
Reference :: Image Style Transfer Using Convolutional Neural Networks
Write about...
StyleGAN을 정리하면서 StyleGAN 논문에서 당연스럽게 사용되던 AdaIN Layer의 이해를 위해 Style Transfer를 읽어보기로 결정하였다.
결론적으로 그람행렬과 같은 수식 부분의 이해가 애매하지만, 우선적으로 정리하고 수식관련 부분은 수정 또는 다른 포스트에서 진행해보도록 하겠다. 참고로 수식만 보면 어지러운 나를 위해 블로그에서만큼은 수식만 달랑 있는 이미지를 제외하려 노력했다.
Introduction
Style Transfer,Texture Transfer라고도 불리는 이 문제는 Source Image와 Target Image의 각각 content와 style을 섞는 문제로, 주요 쟁점은 Target Image의 content는 최대한 보존하면서 Source Image의 style은 최대한 자연스럽게 입히는 것이라 할 수 있다.
기존의 연구의 non-parametric한 방법(논문 참고)은 Target Image의 단순히 Edge정보와 같은 low-level한 Feature들만을 사용한다는 근본적인 한계가 존재하였다.
하지만 Deep CNN의 등장으로 High-Level의 Semantic 정보를 추출할 수 있었으며, 여러 연구를 통해 이를 증명하였다. 이에 CNN을 사용하여 Texture Transfer 영역에서 High-Level Semantic 정보를 통해 Style과 Content를 독립적으로 다룰 수 있는 Style Transfer Algorithm을 제안한다.
Deep Image Representations
본 논문에서는 사전학습 된 VGG19 Network를 기반으로 학습을 진행한다.
(VGG19 내부의 16개의 Convolution Layer, 5개의 Pooling Layer를 채용)
또한 Max Pooling보다 Average Pooling이 실험적으로 더 나은 산출물을 획득하였기 때문에 본 논문에서는 Average Pooling을 채용하였다.
Content Representation
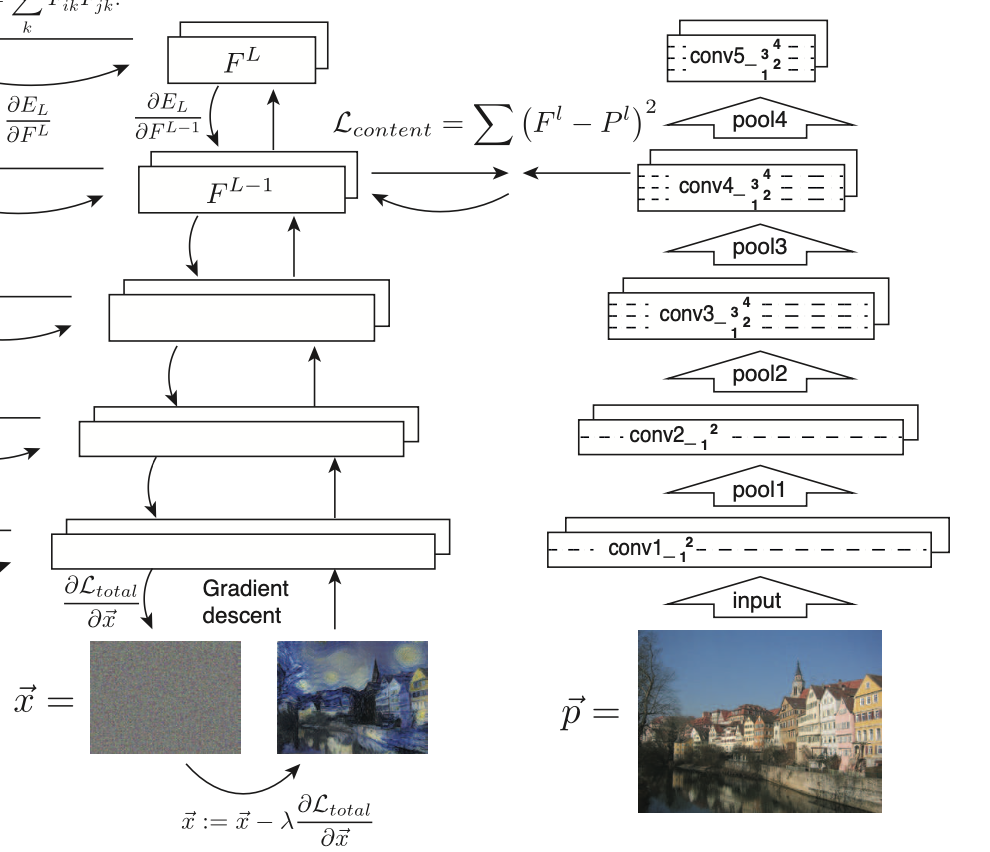
수식을 간추려 설명하도록 하겠다.
