1. 동시성과 병렬성
여러 사용자가 동시에 Database를 원활하게 사용하기 위해선, Database에서 Concurrent Sharing 기능을 제공해주어야 한다. 여러 명의 사용자를 동시에 처리하기 위해 아래의 두 가지 방법을 고려해 볼 수 있다.
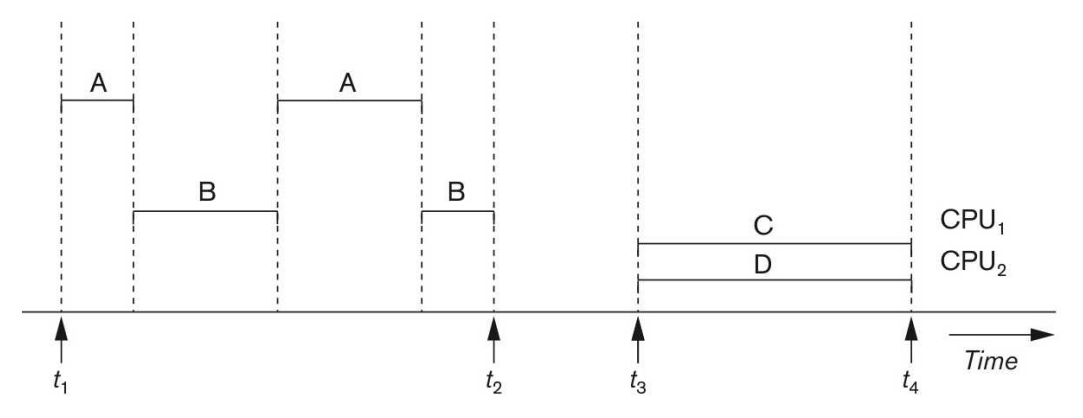
① Interleaved Processing(동시성)
- 하나의 CPU로 여러 개의 프로세스를 번갈아 실행하면서, 마치 병렬적으로 처리되고 있는 것처럼 보이게 한다.
- 이를 멀티 프로그래밍이라고 한다.
② Parallel Processing(병렬성)
- 여러 개의 CPU로 동시에 여러 작업을 처리한다.
- 이를 멀티프로세싱이라 한다.
아래의 그림에서 A와 B가 처리되는 방식은 Interleaved Processing에, C와 D가 처리되는 방식은 Parallel Processing에 해당한다.
2. Concurrency Control의 필요성
병렬적인 처리는 실행시간을 획기적으로 단축시키지만, 여러가지 문제를 발생시키기도 한다. 동시성을 제어하지 않았을 때 생길 수 있는 문제점은 아래와 같다.
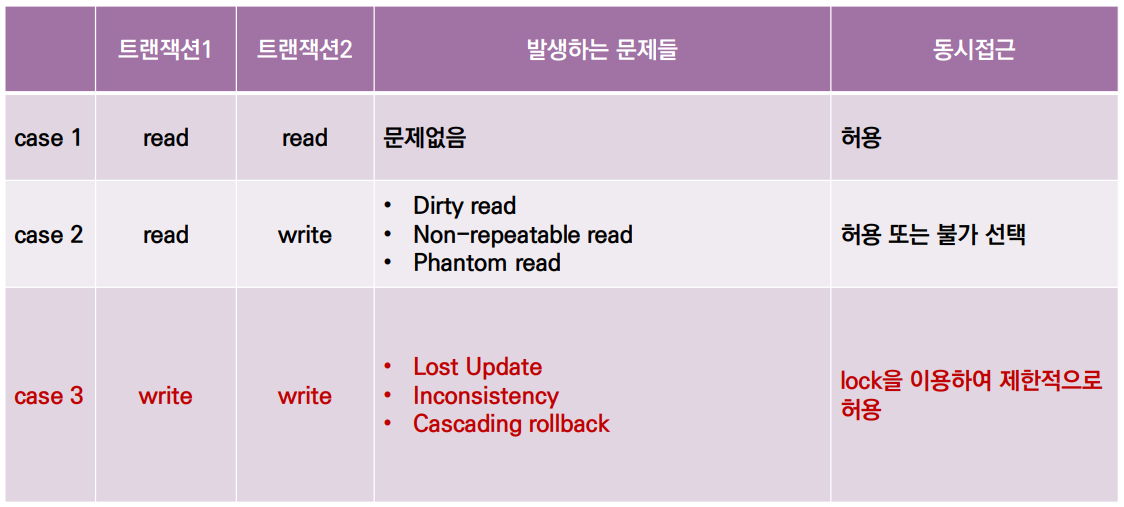
1) Read와 Write를 동시에 수행할 때 발생하는 문제점
① Dirty Read
- 다른 트랜잭션에 의해 수정됐지만, 아직 Commit이 되지 않아 이전 데이터를 읽게 되는 문제를 말한다.
