
데이터 분석을 공부할때 수학의정석 처럼 기초단계에서 반드시 거치는 데이터셋이 있다.
바로 iris 데이터다.
iris데이터는 1930년대에 통계학자이자 유전학자였던 로널드 피셔가 정리한 데이터로,
붓꽃 중 [Setosa, Versicolour, Virginica] 3가지 품종의 꽃잎과 꽃받침의 길이와 넓이 데이터를 갖고 있다.
꽃잎과 꽃받침의 길이로 붓꽃의 품종을 분류하는 모델을 만들어보자.
import numpy as np import pandas as pd
1. 데이터 불러오기
from sklearn.datasets import load_iris iris = load_iris()
iris데이터는 sklearn 패키지에 들어있다.
load_iris()로 iris 에 데이터셋을 저장했다.
iris.keys()

iris 데이터는 딕셔너리와 비슷한 형태이나, 딕셔너리는 아니다.
.keys()를 사용해 iris데이타의 키값을 확인할수 있다.
print(iris['DESCR'])
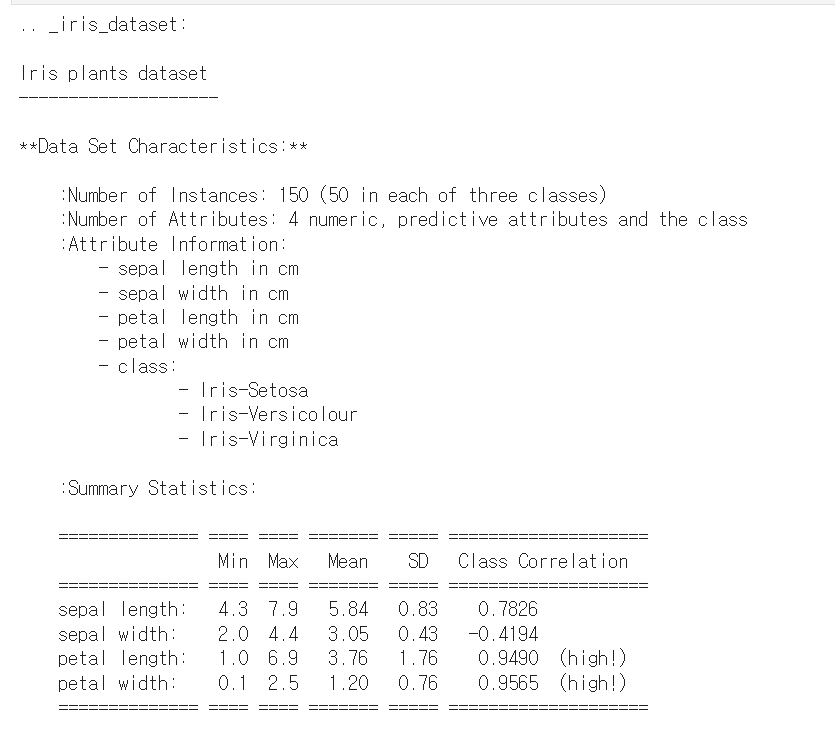
DESCR은 데이터셋을 설명해준다.
1) 이 데이터셋에는 한 클래스에 50개씩, 총 150개의 데이터가 들어있다.
2) 특성은 sepal length in (cm), sepal width in (cm), petal length in (cm), petal width in (cm)으로 총 4가지가 있다. (sepal:꽃받침, petal:꽃잎)
3) 클래스는 Iris-Setosa, Iris-Versicolour, Iris-Virginica가 있다.
4) 표에는 각 특성의 최소값, 최대값, 평균값, 분산값이 나타나있다.
print(iris['target'])
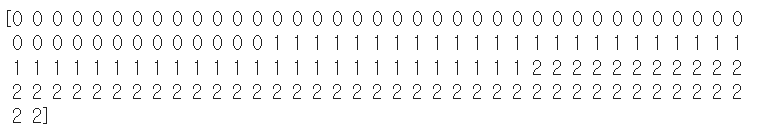
0 : 'setosa'
1 : 'versicolor'
2 : 'virginica'
각 50개씩 총 150개의 데이터가 있다.
iris.data

이렇게 각 특성이 리스트형으로 들어 있는것을 볼수 있다.
2. 데이터 다듬기
iris_pd = pd.DataFrame(iris.data, columns = iris.feature_names) iris_pd.head()
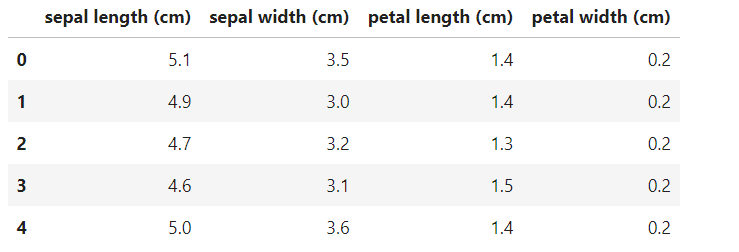
pandas의 dataframe형태로 데이터를 만들어준다.
iris_pd['species'] = iris.target iris_pd.head()
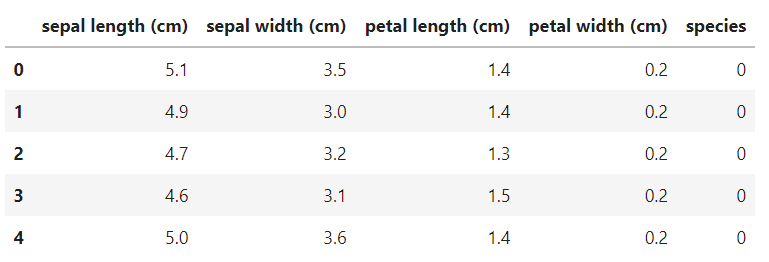
품종 정보도 species 컬럼으로 만들어 추가한다.
