
인공 신경망 모델을 만들다보면 정해주어야 하는 하이퍼파라미터의 값이 많습니다. batch_size, Interation 횟수, 노드의 수, 학습률, 활성화 함수, 드롭 아웃 비율 등 어떤 값을 설정하느냐에 따라서 성능이 천차만별로 달라지는 하이퍼파라미터들이 있습니다.
머신 러닝과 마찬가지로 딥 러닝도 RandomSearchCV, GridSearchCV와 같은 하이퍼파라미터 탐색 기능이 있습니다. 딥 러닝은 머신 러닝보다 학습 속도가 매우 느리고, 층이 깊어질 수록 조정해주어야 할 하이퍼파라미터의 값도 많아집니다. 그렇기 때문에 RandomSearchCV에서 대략적인 범위를 찾은 다음에 GridSearchCV로 디테일을 조정하는 방식을 자주 사용합니다.
하이퍼파라미터를 더욱 효율적으로 탐색하는 Bayesian method라는 방법도 있습니다. 매 회 새로운 하이퍼파라미터를 적용할 때 이전 결과를 반영하여 최적의 하이퍼파라미터를 찾는 방식입니다. 이번 포스팅에서는 tuner를 사용하여 GridSearchCV와 RandomSearchCV를 적용하는 방법에 대해 알아보겠습니다.
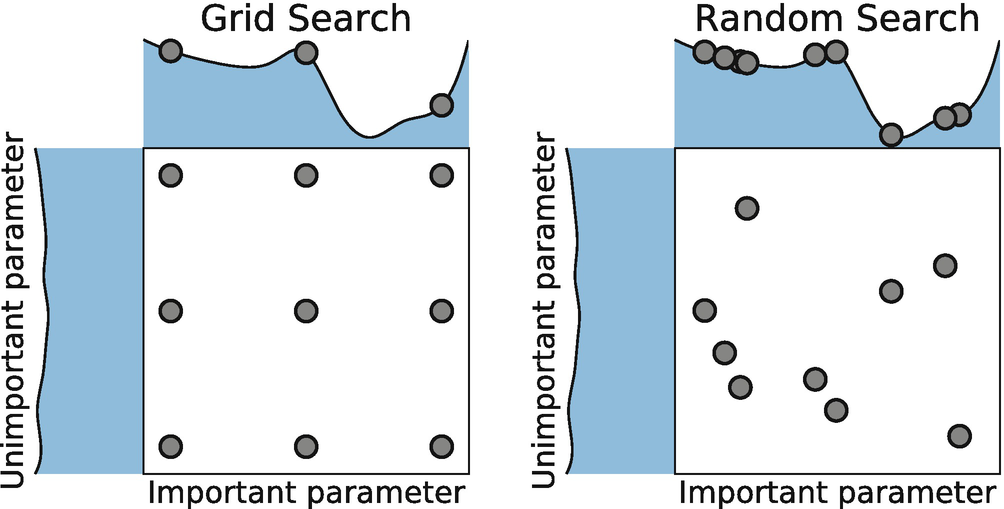
1. GridSearchCV(hyperband)
#모델 제작
def model_builder(hp):
model = keras.Sequential()
model.add(Flatten(input_shape=(28,28))) #입력층
hp_units = hp.Int('units', min_value = 32, max_value = 512, step = 32)
model.add(Dense(units= hp_units, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
model.compile(optimizer = keras.optimizers.Adam(learning_rate = hp_learning_rate),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
return model
#튜너 제작
tuner = kt.Hyperband(model_builder,
objective = 'val_accuracy',
max_epochs = 10,
factor = 3,
directory = 'my_dir',
project_name = 'intro_to_kt')
#callback 함수 지정
#이전 학습 결과를 화면에서 지움
class ClearTrainingOutput(tf.keras.callbacks.Callback):
def on_train_end(*args, **kwargs):
IPython.display.clear_output(wait=True)
#하이퍼파라미터 탐색
tuner.search(X_train, y_train, epochs = 10, validation_data = (X_test, y_test), callbacks = [ClearTrainingOutput()])2. RandomSearchCV
#모델 제작
def model_builder(hp):
model = keras.Sequential()
model.add(Flatten(input_shape=(28,28))) #입력층
hp_units = hp.Int('units', min_value = 32, max_value = 512, step = 32)
model.add(Dense(units= hp_units, activation = 'relu'))
hp_dropout = hp.Float('dropout', 0, 0.5, step=0.1)
Dropout(rate=hp_dropout)
model.add(Dense(10, activation = 'softmax'))
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
model.compile(optimizer = keras.optimizers.Adam(learning_rate = hp_learning_rate),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
return model
#튜너 제작
tuner = kt.RandomSearch(model_builder,
objective = 'val_accuracy',
max_trials = 10,
directory = 'my_dir_2',
project_name = 'intro_to_kt_2')
#callback 함수 지정
class ClearTrainingOutput(tf.keras.callbacks.Callback):
def on_train_end(*args, **kwargs):
IPython.display.clear_output(wait=True)
#하이퍼파라미터 탐색
tuner.search(X_train, y_train, epochs = 10, validation_data = (X_test, y_test), callbacks = [ClearTrainingOutput()])3. tuner에서 사용하는 attribute
- hp.int()
- 계층의 수와 같이 값이 정수인 하이퍼파라미터의 범위를 설정하는데 사용합니다.
- 예시 : hp_units = hp.Int('units_hp', min_value = 32, max_value = 128, step = 32)
- 최소 32, 최대 128의 노드를 32 단위로 탐색(32, 64, 96, 128)
- hp.Float()
- 학습률이나 드롭아웃 비율처럼 실수 하이퍼파라미터 범위를 설정하는데 사용합니다.
- 예시 : hp.Float('dropout', 0, 0.5, step=0.1)
- 0부터 0.5까지 0.1씩 탐색(0.1, 0.2, 0.3..)
- hp.Choice()
- 하이퍼파라미터 조정에 사용할 특정 값을 넘길 때 사용합니다.
- 예시 : hp.Choice(‘learning_rate’, values = [1e-2, 1e-3, 1e-4])
- 1e-2, 1e-3, 1e-4 중 하나의 값을 선택하여 학습

-