- 다른 말로 Uncommited Read라고도 한다.
- 아래의 그림에서 A=5, B=3이라고 하면, Trans 1에서 A가 10으로 바뀌어도, Trans 2에서는 A를 5로 읽기 때문에(지연 갱신 가정) sum의 결과가 8이 된다.

② Non-Repeatable Read
- 동일한 데이터를 두 번 읽는데, 그 사이에 값이 변경되거나 삭제되어 결과가 다르게 나타나는 문제를 말한다.
- 아래의 그림에서 Trans 2는 별다른 연산 없이 그저 A를 두 번 읽었을 뿐인데, 도중에 A가 갱신됨(즉시 갱신 가정)에 따라 두 read의 결과가 서로 다르게 나타난다.
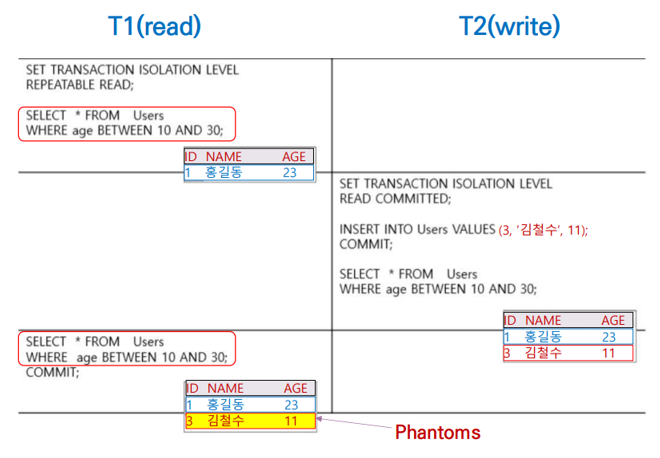
③ Phantom Read
- 한 트랜잭션 내에서 동일한 쿼리를 두 번 수행하는데, 첫 번째 쿼리에서 없던 Phantom(유령) 튜플이 두 번째 쿼리에서 나타나는 문제를 말한다.
- 아래의 그림에서 Trans 1은 그저 동일한 쿼리를 두 번 수행했을 뿐인데, 도중에 새로운 튜플이 삽입됨(즉시 갱신 가정)에 따라 두 쿼리의 결과가 서로 다르게 나타난다.
Write가 수행되는 도중에 Read를 허용할 것인지에 대한 여부는 DBA의 design choice에 맡긴다. 만약 Read를 허용할 경우 이전의 Snapshot에 대해 Read 하는 것이 허용되는데, 이를 Shared Lock이라 한다. 반대로 Read를 불허하는 경우는 Exclusive Lock이라 하며, Read 작업이 원천적으로 금지된다.
2) Write와 Write를 동시에 수행할 때 발생하는 문제점
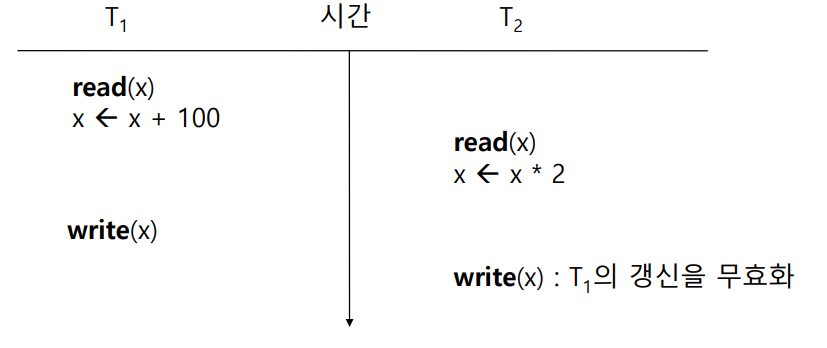
① Lost Update
- 한 Transaction의 갱신 연산이 무효화되는 문제이다.
- Lost Update의 발생 여부를 인지하는 것은 매우 어렵거나 불가능하다.
- 아래의 그림에서 x=10이라 하면 Trans 1에서 x를 110으로 갱신하였으나, Trans 2에 의해 x가 20으로 overwrite 되면서 Trans 1의 갱신 연산이 무효화된다.
