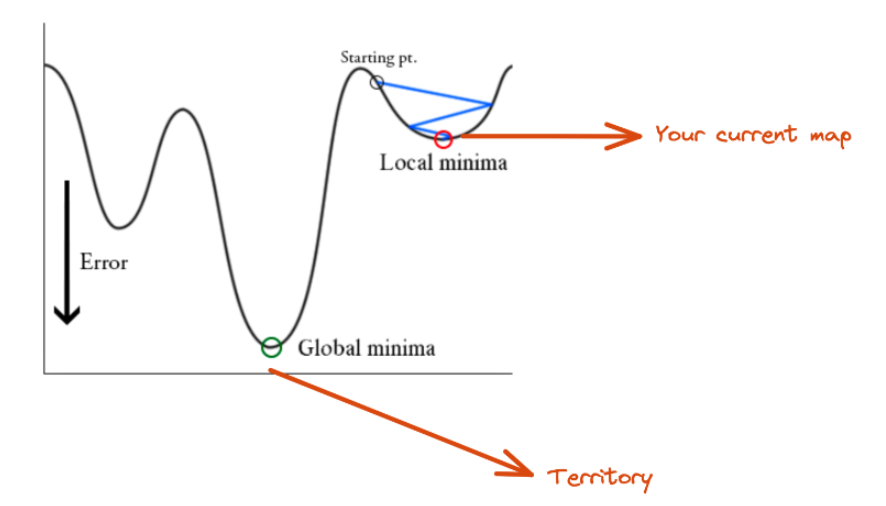
최적의 W값은 Global minima에 있는데, local minima가 optimal하다고 판단해서 이쪽으로 수렴해버릴 수 있다.
이를 막기위한 방법이 Momentum이다.
Momentum
Momentum의 사전적 정의는 외부에서 힘을 받지 않는 한 정지해 있거나 운동 상태를 지속하려는 성질이다. 이를 이용하여 모델을 학습 시킬 때, 이전에 이동했던 방향을 기억하면서 이전 기울기의 크기를 고려하여 어느 정도 추가로 이동시킨다. 이를 식으로 확인하면 다음과 같다.

이전에 누적된 gradient에서 현재 gradient의 값을 빼는 것이다.
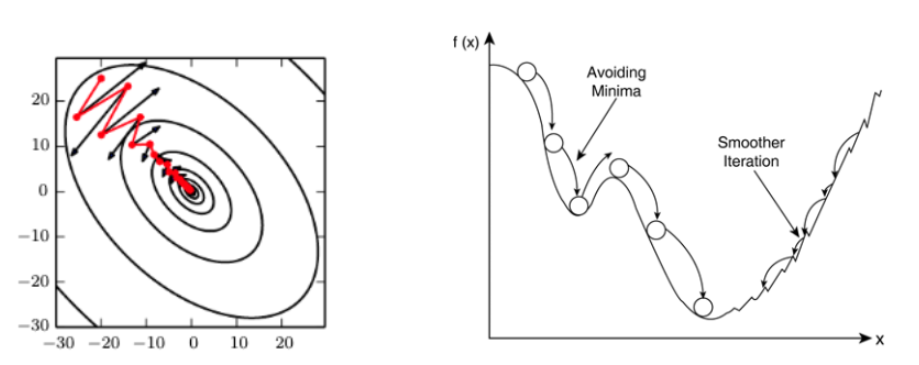
위 그림에서 확인할 수 있듯이, 한 방향으로 크게 튀어도 이전 방향에의해 보정되어 local minima에 빠지지 않는다.
