
Lec.6: Exception/File/Log Handling
- Program 사용할 때 일어나는 Errors :
- 주소를 입력하지 않고 배송 요청- 저장도 안 했는데 컴퓨터 전원이 나감
- 게임 아이템 샀는데 게임에서 튕김
예상치 못한 많은 일(예외)들이 생긴다.
01_Exception
- 예상 가능한 예외
- 발생 여부를 사전에 인지할 수 있는 예외
- 사용자의 잘못된 입력, 파일 호출 시 파일 없음
- 개발자가 반드시 명시적으로 정의 해야함
- 예상이 불가능한 예외
- Interpreter 과정에서 발생하는 예외, 개발자 실수
- List의 범위를 넘어가는 값 호출, 정수 0으로 나누기
- 수행 불가 시, Interpreter가 자동 호출
1) Exception Handling
예외가 발생할 경우 후속 조치 등 대처가 필요
- 없는 파일 호출 : 파일 없음을 알림
- 게임 이상 종료 : 게임 정보 저장
Program = Product, 모든 잘못된 상황에 대처가 필요하다.
02_Python의 Exception Handling
1) try ~ except 문법

- Example : 0으로 숫자를 나눌 때 예외처리
for i in range(10):
try:
print(10 / i)
except ZeroDivisionError:
print("Not divided by 0")Not divided by 0
10.0
5.0
3.3333333333333335
2.5
2.0
1.6666666666666667
1.4285714285714286
1.25
1.1111111111111112- Exception의 종류 : Built-in Exception = 기본적으로 제공하는 예외

2) Example : 예외 정보 표시하기
for i in range(10):
try:
print(10 / i)
except ZeroDivisionError as e:
print(e)
print("Not divided by 0")division by zero
Not divided by 0
10.0
5.0
3.3333333333333335
2.5
2.0
1.6666666666666667
1.4285714285714286
1.25
1.11111111111111123) try ~ except ~ else 구문

for i in range(1, 10):
try:
result = 10 / i
except ZeroDivisionError:
print("Not divided by 0")
else:
print(10 / i)10.0
5.0
3.3333333333333335
2.5
2.0
1.6666666666666667
1.4285714285714286
1.25
1.11111111111111124) try ~ except ~ finally 구문

try:
for i in range(0, 10):
result = 10 // i
print(result)
except ZeroDivisionError:
print("Not divided by 0")
finally:
print("종료되었습니다.")Not divided by 0
종료되었습니다.5) Raise 구문 : 필요에 따라 강제로 Exception을 발생

while True:
value = input("변환할 정수 값을 입력해주세요")
for digit in value:
if digit not in "0123456789":
raise ValueError("숫자값을 입력하지 않으셨습니다")
print("정수값으로 변환된 숫자 -", int(value))zz
ValueError: 숫자값을 입력하지 않으셨습니다6) Assert 구문 : 특정 조건에 만족하지 않을 경우 예외 발생

def get_binary_nmubmer(decimal_number):
assert isinstance(decimal_number, int)
return bin(decimal_number)
print(get_binary_nmubmer(10))
# 0b101002_File Handling
1) Overview
- File System : OS에서 파일을 저장하는 Tree Structure 저장 체계
- File From Wiki : 컴퓨터 등의 기기에서 의미 있는 정보를 담는 논리적인 단위, 모든 Program은 파일로 구성되어 있고, 파일을 사용한다.
2) File & Directory
Directory
- Folder 또는 Directory로 불린다.
- File과 다른 Directory를 포함할 수 있다.
File
- 컴퓨터에서 정보를 저장하는 논리적인 단위 (wikipedia)
- 파일은 파일명과 확장자로 식별됨 (ex. hello.py)
- 실행, 쓰기, 읽기 등을 할 수 있다.
File의 종류
- 기본적인 파일 종류로 Text File과 Binary File로 나눈다.
- 컴퓨터는 Text File을 처리하기 위해 Binary File로 변환시킴(ex. pyc file)
- 모든 Text 파일도 실제는 Binary File, ASCII/Unicode String 집합으로 저장되어 사람이 읽을 수 있다.

3) Python File I/O
- Python은 파일 처리를 위해 'open' Keyword를 사용.