- 이와 같은 문제를 해결하려면 Trans 1에서 write 하기 전에 lock을 걸고, write가 끝났을 때 lock을 해제했어야 한다.
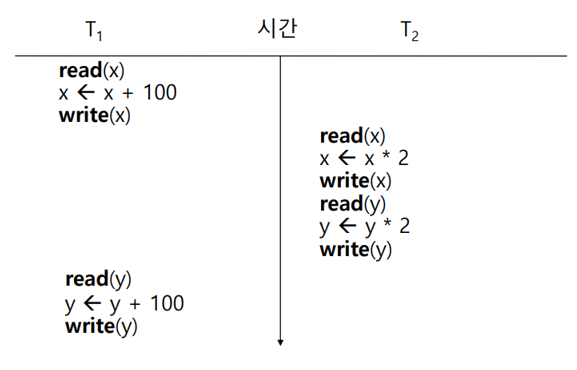
② Inconsistency
- 한 트랜잭션 내에서 두 개의 데이터를 읽을 때, 하나는 갱신되기 전의 값을 읽고 다른 하나는 갱신된 후의 값을 읽게 되어 데이터의 일관성이 유지되지 않는 문제이다.
- 아래의 그림에서 Trans 1은 x와 y를 모두 읽어야 하는데, x는 갱신 이전의 값으로 읽고 y는 갱신 이후의 값으로 읽게 되면서, 데이터베이스의 일관성이 상실된다.
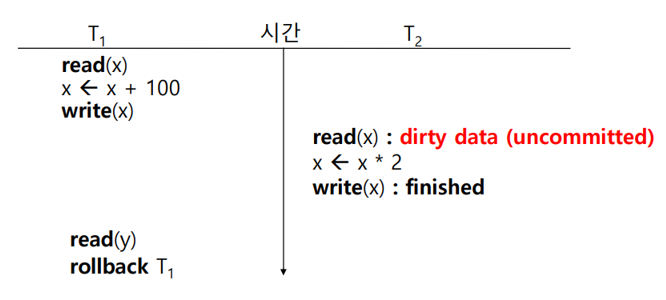
③ Cascading Rollback
- 데이터베이스에서 트랜잭션 롤백이 다른 트랜잭션에 영향을 미치는 문제이다.
- Cascading Rollback의 의미는 A라는 트랜잭션이 데이터를 수정하고, B라는 트랜잭션이 A에 의존하여 실행된 경우, A 트랜잭션을 롤백할 때 B 트랜잭션도 함께 롤백되어야 한다는 것이다.
- Cascading Rollback이 문제가 되는 상황은 다음과 같다. 아래의 그림에서 Trans 2는 정상적으로 실행되어 Commit을 완료했고, Trans 1은 모종의 이유로 실패하였다. Trans 1을 Rollback 하려고 해도 Trans 2에서 이미 x가 Commit 되었기 때문에 Rollback을 수행할 수 없게 된다(Rollback은 Commit 이전에만 가능하기 때문이다).
위와 같은 문제를 해결하기 위해 Concurrency Control이 필요한 것이다.
3. 직렬화 가능성
1) Transaction Schedule
데이터베이스에서 여러 트랜잭션이 동시에 수행될 때, 수행되는 트랜잭션의 순서에 따라 결과가 달라질 수 있다. 이 때, 트랜잭션을 처리하는 순서를 Transaction Schedule이라 한다. Transaction Schedule은 아래의 세 종류로 구분될 수 있다.

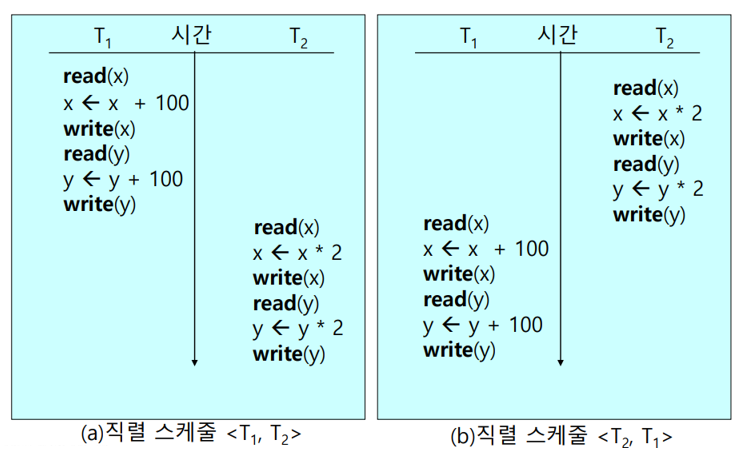
① Serial(직렬) Scedule
- Interleaved 방식을 이용하지 않고 트랜잭션 별로 연산을 순차적으로 실행한다.
