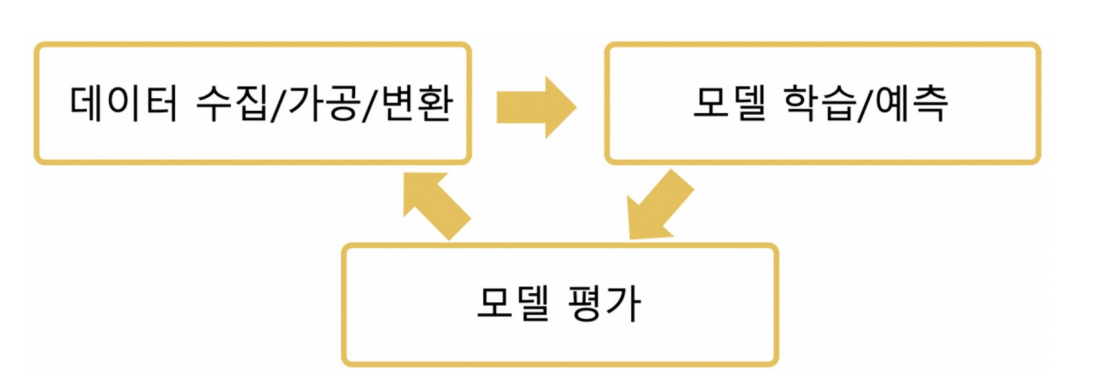
모델에는 여러 종류가 있는데,
이번 글에서는 분류모델만 다뤄볼 예정이다.
분류모델은 입력된 값이 어느쪽에 속할지 비율을 계산하고, 분류하는 모델이다.
지금까지 했던 붓꽃 품종 예측 모델, 와인 분류 모델 등등이 분류모델에 속한다.
분류모델을 평가하는 항목에는
Accuracy(정확도), Precision(정밀도), Recall(재현율), Fall-out,
F1-Score, ROC곡선, AUC, Confusion Matrix(오차행렬) 등이 있다.
(1) 이진분류 모델 평가
먼저 class가 2개인 이진분류 모델을 살펴보자.
예측을 하는 경우의 수는 참을 참/거짓 으로 , 거짓을 참/거짓으로 예측하는 4개가 있다.
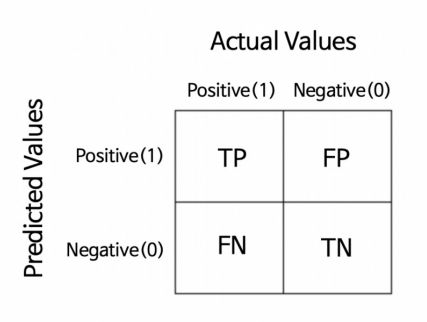
- TP(True Positive) : Positive를 Positive로 맞춤
- FN(False Negative) : Positive를 Negative로 틀리게 예측 (2종오류, 맞는데 아니라고 함)
- TN(True Negative) : Negative를 Negative로 맞춤
- FP(False Positive) : Negative를 Positive로 틀리게 예측 (1종오류, 아닌데 맞다고 함)
(2) Accuracy
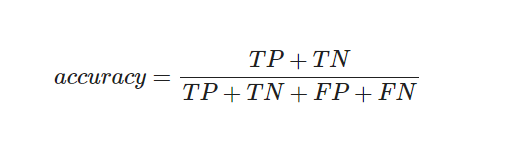
- accuracy(정확도)는 전체 데이터 중 맞게 예측한 것의 비율을 의미한다.
(3) Precision(정밀도)
- True로 예측한것 중 진짜 True인 것의 비율
- Threshold 값을 높게 잡을수록 precision 값도 높게 나온다.
(True 선정 기준을 높게 잡은 것) -> Threshold 를 0.8 또는 0.9 로 설정 - 스팸메일을 분류하는 모델같이, False를 True로 분류하면 안되는 모델인 경우에 중요.
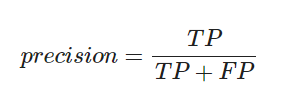
(4) RECALL (TPR, TRUE POSITIVE RATIO)
- 전체 True중 True로 제대로 예측한 비율
- Threshold 값을 낮게 잡을수록, recall값은 올라간다.
(다 True로 예측해버리니까) -> Threshold 를 0.3 혹은 0.4 로 설정 - 암 환자를 찾는 모델처럼, True 데이터를 False로 판단하면 안되는 경우에 중요.