Activation functions
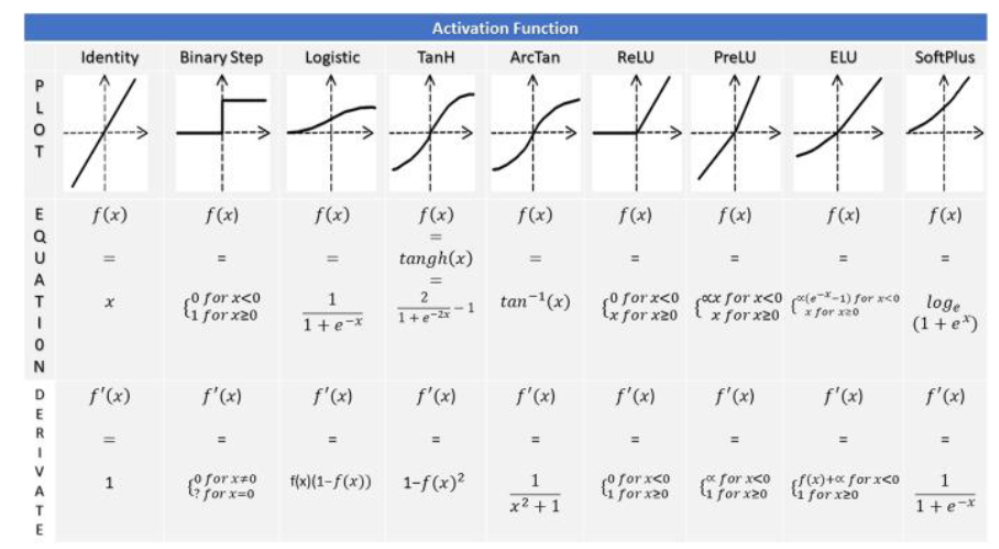
Identity Function
- Equation:
- Derivative:
결국 하나의 layer와 같아서 회귀 문제의 output layer에만 사용된다.
Binary Step Function
이진 분류에서 사용되곤 한다. 문제는 미분이 불가능하기 때문에 gradient를 이용한 학습을 할 수 없다.
Sigmoid Function
이진 분류에서 사용되는데, input이 너무 크거나 작으면 Vanishing 문제가 발생하여, 훈련이 잘 되지 않는다.
또한, Not zero-centered여서 output이 항상 양수로 나온다는 한계도 있다.
ReLU (Rectified Linear Unit)
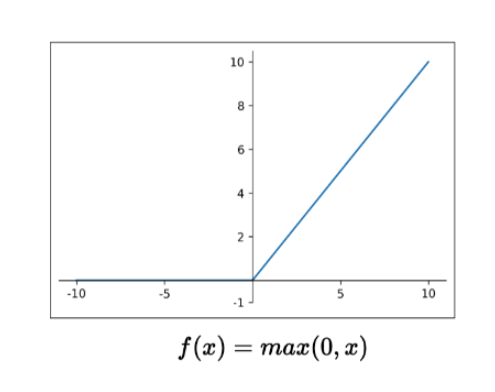
다음 그림을 보면 양의 구간에서 포화되지않는 것을 확인할 수 있다.
또한, gradient를 구하기 쉽기 때문에 연산에서도 효율적이다.
문제는 어떤 포인트에서 bias로 인해 매우 큰 음수 값으로 업데이트 된다면 포화상태에 빠져 버릴 수 있다는 점이다. (음수 구간에서 gradient = 0)
이런 output이 0인 뉴런은 dead neuron이라 한다.
그렇기 때문에 bias를 아주 작은 양수인 (0.01)정도로 초기화 시키는 것을 권장한다.
ReLU는 연산에서의 효율성과 vanishing 문제를 피한다는 점(양수 구간) 등의 이유로 DNN에서 가장 흔하게 사용되는 activation function이다.
Leaky ReLU
음의 구간에서의 포화도 없애기 위해 정의되었다.
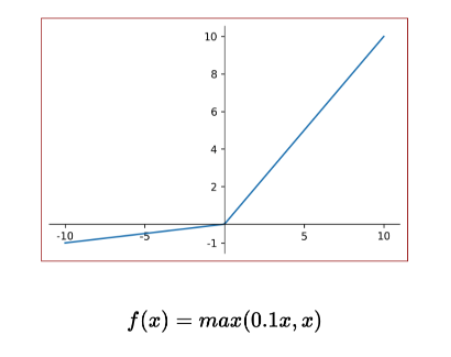
의 형태로 정의한다.
dead neuron을 막기위해 사용한다.
hyperparameter인 를 매우 신중히 조정해야한다.
