
Dataset : https://www.kaggle.com/loveall/email-campaign-management-for-sme
이번 시간에는 이메일 켐페인 데이터셋을 활용해 EDA 및 가설 검정을 연습해보도록 하겠습니다.
먼저 데이터를 불러와 중복행을 제거한 후 전체적인 구조를 확인하겠습니다.
train <- read.csv("Train_psolI3n.csv")
train <- unique(train)
str(train)'data.frame': 68353 obs. of 12 variables:
$ Email_ID : chr "EMA00081000034500" "EMA00081000045360" "EMA00081000066290" "EMA00081000076560" ...
$ Email_Type : int 1 2 2 1 1 1 1 1 1 2 ...
$ Subject_Hotness_Score : num 2.2 2.1 0.1 3 0 1.5 3.2 0.7 2 0.5 ...
$ Email_Source_Type : int 2 1 1 2 2 1 1 2 1 1 ...
$ Customer_Location : chr "E" "" "B" "E" ...
$ Email_Campaign_Type : int 2 2 3 2 3 2 2 2 2 2 ...
$ Total_Past_Communications: int 33 15 36 25 18 NA 34 21 NA 40 ...
$ Time_Email_sent_Category : int 1 2 2 2 2 2 3 2 3 3 ...
$ Word_Count : int 440 504 962 610 947 416 116 1241 655 655 ...
$ Total_Links : int 8 5 5 16 4 11 4 6 11 11 ...
$ Total_Images : int 0 0 0 0 0 0 0 2 4 0 ...
$ Email_Status : int 0 0 1 0 0 0 0 0 0 0 ...
총 12개의 변수와 68353개의 행으로 이루어진 데이터라는 것을 확인할 수 있습니다.
이제 recipes 패키지를 활용해 각 변수의 타입이 맞게 변환 및 EDA에 필요없는 Email_ID 변수와 의미가 불분명한 Subject_Hotness_Score 변수를 제거하겠습니다.
recipe <- train %>% recipe(Email_Status ~.) %>%
step_mutate_at(1,2,4,5,6,8,12, fn = factor) %>%
step_rm(1,3) %>%
prep(training = train)
train <- juice(recipe)
str(train)tibble [68,353 x 10] (S3: tbl_df/tbl/data.frame)
$ Email_Type : Factor w/ 2 levels "1","2": 1 2 2 1 1 1 1 1 1 2 ...
$ Email_Source_Type : Factor w/ 2 levels "1","2": 2 1 1 2 2 1 1 2 1 1 ...
$ Customer_Location : Factor w/ 8 levels "","A","B","C",..: 6 1 3 6 4 8 6 8 8 8 ...
$ Email_Campaign_Type : Factor w/ 3 levels "1","2","3": 2 2 3 2 3 2 2 2 2 2 ...
$ Total_Past_Communications: int [1:68353] 33 15 36 25 18 NA 34 21 NA 40 ...
$ Time_Email_sent_Category : Factor w/ 3 levels "1","2","3": 1 2 2 2 2 2 3 2 3 3 ...
$ Word_Count : int [1:68353] 440 504 962 610 947 416 116 1241 655 655 ...
$ Total_Links : int [1:68353] 8 5 5 16 4 11 4 6 11 11 ...
$ Total_Images : int [1:68353] 0 0 0 0 0 0 0 2 4 0 ...
$ Email_Status : Factor w/ 3 levels "0","1","2": 1 1 2 1 1 1 1 1 1 1 ...
각 변수들의 타입에 맞게 적절하게 변환된 것을 확인할 수 있습니다.
아래는 각 변수들에 대한 간략한 설명입니다.
Email_Type : 이메일 종류
Email_Source_Type : 이메일 소스 종류
Customer_Location : 고객의 위치
Email_Campaign_Type : 이메일 캠페인 종류
Total_Past_Communications : 지금까지의 총 커뮤니케이션 횟수
Time_Email_sent_Category : 이메일 발송 시간 종류
Word_Count : 이메일에 포함된 글자 수
Total_Links : 이메일에 포함된 링크 수
Total_Images : 이메일에 포함된 사진 수
Email_Status : 이메일 상태 (Target 변수)
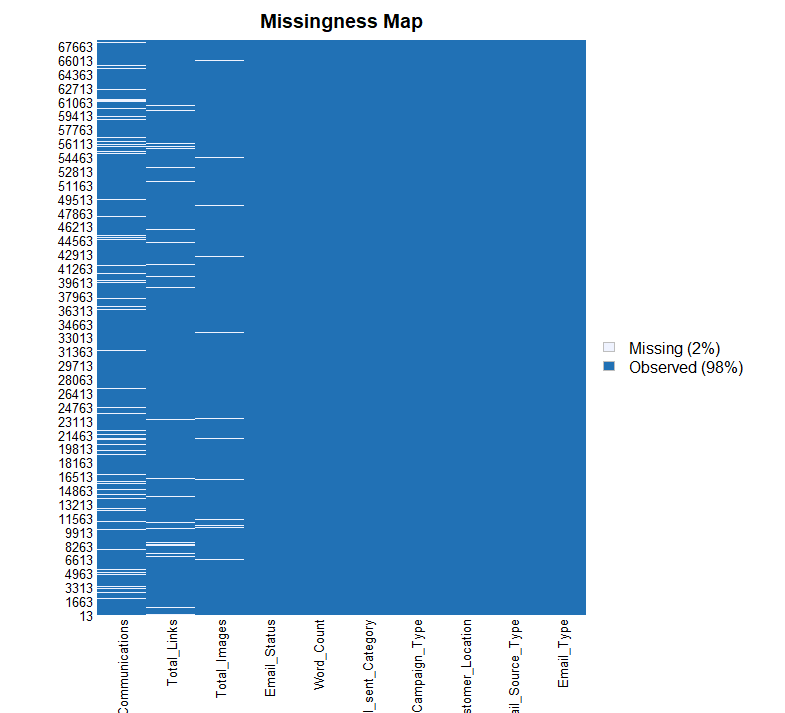
우선 summary() 함수와 Amelia 패키지의 missmap() 함수를 통해 전체적인 요약통계량 및 결측값 그래프를 확인하겠습니다.
summary(train)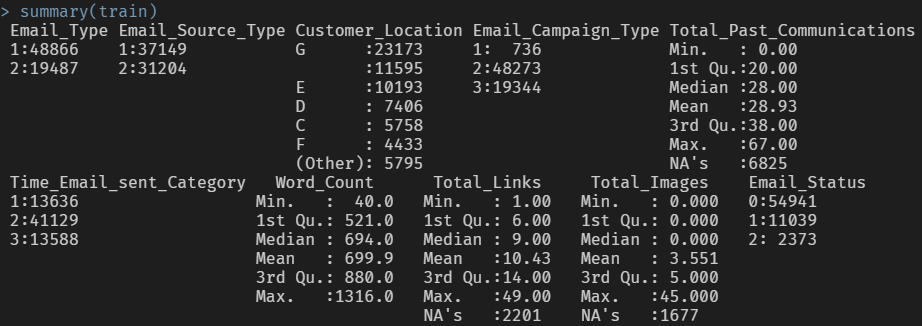
요약통계량 확인 결과 Customer_Location 변수의 level 중 공백으로 채워진 부분이 있다는 것을 확인할 수 있습니다.
