
1. 기본 동작 원리
: DNN 심층신경망의 기본 동작 원리
(1) 학습데이터 양이 많아야 함, (2) Gpu 하드웨어 성능, (3) 알맞는 알고리즘
이 3가지가 모두 잘 맞아야 한다.
Deep Neural Network, 딥러닝은 다수의 층으로 이루어진 neural network임.
2. Perceptron
: (input * weight -> 가중합 -> 활성화함수 -> 최종 신호) —> 다음 계층으로 넘어간다.
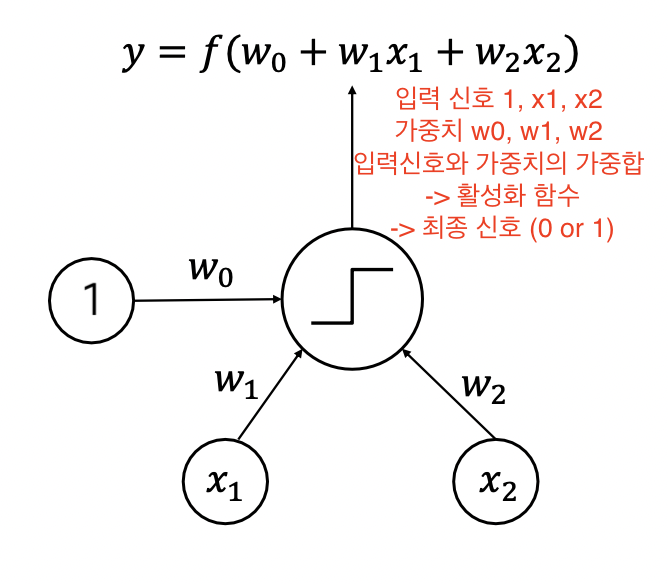
최종신호 > 0 : output 1
최종신호 < 0 : output 0
AND 구현 가능, 가중치값을 조정함에 따라 OR도 구현 가능
3. Decision boundary
: input feature space상에서 직선의 형태로 존재, output이 0과 1로 구분되게 만든다.
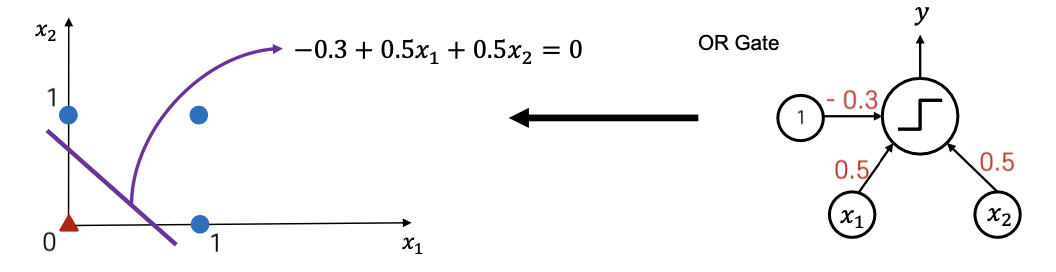
보라색 선이 decision boundary.
-> XOR의 decision boundary는 어떻게 구현하는가?
A+bx1+cx2 = 0 의 직선을 가지는데, 이 직선으로는 XOR 문제를 해결할 수가 없다.
그러나 층을 늘리면 구분을 할 수 있다.
첫 계층에서 하나는 AND 게이트 하나는 OR 게이트를 구성하도록 가중치를 조절하고, 그 다음 계층에서 곱셈 연산을 하면 XOR 게이트 구현 가능!
이처럼 다층 퍼셉트론으로 복잡한 task를 수행할 수 있게 된다.
총 계층은 input layer - hidden layer - output layer로 구성된다.
4. Forward propagation 순전파
아래 첨자 -> 계층 수, 위 첨자 -> 한 계층 내 몇번째 노드인지
행렬의 내적 형태로 나타낸다.
가중치 행렬과 인풋 행렬이 선형결합된 함수가 활성화함수를 통과하면 0 또는 1의 값으로 출력이 나오게 된다.
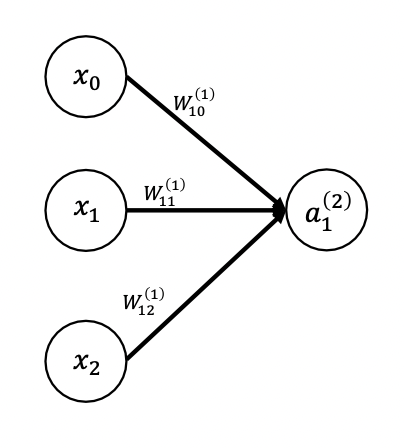
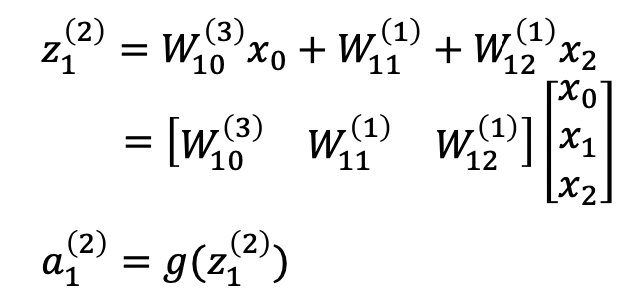
g는 활성화함수가 되고, w는 각각의 가중치, x는 입력값, a는 최종 시그널이 된다.