- 트랜잭션의 집합 {a, b, c}에서 가능한 스케줄은 a→b→c, a→c→b, b→a→c, b→c→a, c→a→b, c→b→a로 총 6가지이며, 항상 n! 가지의 스케줄링 방법이 존재한다.
- 위 그림의 {Trans 1, Trans 2}를 Serial Scedule로 나타내면 아래와 같다. (어떤 순서로 실행하느냐에 따라 결과가 달라진다.)
② Non-Serial(비직렬) Schedule
- 트랜잭션 {a, b, c}를 Interleaved 방식을 이용하여 실행한다.
- 위 그림의 {Trans 1, Trans 2}를 Non-Serial Scedule로 나타내면 아래와 같다.

③ Serializable(직렬화 가능) Schedule
- 직렬 스케줄과 동일한 결과를 생성하는 비직렬 스케줄을 의미한다.
- Serializable Schedule은 Serial Scedule이 아니라 Non-Serial Schedule이다.
당연히 Serial Schedule이 격리성이 가장 높기 때문에 항상 정확한 결과를 만들어낸다. 그러나 처리 속도가 매우 느리고 비효율적이라는 점에서 문제가 있다(격리성과 처리속도 사이의 Trade-Off). 만약 Non-Serial Schedule이 직렬 스케줄과 같은 결과를 낼 수 있으면, 이는 Serializable 한 스케줄이라고 말한다. 즉, Serializable Schedule은 Serial Schedule과 Non-Serial Schedule의 장점을 합친(빠른 처리 속도와 정확한 결과를 보장하는) Schedule인 셈이다.
2) Serializable Check
직렬화 가능성을 검사하기 위한 방법으로 Graph를 이용할 수 있다. 각 트랜잭션은 그래프의 노드로 표현하고, 아래와 같은 경우에 대해서는 T1→T2의 간선으로 표현한다.
- T1이 write(x)를 수행한 후 T2가 read(x)를 수행하는 경우
- T1이 read(x)를 수행한 후 T2가 write(x)를 수행하는 경우
- T1이 write(x)를 수행한 후 T2가 write(x)를 수행하는 경우
T1이 read(x)를 수행한 후 T2가 read(x)를 수행하는 경우는 무순서성이 보장되므로, 간선으로 표현하지 않는다. 이렇게해서 완성된 그래프에 사이클이 없고, 모든 트랜잭션 간의 간선이 일관된 방향을 가질 경우, 해당 스케줄은 Serializable 하다고 판단할 수 있다.
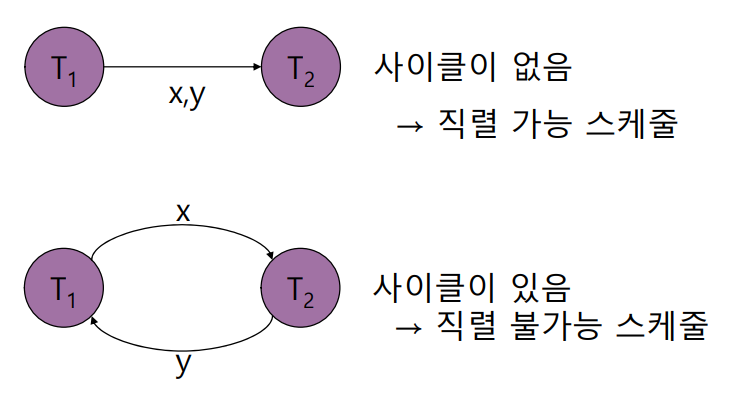
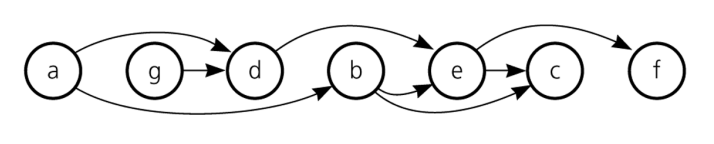
이 때, 모든 트랜잭션이 꼭 일렬로 정렬될 필요는 없으며, 위상 정렬만 가능하다면 해당 스케줄은 Serializable 하다. 즉, 아래와 같은 그래프도 직렬화가 가능하다.