아마 level명이 누락된 것으로 파악됩니다만, 확실한 판단이 어렵기 때문에 해당 level은 NA로 변환 후 나중에 최빈값으로 대체하도록 하겠습니다.
levels(train$Customer_Location) <- ifelse(levels(train$Customer_Location) == "", NA, levels(train$Customer_Location))또한 결측값 그래프를 확인해보니 Total_Past_Communications, Total_Links, 그리고 Total_Images 변수에서 이미 결측값이 존재하는 것을 확인할 수 있습니다.
다만 각 변수에 존재하는 결측값의 비율이 그렇게 크지 않기 때문에 충분히 다른 값으로 대체할 수 있을 것 같습니다만, 그 전에 결측값이 존재하는 세 개의 연속형 변수에 대한 히스토그램을 확인하겠습니다.
library(gridExtra)
a <- train %>% ggplot(aes(x=Total_Past_Communications)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
b <- train %>% ggplot(aes(x= Total_Links)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
c <- train %>% ggplot(aes(x= Total_Images)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
grid.arrange(a,b,c)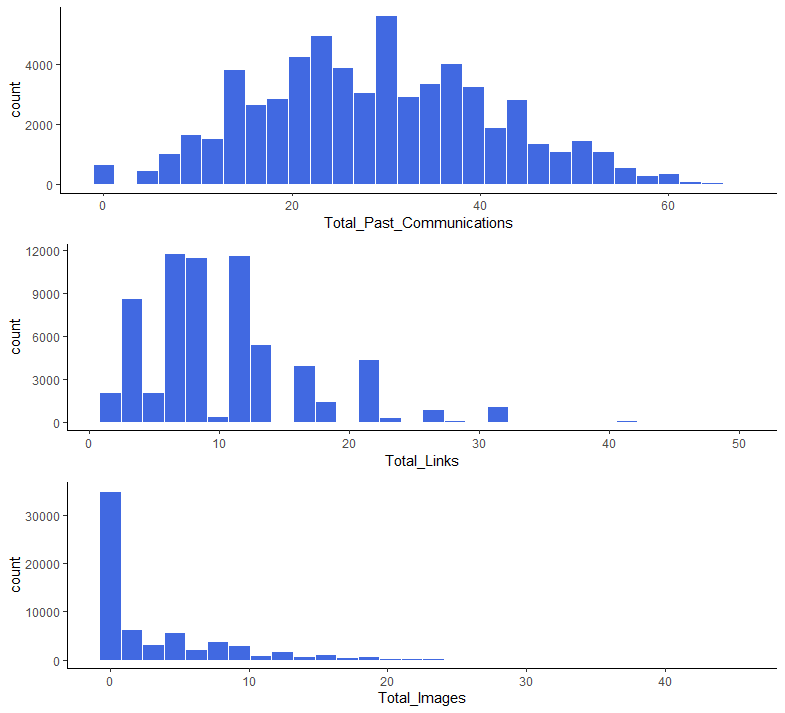
Total_Past_Communications 변수의 경우는 데이터가 나름 정규분포에 가까운 형태를 보이기 때문에 결측값의 대체로 평균을 사용해도 될 것 같습니다.
다만 Total_Links 변수와 Total_Images 변수의 경우는 데이터가 왼쪽으로 치우친 분포를 보이기 때문에 결측값의 대체로 평균 대신 중앙값을 사용하는 것이 더 나아보입니다.
따라서 recipes 패키지를 활용해 Customer_Location 변수에 존재하는 결측값을 최빈값으로 대체, Total_Past_Communications 변수에 존재하는 결측값을 평균으로 대체, 그리고 Total_Links와 Total_Images 변수에 존재하는 결측값은 중앙값으로 대체하겠습니다.
recipe <- train %>% recipe(Email_Status ~.) %>%
step_impute_mean(5) %>%
step_impute_median(8, 9) %>%
step_impute_mode(3) %>%
prep(training = train)
train <- juice(recipe)
missmap(train)
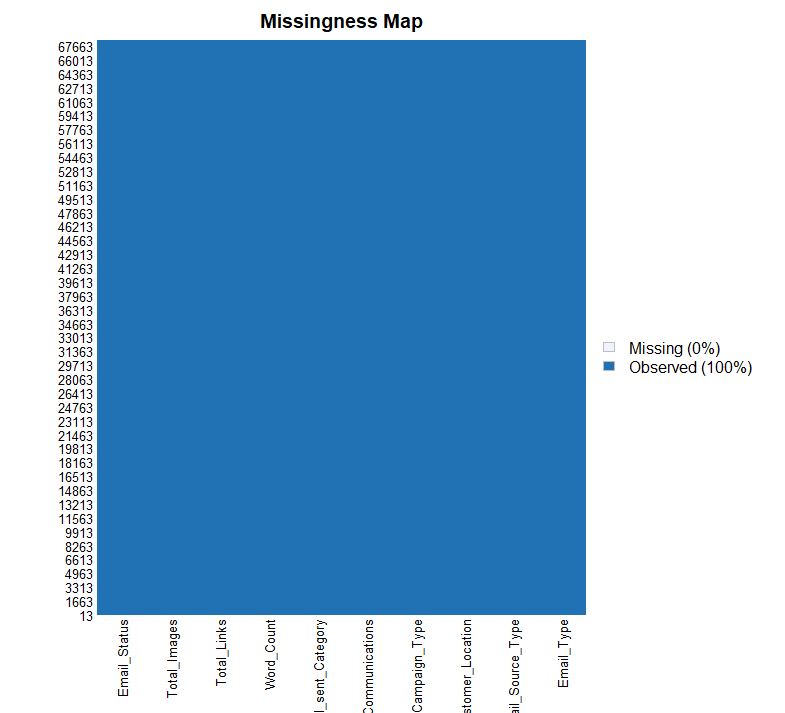
recipes를 활용해 결측값을 대체한 후 제대로 적용이 되었는지 missmap() 함수를 통해 다시 한 번 확인한 결과, 결측값이 전부 사라진 것을 확인할 수 있습니다.
