ML맛보기
1.Decision Tree 모델로 iris 품종 구분하기

데이터 분석을 공부할때 수학의정석 처럼 기초단계에서 반드시 거치는 데이터셋이 있다.바로 iris 데이터다.iris데이터는 1930년대에 통계학자이자 유전학자였던 로널드 피셔가 정리한 데이터로, 붓꽃 중 Setosa, Versicolour, Virginica 3가지 품종
2.타이타닉 생존자 분석하기

타이타닉에 나왔던 레오나르도 디카프리오와 케이트윈슬렛은 생존확률이 얼마나 됐을지, ML을 통해 알아보자!<컬럼의 의미>pclass : 객실등급survived : 생존유무(0: 사망 / 1: 생존)sex : 성별age : 나이sibsp : 형제 혹은 부부의 수par
3.Decision Tree 를 이용해 와인의 종류 분류하기

와인 데이터는 분류 문제에서 많이 사용하는 Iris 꽃 데이터만큼 알려지진 않았지만, 많이 사용된다.두 데이터의 구조는 동일하다.<컬럼 설명>fixed acidity : 고정 산도volatile acidity : 휘발성 산도citric acid : 시트르산resi
4.와인 분류 모델을 Pipeline으로 구현하기

데이터는 앞에서 사용했던 와인데이터를 사용한다.두 와인 데이터 모두 불러온 뒤color 컬럼을 만들어 레드와인은 1, 화이트와인은 0 값울 주고, 하나로 합친다.앞서 했었던 와인 분류 모델은 아래와 같은 순서로 작동한다.여기서 test_train_split은 Pipel
5.K-fold Cross Validation(교차검증)

모델이 학습 데이터에만 과도하게 최적화되어 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상을 과적합 이라고 한다.과적합을 막기 위해 사용하는게 Cross Validation(교차검증) 이다.일반적인 모델 학습 방식은 데이터셋을 train/test 데이터로 분류한
6.Cross Validation을 사용한 Wine 분류모델

앞서 사용했던 wine 데이터를 사용해서 Cross Validation을 사용한 와인 분류 모델을 만들어보려 한다..!데이터이번에도 color 컬럼에 레드와인은 1, 화이트와인은 0 값을 주고, 두 데이터를 합쳤다.그리고 taste 값이 5보다 크면 1, 5이하면 0
7.하이퍼파마리터 튜닝
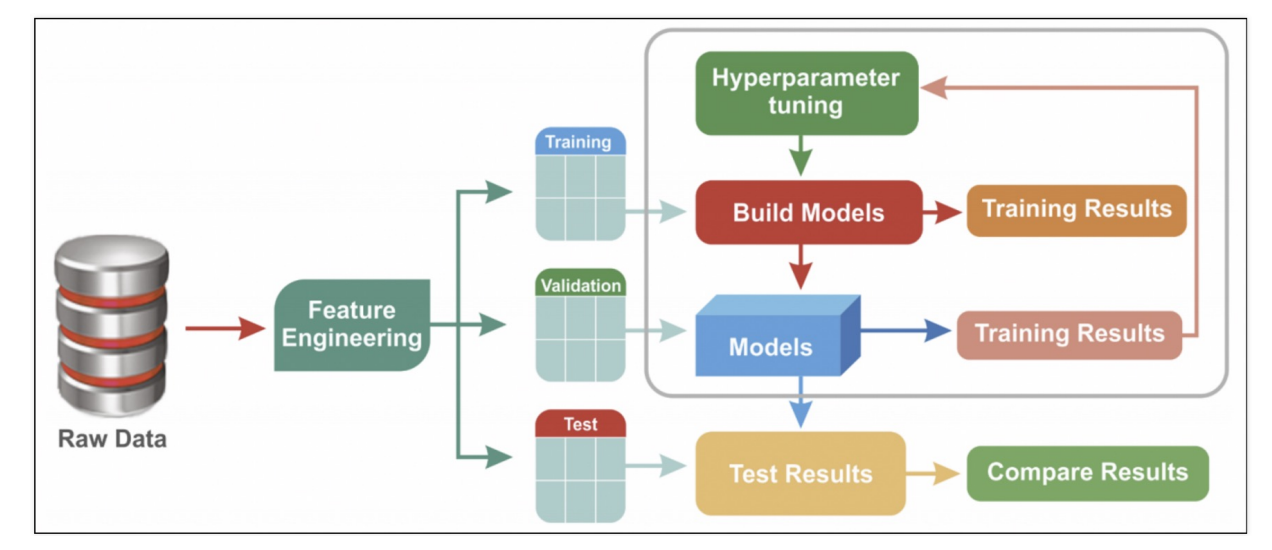
하이퍼파마리터 튜닝은 모델의 성능을 확보하기 위해 조절하는 설정 값 을 의미한다.예를 들면 Decision Tree에서는 max_depth 가 있다.물론 반복문을 사용할 수 있지만, 더 쉬운 방법이 있다!이번에도 와인 데이터를 분류하는 모델을 만들고, 다양한 max
8.분류모델 평가 지표
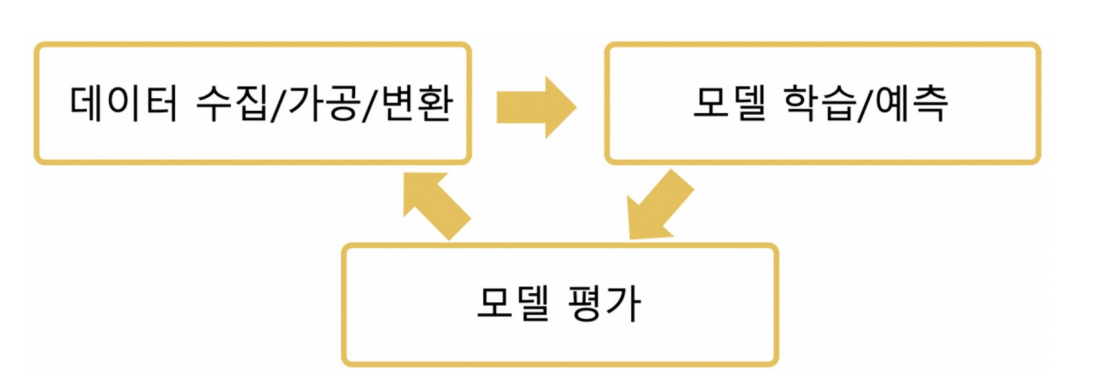
모델에는 여러 종류가 있는데,이번 글에서는 분류모델만 다뤄볼 예정이다.분류모델은 입력된 값이 어느쪽에 속할지 비율을 계산하고, 분류하는 모델이다.지금까지 했던 붓꽃 품종 예측 모델, 와인 분류 모델 등등이 분류모델에 속한다. 분류모델을 평가하는 항목에는 Accuracy