1. 딥러닝 개념
1) 생성 모델링(Generative Modeling)
cf) 판별 모델링(Discriminative Modeling)
입력받은 데이터를 특정 기준에 따라 판별하는 것이 목표인 모델링
- 의미:
- 존재하지 않던 데이터를 생성하는 것이 목표
- 학습한 데이터셋과 유사하면서도 기존에 없던 새로운 데이터를 생성하는 모델
- 생성 모델링 기법
- Pix2Pix: 간단한 이미지를 입력하면 실제 사진처럼 보이도록 변환, (그림, 사진) 쌍의 데이터셋 필요
- CycleGAN: 양방향 변환이 가능 (이미지 ↔ 사진), 쌍으로 된 데이터가 필요 없음
- Neural style transfer: 신경망을 기반으로 base image와 style image를 이용해 새로운 이미지를 생성함
- GAN
- 가장 간단한 형태의 생성 모델
- 생성자: 의미가 불명한 랜덤 노이즈로부터 신경망에서의 연산을 통해 이미지 형상의 벡터를 생성함.
- 판별자: 기존에 있던 실제 이미지와 생성자가 생성한 이미지를 입력받아 각 이미지가 real, fake인지 에대 한 판단 정도를 실수로 나타냄
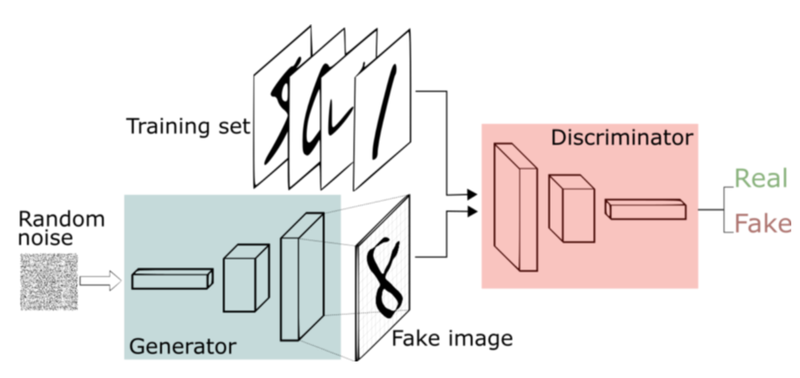
: Adversarial이라고 함
2) 코드 구성
for i in range(10):
plt.subplot(2, 5, i+1) # 1
plt.imshow(train_x[i].reshape(28, 28), cmap='gray') # 2
plt.title(f'index: {i}') # 3
plt.axis('off') # 4
plt.show()- plt.subplot(row, col, index)
- 1 <= index
- 보여줄 내용 전달
- 이미지마다 제목 달아줌
- 불필요한 축 제거
random_idx = np.random.randint(1, 60000)- np.random.randint(n, k): n부터 k 사이의 랜덤 숫자 추출
train_dataset = tf.data.Dataset.from_tensor_slices(train_x).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# train_x라는 넘파이 배열형 자료를 섞음, 배치 사이즈에 따라서 나눔- from_tensor_slices(): 리스트, 넘파이, 텐서 자료형에서 데이터셋 생성 가능
- Buffer size: 데이터를 잘 섞이게 하기 위해 총 데이터 사이즈와 같게 하거나 크게 하면 좋음
model.add(layers.Conv2DTranspose(128, kernel_size=(5, 5), strides=(1, 1), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())-
Conv2DTranspose: Conv2D와 반대로 이미지 사이즈를 넓혀주는 층 (upsampling)
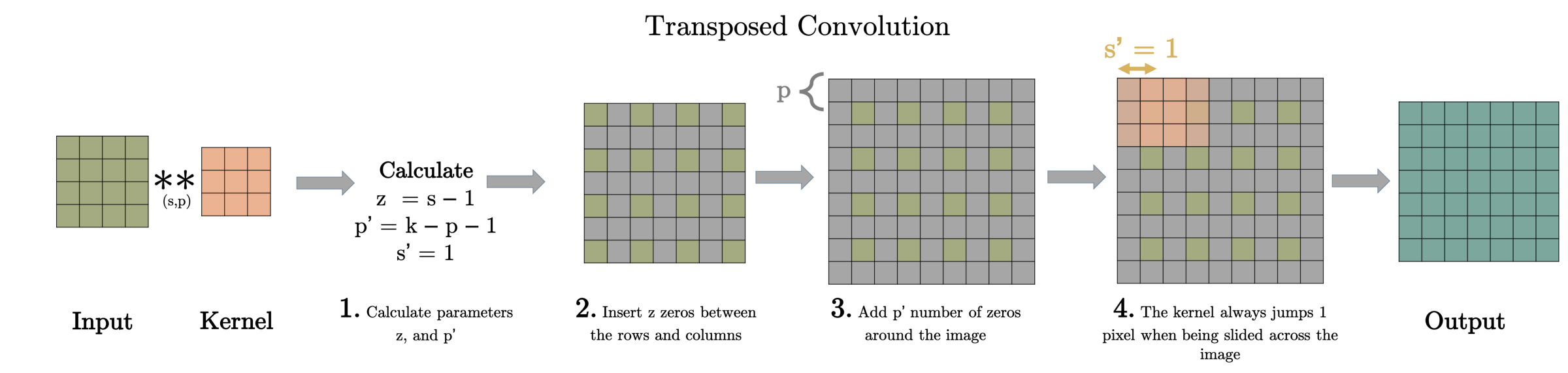
출처 -
BatchNormalization: 가중치가 폭발하지 않도록 가중치 값을 정규화 해줌.