먼저 범주형 변수에 대한 탐색을 진행하겠습니다.
train %>% group_by(Email_Type) %>% summarise(count = n()) %>% mutate(prop = round(count/sum(count),3)*100) %>%
ggplot(aes(x=Email_Type, y=count, fill = Email_Type)) + geom_bar(stat = "identity") + geom_text(aes(label = paste(prop, "%")), size = 10) + theme_classic()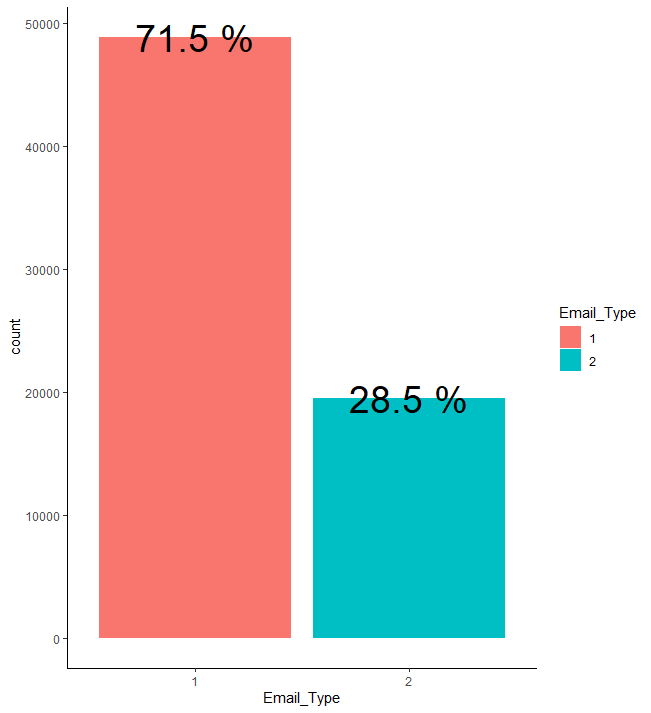
이메일 종류의 경우 1의 비율이 약 71.5%로 2에 비해 상당히 높습니다.
train %>% group_by(Email_Source_Type) %>% summarise(count = n()) %>% mutate(prop = round(count/sum(count),3)*100) %>%
ggplot(aes(x=Email_Source_Type, y=count, fill = Email_Source_Type)) + geom_bar(stat = "identity") + geom_text(aes(label = paste(prop, "%")), size = 10) + theme_classic()
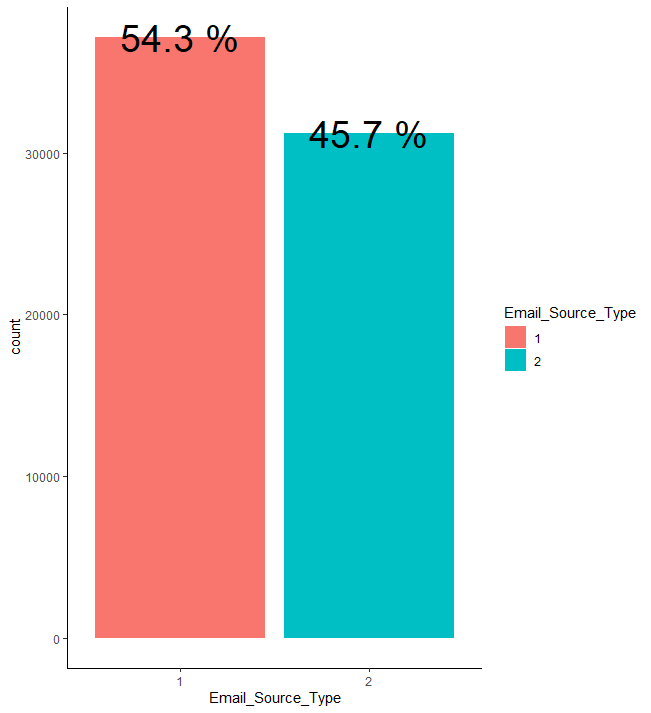
이메일 소스 종류의 경우 1의 비율이 약 54.3%로 2에 비해 약간 높습니다.
train %>% group_by(Customer_Location) %>% summarise(count = n()) %>% mutate(prop = round(count/sum(count),3)*100) %>%
ggplot(aes(x=fct_rev(fct_reorder(Customer_Location, count)), y=count, fill = Customer_Location)) + geom_bar(stat = "identity") + geom_text(aes(label = paste(prop, "%")), size = 5) + theme_classic() + xlab("Customer_Location")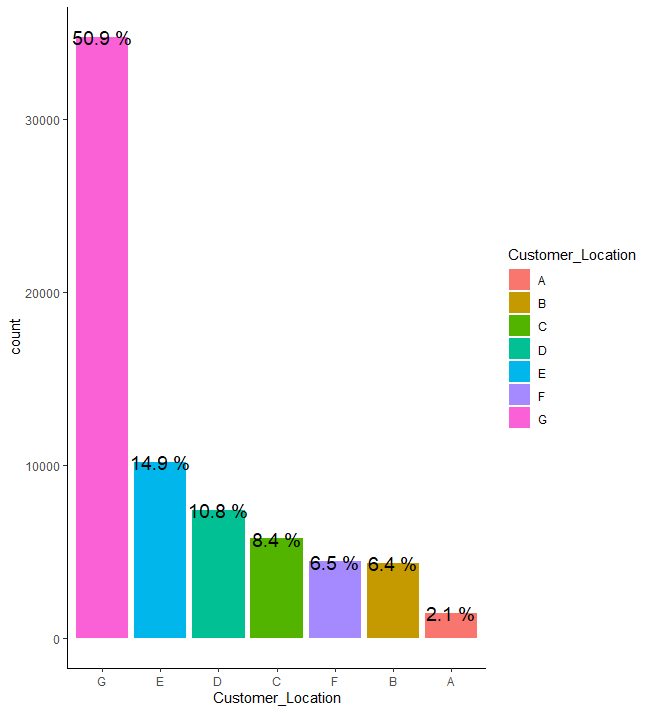
고객의 위치의 경우 G의 비율이 전체 7개의 level 중 약 50.9%로 매우 높으며, A의 비율이 약 2.1%로 가장 낮습니다.