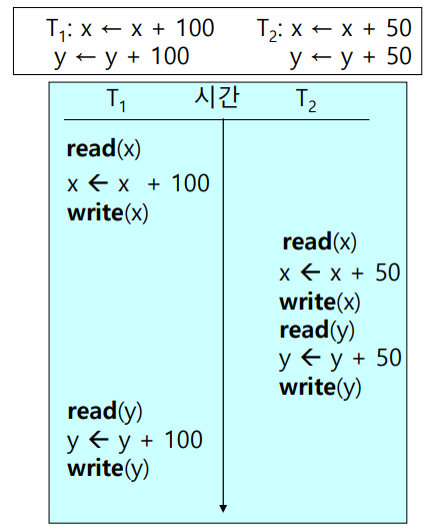
아래의 예시에서 직렬화 가능성을 검사해보자.
위 트랜잭션을 그래프로 나타내면 아래와 같다.
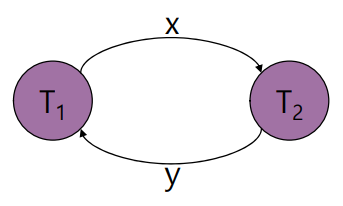
Interleaved 방식으로 실행한 결과가 직렬 스케줄(T1 → T2)의 결과와 동일하긴 하지만, 그래프에 사이클이 발생하기 때문에 직렬 불가능한 스케줄이다. 참고로, 실행 결과가 직렬 스케줄과 동일한 것은 두 트랜잭션 모두 덧셈만 수행하기 때문에 우연히 같았을 뿐이다. 정리하면, 아래의 두 경우에 대해서는 주어진 스케줄이 Serializable 하지 않다고 말할 수 있다.
- 주어진 스케줄(Interleaved 방식)의 실행 결과가 직렬 스케줄의 결과와 다른 경우
- 주어진 스케줄이 직렬 스케줄과 결과는 같지만, 그래프에 사이클이 존재하는 경우
4. Locking Protocol
그러나 모든 스케줄의 직렬 가능성을 일일이 검사하는 것은 어려운 일이다. 그러므로, 직렬 가능성을 검사하는 방식 대신, 직렬 가능성을 보장하는 방식을 사용하는데, 이 때 사용되는 규약이 바로 Locking Protocol이다.
1) 내용
① 트랜잭션에서 read(x) 또는 write(x)를 수행하려면 반드시 먼저 lock(x)를 수행해야 한다.
② 트랜잭션에서 수행한 lock(x)에 대한 unlock(x)는 반드시 트랜잭션이 종료되기 전에 수행되어야 한다.
③ 트랜잭션은 다른 트랜잭션이 걸어놓은 lock(x)에 대해 재차 lock(x)를 수행할 수 없다.
④ lock(x)를 수행한 트랜잭션 외의 다른 트랜잭션에서는 unlock(x)를 수행할 수 없다.
2) 문제점
그러나, Lock을 수행한다고 해서 스케줄의 직렬화 가능성을 정확히 판단할 수 있는 것은 아니다. 아래의 예시를 보자.
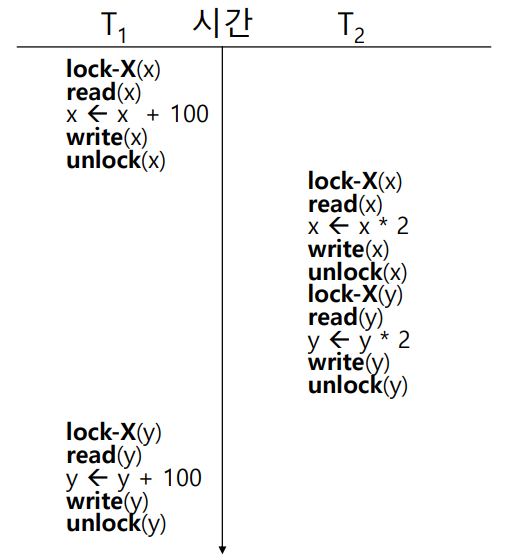
x=100, y=200이라 할 때, 위 스케줄의 실행 결과는 x=300, y=500이지만, 직렬화 스케줄 <T1, T2>의 실행 결과는 x=400, y=600이므로, 이 스케줄은 Serializable 하지 않을 것으로 판단된다. 그러나 사실 이 스케줄은 아래에서 이야기할 2PLP를 적용하여 직렬화 가능하다. 즉, 단순히 위의 Locking Protocol을 적용하는 것만으로는 직렬 가능성을 완전히 보장할 수 없다.