4) Python File Read
- read().txt 파일 안에 있는 내용을 String으로 Return
# 대상 파일이 같은 폴더에 있을 경우
f = open("i_have_a_dream.txt", "r")
contents = f.read()
print(contents)
f.close()- with 구문과 함께 사용하기
with open("i_have_a_dream.txt", "r") as my_file:
contents = my_file.read()
print(type(contents), contents)- 한 줄씩 읽어 List Type으로 Return
with open("i_have_a_dream.txt", "r") as my_file:
content_list = my_file.readlines() # 파일 전체를 list로 Return
print(type(content_list)) # Type 확인
print(content_list) # List 값 출력- 실행 시 마다 한 줄씩 읽어 오기
with open("i_have_a_dream.txt", "r") as my_file:
i = 0
while True:
line = my_file.readline()
if not line:
break
print(str(i) + " === " + line.replace("\n", "")) # 한 줄씩 값 출력
i = i + 1- 단어 통계 정보 산출
with open("i_have_a_dream.txt", "r") as my_file:
contents = my_file.read()
word_list = contents.split(" ") # 빈칸 기준으로 단어를 분리 List
line_list = contents.split("\n") # 한 줄씩 분리하여 List
print("Total Number of Characters:", len(contents))
print("Total Number of Words:", len(word_list))
print("Total Number of Lines:", len(line_list))5) Python File Write
- Mode "W", encoding="utf8"
f = open("count_log.txt", 'W', encoding="utf8")
for i in range(1, 11):
data = "%d번째 줄입니다.\n" % i
f.write(data)
f.close()- Mode "a" : 추가 Mode
with open("count_log.txt", 'a', encoding="utf8") as f:
for i in range(1, 11):
data = "%d번쨰 줄입니다.\n" % i
f.write(data)6) Python Directory 다루기
- OS Module을 사용하여 Directory 다루기
import os
os.mkdir("log")- Diretory가 있는지 확인하기
if not os.path.isdir("log"):
os.mkdir("log")- 최근에는 Pathlib Module을 사용하여 Path를 Object로 다룬다.
import pathlib
cwd = pathlib.Path.cwd()
print(cwd) # WindowsPath('D:/workspace')
print(cwd.parent) # WindowsPath('D:/')
print(list(cwd.parents)) # [WindowsPath('D:/')]
print(list(cwd.glob("*"))) # [WindowsPath('D:/workspace/ai-pnpp'), WindowsPath('D:/workspace/cs50_auto_grader'), WindowsPath('D:/workspace/data-academy'), WindowsPath('D:/workspace/DSME-AI-Smart- Yard'), WindowsPath('D:/workspace/introduction_to_python_TEAMLAB_MOOC'),7) Log File 생성하기
- Directory, File 있는지 확인 후
import os
if not os.path.isdir("log"):
os.mkdir("log")
if not os.path.exists("log/count_log.txt"):
f = open("log/count_log.txt", 'w', encoding="utf8")
f.write("기록이 시작됩니다\n")
f.close()
with open("log/count_log.txt", 'a', encoding="utf8") as f:
import random, datetime
for i in range(1, 11):
stamp = str(datetime.datetime.now())
value = random.random() * 1000000