train %>% group_by(Email_Campaign_Type) %>% summarise(count = n()) %>% mutate(prop = round(count/sum(count),3)*100) %>%
ggplot(aes(x=fct_rev(fct_reorder(Email_Campaign_Type, count)), y=count, fill = Email_Campaign_Type)) + geom_bar(stat = "identity") + geom_text(aes(label = paste(prop, "%")), size = 5) + theme_classic() + xlab("Email_Campaign_Type")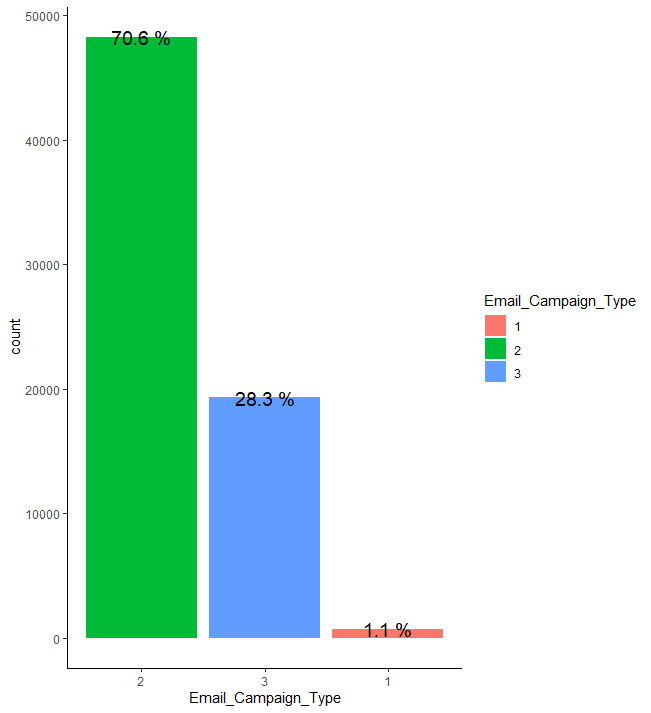
이메일 캠페인 종류의 경우 2의 비율이 약 70.6%로 가장 높으며, 1의 경우는 약 1.1%로 가장 낮습니다.
train %>% group_by(Time_Email_sent_Category) %>% summarise(count = n()) %>% mutate(prop = round(count/sum(count),3)*100) %>%
ggplot(aes(x=fct_rev(fct_reorder(Time_Email_sent_Category,count)), y=count, fill = Time_Email_sent_Category)) + geom_bar(stat = "identity") + geom_text(aes(label = paste(prop, "%")), size = 5) + theme_classic() + xlab("Time_Email_sent_Category")
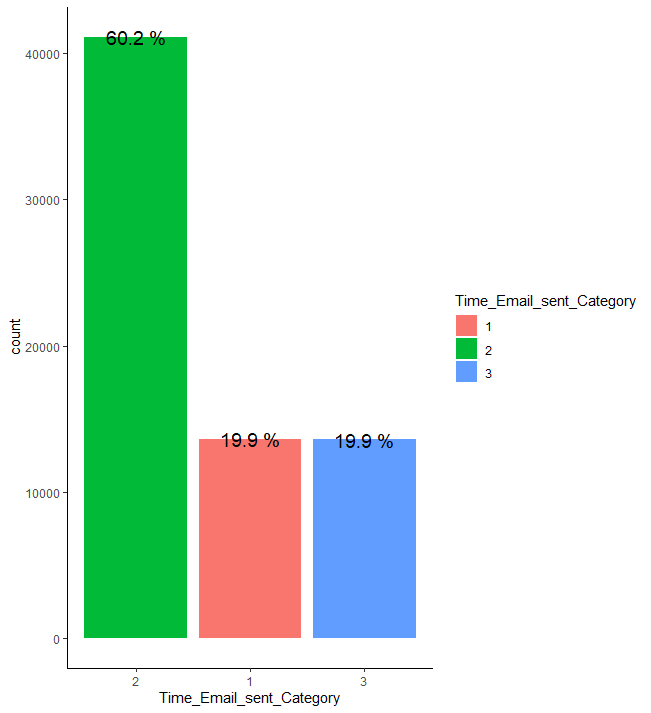
이메일 발송 시간 종류의 경우 2의 비율이 약 60.2%로 가장 높으며, 1과 3의 비율이 각각 19.9%로 같습니다.
train %>% group_by(Email_Status) %>% summarise(count = n()) %>% mutate(prop = round(count/sum(count),3)*100) %>%
ggplot(aes(x=Email_Status, y=count, fill = Email_Status)) + geom_bar(stat = "identity") + geom_text(aes(label = paste(prop, "%")), size = 5) + theme_classic()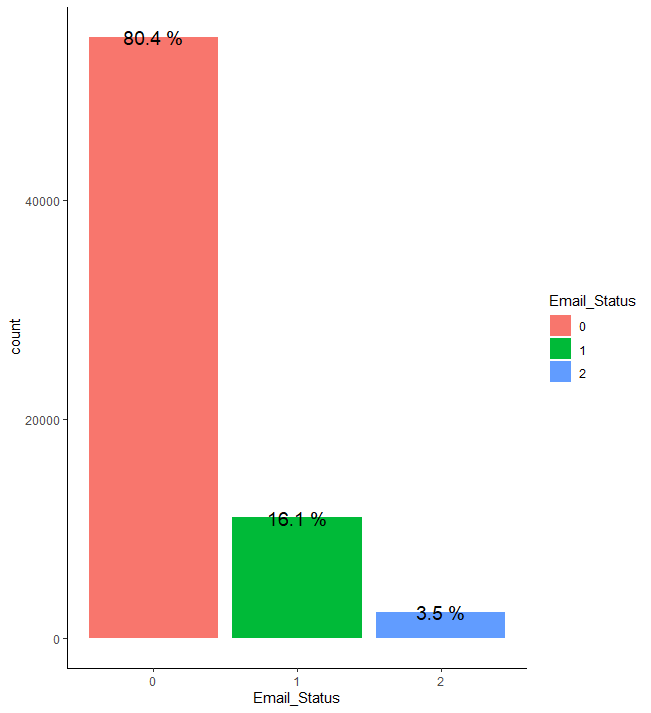
이메일 상태의 경우 0의 비율이 약 80.4%로 가장 높으며, 2의 비율이 약 3.5%로 가장 낮습니다.