5. 2PLP(Two Phase Locking Protocol)
1) 개념
위와 같은 문제가 발생하는 근본적인 원인은 하나의 트랜잭션 내에 lock과 unlock을 수행하는 단계가 엄격히 구분되지 않기 때문이다. 쉽게 말해서 x에 대한 연산과 y에 대한 연산을 수행할 때, lock(x) → unlock(x) → lock(y) → unlock(y)의 순서로 실행하는 것이 아닌, lock(x) → lock(y) → unlock(x) → unlock(y)의 순서로 실행해야 한다는 것이다.
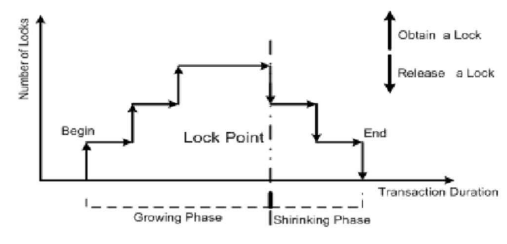
이처럼 lock만 수행하는 단계와 unlock만 수행하는 2개의 단계로 구분하는 방식을 2PL(Two Phase Locking)이라고 부른다. 2PL의 두 단계를 조금 더 자세히 설명하면 아래와 같다.
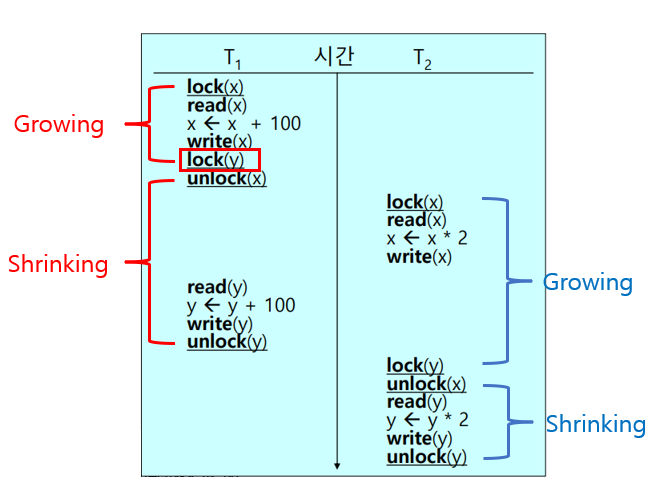
① Growing Phase(확장 단계)
- Transaction이 lock만 수행할 수 있고, unlock은 수행할 수 없는 단계
- Lock을 획득하는 단계
② Shrinking Phase(축소 단계)
- Transaction이 unlock만 수행할 수 있고, lock은 수행할 수 없는 단계
- Lock을 해제하는 단계
Locking Protocol의 문제점 부분에서 다룬 문제에 2PLP를 적용하여, 직렬화 가능성을 검사해보자. 아래는 그 문제이다.
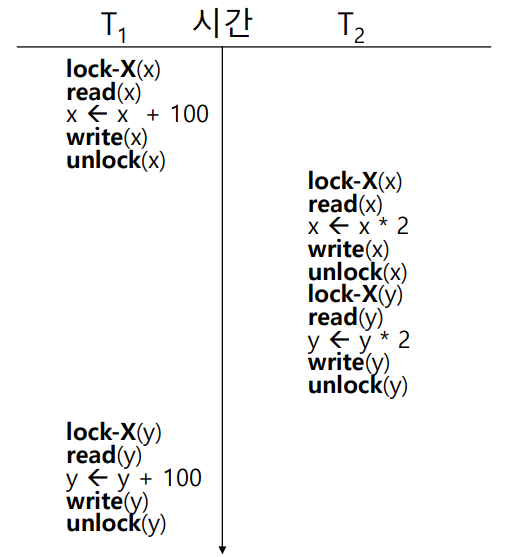
위 스케줄에 2PLP를 적용한 것이 아래의 스케줄이다. Trans 1은 x+100, y+100, Trans 2는 x*2, y*2를 수행한다고 할 때, 2PLP를 적용한 스케줄에선 어떤 점이 달라졌는지 찾아보자.
