SDF (Signed Distance Function) 와 Eikonal Equation 의 관계는?
3D AI
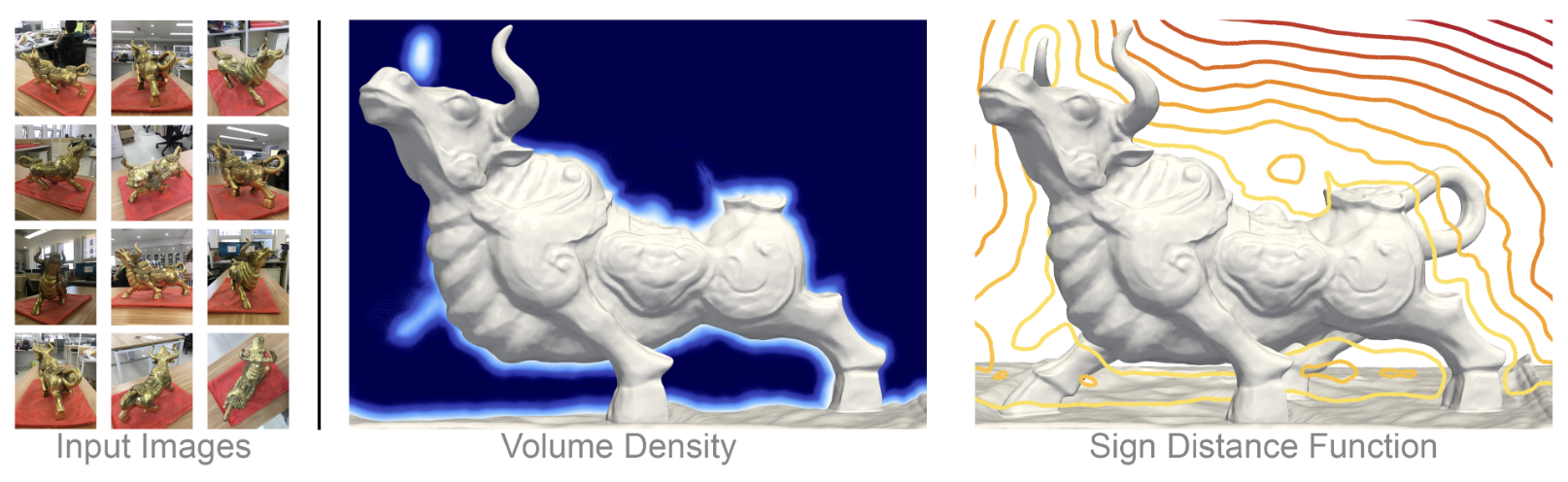
- Neus 등의 SDF 학습을 위해 사용하는 eikonal loss 를 유도해보자!
1. 들어가며: SDF & Surface Reconstruction
블로그에서는 잘 다루지 않았지만, Implicit Neural Network 가 주요 task 로 다루는 것은 NeRF 를 위시한 Novel View Synthesis 뿐만이 아니다. NeRF 만으로 풀기 어려운 문제들도 상당히 많으며, 그 중 대표적인 문제가 바로 Surface Reconstruction 이다.
Radiance Fields 계열의 기술들은 3D scene reconstruction 을 위해 주로 opacity 값을 누적하여 간접적으로 표면을 처리하는 방식을 사용한다. 이러한 접근 방식은 장면 전체를 표현하는 데는 효과적이지만, 정확한 surface reconstruction 에는 취약하다.
이와 대조적으로 SDF (Signed Distance Function)는 3D surface reconstruction 에 훨씬 특화된 모델이다. SDF는 공간 내의 각 점에 대해 해당 점에서 표면까지의 최단 거리를 나타내며, 그 거리 값이 0인 점들의 집합, 즉 zero-level set (isosurface) 이 바로 실제 surface 를 정의하게 된다.
NeRF 와 마찬가지로, MLP 로 이러한 SDF function 을 근사하게 되며, 다음과 같은 주요 연구들이 있다.
