
지난 포스팅에 이어서 과적합 방지에 대해 정리해보겠습니다.
과적합 방지를 위한 방법들
1. 가중치 감소(규제)
가중치가 커질 수록 모델이 특정 데이터셋에만 과적합될 확률이 높습니다. 최소화된 손실함수가 global minimum이 아니라 local minimum에 머무르게 되는 것입니다. 머신러닝 모델에서 L1, L2 정규화를 적용하여 모델의 기울기와 복잡도를 규제했던 것처럼 딥러닝에서도 L1, L2 정규화로 가중치가 커지지 않도록 규제할 수 있습니다.
규제 강도를 정하는 람다 값이 커질 수록 비용함수를 최소화하기 위해 가중치들의 값이 작아질 수 밖에 없습니다. 그럼 각 정규화 별로 특징을 살펴보겠습니다.
- L1 Regularization
- 모든 가중치의 절대값의 합을 비용 함수에 추가합니다.
- L1 노름는 절대값을 사용하여 규제 대상을 고르게 제약하는 특징이 있습니다.
- 이러한 특성 때문에 L1 노름는 주로 활성함수 규제에 사용합니다.
- 큰 값을 더 크게 규제하고, 작은 값을 더 작게 규제하는 L2 노름는 활성값을 고르지 못하게 만들 위험이 있기 때문입니다.
- L2 Regularization
- 모든 가중치의 제곱합을 비용 함수에 추가합니다.
- L2 노름는 제곱을 사용하여 큰 값을 더 크게 규제하고, 작은 값은 작게 규제하는 특징이 있습니다.
- 이러한 특징 덕분에 각 값이 분산되어 있는 가중치를 규제하기에 적당합니다. 주로 가중치 규제에 사용합니다.
- keras를 이용한 L1, L2 노름 적용 방법
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))2. Drop out
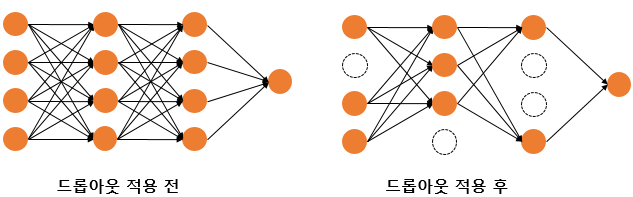
Iteration마다 레이어 노드 중 일부를 사용하지 않으면서 학습을 진행하는 방법입니다. 모델 내에 있는 특정 레이어의 노드 연결을 지정한 비율만큼 강제로 끊어버립니다. 특정 노드가 과도하게 학습되는 걸 방지하여 인공 신경망이 특정 뉴런 또는 특정 조합에 의존하는 것을 방지합니다. 또한 매 Iteration이 사실상 다른 모델이므로 서로 다른 신경망을 앙상블하여 사용하는 것과 같은 효과를 내기도 합니다.
- Keras를 이용한 드롭아웃 적용 방법
#직전 노드 수를 Drop합니다.
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01))
Dropout(0.5)3. Early Stopping(조기 종료)
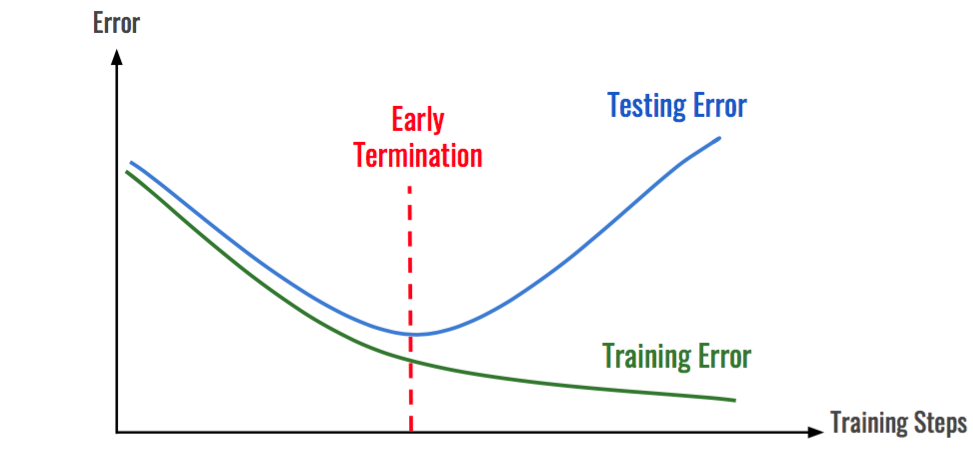
학습 데이터를 과도하게 학습하게 되면 학습 데이터에 대한 성능은 늘어나지만 테스트 데이터에 대한 성능은 감소하는 시점이 옵니다. 학습 데이터는 편향 오차가 줄어들지만, 그만큼 테스트 데이터는 분산 오차가 커지기 때문입니다. 조기 종료는 정해진 학습 횟수(epochs) 전에 검증 데이터셋의 손실이 감소하지 않고, 증가하기 시작한다면(혹은 정체한다면) 학습을 중단할 수 있는 방법입니다.
- keras를 이용한 Early Stopping 방법
#모듈 import
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout
from tensorflow.keras import regularizers
import os
import numpy as np
import tensorflow as tf
import keras
#랜덤 시드 고정
np.random.seed(42)
tf.random.set_seed(42)
#데이터셋 불러오기
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
print(X_train.shape, X_test.shape)
#데이터 정규화
X_train = X_train / 255.
X_test = X_test / 255.
#레이블의 개수와 형태 확인
np.unique(y_train)
#신경망 구축
#신경망 구축에서 dropdout, 가중치 초기화 적용
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01)),
Dropout(0.5),
Dense(10, activation='softmax')
])
#compile
#compile 과정에서 학습률 감소 적용
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001, beta_1 = 0.89)
, loss='sparse_categorical_crossentropy'
, metrics=['accuracy'])
#파라미터 저장 경로 설정
checkpoint_filepath = "FMbest.hdf5"
#조기 종료 옵션 설정
#loss 값이 10회동안 변화가 없으면 조기종료
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
#종료 기준은 val_loss
#가장 좋은 결과만 저장
#가중치만 저장
#저장 단위는 에포크
save_best = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath, monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch', options=None)
#모델 학습
model.fit(X_train, y_train, batch_size=32, epochs=30, verbose=1,
validation_data=(X_test,y_test),
callbacks=[early_stop, save_best])
#조기 종료 직전의 모델 평가
model.predict(X_test[0:1])
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
#콜백으로 Best 모델 파라미터를 불러서 모델 평가
model.load_weights(checkpoint_filepath)
model.predict(X_test[0:1])
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=1)