Normal Distribution으로부터 생성된 이미지 Feature map F와 Content Orginal Image의 Feature map P의 MSE LOSS를 최소화하는 식으로 학습된다.
이때 뒤에 나올 Style Loss와는 달리 Content Loss는 4번째 Layer(conv4_)에서만 계산을 해주는 것을 그림에서 확인할 수 있는데, 이는 계층적으로 높은 4번째 layer에서 High-Level의 Feature들의 재생산에 집중한다는 것을 알아냈기 때문이다. 상대적으로 낮은 1~3번째 layer의 경우 pixel값 자체를 재생산하는데에만 초점이 맞춰져 있다는 것을 아래 그림을 통해 확인할 수 있다.
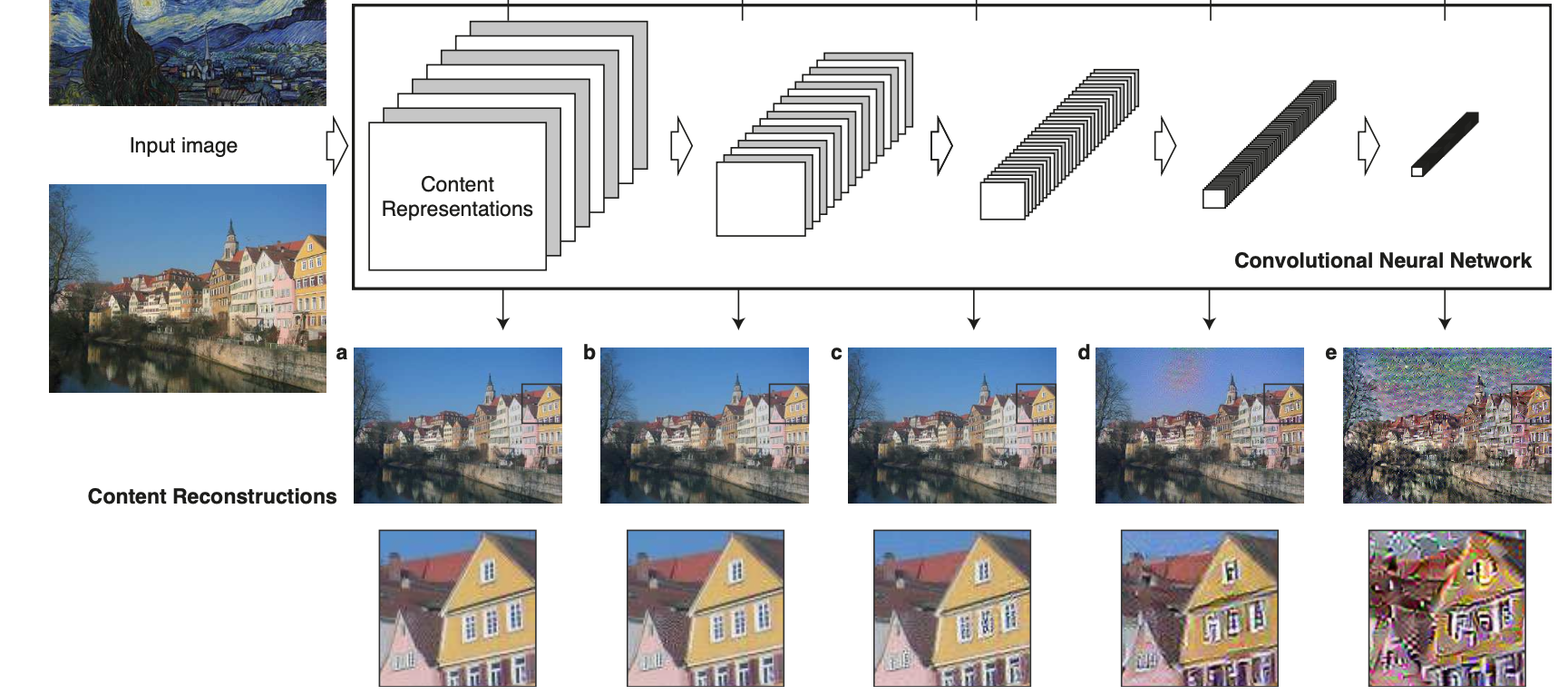
또한 이 결과물은 본 논문의 Result::3.2. Effect of different layers of the Convolutional Neural Network에서 확인할 수 있다. (아래 그림)