- DeepSDF: Learning Continuous Signed Distance Functions for Shape Reconstruction
- NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
- Volume Rendering of Neural Implicit Surfaces
- Neuralangelo: High-Fidelity Neural Surface Reconstruction

- figure credit: Neuralangelo
이러한 SDF 계열 논문을 읽다 보면, 필연적으로 마주하게 되는 공식이 바로 eikonal equation,
와 이를 통해서 유도된 eikonal regularization term (or eikonal loss)
이다. (: MLP's parameter)
이 글에서는 SDF 학습이 왜 이러한 eikonal equation 을 푸는 것과 동치인지 알아볼 것이다.
2. SDF to Eikonal Equation
공간을 점유하고 있는 어떠한 object 와 이 object 의 boundary 에 대하여, 우리는 SDF (Signed Distance Function) 을 다음과 같이 정의할 수 있다.
여기서 는 와 boundary 사이의 distance 이다.
이제
- 삼각부등식과 경로 적분을 이용하는 방식
- 기하학적인 직관을 이용한 조금 더 간단한 방식
두 방법으로 SDF function 이 eikonal equation 을 만족함을 증명하겠다.
2.2. Proof 1: Using the Triangle Inequality and Path Integration
2.1.1. Upper bound of the SDF's gradient
내의 임의의 두 점 , 와 이를 잇는 선분 에 대하여, 삼각부등식으로 다음이 성립한다.
이제 이 식으로부터, 로 치환하여 대입해보면 다음과 같은 부등식을 얻는다.
여기서 으로 보내 극한값을 구해보면
임을 알 수 있고, 따라서 이 성립한다.
2.1.2. Lower bound of the SDF's gradient
에 대하여, 가 와 boundary 사이의 shortest path 라고 가정하자.
이 경우, 모든 에 대하여 SDF 는 다음과 같이 표현할 수 있다.
이는 가 와 boundary 사이의 최단 경로에 있기 때문에, 와 boundary 사이의 거리가 해당 경로의 길이와 같음을 의미한다.
따라서 위의 방정식을 미분하면 다음을 얻을 수 있고,
Cauchy–Schwarz inequality 에 의해
을 만족하므로
임을 알 수 있다.
2.2. Proof 2: Using Geometric Intuition
2.2.1. Gradient of the Distance Function
Distance Function 는 boundary 수직인 방향으로 최단 거리를 측정한다. 정의에 따라 distance function 의 gradient 는 distance 값이 steepest ascent 하는 방향, 즉 surface normal direction 과 같아야 할 것이다.
따라서 distance function 의 gradient 는 다음과 같다.
2.2.2. Norm of the gradient
-
:
-
:
distance function 의 gradient 는 unit vector 이므로 그 norm 은 항상 1 이다.
따라서, 모든 에 대하여 eikonal equation
이 만족한다.
3. Conclusion?
그래서 어쩌라고? 저 식이 무슨 의미인지 알면 SDF 학습이 더 잘되나?
그런 것은 아니다. 오히려 저 식은 SDF 학습이 어렵게 하는 주범 중의 하나이다.
eikonal loss term 을 계산하려면 MLP 에 대한 second derivative 가 필요한데, INN 전가의 보도로 등장하는 Instant-NGP, tcnn library 에는 공식적으로 second derivative 기능을 제공하지 않는다.
그래서 Hash-Grid (feature-grid) representation 을 사용하는 SDF method 는 gradient 를 analytic 하게 계산하는 대신 finite difference 를 이용하여 numerical gradient 를 계산한다.
