
일반적으로 딥러닝은 머신러닝보다 훈련 데이터에 더 잘 과적합이 된다고 알려져 있습니다. 퍼셉트론의 수만큼 연산이 되고, 연산 과정 또한 복잡하기 때문에 모델 구성에 조금만 신경 쓰지 않으면 쉽게 과적합 모델이 나옵니다.
오늘은 딥러닝에서 적절한 모델을 만들 수 있는 방법과 과적합을 줄일 수 있는 방법들에 대해 정리해보겠습니다.
1. 가중치 초기화
가중치 초기화는 모델에 처음 가중치를 어떻게 부여할 것인지를 정하는 방법입니다. 처음 신경망을 구성할 때 가중치는 랜덤으로 부여됩니다. 툴마다 다르지만, keras는 Xavier가 디폴트입니다. 처음 가중치를 어떻게 설정하느냐에 따라 모델의 성능이 크게 달라집니다. 가중치 초기화 방법을 하나씩 알아보겠습니다.
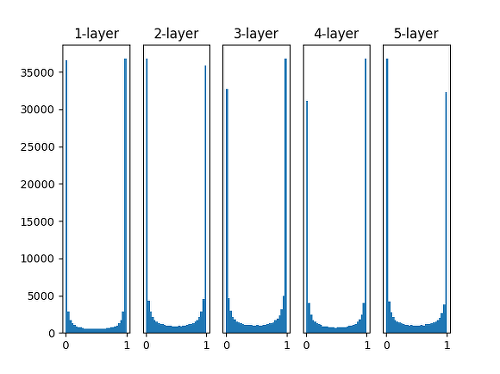
- 표준편차가 1인 정규분포로 가중치를 초기화
- 노드 수(가중치의 수)와 상관없이 가중치를 초기화하는 방법입니다.
- 이와 같은 방법으로 가중치를 초기화할 때는 대부분의 활성화 값이 0과 1에 위치하게 됩니다.
- 활성화 값이 고르지 못할 경우 학습이 제대로 이루어지지 않기 때문에 사용하지 않는 방법입니다.
-
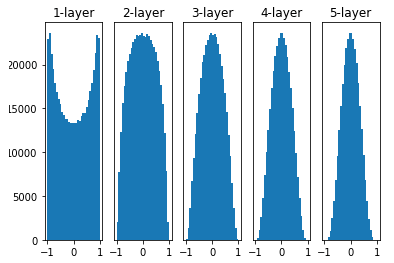
Xavier 초기화
- 가중치를 표준편차가 고정값인 정규분포로 초기화 했을 때의 문제점을 해결하기 위해 등장한 방법입니다.
- Xavier 초기화는 이전 층의 노드가 n개일 때, 현재 층의 가중치를 표준편차가 인 정규분포로 초기화합니다.
- Xavier 초기화는 활성화 함수가 시그모이드인 신경망에서 잘 동작합니다.
- 활성화 함수가 ReLU일 경우에는 층이 지날 수록 활성화 값이 고르지 못하게 되는 문제가 생깁니다.
-
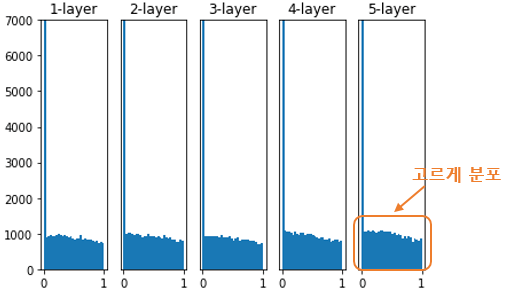
He 초기화
- ReLU 함수에 적합한 가중치 초기화 방법입니다.
- He 초기화는 이전 층의 노드가 n개일 때, 현재 층의 가중치를 표준편차가 인 정규분포로 초기화합니다.
- keras를 이용한 가중치 초기화 적용 방법
He_normal = keras.initializers.he_normal(seed=None)
model = Sequential()
model.add(Flatten(input_shape=(32,32,3)))
model.add(Dense(128, activation='relu', kernel_initializer = He_normal))
model.add(Dense(128, activation='relu', kernel_initializer = He_normal))
model.add(Dense(100, activation='softmax'))
#층마다 초기화를 적용해주어야 함2. 배치 정규화
batch는 입력되는 데이터셋의 한 뭉치를 의미합니다. 배치 정규화는 데이터가 각 층에 들어갈 때 그 입력을 평균과 분산으로 정규화하여 학습을 효율적으로 만듭니다. 배치 정규화를 하면 가중치 초기화에 덜 민감해지고, 기울기 소실 문제가 개선할 수 있다는 이점이 있습니다.
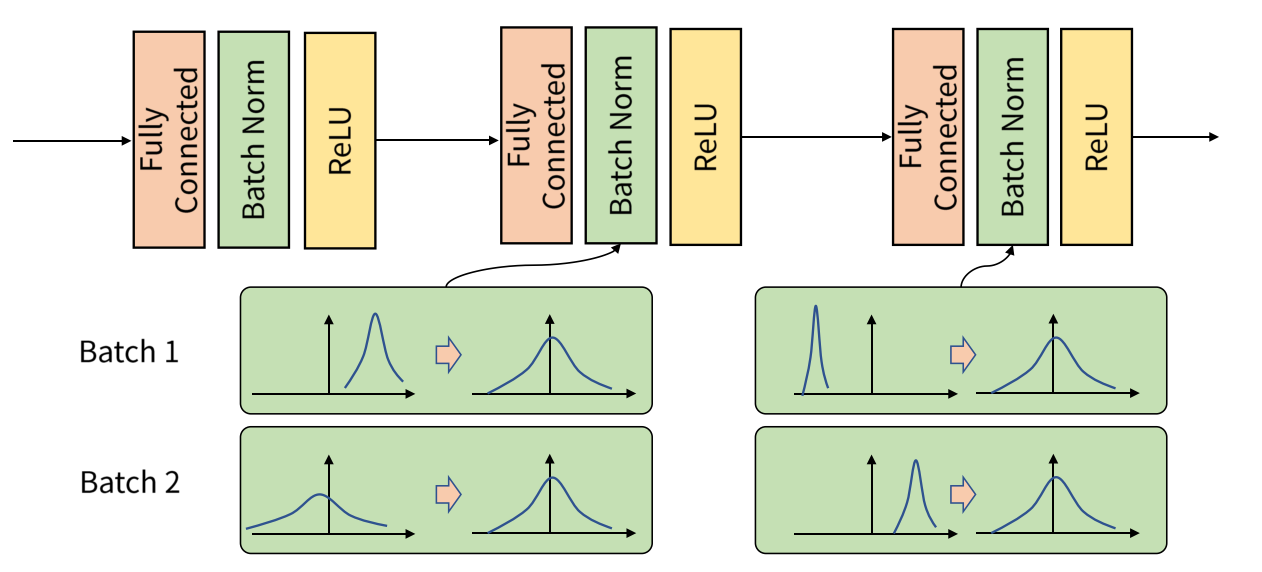
배치 정규화는 각 층에서 활성화 함수를 통과하기 전에 수행됩니다.
- keras를 이용한 배치 정규화 적용 방법
model = Sequential([
Dense(64, input_shape=(4,), activation="relu"),
BatchNormalization(),
Dense(128, activation='relu'),
BatchNormalization(),
Dense(128, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
BatchNormalization(),
Dense(64, activation='relu'),
BatchNormalization(),
Dense(3, activation='softmax')
])
-