이번에는 연속형 변수에 대한 탐색을 하겠습니다.
a <- train %>% ggplot(aes(x=Total_Past_Communications)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
b <- train %>% ggplot(aes(x=Word_Count)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
c <- train %>% ggplot(aes(x=Total_Links)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
d <- train %>% ggplot(aes(x=Total_Images)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
grid.arrange(a,b,c,d)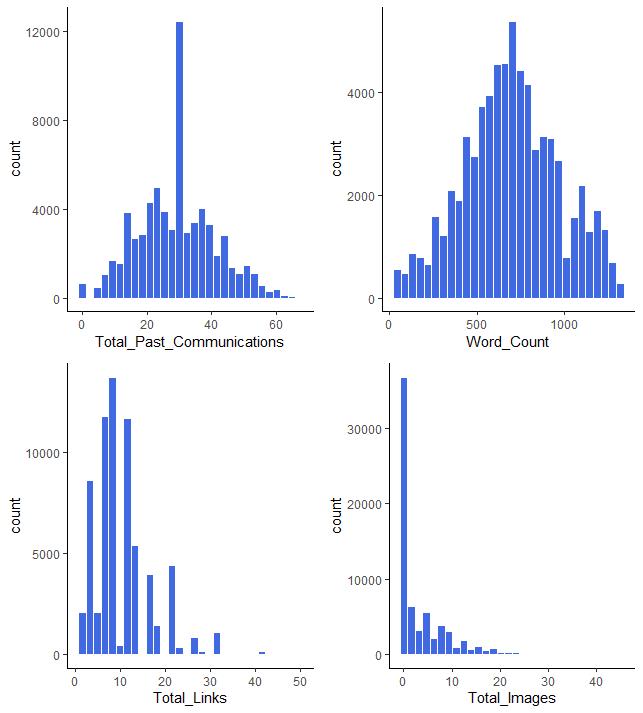
4개의 연속형 변수에 대한 히스토그램을 확인해보니, Total_Past_Communications와 Word_Count 변수의 경우는 나름 중앙으로 몰린 정규분포의 모습을 보이고 있습니다.
다만 Total_Links와 Total_Images 변수의 경우 왼쪽으로 치우친 비대칭 분포의 모습을 보이고 있습니다.
보통 왼쪽으로 치우친 비대칭 분포의 경우 로그화나 제곱근을 통해 정규분포화를 시도하는 것이 일반적이기 때문에, 일단 두 변수에 대해 로그화를 적용한 히스토그램을 반영해 다시 그래프를 그리겠습니다.
a <- train %>% ggplot(aes(x=Total_Past_Communications)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
b <- train %>% ggplot(aes(x=Word_Count)) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
c <- train %>% ggplot(aes(x=log(Total_Links))) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
d <- train %>% ggplot(aes(x=log(Total_Images))) + geom_histogram(fill = "royalblue", color = "white") + theme_classic()
grid.arrange(a,b,c,d)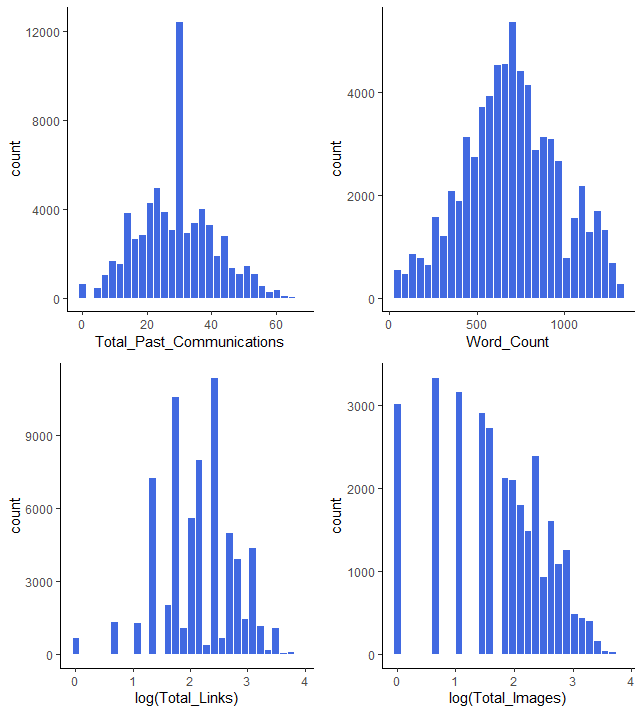
Total_Links 변수의 경우는 로그화를 적용한 결과 왼쪽으로 치우친 정도가 많이 해소되면서 중앙으로 몰린 정규분포의 모습을 보입니다.
다만 Total_Images 변수의 경우는 로그화를 적용한 결과 오히려 오른쪽으로 데이터가 치우치게 되는 역설적인 상황이 발생하였습니다.
따라서 Total_Images 변수의 경우는 로그화가 아닌 제곱근을 적용하겠습니다.
train$Total_Links <- log(train$Total_Links)
train$Total_Images <- sqrt(train$Total_Images)한 번 4개의 연속형 변수들 간의 상관관계 또한 corrgram() 함수를 통해 파악해보겠습니다.
library(corrgram)
corrgram(train[,c(5,7,8,9)], upper.panel = panel.conf)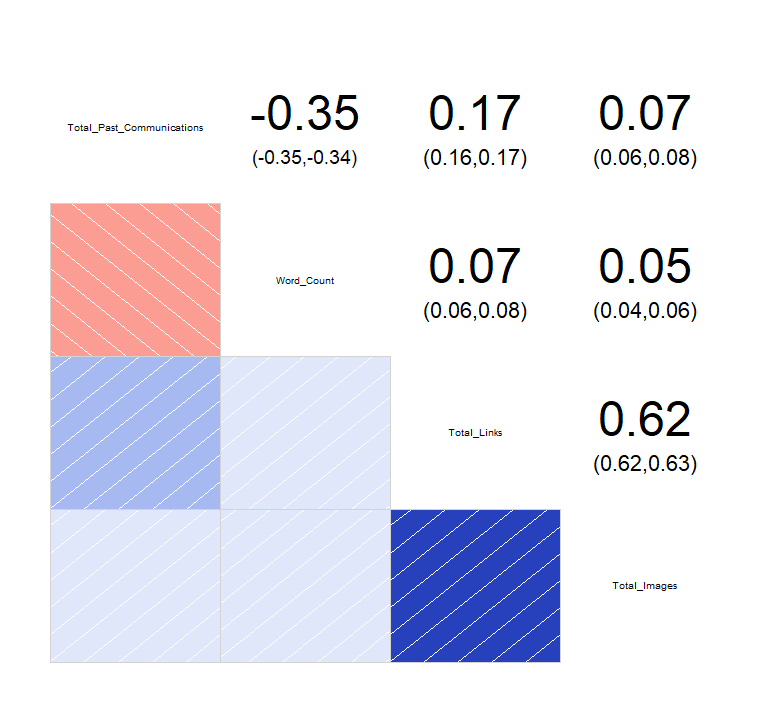
상관관계 그래프를 그려본 결과, Total_Links 변수와 Total_Images 변수 사이의 상관계수가 0.62로써 상당히 높은 양의 상관관계를 가지고 있다는 것을 알 수 있습니다.