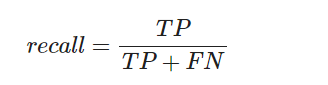
(5) FALL-OUT (FPR, FALSE POSITION RATIO)
- False 중 True로 잘못 예측한 비율
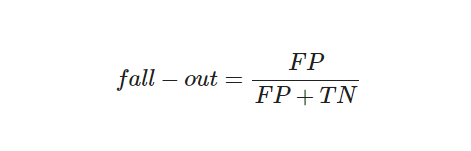
(6) F1-Score(조화평균)
recall과 precision을 결합한 지표
recall과 precision이 한쪽으로 치우치지 않고 둘다 높은값을 가질수록, 높은 값을 갖는다.
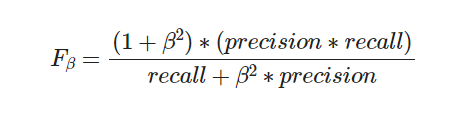
F-score에서 beta를 1로 두면
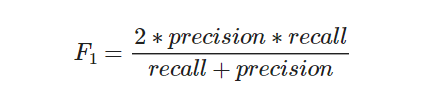
F1-score다.
(7) ROC 곡선/AUC
ROC
- FPR(fall_out)이 변할 때, TPR(recall)의 변화를 그린 그림
- FPR을 x축, TPR을 y축으로 그린다.
- 직선에 가까울수록 머신러닝 모델의 성능이 떨어지는 것으로 판단한다.
- 직선 위에 있어야 좋은 모델이고, 직선 아래에 있으면 나쁜 모델, 직선이면 random하게 때려맞추는 모델이다.
AUC
- ROC곡선 아래의 면적
- 1에 가까울수록 좋은 수치
- 기울기가 1인 직선 아래의 면적이 0.5 -> AUC는 0.5보다 커야함!
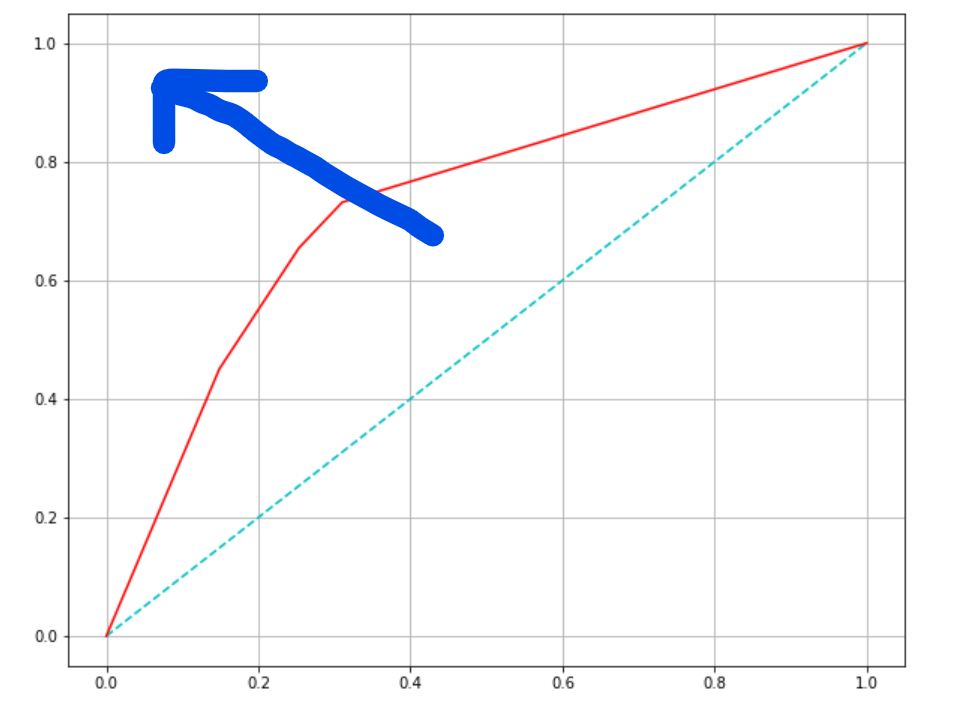
초록색 선이 기준이 되는 직선이다.
빨간색 선인 ROC 곡선이 직선에서 멀어져 파란 화살표 방향으로 갈수록, 모델의 성능이 좋은 것이다.
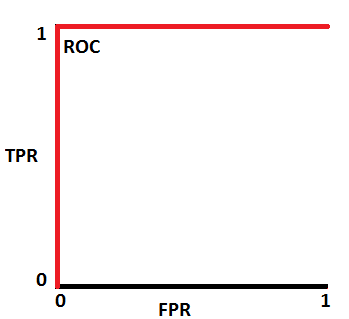
이게 가장 이상적인 ROC 곡선이다.
물론 거의 존재하진 않는다..!
ROC 곡선 아래 면적이 AUC 이다.
ROC 곡선이 멀어질 수록 좋은 것이니까, AUC값은 1에 가까워질수록 좋은 것이다.

데이터 분석으로 세상을 읽어보쟈 빠샤