
해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/입니다.
7월 7일, 본격적인 인공지능 수업을 듣었다.

사람이 위와 같은 사진을 보고, 이 동물이 어떤 동물이냐고 물으면 99.999%의 사람들은 '사자'라고 금방 답이 나올 것이다. 아마 어려서부터 '사자'라는 동물에 대한 경험이 쌓여왔기 때문일 것이다.
하지만, 인공지능은 이 사진을 보고 단번에 '사자' 라고 답하기는 어렵다.
2~3살 어린아이처럼 '사자'에 대한 특성을 전혀 모르고, 관련된 경험도 없기 때문이다.
기계 학습 (Machine Learning)은 특정 데이터로부터 내제된 패턴을 학습하는 과정이다.
Supervised Learning
지도 학습 (Supervised Learning)은 인공지능 모델에게 정답과 학습문제를 알려주는 방식의 학습 방법이다.
Machine Learning 문제는, 크게 3가지로 분류된다.
Binary ClassificationMulti-Class ClassificationRegression
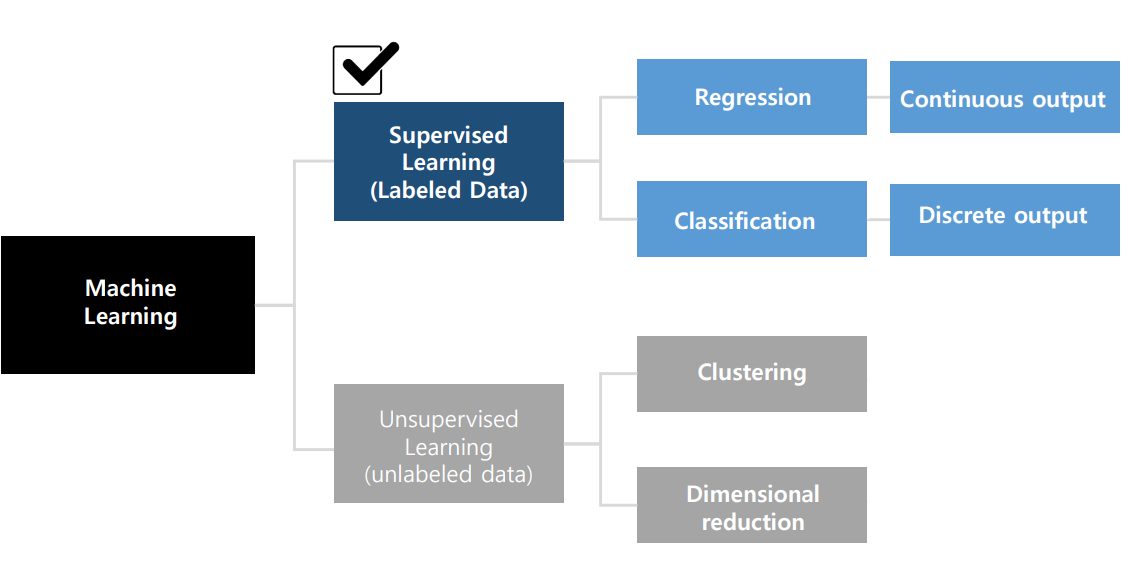
Regression과 Classification의 차이는, 출력이 연속 변수면 Regression, 이산 변수면 Classification이고 Supervised Learning과 Unsupervised Learning의 가장 큰 차이점은, 학습 데이터가 Labeled Data인지, Unlabeled Data인지다.
Supervised Learning의 목표는 입력값 X를 넣었을 때 나오는 Y의 관계를 설명하는 함수 h(x)를 정의하는 것으로, (X1, Y1) 형식의 데이터셋을 사용한다.
그 중, Classification의 예다.

cat dog mug hat은 label에 해당하며, 각 label 밑에 있는 사진들이 입력값 X에 해당한다.
즉, Supervised Learning에서는 입력값 X와 정답 label을 주고 모델을 학습한다.
Learning Pipeline은 다음과 같다.
