해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/ 입니다.
오늘로써, unsupervised learning에 대한 강의도 끝이난다.
Pretext Learning - Representation Learning Driven by Task Design
pretext learning은 A라는 task를 처리하는데 실질적인 목표는 task A를 처리하는 것이 아니라, 잘 정리된 representation, 유용한 정보를 만드는 것이 주요 task인 학습 전략이다.
즉, task A를 잘 푸는 네트워크를 만드는 것이 아니라, 저런 방식으로 학습시킨 네트워크에서 유용한 representation을 찾는 것이 목표다.
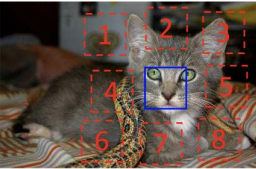
예를 들어 위 그림에서 코 있는 부분을 reference로 만들고, 주위로 8개의 상자를 만든다. 그런 후, 1~8번 상자중 아무 상자 하나를 빈칸으로 만들고 해당 부분의 정답을 맞추도록 모델을 학습시킨다.
이런식의 학습 전략은, 이전 시간에 나왔던 self-supervised learning이라고 하며 스크립트 하나만으로
supervised data set을 만들어 문제를 풀 수 있도록 한다.

또 다른 예로는, 위 그림 속 호랑이를 9등분 하여 jigsaw 퍼즐을 만든 뒤 shuffle 과정을 통해 무작위로 섞는다(그림 b). 그 후, 모델을 호랑이 그림을 다시 원상복구를 하도록 학습한다 (그림 c).
본 과정에서도 마찬가지로, 하고싶은 task는 jigsaw 퍼즐을 잘 맞추도록 하는 것이 아니고, jigsaw 퍼즐을 통해 학습된 네트워크를 사용했더니 일반적으로 의미 있는 다른 task들에서 상당히 도움이 되는 방식으로 representation을 정리할 수 있도록 하는 것이 진짜 목표다.
Mutual Information
mutual information은 어떻게 하면 여기 있는 variable과 다른 variable 사이에 공유하는 정보의 양이 얼마큼인지를 숫자로 계산할 수 있을지에 관한 방법론이다.
Contrastive Learning - Predict Learning
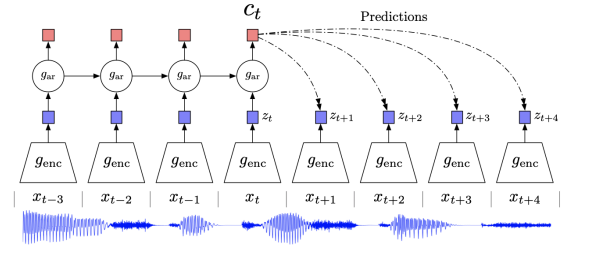
위 그림 하단의 파랑색 부분은 음성 신호를 나타내는데, 신호의 부분부분을 Nerual Network로 정리하는 과정을 반복한 후, 정리된 정보를 RNN (Recurrent Nerual Network)에 넣어 지속적으로 학습하는 과정을 반복할 경우 미래에 들어올 음성 신호를 잘 예측할 수 있을 것이다.
이런 개념으로부터 도출된 일반적인 생각은 다음과 같다.
어떤 이미지
A가 있을 때,A의 정보를representation vector로 잘 정리한다면A와 비슷한 개념을 가진 이미지B의representation vector는A의representation vector와 매우 유사해야하며, 그와 반대로 아무 상관관계가 없는 이미지C의representation vector를 정리했을 떄 해당vector는 이미지A,B의vector와 상당히 달라야 한다.
아래 그림은 정보이론 기반 unsupervised learning 수식을 나타낸다.
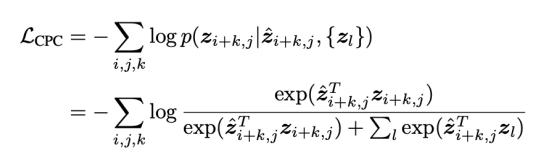
Multiview Coding
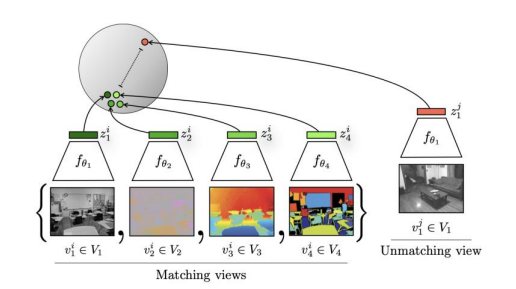
multiview coding은 결국 같은 concept이라면, 특정 오브젝트에 대해 어느 방향에서 찍은 사진이어도 결국은 오브젝트에 대한 관점만 달라질 뿐이지, 같은 정보를 담고 있어 결론적으로 해당 사진들을 Nerual Network에 통과시켜 representation activation vector를 얻으면 모두 비슷한 결과가 나와야한다는 개념이다.
SimCLR
본 개념은 augmentation을 통해 visual representation의 성능을 극대화했다. 위 그림은 original image a에 대한 다양한 augmentation을 나타낸다.