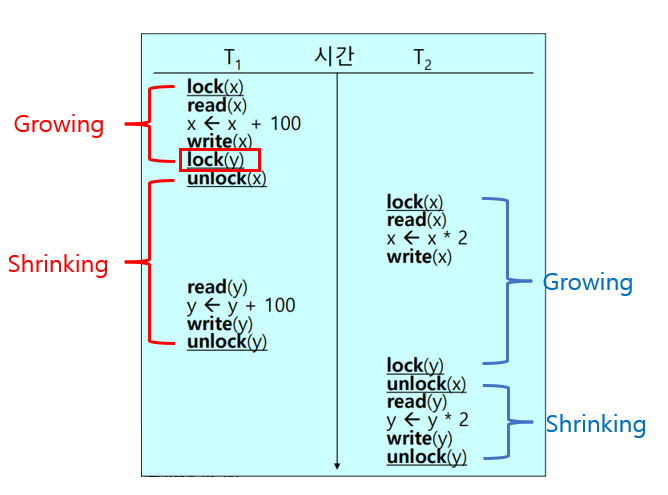
① Trans 1
- Growing: unlock(x)를 하기 전에 lock(y)를 먼저 수행한다.
- Shrinking: unlock(x)를 수행하여 Trans 2가 x를 사용할 수 있게 한다. y에 대한 연산을 수행하고 마지막에 unlock(y)를 수행한다.
② Trans 2
- Growing: x에 대한 연산을 마쳤지만, unlock(x)보다 lock(y)를 먼저 수행해야 하기 때문에 Trans 1에서 y에 대한 연산이 마쳐지기를 기다린다.
- Shrinking: unlock(x)를 수행하고 y에 대한 연산을 진행한다. 연산이 마쳐지면, unlock(y)를 수행한다.
위 스케줄이 정말 Serializable 한지 확인해보자. x=100, y=200이라 하고, 스케줄의 결과를 계산해보면, x=400, y=600이 된다. 직렬화 스케줄 <T1, T2>의 실행 결과도 마찬가지로 400, 600이므로, Interleaved 방식으로 처리하였음에도 Serial Schedule과 동일한 결과를 도출해낸다. 따라서 위 스케줄은 Serializable 하다.
2) 주의사항
스케줄 내의 모든 Transaction이 2PLP를 준수한다면, 해당 스케줄은 Serializable 하다. 이 명제에 대해 두 가지 주의해야 할 점이 있다.
- 명제의 역은 성립하지 않는다. 즉, 스케줄이 Serializable 하다고 해서 반드시 2PLP를 준수하는 것은 아니다.
- 스케줄에 속한 트랜잭션 중 어느 하나라도 2PLP를 만족하지 않으면, 직렬화 가능성을 보장할 수 없다.
먼저, 첫번째 주의 사항에 대해 생각해보자. 2PLP는 직렬화 가능성에 대한 충분조건일 뿐, 필요조건은 아니기 때문에 2PLP를 만족하지 않더라도 Serializable 한 스케줄이 존재할 수 있다. 아래의 예시를 보자.
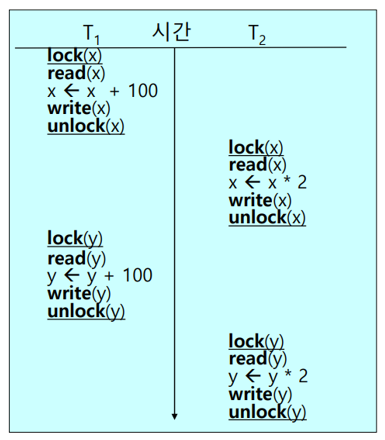
Trans 1과 Trans2 모두 2PLP를 만족하지 않지만, <T1, T2>의 실행결과와 동일한 결과를 도출한다. 따라서, 2PLP를 만족하지 않더라도 Serializable 한 경우가 존재할 수 있다.
그럼에도 2PLP는 거의 모든 스케줄의 직렬화 가능성을 보장할 수 있다. 스케줄이 2PLP를 만족하지 않으면서, Serializable 한 경우는 많지도 않을 뿐더러, 명백하게 Seriazable 이라는 것이 드러나는 경우가 많기 때문에(덧셈, 뺄셈만 수행하는 등) 2PLP는 Serializable Check에 충분히 유용하다.
조금 복잡한 이야기일 수는 있지만, Serializable 한 모든 스케줄은 2PLP를 적용한 스케줄로 변환할 수 있다. 따라서, 2PLP를 만족하지 않지만 Serializable 한 스케줄에 대해 2PLP를 적용한 스케줄로 변경하라는 문제가 출제될 수 있다. 위 문제의 스케줄을 2PLP를 적용한 스케줄로 변환하면 아래와 같다. (2PLP의 개념 부분에서 다루었던 이미지이다.)
다음으로 두번째 주의사항에 대한 예시를 살펴보자.