3. 그래프 그리기
import seaborn as sns import matplotlib.pyplot as plt from matplotlib import rc rc('font', family = "Malgun Gothic") %matplotlib inline
필요한 모듈을 불러오고, matplotlib의 한글설정도 해준다.
(1) sepal length
boxplot을 그려 sepal length와 species 간 관계를 확인해보자.
plt.figure(figsize=(12, 6)) sns.boxplot(x="sepal length (cm)", y="species", data=iris_pd, orient="h");
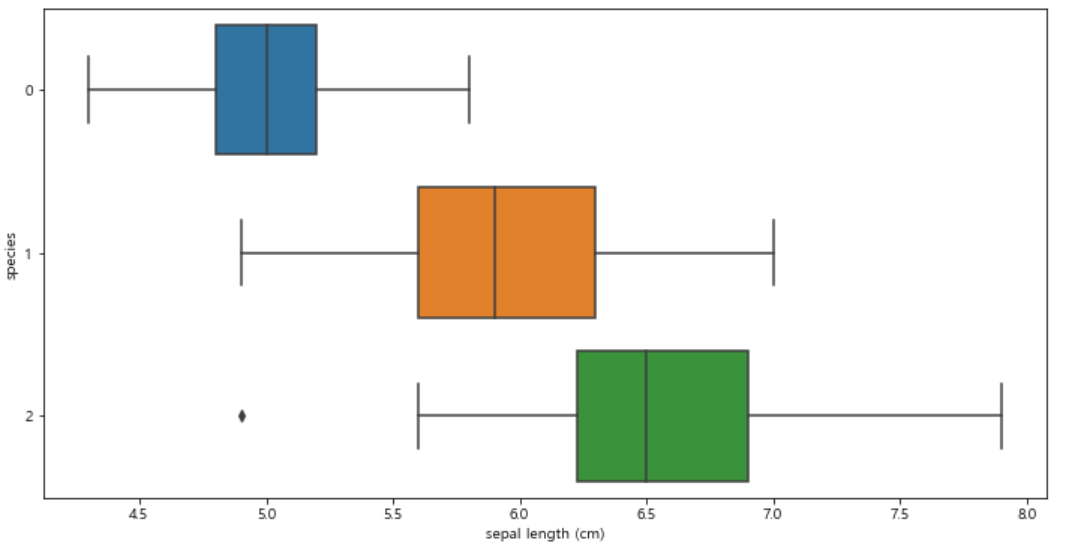
1) 55 - 60 구간은 세 품종 모두 해당. 따라서 sepal length 만 가지고 품종을 구분하는 것은 어려울듯!
2) virginica(2)에 이상점이 하나 존재!
(2) sepal width
boxplot을 그려 sepal width와 species 간 관계를 확인해보자.
plt.figure(figsize=(12, 6)) sns.boxplot(x="sepal width (cm)", y="species", data=iris_pd, orient="h");
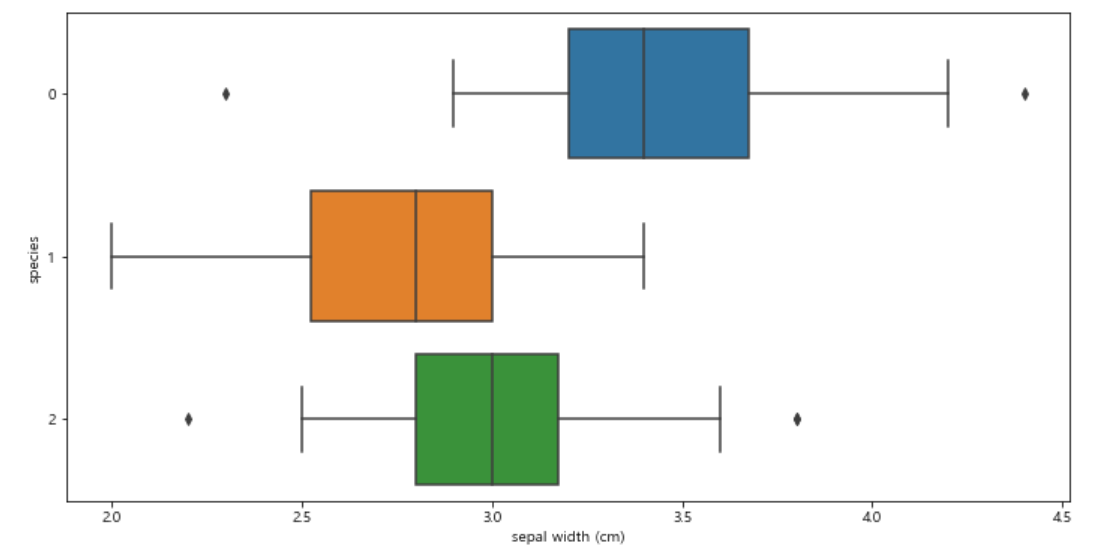
sepal width도 품종별로 큰 특징을 보이는 부분이 없어서 품종 구분에 도움이 안될것 같다!