log_line = stamp + "\t" + str(value) + "값이 생성되었습니다" + "\n"
f.write(log_line)8) Pickle
- Python의 Object를 영속화(Persistence)하는 Built-in Object
- Data, Object 등 실행 중 정보를 저장 > 불러와서 사용
- 저장해야하는 정보, 계산 결과(Model) 등 활용이 많음
import pickle
f = open("list.pickle", "wb")
test = [1, 2, 3, 4, 5]
pickle.dump(test, f)
f.close()
f = open("list.pickle", "rb")
test_pickle = pickle.load(f)
print(test_pickle)
f.close()import pickle
class Multiply(object):
def __init__(self, multiplier):
self.multiplier = multiplier
def multiply(self, number):
return number * self.multiplier
muliply = Multiply(5)
muliply.multiply(10)
f = open("multiply_object.pickle", "wb")
pickle.dump(muliply, f)
f.close()
f = open("multiply_object.pickle", "rb")
multiply_pickle = pickle.load(f)
multiply_pickle.multiply(5)03_Logging Handling
1) Log 남기기: Logging
- Program이 실행되는 동안 일어나는 정보를 기록으로 남기기
- 유저의 접근, Program의 Exception, 특정 Function의 사용
- Console 화면에 출력, 파일에 남기기, DB에 남기기 등등
- 기록된 Log를 분석하여 의미있는 결과를 도출 할 수 있음
- 실행 시점에서 남겨야 하는 기록, 개발 시점에서 남겨야하는 기록
2) Print Vs Logging
- 기록을 Print로 남기는 것도 가능함
- 그러나 Console 창에만 남기는 기록은 분석시 사용불가
- 때로는 Level별(개발, 운영)로 기록을 남길 필요도 있음
- Module별로 별도의 Logging을 남길 필요도 있음
- 이러하느 기능을 체계적으로 지원하는 Module이 필요함
3) Logging Module
- Python의 기본 Log 관리 Module
- Default Logging Level은 Warning.
import logging
logging.debug("틀렸습니다")
logging.info("확인하세요")
logging.warning("조심하세요")
logging.error("에러발생")
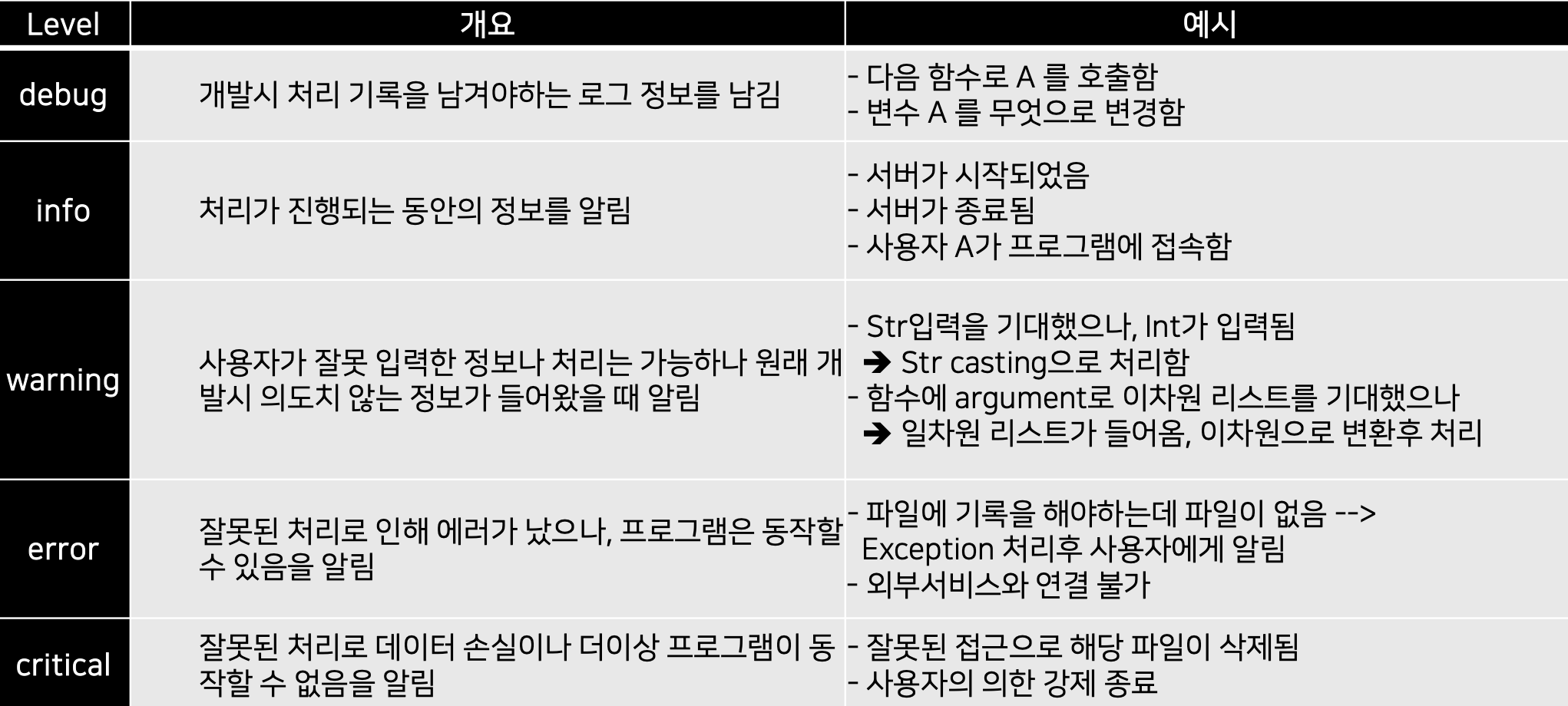
logging.critical("치명적인 상황")4) Logging Level
- Program 진행 상황에 따라 다른 Level의 Log를 출력함
- 개발 시점, 운영 시점 마다 다른 Log가 남을 수 있도록 지원함
- Debug > Info > Warning > Error > Critical
- Log 관리시 가장 기본이 되는 설정 정보
import logging
logger = logging.getLogger("main") # Logger 선언
stream_hander = logging.StreamHandler() # Logger의 Output 방법 선언
logger.addHandler(stream_hander) # Logger의 Output 등록
logger.setLevel(logging.DEBUG)
logging.debug("틀렸습니다")
logging.info("확인하세요")
logging.warning("조심하세요")
logging.error("에러발생")
logging.critical("치명적인 상황")
logger.setLevel(logging.CRITICAL)
logging.debug("틀렸습니다")
logging.info("확인하세요")
logging.warning("조심하세요")
logging.error("에러발생")
logging.critical("치명적인 상황")- 실제 Program을 실행할 땐 여러 설정이 필요
- Data File Location, File 저장 Directory, Operation Type 등 정보들을 설정해줄 방법이 필요
1) Configparser : 파일에
2) Argparser : 실행시점에
5) Configparser
- Program의 실행 설정을 File에 저장함
- Section, Key, Value 값의 형태로 설정된 설정 파일을 사용
- 설정파일을 Dict Type으로 호출 후 사용
- Config File
Section : "[]"
속성 : "Key : Value"