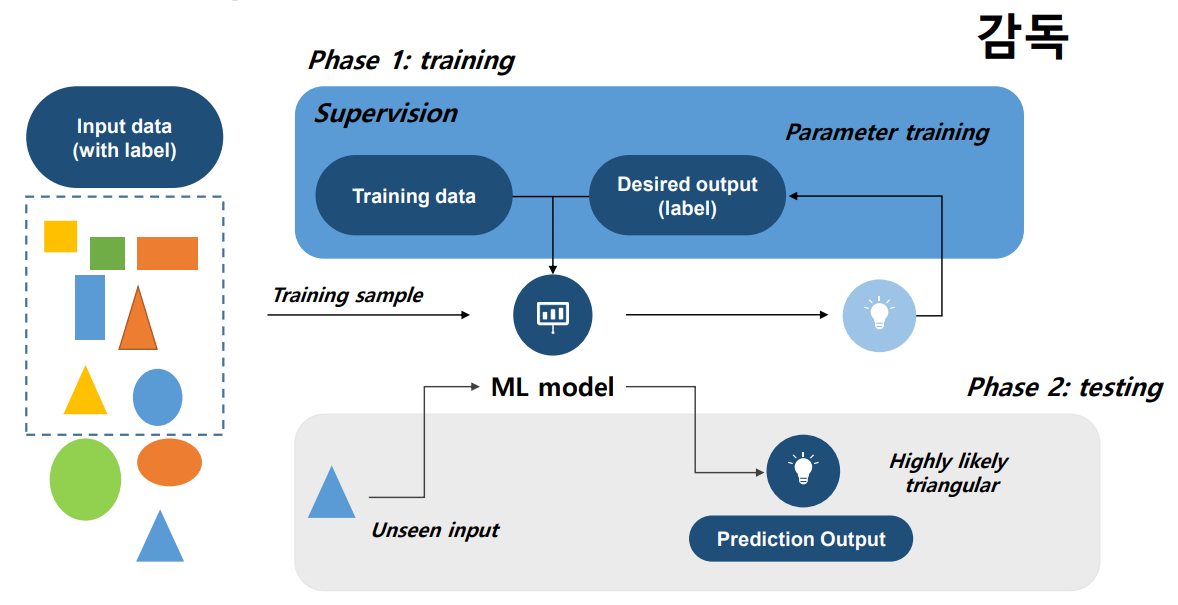
학습 시작 초기에는 모델의 성능이 우수하지 않기에, label로부터 모델의 출력값과 비교해 정확하게 맞추고 있는지, 학습이 정상적으로 잘 되고 있는지를 확인한 후 필요에 따라 교정을 진행한다.
즉, 모델의 출력값과 정답과의 차이인 error를 통해 이 error를 줄여가며 학습을 진행한다.
모델의 실제 성능은 학습에 쓰이지 않은 입력값을 넣었을 때 확인할 수 있다.
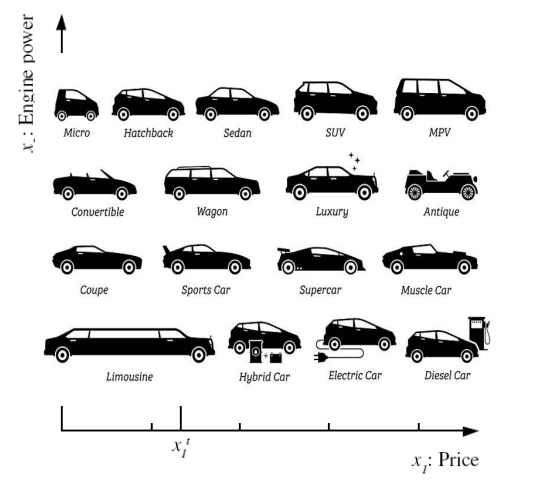
해당 그래프에서 Price와 Engine Power는 풀고자하는 문제에 대해 알고있어야 하는 Feature 값이며, 전문가와 협업을 통해 지정할 수도 있고, 모델이 알아서 지정하는 경우도 있다.
위의 예제의 경우 Family Car 인지 아닌지를 판단하고자 하는 문제였는데, 이 때 Family Car에 속할 경우 Positive samle, 반대의 경우 Negative Sample로 지칭한다.
결국 Supervised Learning의 목표는 Target Function f(x)에 근접한 함수를 만드는 것이다.
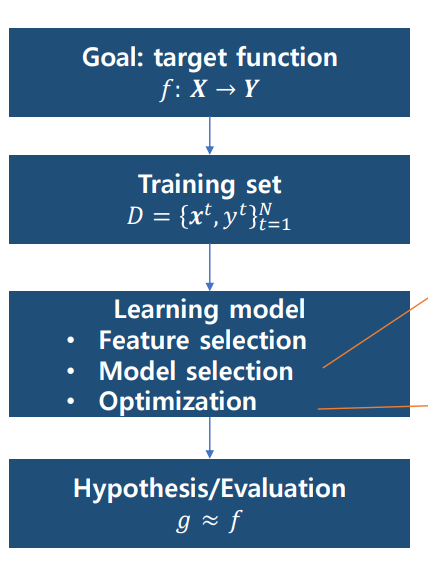
모델의 학습에 있어 중요한 요소는 약 3가지다.