(3) petal width
boxplot을 그려 petal width와 species 간 관계를 확인해보자.
plt.figure(figsize=(12, 6)) sns.boxplot(x="petal width (cm)", y="species", data=iris_pd, orient="h");
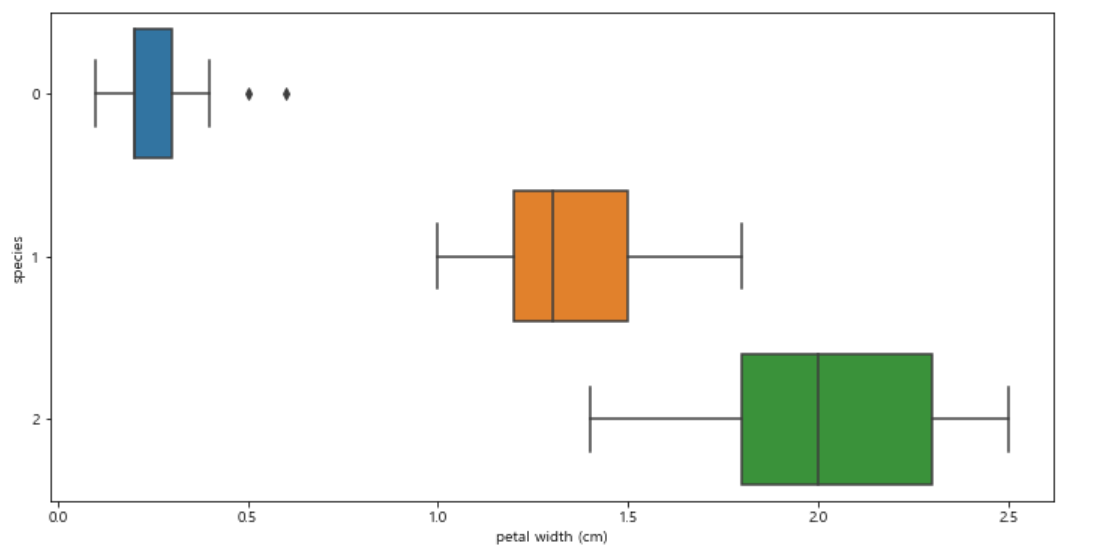
setosa 만 0에서 1사이의 값을 갖는다.
하지만 다른 두 품종을 구분하기는 어려워 보인다.
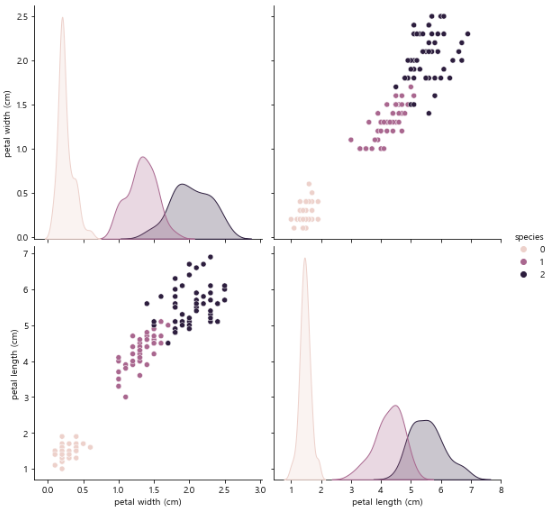
(4) pairplot
pairplot으로 한번에 확인해보자!
sns.pairplot(iris_pd, hue="species");
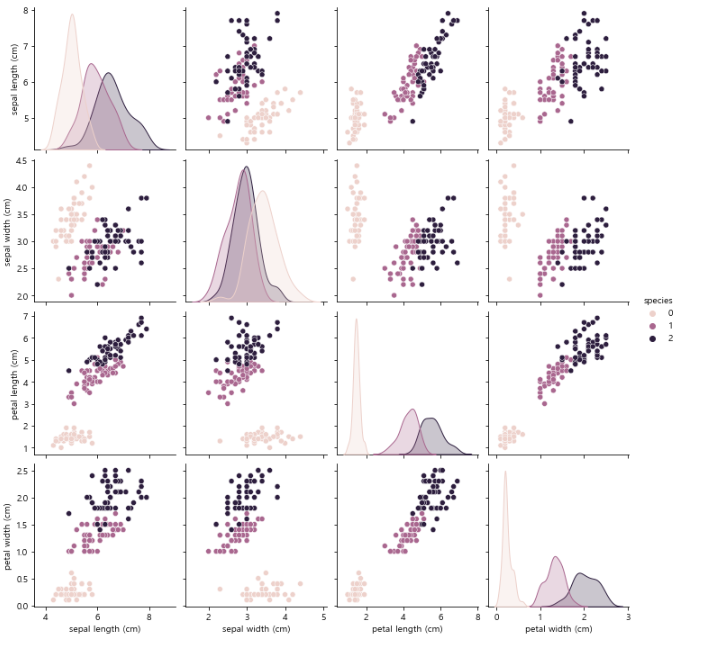
petal width와 petal length가 품종간 겹치는 부분이 거의 없어보인다.
(5) pairplot
위에서 유의미하다고 생각한 petal width와 petal length만 가지고 pairplot을 그려보자.
sns.pairplot(data=iris_pd, vars=["petal width (cm)", "petal length (cm)"], hue="species", height=4);
petal length가 2.5 보다 작다면 Setosa
petal length가 2.5 보다 크고 & petal width 가 1.6 보다 작다면 Versicolor
petal length가 2.5 보다 크고 & petal width 가 1.6 보다 크다면 Virginica
로 분류할 수 있을것 같다!!