Style Transfer시, 픽셀의 재생산에 초점이 맞춰진 conv2보다 conv4를 활용한 이미지가 조금 더 스타일을 반영하여 느낌있게 형성된 것을 확인할 수 있다.

Style Representation
본 논문에서는 Style을 Feature Map으로부터 얻고자 하였으며, 서로 다른 Style에 대하여 Feature Map간의 상관관계를 통해 해석하였다. 쉽게 말하자면, "두 이미지의 스타일이 같다" = "두 이미지의 Feature간 상관관계가 유사하다." 라고 해석하면 된다. 즉, Style Loss는 이미지간의 Feature Correlation을 유사하게 하는 과정으로 최소화하였다고 할 수 있다.
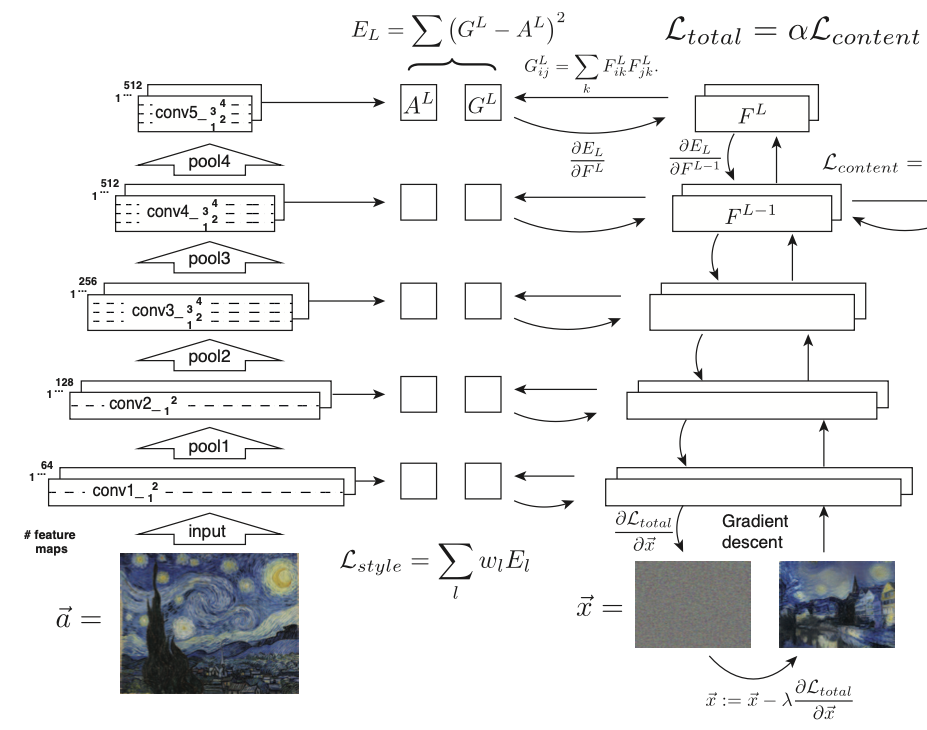
How?