Feature Selection: 문제의 적절한Feature를 선정하여 학습한다.Model Selection: 주어진 문제에 가장 적합한 모델을 선택하여 문제를 해결한다.Optimization: 모델 파라미터를 최적화하여 성능을 최대화한다.
또한, 현실 세계에 있는 모든 데이터에 대한 모델을 구성하기는 불가능에 가깝기 때문에 데이터의 결핍으로 인한 불확실성을 포함하게 되며 이로 인해 Generalization도 중요하다.
모델의 Generalization는, 모르는 데이터에도 우수한 성능을 제공해야 하는 것이 목표이며,
Generalization Error의 최소화가 목적이다.
하지만 학습과정에서 직접적으로 Generalization Error를 낮출수 없기 때문에 Training Error,
Validation Error, Test Set Error를 이용해 최소화하려 한다.
Error의 경우 e(h(x), y)로 계산하며 대표적으로 Squared Error와 Binary Error가 있다.
squared error : e(h(x), y) = (h(x) - y)^2
binary error : e(h(x), y) = 1[h(x) != y]
overall error : E[(h(x) - y)^2] 이들은 손실함수, cost function, loss function이라고 불린다.
주요 error들은 다음과 같다.
error_training: 주어진 데이터셋에 맞추어 학습하는 데 사용하는 에러로 모델 파라미터 최적화에 사용error_test: 현실 세계에 적용했을 때 나타나는Generalization Error를 표현
모델의 학습에서 에러를 조절하고자 하는 목적은 2개가 있다.
error_test와error_training가 가까워지도록error_training의 값이 0에 가까워지도록
1번 과정의 실패에는 모델의 분산이 커져, 학습데이터셋에 의존하는 overfitting 문제가 대두될 수 있으며, 정규화나 더 많은 데이터 셋으로 해결할 수 있다.
2번 과정의 실패에는 모델의 bias가 커져, underfitting 문제가 대두될 수 있으며, 최적화나 더 복잡한 모델을 사용해 해결할 수 있다.
variance와bias사이에는 서로 반비례 관계인trade-off관계가 나타난다.
Total Loss = Bias + Varinace (+ noise)
Underfitting
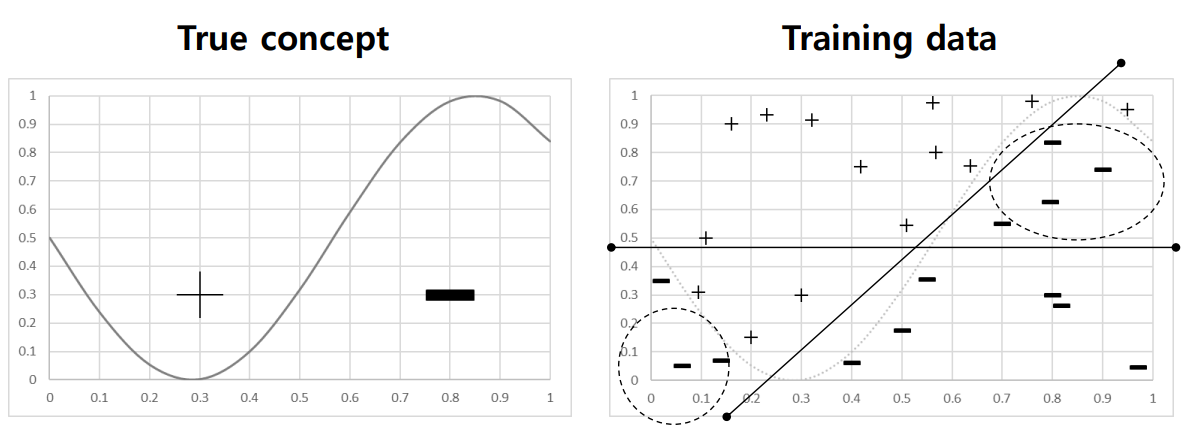
Underfitting의 경우 높은 bias 문제로 인해 발생하는 문제이며, 오른쪽 그림의 왼쪽 아래, 오른쪽 위와 같이 Decision Boundary로 커버할 수 없는 부분이 생긴다.