4. 모델 만들기(Decision Tree)
plt.figure(figsize=(12, 6)) sns.scatterplot(x="petal length (cm)", y="petal width (cm)", data=iris_pd, hue="species", palette="Set2");
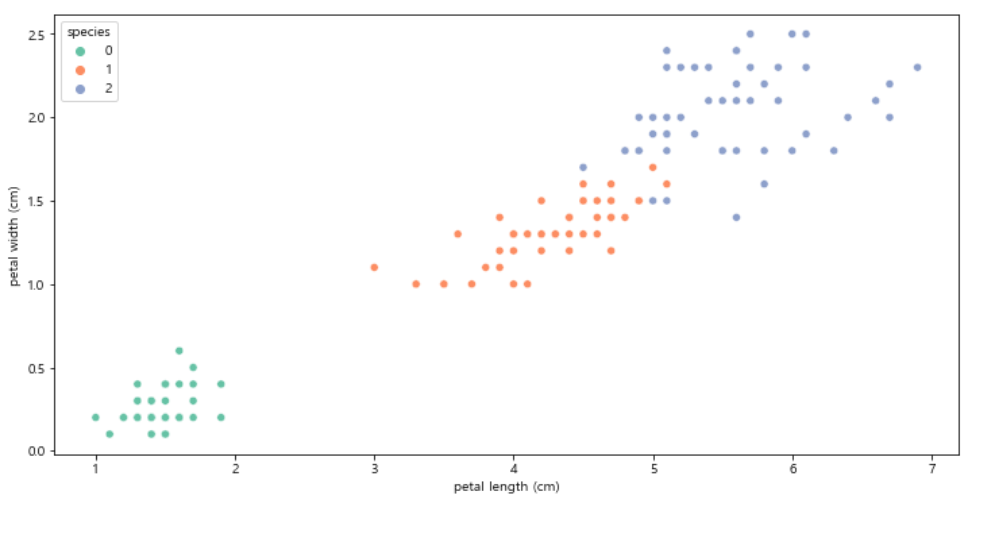
위에서 본 petal length 와 petal width 그래프다.
Versicolor와 Virginica를 구분지을 prtal width의 경계값이 1.6 이라고 확신할 수 없다.
Decision Tree 모델을 사용해 제일 최선의 경계값을 구해보자.
iris_12 = iris_pd[iris_pd['species']!=0]
Versicolor와 Virginica를 구분하는게 목적이니, 그 둘만 가지고 dataframe을 다시 만들었다.
plt.figure(figsize=(12, 6)) sns.scatterplot(x="petal length (cm)", y="petal width (cm)", data=iris_12, hue="species", palette="Set2");
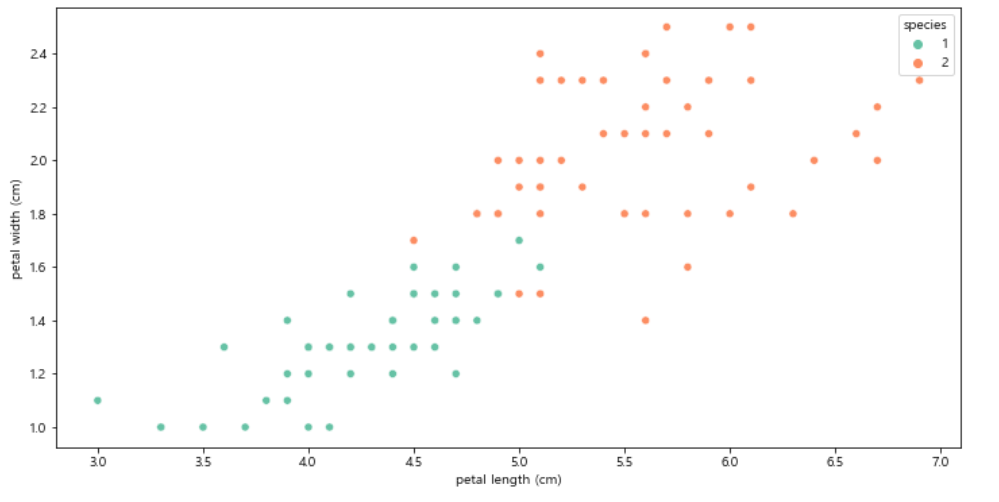
다시한번 petal length 와 petal width 의 그래프를 확인해봤다.
역시 경계값이 애매하다.
사실 petal length, petla width 모두 애매하다.
sklearn을 이용한 Decision Tree 구현
- fit(학습데이터, 정답): 제공받은 데이터를 학습하는 모듈
from sklearn.tree import DecisionTreeClassifier iris_tree = DecisionTreeClassifier() iris_tree.fit(iris.data[:, 2:], iris.target)
iris.data[:, 2:] : data의 모든 행&petal length와 petal width 컬럼을 학습데이터로 사용
iris.target : target이 Decision Tree의 분류 대상
- predict(데이터) : 학습한 내용을 바탕으로 데이터를 예측
- accuracy_score(정답, 예측값) : 두 데이터를 비교해 정확도를 계산
from sklearn.metrics import accuracy_score y_pred_tr = iris_tree.predict(iris.data[:, 2:]) accuracy_score(iris.target, y_pred_tr)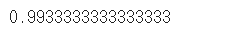
predict로 예측하고 그 결과값을 y_pred_tr에 저장한다.