논문에서는 Feature Correlation 정도를 구하며 이에 대한 차이로 Loss를 수식화하기 위해 Gram Matrix를 사용하였다. 각 Layer에서 뽑아낸 Gram Matrix의 차이로 layer당 Loss를 구성하였으며, 최종적으로 모든 레이어의 Loss를 더하고 각 레이어의 weight를 곱하는 형태로 Style loss를 구성하였다.
위 그림에서 A는 Target Image Layer의 Gram Matrix, G는 생성 이미지 Layer의 Gram Matrix라고 생각하면 되겠다.
Gram Matrix가 왜 Layer Feature Correlation과 관계있는지는 따로 정리해보도록 하겠다.
Style Transfer
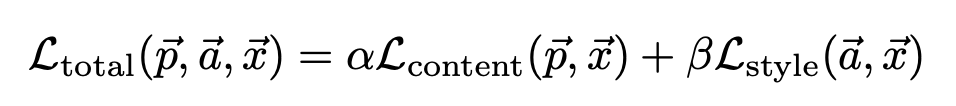
Alpha가 커질수록 Content Loss의 중요도가 커져 Content 및 이미지 형상 자체가 조금 더 부각되는 효과를 보이며, Beta가 커질수록 Style Loss의 중요도가 커져 Style적인 느낌이 부각되는 효과를 보인다.
본 논문 Result::3.1. Trade-off between content and style matching에서 다음 내용에 대한 실험적인 내용 및 결과 이미지를 확인해 볼 수 있다.
[아래 그림, 그림 위의 각 숫자는 alpha/beta 를 뜻한다.]

또한 Optimization은 Image Synthesis에 실험적으로 가장 높은 결과를 낸 L-BFGS를 사용하였다.
Addons
본 논문 Result에서 언급되었으나 핵심내용이 아니기 때문에 추가적으로 다뤄보고자 한 part이다. 핵심내용 Result는 앞서 언급하였다.
생성 이미지 Initialize

생성 이미지 Initialize는 White Noise Image를 사용하였다.
Content Image(A), Style Image(B), White Noise Image(C)이며, 결과에서 볼 수 있듯이 생성 이미지의 초기 값은 별로 중요하지 않다는 것을 확인할 수 있으나, 초기 값에 결과 값이 1대1 매칭되기 때문에 굳이 Content/Style Image를 Initialize할 필요는 없다.
값이 다양한 White Noise Image Initialize를 추천하는 바이다.
실사 사진 Style 적용

결론=이쁘다
Conclusion
논문 자체도 참고하였지만, Style Loss와 같이 영어 및 기본지식이 부족하여 해석이 난해했던 곳은 정리해 놓은 한글자료를 참고하여 내 글으로 정리해보았다. 비록 Style Transfer라는 논문이 발표된 지 많이 지난 논문이며 이에 따른 정리글도 정말 많지만 이렇게 논문 하나를 나의 언어로 완벽하게 정리한다는 데에 초점을 맞추어 정리해보았다. 뿌듯
논문 정리를 블로그에 공개적으로 올려보는 것은 처음이고, 혹시나 이 글을 읽게되는 분들의 피드백은 적극 반영해보도록 하겠다.
+ 혹시 이미지 크기 조정 관련해서 아시는 분 있음 말씀 좀 해주시길 바랍니다..ㅠ