Ex) MNIST data set 손글씨 분류
-> 손글씨 그림을 명암 정도로 행렬로 나타내고, 진한 정도에 따라 숫자를 부여한다.
이 이미지를 잘라서 input layer로 생성하고, Hidden layer에서 연산하고, output layer에서는 그 레이어를 구성하고 있는 각 노드가 0부터 9까지 얼마의 확률인지를 알려준다.
-> 이 확률로부터 정답인지 아닌지를 비교해서 loss를 찾아낸다.
5. MSE loss 평균제곱오차
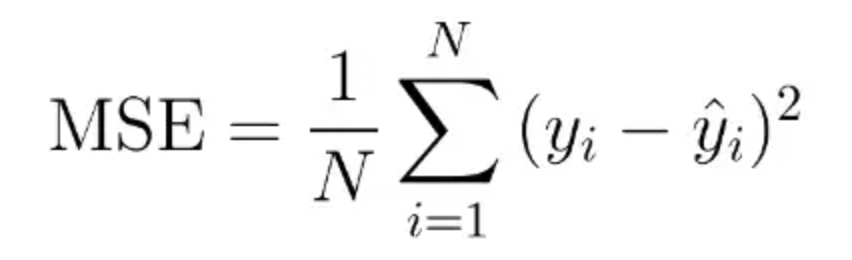
-> 문제점 : 오차가 최대 1이 될 수 있는데, 오차가 점점 줄어들수록 gradient가 크지 않아서 학습속도가 느려진다는 단점
Output vector의 합이 1이 되도록 하는 확률분포의 형태로 나타나야 한다. -> softmax classifier를 사용하면 된다.
6. Softmax layer
: 활성함수 중 하나. 확률값으로 나타내게 된다.
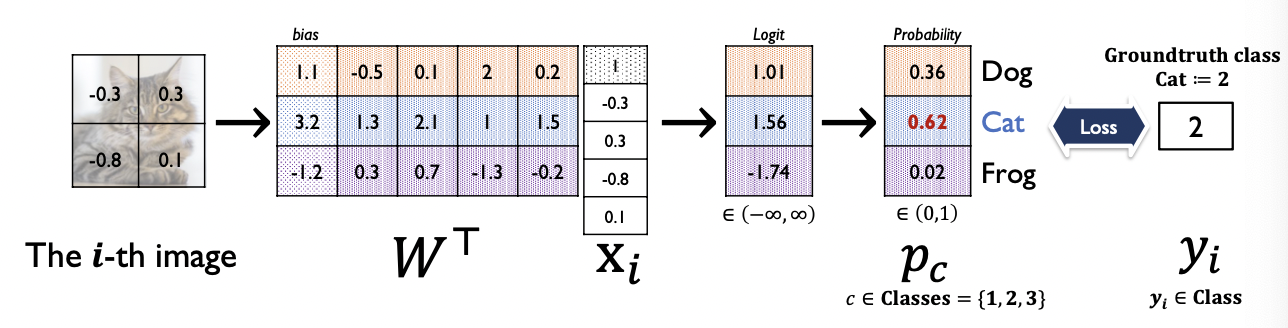
각각의 확률에 대해서 softmax loss에 대해 정답 클래스에 대해 최대한 1이 나오도록 설계할 수 있다.
먼저 입력 벡터와 가중치 행렬을 행렬곱 연산을 해서 softmax layer(활성화함수)에다 넣어주면 확률값으로 나타난다.
상대적인 비율로 각각의 양수인 벡터로써 확률을 파악할 수 있다.
여기에서, softmax layer을 거치고 난 output vector 중 정답 클래스에 해당하는 확률값이 최대한 1이 되도록 하는 loss function을 설계한다.
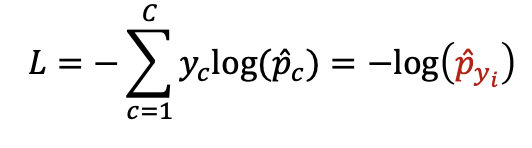
이렇게!!! 그러면 출력이 One-hot vector 형태로 만들어져서 최종 하나에 대해서만 고르게 되고 이 값에 대해서만 오차가 나오게 된다.
정답 클래스가 1에 가까울수록 loss가 0에 가까워진다.
정답 클래스만을 고려해서 loss function을 결정하게 된다.
7. Logistic regression
Output 노드가 하나의 노드로만 구성되게 된다.
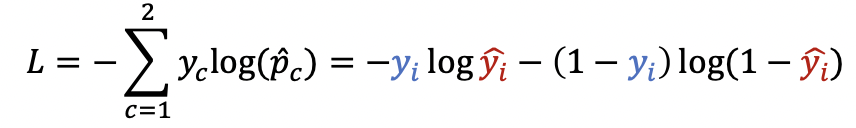
선형결합의 가중치를 곱해주면 output node에서 선형 결합의 결과를 알려줌.
가상의 또 다른 class에 해당하는 logic값을 0으로 설정해주고 이진 분류를 진행한다.
Positive/negative class로 분류를 한다.
Binary cross-entropy loss에서 class 개수가 2개일 때는 BCE loss 사용이 가능하다.