accuracy_score() 을 사용해 성능을 확인해봤더니 약 99% 의 정확도를 갖는다고 한다!!!!
from sklearn.tree import plot_tree plt.figure(figsize=(12, 8)) plot_tree(iris_tree);
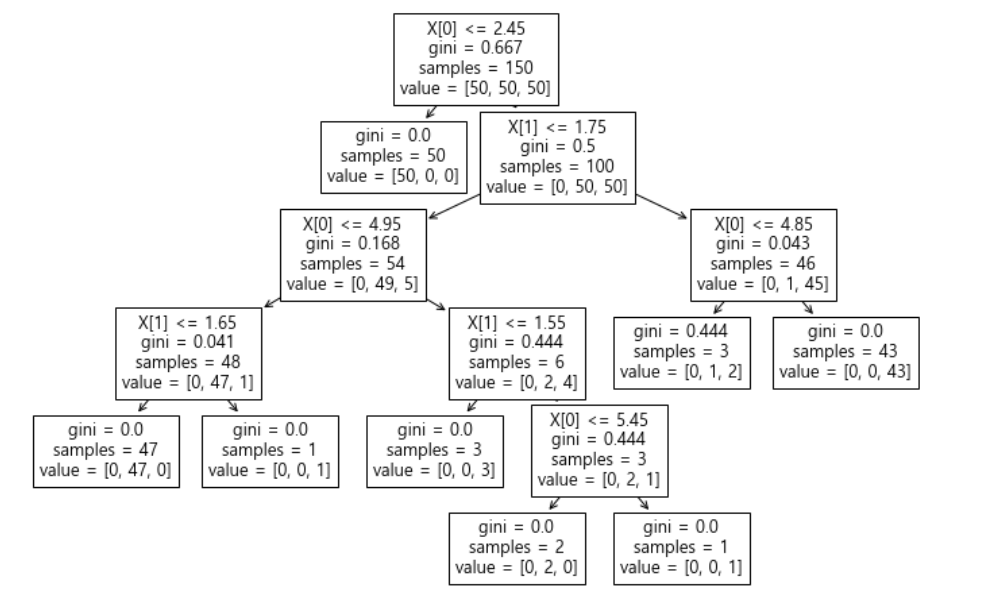
내가 만든 Decision Tree가 어떤 논리로 돌아가는지 궁금하면,
plot_tree로 시각화할 수 있다.
여기서 gini는 불순도율을 의미한다. 낮을수록 좋다!
첫 분류에서 40개의 setosa중 40개 모두 setosa로 분류했다.
두번째 분류에서 versicolor 50개 중에 5개를 virginica로 오분류했다.
두번째 분류에서 virginica 50개 중에 1개를 versicolor로 오분류했다.
이런 식으로 모델을 해석할수 있다.
from mlxtend.plotting import plot_decision_regions plt.figure(figsize=(14, 8)) plot_decision_regions(X=iris.data[:, 2:], y=iris.target, clf=iris_tree, legend=2) plt.show()
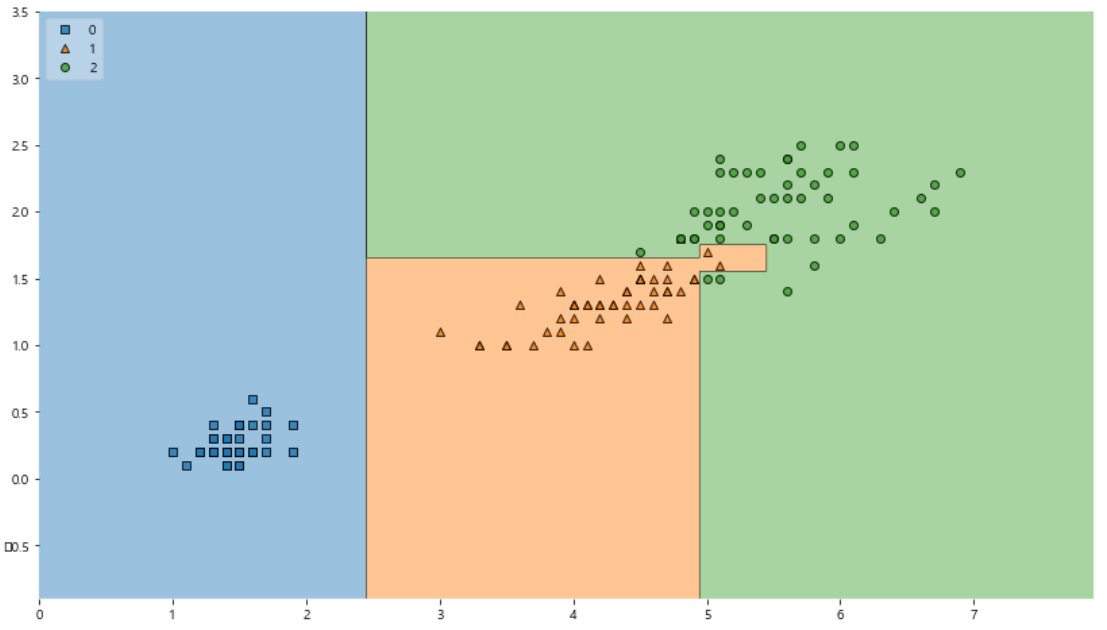
mlxtend를 이용해 결정나무 모델이 어떻게 데이터를 분류했는지 확인해보자.
만약 mlxtend가 없다면 !pip install mlxtend 로 설치하면 된다.