아마 이메일을 보낼 때 이미지를 첨부할 경우 링크 또한 같이 첨부하는 상황이 많이 발생하는 것 같습니다.
이제 Email_Status 변수를 Target 변수로 설정한 몇 가지 EDA를 진행하겠습니다.
PlotXTabs2(train, Email_Type, Email_Status, palette = "Oranges") + theme_classic()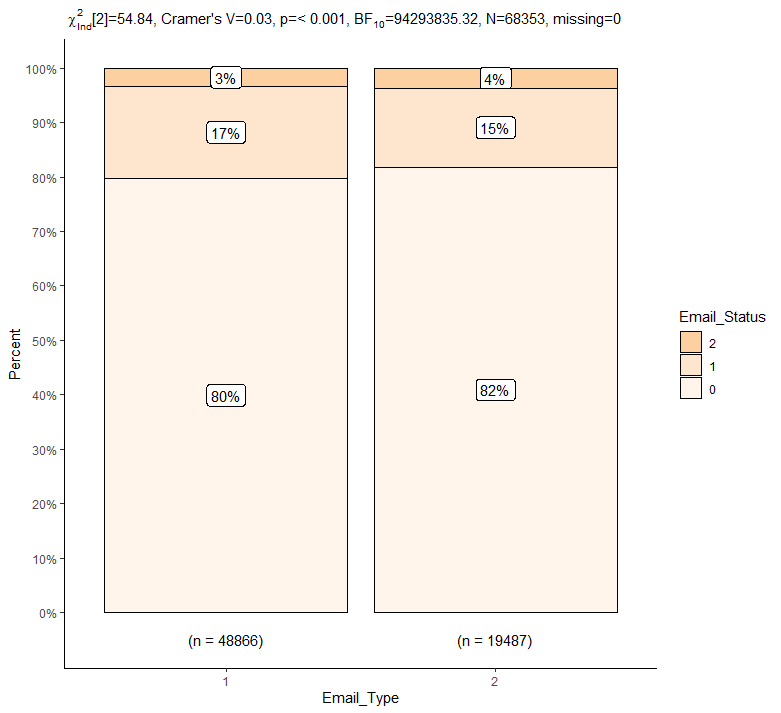
이메일 종류에 따른 이메일 상태의 각 비율 간에는 큰 차이가 없어보입니다.
이메일 종류에 따른 이메일 상태의 각 비율 간에 통계적으로 유의한 차이가 존재하는 지 확인하기 위해 카이제곱 동질성 검정을 실시하도록 하겠습니다.
a <- table(train$Email_Type, train$Email_Status)
chisq.test(a)Pearson's Chi-squared test
data: a
X-squared = 54.842, df = 2, p-value = 1.234e-12
카이제곱 동질성 검정 결과 p-value의 값이 유의수준 0.05보다 매우 낮기 때문에 이메일 종류에 따른 이메일 상태의 각 비율이 모두 같지는 않다고 판단할 수 있습니다.
따라서 어느 부분에서 유의한 차이가 발생한 것인지 확인하기 위해 사후검정을 실시해야 하는데, 카이제곱 동질성 검정의 사후검정으로는 피어슨 수정잔차를 구해서 확인하는 것이 가장 보편적인 방법입니다.
R에서는 chisq.posthoc.test 패키지를 통해 해당 기능을 지원하고 있습니다. 한 번 chisq.posthoc.test() 함수를 사용해 사후검정을 실시하겠습니다.
a <- table(train$Email_Type, train$Email_Status)
chisq.posthoc.test(a)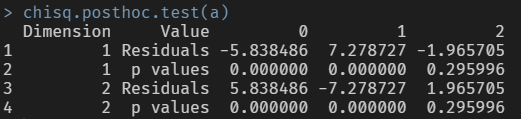
사후검정 결과 이메일 종류에 따른 이메일 상태의 각 비율 중, 0과 1에서는 p-value가 매우 작으므로 이메일 종류에 따라 유의한 차이가 존재합니다.
다만 이메일 종류에 따른 이메일 상태 중 2의 경우는 p-value가 0.05보다 크기 때문에 이메일 종류에 따른 이메일 상태(2)의 비율 간에는 차이가 없다고 볼 수 있습니다.
즉 이메일 종류에 따른 이메일 상태 중 0과 1의 비율 간에는 유의한 차이가 존재하지만, 2의 비율 간에는 차이가 없습니다.
이메일 종류가 1일 경우에는 이메일 상태가 1일 비율이 이메일 종류가 2일 경우보다 약 2% 높으며, 이메일 종류가 2일 경우에는 이메일 상태가 0일 비율이 이메일 종류가 1일 경우보다 약 2% 높습니다.