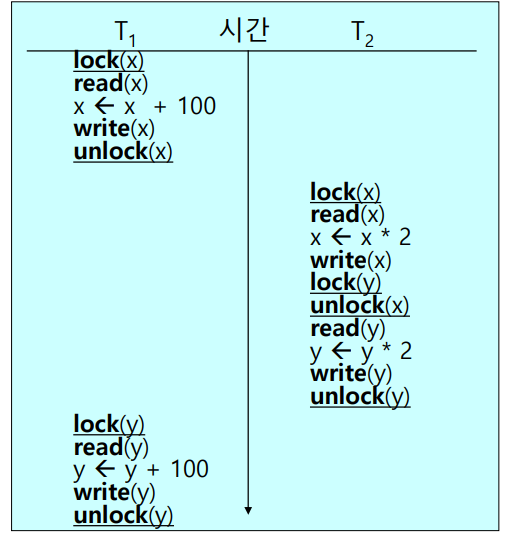
위 예시에서 Trans 2는 2PLP를 만족하지만, Trans 1은 2PLP를 만족하지 않으므로, 직렬화 가능성을 보장할 수 없다. 실제로 x=100, y=200을 넣어 계산한 결과는 직렬화 스케줄 <T1, T2>와 다른 결과를 보이므로, 위 스케줄은 Serializable 하지 않다.
5. Isolation Level
1) 정의
Isolation Level(트랜잭션 격리 수준)은 동시에 여러 트랜잭션이 동일한 데이터에 접근할 때, 다른 트랜잭션에서 변경하거나 조회하고 있는 데이터를, 읽을 수 있도록 허용할지 결정하는 것을 의미한다.
2) 종류
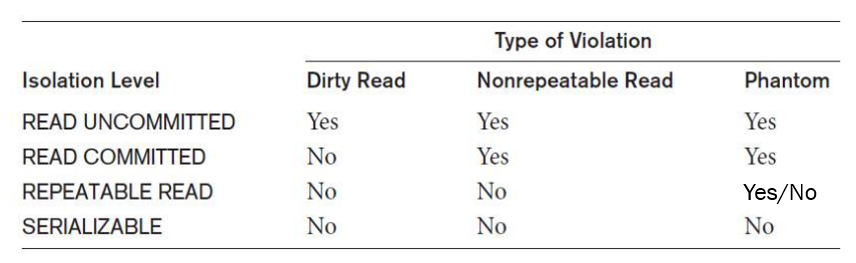
아래로 갈수록 높은 수준의 격리 수준을 제공한다. 아래는 MySQL 기준의 Isolation Level을 나타낸 것이다.
① READ UNCOMMITTED
- 다른 트랜잭션에서 Commit 되지 않은 데이터를 읽는 것을 허용한다.
- Dirty Read, Non-Repeatable Read, Phantom Read가 모두 발생한다.
- 정합에 문제가 자주 발생하기 때문에 거의 사용되지 않으며, 사용하지 않을 것을 권장한다.
② READ COMMITTED
- Commit 된 데이터만 읽을 수 있는 상태로 다른 트랜잭션에서 Commit 한 데이터를 읽는 것이 허용된다.
- Dirty Read는 발생하지 않지만, Non-Repeatable Read와 Phantom Read는 여전히 발생한다.
③ REPEATABLE READ
- 현재 데이터 버전의 Snapshot을 생성하고, 그 Snapshot을 이용해 데이터를 읽을 수 있다.
- 트랜잭션이 처음 시작했을 때의 데이터가 동일하게 유지되므로 일관성이 보장된다.
- Dirty Read, Non-Repeatable Read는 발생하지 않고, MySQL에 한해서 Phantom Read도 발생하지 않는다. (다른 DBMS에서는 Phantom Read가 발생할 수 있다.)
④ SERIALIZABLE
- 트랜잭션이 완료되기까지 Select 쿼리에 필요한 모든 데이터에 Shared Lock이 걸린다.
- 트랜잭션이 처음 시작했을 때의 데이터를 동일하게 유지하기 위해 Snapshot을 사용하는 것이 아닌, 다른 트랜잭션에서 해당 데이터를 아예 변경할 수 없게 만드는 방식을 사용한다.
- 동시 처리 성능이 매우 낮기 때문에, 특별한 경우가 아니라면 사용하지 않을 것을 권장한다.
3) MySQL에서 Isolation Level 조회 및 변경하기
① 조회
- MySQL에서는 REPEATABLE READ를 기본 값으로 사용한다.
SELECT @@GLOBAL.transaction_isolation; // 전역 설정
SELECT @@SESSION.transaction_isolation; // 현재 세션에 대한 설정② 변경
- 시스템 요구 사항에 맞는 Isolation Level을 선택해야 한다.
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;