1과 2 를 구분하는 경계면이 너무 정확하다.
다시말해 너무 이 데이터에 적합한 형태라서 일반화 하기 어려움이 있다.
성능이 99% 여도 일반화 할 수 없는 모델은 좋지 않다...!!
5. 과적합(overfitting)
- 지도학습으로 인해 과적합 발생
- 내가 가진 데이터에 너무 맞게 학습해서 다른 데이터에서는 성능이 낮게 나오는 것
- 그래서 accuracy가 높아도 좋게만 생각할수는 없다
- 데이터를 전부 모델학습에 사용하지 않고, 훈련(training), 검증(validation), 테스트(testing)용으로 분리한다.
(1) iris 데이터를 train/test 로 분리
from sklearn.model_selection import train_test_split features = iris.data[:, 2:] labels = iris.target X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=13)
train_test_split() 을 사용해
8:2 확률로 특성(features)과 정답(labels)를 분리했다.
X_train.shape, X_test.shape
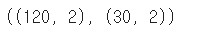
150개의 데이터가 8:2 비율로 분리된것을 확인할수 있다.
np.unique(y_test, return_counts=True)
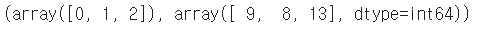
return_counts=True 는 각 값의 개수를 반환하는 옵션이다.
0, 1, 2 클래스가 각각 9, 8, 13개씩 있다.
동일 비율이 아니다...!
크게 문제가 되지는 않지만, 나는 비율을 맞춰줘야지!
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify=labels, random_state=13) np.unique(y_test, return_counts=True)
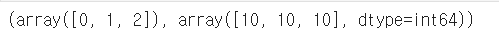
stratify=labels 옵션을 사용하면 각 클래스의 비율이 동일하게 나눠지도록 할수 있다.
test데이터에 각 클래스가 10개씩 들어있는것을 확인할수 있다.
(2) train 데이터를 사용해 Decision Tree 만들기
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13) iris_tree.fit(X_train, y_train)
max_depth 를 설정하면 성능이 나빠진다.
하지만 max_depth 를 설정하지 않으면, 모델이 나의 데이터에 근접하게 다가가는 문제가 발생한다.
plt.figure(figsize=(10,8)) plot_tree(iris_tree);
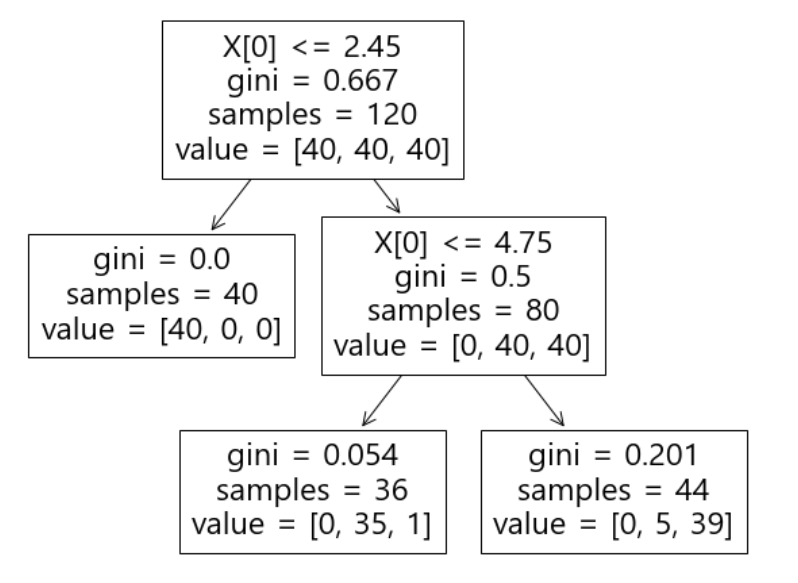
새로 만든 모델은 이런 구조를 갖는다.
첫 분류에서 40개의 setosa중 40개 모두 setosa로 분류했다.
두번째 분류에서 versicolor 40개 중에 1개를 virginica로 오분류했다.
두번째 분류에서 virginica 40개 중에 5개를 versicolor로 오분류했다.
y_pred_train = iris_tree.predict(X_train) accuracy_score(y_train, y_pred_train)
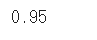
성능이 아까보다는 낮아졌지만, 여전히 꽤 좋은 성능을 가졌다!