PlotXTabs2(train, Email_Source_Type, Email_Status, palette = "Oranges")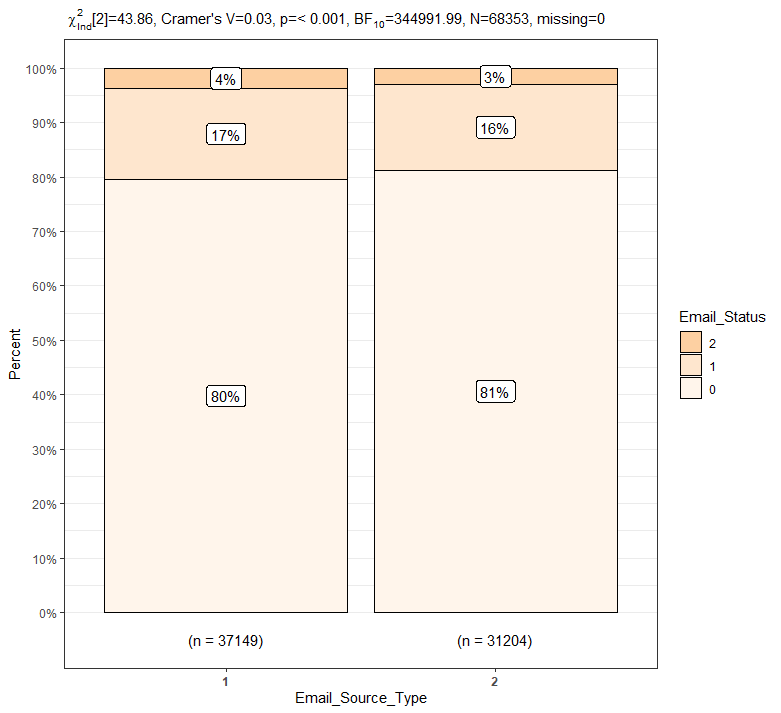
이메일 소스 종류에 따른 이메일 상태의 각 비율 간에는 거의 차이가 없어보입니다.
카이제곱 동질성 검정을 통해 이메일 소스 종류에 따른 이메일 상태의 각 비율 간에 통계적으로 유의한 차이가 존재하는 지 확인하겠습니다.
a <- table(train$Email_Source_Type, train$Email_Status)
chisq.test(a)Pearson's Chi-squared test
data: a
X-squared = 43.859, df = 2, p-value = 2.993e-10
카이제곱 동질성 검정 결과 p-value가 0.05보다 매우 낮기 때문에 이메일 소스 종류에 따른 이메일 상태의 각 비율이 모두 같지는 않다고 판단할 수 있습니다.
따라서 사후검정을 통해 어느 부분에서 유의한 차이가 존재하는 지 확인하겠습니다.
chisq.posthoc.test(a)
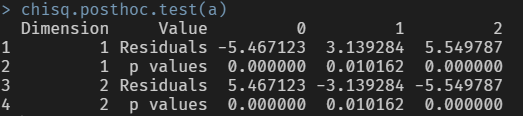
모든 영역의 p-value가 0.05보다 작기 때문에 이메일 소스 종류에 따른 이메일 상태의 각 비율은 전부 다르다고 판단할 수 있습니다.
이메일 소스 종류가 1일 경우 이메일 상태 중 2와 1의 비율이 이메일 소스 종류가 2일 경우보다 각각 약 1%씩 높습니다.
이메일 소스 종류가 2일 경우 이메일 상태 중 0의 비율이 이메일 소스 종류가 1일 경우보다 약 1% 높습니다.
PlotXTabs2(train, Customer_Location, Email_Status, palette = "PuBu")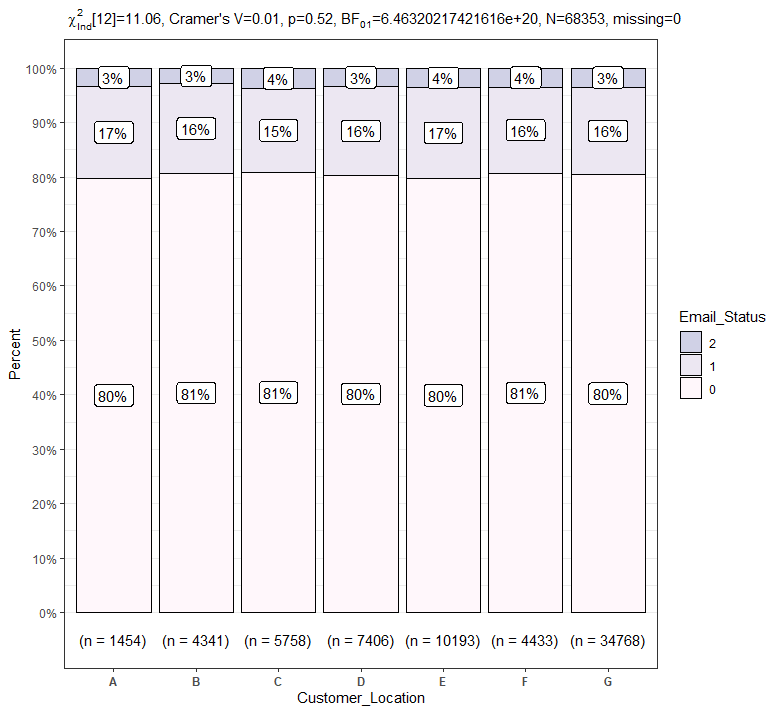
고객의 위치에 따른 이메일 상태의 각 비율 간에는 거의 차이가 없어보입니다.
마찬가지로 카이제곱 동질성 검정을 통해 고객의 위치에 따른 이메일 상태의 각 비율 간에는 통계적으로 유의한 차이가 존재하는지 확인하겠습니다.
a <- table(train$Customer_Location, train$Email_Status)
chisq.test(a)Pearson's Chi-squared test
data: a
X-squared = 11.064, df = 12, p-value = 0.5234
카이제곱 동질성 검정 결과 p-value가 0.05보다 크기 때문에 고객의 위치에 따른 이메일 상태의 각 비율은 모두 같다고 판단할 수 있습니다.
즉, 고객의 위치는 이메일 상태의 각 비율에 유의한 영향을 미치지 못한다고 말할 수 있으며 사후검정을 진행할 필요가 없습니다.
PlotXTabs2(train, Email_Campaign_Type, Email_Status, palette = "Oranges")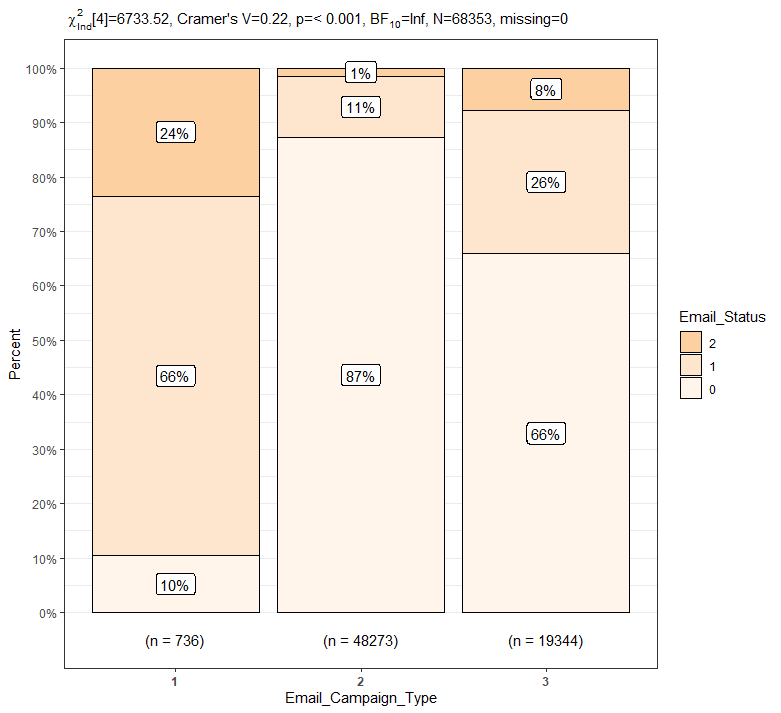
이메일 캠페인 종류에 따른 이메일 상태의 각 비율 간에 상당한 차이가 있다는 것을 그래프를 통해 짐작할 수 있습니다.