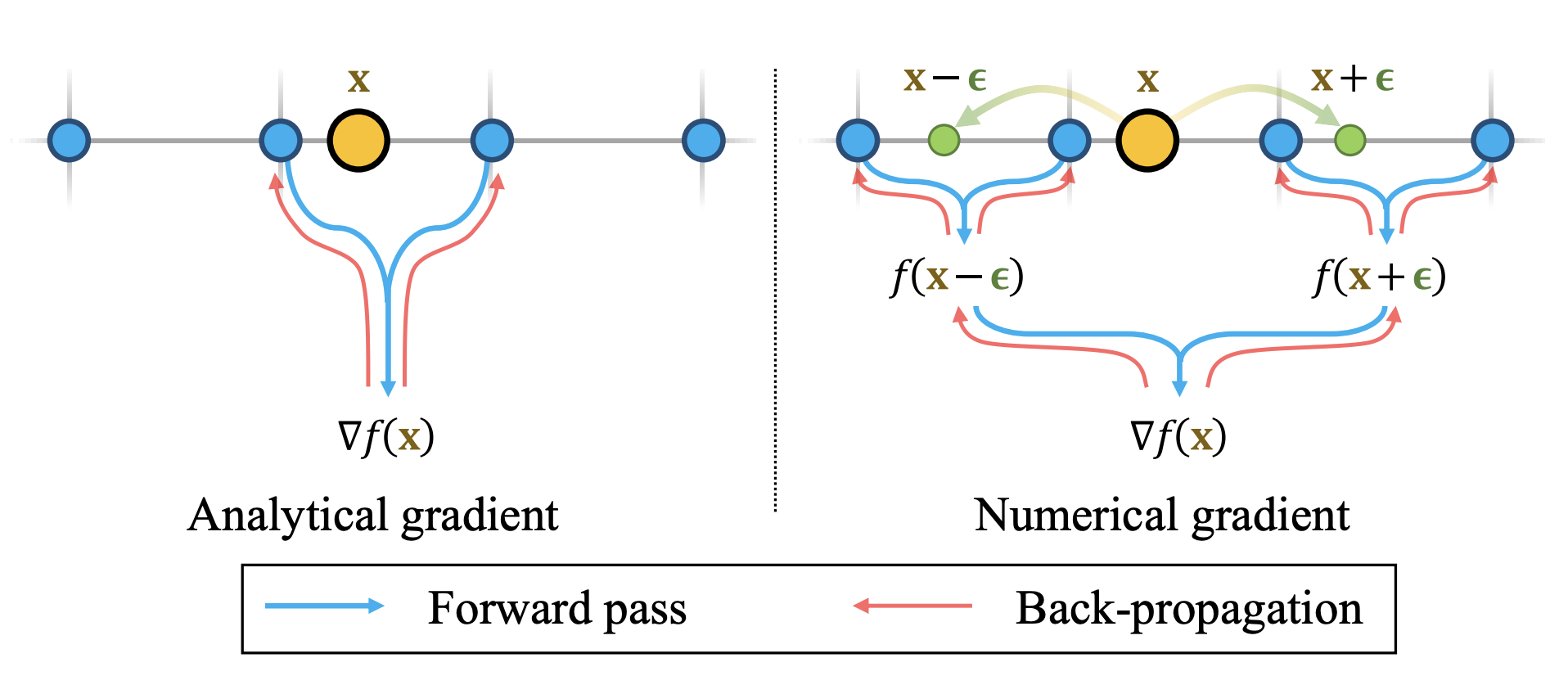
대표적으로, 인용했던 Neuralangelo 등이 해당 방식을 통해 gradient 를 계산하며, 이는 neuralangelo 의 original Instant-NGP 대비 학습 시간 증가의 원인 중 하나이다.
SDF는 second derivative 까지는 근사할 필요가 없는 NeRF 보다 복잡하지만, 더 정확한 3D surface 를 얻을 수 있다는 점에서 그 가치가 있다. 이러한 SDF 의 핵심적인 문제가 eikonal equation 을 잘 근사하는 것이므로, 수학적으로 정확히 이해하는 것이 SDF 학습의 최적화된 방법을 찾아가는 첫 단계라고 믿는다.
cf. https://math.stackexchange.com/questions/3605929/signed-distance-function-and-the-eikonal-equation
You may also likes:
