
Colab에서 Pytorch라는 딥러닝/머신러닝용 라이브러리를 사용할 것입니다.
- Colab이란 무엇인가?
- 머신러닝을 위한 무료 소프트웨어
- 주피터 노트북 지원
- 딥러닝 프레임워크 지원 ( Tensorflow, Pytorch, etc )
- CPU/GPU 의 지원
▶ Theoretical Overview
Linear Regression이란 것은 2시간 공부했을 때 20점, 9시간을 공부했을 때 90점을 맞는 시험이 있을 때, 7시간을 공부했을 때 몇 점을 맞을 수 있는지 예측할때 필요한 것이 Linear Regression(선형회귀)라는 것이었습니다.
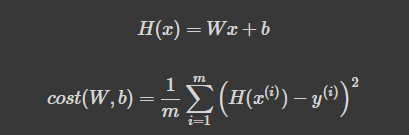
- H(x): 주어진 x 값에 대해 예측을 어떻게 할 것인가
- cost(W,b): H(x) 가 y 를 얼마나 잘 예측했는가
▶ Imports
import torch
import torch.optim as optimtorch라는 Library를 사용하기 위해 import시켜 주고,
torch.optim 라는 다양한 최적화 알고리즘을 구현해논 패키지를 import해주었습니다.
# For reproducibility
torch.manual_seed(1)이렇게 seed를 고정하게 되면 랜덤함수를 호출 할 때 매번 동일한 값이 호출하게 됩니다.
즉, 랜덤수를 생성하기 위한 Seed를 셋팅해주는 것입니다. 이제, 선형회귀에 필요한 데이터를 만들어보겠습니다.
▶ Data
# (x1,y1)=(1,1), (x2,y2)=(2,2), (x3,y3)=(3,3)
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])x_train , y_train이라는 변수에 값을 할당받아서 각각 프린트 해보겠습니다.
print(x_train)
print(x_train.shape)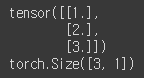
print(y_train)
print(y_train.shape)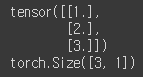
각각 프린트 하면 할당된 Tensor들이 출력이 되며, shape 함수를 통해 3 by 1 행렬이라는 것을 알 수 있습니다.
▶ Weight Initialization
W = torch.zeros(1, requires_grad=True)
print(W)
w는 size가 1이며 영행렬로 셋팅을 해주고, requires_grad가 True가 되면, 이 변수는 학습을 통해서 w 값을 찾겠다는 의미가 됩니다.
b = torch.zeros(1, requires_grad=True)
print(b)
b도 마찬가지로 영행렬로 초기화하며 동시에 학습을 하는 변수로 선언을 해주고 출력을 하였습니다.
▶ Hypothesis
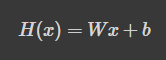
hypothesis = x_train * W + b
print(hypothesis)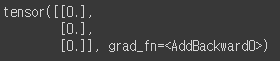
이제 설정한 가설을 이렇게 명시적으로 써줍니다.
x_train이 위의 가설 설정 수식에 x에 해당하며, W와 b는 위에서 초기화한 변수들입니다.
W와 b를 0으로 초기화를 해두었기 때문에 모두 0이 뜨는 것을 확인할 수 있습니다.
▶ Cost
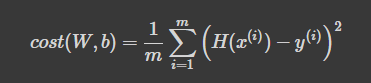
Cost Function을 코드로 구현을 해보겠습니다.
cost = torch.mean((hypothesis - y_train) ** 2)
print(cost)
hypothesis가 H에 해당이 되고, y_train이 y에 해당이 되며 그것을 제곱을 하여 mean함수로 평균값을 구하여 cost 변수에 담은 것입니다.
이렇게 가설과 Cost함수를 프로그래밍을 통해 정의를 해보았습니다. 이제는 Gradien Descent Algoritm을 통하여 자동으로 w와 b값을 구하면 됩니다.
▶ Gradient Descent
직접 이 알고리즘을 구현할 수도 있겠지만, 지금은 파이토치 안에 있는 optimize 함수를 사용할 것 입니다.
# learning rate => lr = 0.01
# W := W - alpha*d/dw*cost(w)
optimizer = optim.SGD([W, b], lr=0.01)optim 함수에는 다양한 함수가 존재합니다.
그중에 Gradient Descent Algoritm을 해결할 수 있는 SGD를 사용하였습니다.
이 함수의 사용방법은 optim 함수를 통해 구하고자 하는 변수가 W와 b라는 것을 설정해주고, 이전에 배웠던 Gradient Descent를 할 때 곱해줬던 하나의 alpha값이 있었는데, 그 값이 lr(=learning rate)이라는 변수에 alpha값을 0.01로 셋팅 해주었습니다.
# 옵티마이저 0으로 초기화
optimizer.zero_grad()
# cost계산 !!! 미분값 계산해서
cost.backward()
# 옵티마이저 갱신
optimizer.step() gradient 값을 0으로 초기화 해주고, Cost 계산을 해 W의 값을 계산합니다.
마지막으로 optimizer.step()으로 W값이 위의 계산을 통해서 갱신이 된다. 이제 출력해보겠습니다.
print(W)
print(b) 
분명히 앞에서 w와 b는 0이었고, cost값은 4.6667이었습니다. 모든 계산을 마친 후 w는 0.0933, b는 0.0400 이 되었고, hypothesis와 cost값을 계산해보겠습니다.
hypothesis = x_train * W + b
print(hypothesis)
cost = torch.mean((hypothesis - y_train) ** 2)
print(cost)
cost 값은 4.6667에서 3.6927이 되었습니다. 이렇게 한 번씩 돌게 되면 cost값은 작아지게 되며, 계속 반복이 되다보면 더이상 cost값이 변하지 않는 위치에 도달하게 될 때 학습을 멈추면 됩니다.
▶ Training with Full Code
In reality, we will be training on the dataset for multiple epochs. This can be done simply with loops.
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
# 모델 초기화
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=0.01)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = x_train * W + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} W: {:.3f}, b: {:.3f} Cost: {:.6f}'.format(
epoch, nb_epochs, W.item(), b.item(), cost.item()
))
결과를 w , b , cost 값을 차례로 찍어보면, 점점 W는 1에 가까워지고, b는 0에 가까워지며 cost값은 계속 작아지는 것을 볼 수 있었습니다. 여기서 중요한건 W가 1로 수렴하고 있다는 사실입니다.
여기까지 Pytorch를 통해서 W와 b값을 구해보는 과정을 알아보았는데요. 앞으로 w,b값을 계산할 수 있게 되었습니다.
이제 맨 위의 선형회귀의 설명해서 다룬 예시 처럼 7시간 공부한 학생은 이번 시험에서 몇 점을 맞을 수 있을지 알아낼 수 있었습니다.
# H(x) = Wx + b
# 가설설정 => 예측하고자 하는 값 => 시험성적 => 1 * 7 + 0.033 =가설설정이 곧 예측하고자 하는 값이고, 이것이 결국 시험 성적입니다.
그러므로 W는 1이고, 7시간 공부했으므로 x는 7, b값은 예를들어 0.033이라 했으면 몇점이 나오는지 도출해낼 수 있을 것입니다.