모든 이미지는 다 같은 개념을 갖는다. 그러므로 이 모든 이미지들은 representation을 잘 정리해주는 네트워크에 통과시켰을 때 전부 비슷한 representation vector를 뱉어내야 한다는 것을 학습한다.
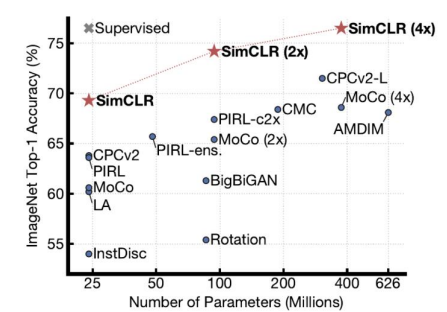
결론적으로 unlabeled 데이터만 가지고, 정보를 너무 잘 정리하다보니 네트워크의 맨 위 layer에
supervised learning으로 아주 간단한 linear network만 살짝 튜닝해줘도 정보를 별로 사용하지 않고, labeled 데이터를 조금만 쓰고도 상당히 좋은 성능이 나오는 것을 확인한다.
네트워크의 규모가 커지면 supervised learning의 성능을 따라잡고, 심지어 넘는 경우도 발생한다. 이와 같이 unsupervised learning은 제한된 조건 안에서 만든 문제에 대해서 매우 좋은 성능을 발휘한다.
Key Concepts
-
self-supervised learning:unsupervised dataset이지만,labeled dataset처럼 보이게 하는 학습 -
Instance Discrimination: 개별적인 이미지를 하나의 클래스로 정의한다. 만약 10000장의 사진이 있을 경우 10000개의class로 생각하고, 자신의augmentation만positive관계, 나머지 9999장은negative관계로 생각한다. -
contrastive loss (InfoNCE loss)
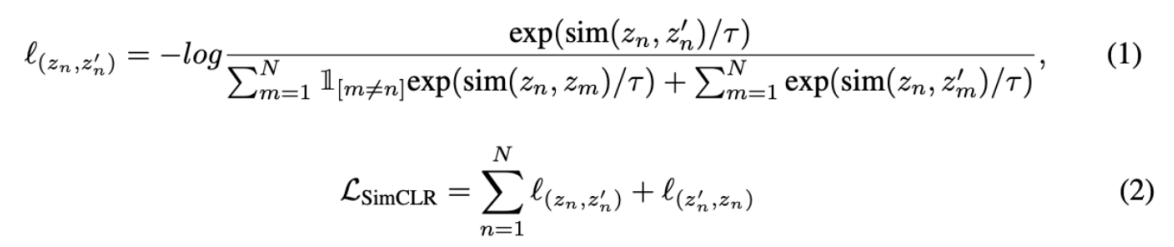
Unsupervised Learning Summary
-
unsupervised learning과supervised learning의 성능은 제한된 조건 안에서 거의 동등하다. -
NLP의 경우Masked Language Modeling과 같은 방법으로 이미 많이 발전했다. -
Unsupervised Representation Learning에서는,
- 이 개념이 무엇인지
- 이 개념의 한계가 무엇인지
- 이 개념을 이용해 무엇을 해야하는지
위 3개의 의문점을 항상 명확하게 해야하며 고려해야 한다.
Recent Example - DALL-E 2

본 논문에서 소개하는 기법은, 사람이 인공지능 모델에게 텍스트를 주었을 때 해당 텍스트를 기반으로 모델이 그림을 그려내는 기법이다.

본 기법은, 인터넷을 그냥 돌아다니며, 인간이 이미지에 달아놓은 텍스트와 이미지를 짝지어 수집한 뒤,
text mode와 visual mode를 각각 따로 만드는 것을 목표로 하고 학습을 진행했다.
" 짝으로 찾은 텍스트와 그림은 representation이 정리되었을 때 상당히 비슷해야한다 " 라는 기준을 이용해 학습을 진행했으며, 원활한 결과를 내놓았다.