-
LeakyReLU: 중간층의 활성화 함수로 쓰임
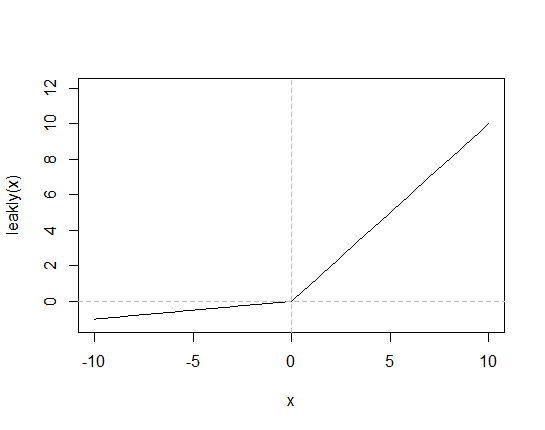
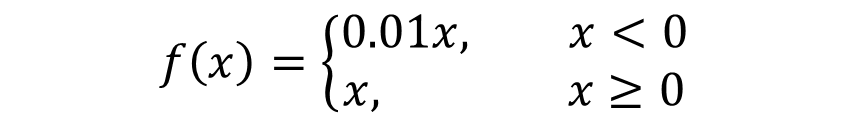
출처 -
tanh: 마지막의 활성화 함수로 쓰임 - 앞서 0-255를 -1~1 이내의 값으로 정규화 시켰던 것과 동일하게 맞추기 위함
-
손실함수: binary cross entropy 사용
- 생성자: 판별자가 Fake Image를 판별한 값이 1에 가까워져야함
- 판별자: Fake Image는 0에 가깝게, Real Image는 1에 가깝게 판별해야함
-
tf.ones_like(vector) / zeros_like: 0 또는 1로 채워진 넘겨진 vector와 같은 크기의 벡터를 반환함
2. 파이썬 개념
1) first class function
출처: 파이썬 - 퍼스트클래스 함수
1. 의미
함수 자체를 인자로써 다른 함수에 전달하거나 다른 함수의 결과값으로 리턴 할 수 있음.
특정 변수에 함수를 할당할 수도 있고, 데이터 구조 안에 저장도 가능함
- 예시
def plus(x, y):
return x + y
print(plus(5, 3))
f = plus
print(plus)
print(f)
>> 8
>> <function plus at ---->
>> <function plus at ---->- plus와 f의 주소값은 같음
f(5, 3)
>> 8- f도 plus와 동일하게 사용 가능
2) closure
- 의미
다른 함수의 지역변수를 그 함수가 종료된 이후에도 기억할 수 있음
def logger(msg):
def log_message(): # 1
print('Log: ', msg)
return log_message
log_hi = logger('Hi')
print(log_hi) # log_message 오브젝트가 출력됩니다.
log_hi() # "Log: Hi"가 출력됩니다.
del logger # 글로벌 네임스페이스에서 logger 오브젝트를 지웁니다.
# logger 오브젝트가 지워진 것을 확인합니다.
try:
print(logger)
except NameError:
print('NameError: logger는 존재하지 않습니다.')
log_hi() # logger가 지워진 뒤에도 Log: Hi"가 출력됩니다.
>> $ python first_class_function.py
>> <function logger.<locals>.log_message at 0x0000022EC0BBAAF0>
>> Log: Hi
>> NameError: logger는 존재하지 않습니다.
>> Log: Hidef outer_func(): # 1
message = 'Hi' # 3
def inner_func(): # 4
print message # 6
return inner_func() # 5
outer_func() # 2- 수행 과정: #2에서 함수(#1) 호출 ⇒ message에 'Hi' 할당 ⇒ #4에서 inner_func 정의, #5에서 inner_func 호출하며 리턴 ⇒ #6에서 message 변수 참조해 출력
def outer_func(): # 1
message = 'Hi' # 3
def inner_func(): # 4
print(message) # 6
return inner_func # 5
my_func = outer_func() # 2
my_func() # 7
my_func() # 8
my_func() # 9
>> Hi
>> Hi
>> Hi- outer_func이 2에서 호출된 후에 종료되었는데도 #7, #8, #9에서 호출된 my_func이 outer_func의 로컬 변수(message)를 참조함.
- 클로저는 함수의 프리변수를 cell_contents라는 곳에 저장하기 때문
- 하나의 함수로 여러 종류의 함수를 간단하게 생성할 수 있음
- 기존의 함수나 모듈을 수정하지 않아도 wrapper 함수를 이용해 커스터마이징 가능
프리 변수
코드 블럭 안에서 정의되지 않았으나 사용된 함수
ex) 함수 안에서 변수와 함수를 선언. 이때 함수 안에 있는 함수에서 해당 변수를 사용하면 이 변수를 프리 변수라고 함
3) 데코레이터
- 기존 코드에 여러 가지 기능을 추가하는 파이썬 구문의 일종
참고
3. 회고
이전에 배웠던 데코레이터 개념을 복습할 수 있었다. 그때 이해가 안돼서 그냥 그런가보다 하고 넘어갔었는데 그때에 비해선 이해가 잘 되는 느낌이다. 다만 지금도 주어진 내용만 이해한 거지 새롭게 사용해보라고 하면 잘 할 수 있을진 모르겠다.
오늘 checkpoint를 이용해서 학습된 내용을 저장한 후 이어서 학습시키는 방법을 배웠는데 유용하게 쓰일 거 같다. 다만 자꾸 파일 경로를 잘못 설정해서 checkpoint와 상관없이 다시 실행해야하는 불상사가 일어났다.. 한 번 할 때 제대로 하자.