한 번 카이제곱 동질성 검정을 통해 이메일 캠페인 종류에 따른 이메일 상태의 각 비율 간에는 통계적으로 유의한 차이가 존재하는지 확인해보겠습니다.
chisq.test(a)
chisq.posthoc.test(a)Pearson's Chi-squared test
data: a
X-squared = 6733.5, df = 4, p-value < 2.2e-16
카이제곱 동질성 검정 결과 p-value가 0.05보다 매우 낮기 때문에 이메일 캠페인 종류에 따른 이메일 상태의 각 비율이 모두 같지는 않다고 판단할 수 있습니다.
따라서 사후검정을 통해 어느 부분에서 유의한 차이가 존재하는 지 확인하겠습니다.
chisq.posthoc.test(a)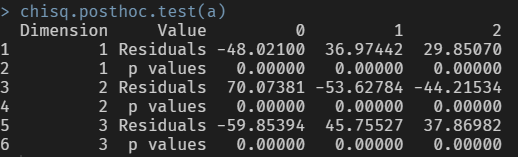
사후검정 결과 모든 영역의 p-value가 0.05보다 매우 낮기 때문에 이메일 캠페인 종류에 따른 이메일 상태의 각 비율은 전부 다르다고 판단할 수 있습니다.
이메일 캠페인 타입이 1일 경우 이메일 상태 중 1의 비율이 약 66%로 가장 높으며, 이메일 캠페인 타입이 2와 3일 경우 이메일 상태 중 0의 비율이 각각 87%와 66%로 가장 높습니다.
이메일 캠페인 종류가 1인 경우에 이메일 상태 중 2와 1의 비율이 가장 높으며, 이메일 캠페인 종류가 2인 경우에 이메일 상태 중 0의 비율이 가장 높습니다.
PlotXTabs2(train, Time_Email_sent_Category, Email_Status, palette = "PuBu")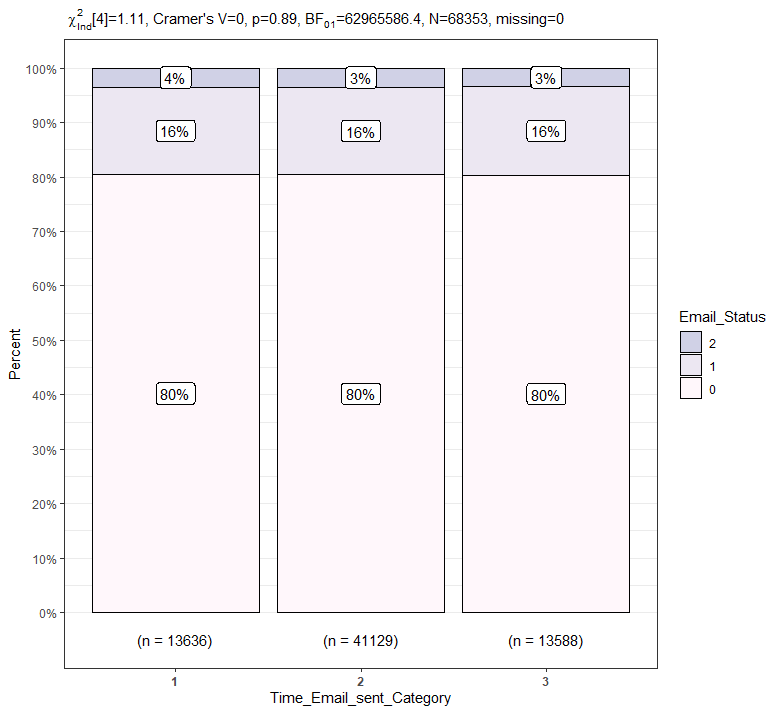
이메일 발송 시간 종류에 따른 이메일 상태의 각 비율 간에는 차이가 없어보입니다.
카이제곱 동질성 검정을 통해 이메일 발송 시간 종류에 따른 이메일 상태의 각 비율 간에는 통계적으로 유의한 차이가 존재하는지 확인하겠습니다.
a <- table(train$Time_Email_sent_Category, train$Email_Status)
chisq.test(a)chisq.test(a)
Pearson's Chi-squared test
data: a
X-squared = 1.1065, df = 4, p-value = 0.8932
카이제곱 동질성 검정 결과 p-value가 0.05보다 크기 때문에 이메일 발송 시간 종류에 따른 이메일 상태의 각 비율은 모두 같다고 판단할 수 있습니다.
따라서 사후검정을 진행할 필요가 없으며, 이메일 발송 시간 종류는 이메일 상태에 통계적으로 유의한 영향을 주지 않습니다.
이렇게 EDA를 마친 결과, 이메일 상태에 통계적으로 유의한 영향을 미치는 변수는 Email_Type, Email_Source_Type 그리고 Email_Campaign_Type으로 확인되었으며, Customer_Location 변수와 Time_Email_sent_Category 변수는 통계적으로 유의한 영향을 미치지 못하는 것으로 확인되었습니다.
따라서 이메일 종류, 이메일 소스 종류, 이메일 캠페인 종류를 잘 활용하여 이메일 상태의 각 비율을 조절하는 것 또한 괜찮은 방법일 것 같습니다.
예를 들어 이메일 상태 중 1의 비율을 늘리고 싶다면, 이메일 종류, 이메일 소스 종류 그리고 이메일 캠페인 종류를 모두 1로 결정할 수 있을 것 같습니다.
이상으로 이메일 캠페인 데이터셋을 활용한 EDA 및 가설 검정을 마치도록 하겠습니다. 감사합니다.