Overfitting
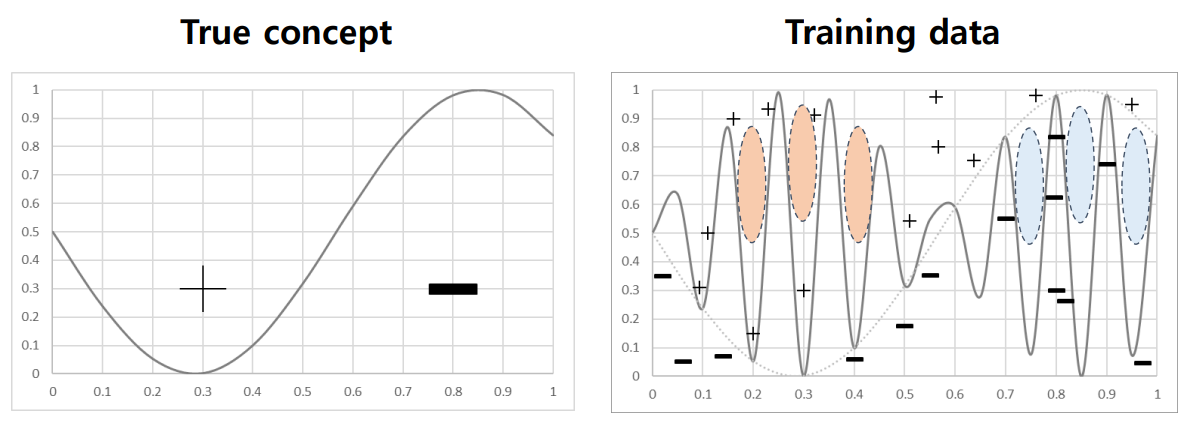
Overfitting의 경우 높은 분산 문제로 인해 발생하는 문제이며, 모델이 너무 과한 Decision Boundary를 구성함으로써 오른쪽 그림의 붉은색, 푸른색 부분의 값이 초기 개념과 반전되는 부분이 생긴다.
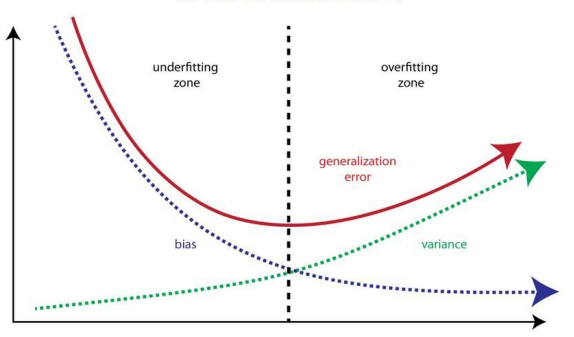
- 모델이 복잡한 경우 ->
overfitting-> 분산 증가 -> bias 감소 - 모델이 단순한 경우 ->
underfitting-> bias 증가 -> 분산 감소
하지만, 최근에는 복잡도의 증가속도가 데이터셋의 샘플 수 확보 속도보다 빨라 overfitting이 증가하는 추세다.
이를 Curse of Dimension 문제라고 부르며, 이를 해결하기 위한 가장 단순한 방법은 데이터셋을 늘리는 것이다.
데이터를 확보할 수 없는데 늘리기 위해서, Data augmentation이 등장했고,
주요 개념으로 Regularization, Ensemble이 있다. 두 개념은 추후 다시 다룬다.
Cross-Validaion
k-fold cross-validation: 학습 데이터셋을 k개의 그룹으로 나누어(k-1)개의 그룹은 학습에 사용하고 1개의 그룹은 검증에 사용하는 방법으로, 부족한 데이터셋의 빈틈을 채워줄 수 있는 방법이다.
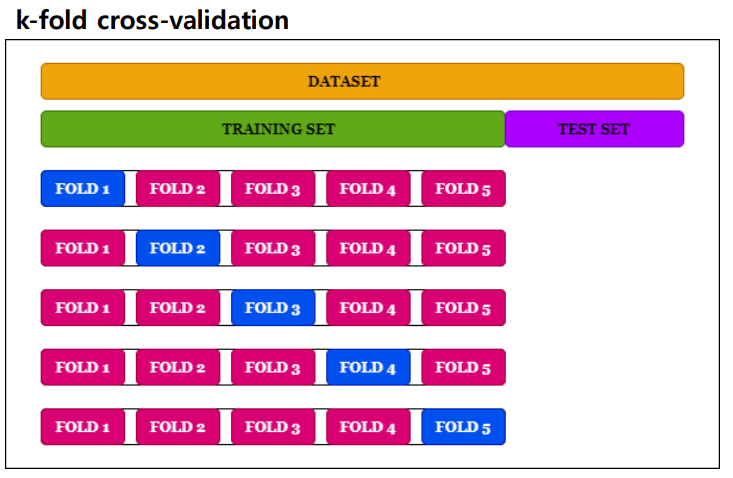
이는 overfitting을 방지하며 더 좋은 모델을 구축할 수 있게 해준다.