plt.figure(figsize=(14, 8)) plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2) plt.show();
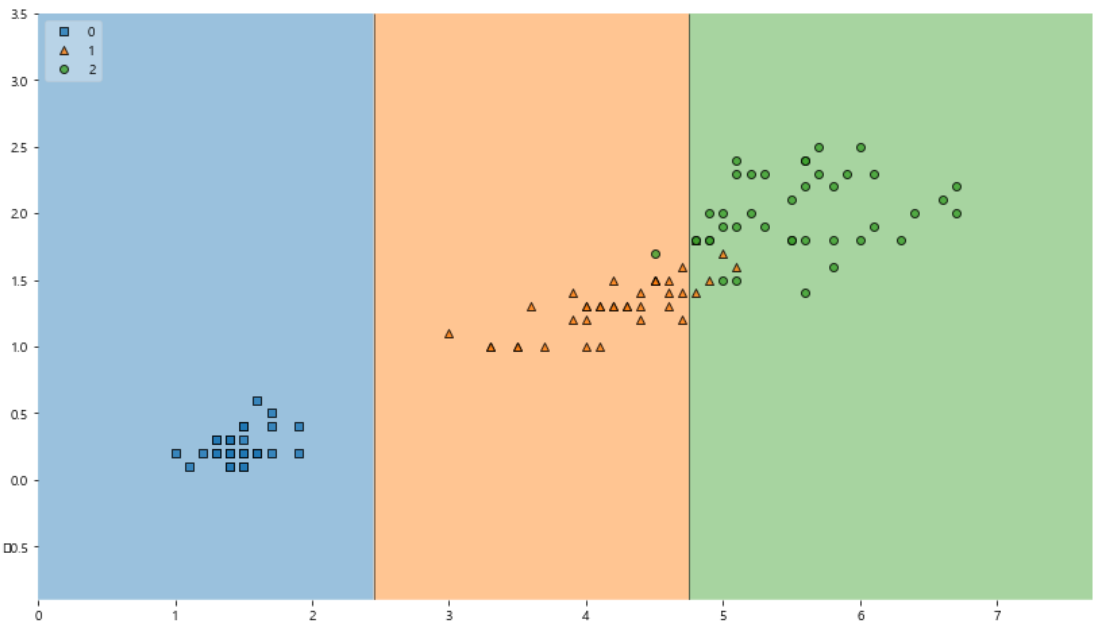
아까와 다르게 일반화할 수 있을것같다.
4개의 1번이 2번으로 예측되고,
1개의 2번이 1번으로 예측되었다.
y_pred_test = iris_tree.predict(X_test) accuracy_score(y_test, y_pred_test)
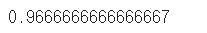
train 데이터로 만든 모델로 test데이터를 예측해보자.
정확성이 96%로, train 데이터에서보다 더 높게 나왔다.
이는 모델이 train 데이터에 과적합 되지 않았음을 의미한다!
plt.figure(figsize=(14, 8)) plot_decision_regions(X=X_test, y=y_test, clf=iris_tree, legend=2) plt.show();
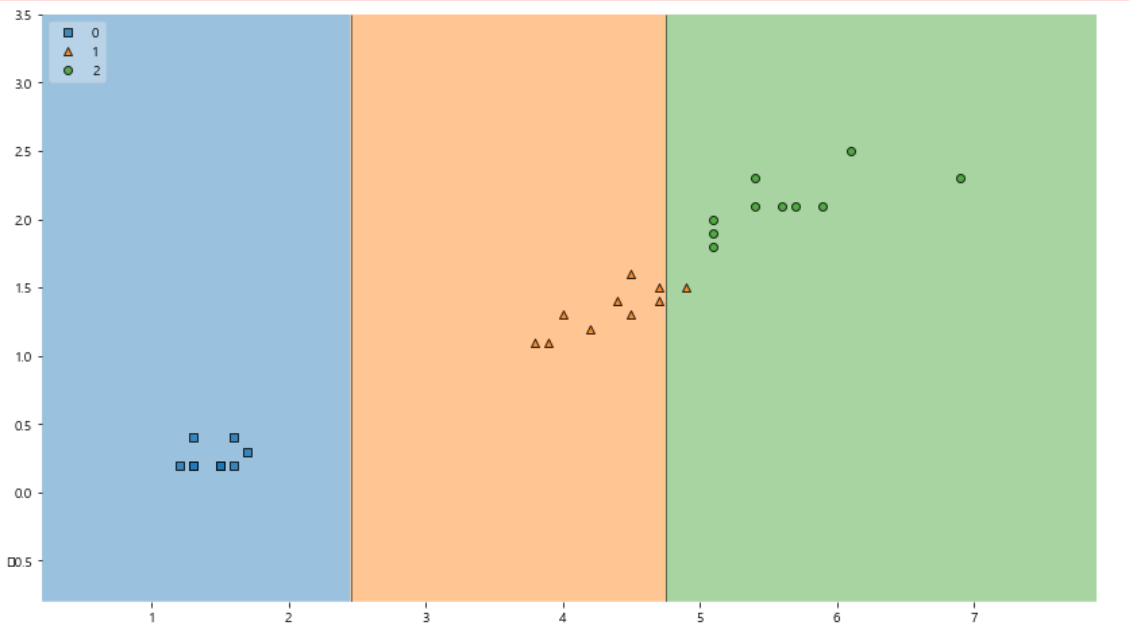
train 데이터때 처럼 모델을 시각화해봤다.
확실히 잘 만들어진것 같다.