- Configparser File
import configparser
config = configparser.ConfigParser()
config.sections()
config.read('example.cfg"')
config.sections()
for key in config['SectionOne']:
print(key)
config['SectionOne']['status']
6) Argparser
- Console 창에서 Program 실행시 Setting 정보를 저장함
- 거의 모든 Console 기반 Python Program 기본으로 제공
- 특수 Module도 많이 존재하지만(TF), 일반적으로 Argparser를 사용
- Command-Line Option이라고 부름
import argparse
parser = argparse.ArgumentParser(description='Sum two integers.')
# parser.add_argument('짧은 이름', "긴 이름", dest="표시명", help="Help 설명", type=Argument Type
parser.add_argument('-a', "--a_value", dest="A_value", help="A integers", type=int)
parser.add_argument('-b', "--b_value", dest="B_value", help="B integers", type=int)
args = parser,parse_args()
print(args)
print(args.a)
print(args.b)
print(args.a + args.b)def main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default:64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing(default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N', help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR', help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M', help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S', help="random seed (default: 1)")
parser.add_argument('--save-model', action='store_true', default=False, help='For Saving the current Model')
args = parser.parse_args()
if __name__ == '__main__':
main()7) Logging 적용하기
- Logging formmater : Log의 결과값의 format을 지정해 줄 수 있음
formatter = logging.Formatter('%(asctime)s %(levelname)s %(process)d %(message)s')- Log Config File
logging.config.fileConfig('logging.conf')
logger = logging.getLogger()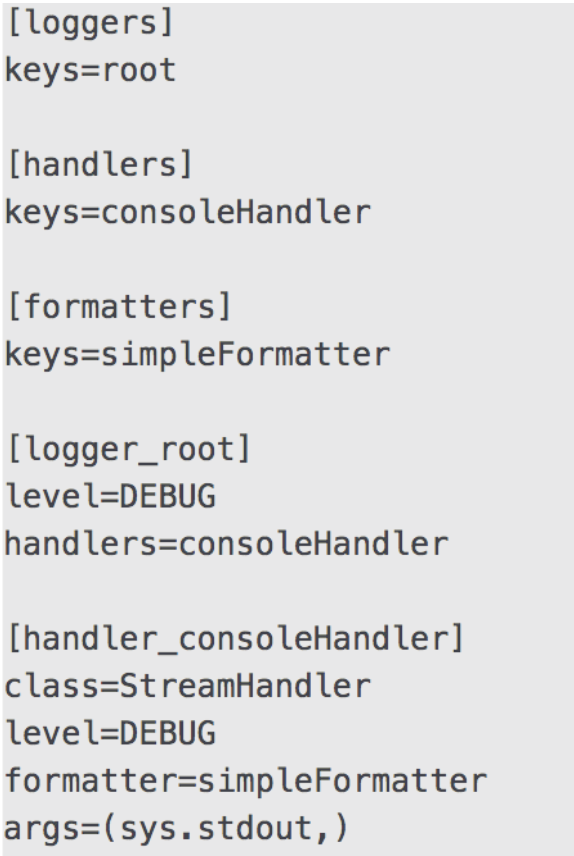
import csv
logger.info('Open file {0}'.format("customers.csv"))
try:
with open("customers.csv", "r") as customer_data:
customer_reader = csv.reader(customer_data, delimiter=',', quotechar='"')
for customer in customer_reader:
if customer[10].upper() == "USA": # customer Data의 Offset 10번째 값
logger.info('ID {0} added'.format(customer[0]))
customer_USA_only_list.append(customer) # 즉 country Field가 "USA"인 것만
except FileNotFoundError as e:
logger.error('File NOT found {0}'.format(e))