scatter_highlight_kwargs= {'s':150, "label":"Test Data", "alpha":0.9} scatter_kwargs = {'s':120, "edgecolor":None, "alpha":0.9} plt.figure(figsize=(12, 8)) plot_decision_regions(X=features, y=labels, X_highlight=X_test, clf=iris_tree, legend=2, scatter_highlight_kwargs=scatter_highlight_kwargs, scatter_kwargs=scatter_kwargs, contour_kwargs={"alpha":0.2})
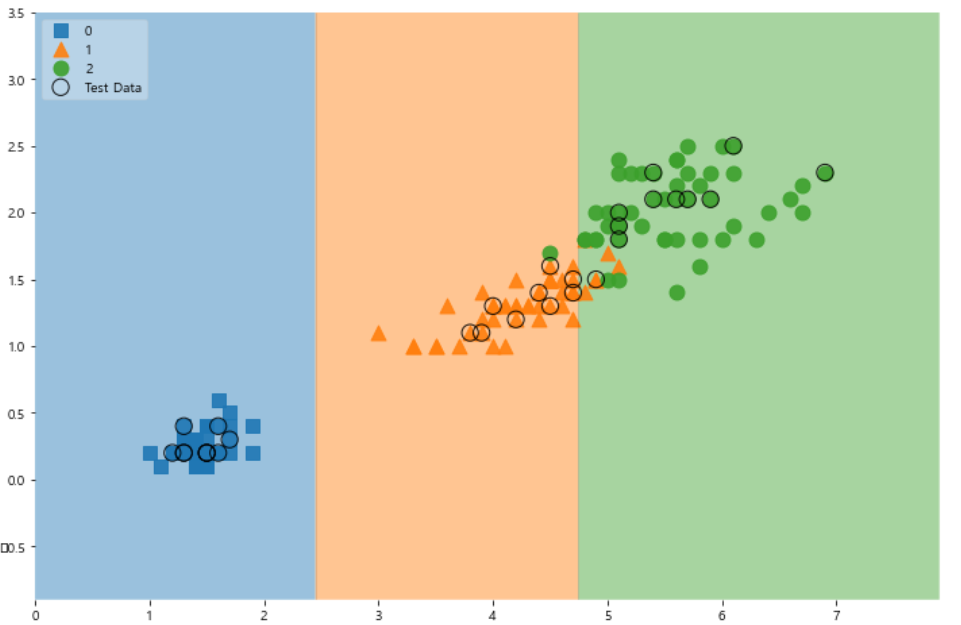
train, test데이터를 한번에 보고싶어서
test데이터를 나타내는 효과를 더해봤다.
동그라미 쳐진 애들이 test 데이터다.
6. 컬럼을 모두 사용해 모델 만들기
지금까지는 iris 데이터셋의 컬럼 중, 2개만 사용했다.
이번에는 4개의 컬럼을 모두 사용해서 모델을 만들어보자!
(1) 모델 만들기
features = iris.data labels = iris.target X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify=labels, random_state=13) iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13) iris_tree.fit(X_train, y_train)
위와 동일한 방법으로 Decision Tree 모델을 만들었다.
이번에서 max_depth=2 로 설정했다.
plt.figure(figsize=(10,8)) plot_tree(iris_tree);
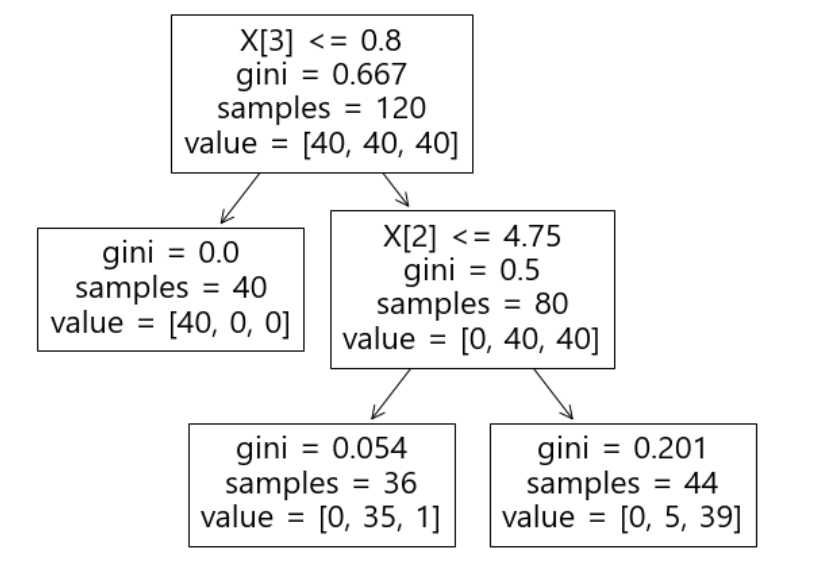
만들어진 모델은 이와 같다.
첫 분류에서 40개의 setosa중 40개 모두 setosa로 분류했다.
두번째 분류에서 versicolor 40개 중에 1개를 virginica로 오분류했다.
두번째 분류에서 virginica 40개 중에 5개를 versicolor로 오분류했다.
(2) 모델 사용하기
test_data = np.array([[4.3, 2., 1.2, 1.]]) #[[]] 두번 사용! iris_tree.predict(test_data)
임의의 값을 test_data로 할당하고, 이를 방금 만든 모델에 넣어봤다.
iris.target_names[iris_tree.predict(test_data)]
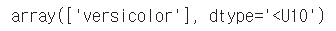
이 모델은 test_data를 versicolor 로 예측했다.
iris_tree.predict_proba(test_data)
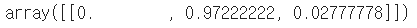
예측 결과를 알고싶은 경우에는 .predict()를 사용하고,
결과 예측 확률을 알고 싶은 경우에는 .predict_proba() 를 사용한다.
내가 만든 모델에 의하면, 97%의 확률로 test_data는 'versicolor' 이다.
7. 모델에서 주요 특성 확인하기
iris_tree.feature_importances_

.feature_importances_ 는각 feature가 어느정도 유의성을 갖는지 출력한다.
맨 뒤에 _ 는 꼭 붙여야 한다...!!
iris_clf_mo = dict(zip(iris.feature_names, iris_tree.feature_importances_)) iris_clf_mo

위 리스트의 의미는 이와 같다.
petal의 length와 width가 각각 42%, 58%의 중요성을 갖고, 다른 두 컬럼은 0% 이다.
max_depth가 달라지면, 이 결과값도 달라진다.
