Decision Tree
의사결정나무(decision tree)는 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내준답니다. 흡사 '스무고개' 놀이를 떠올리면 쉽게 이해할 수 있답니다.
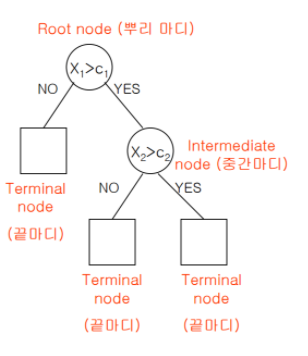
초기 지점은 root node이고 그로부터 시작해서 terminal node로 데이터가 분리됩니다. 위의 decision tree처럼 terminal node가 3개라면, 부분집합 3개로 전체 데이터가 분리된 것입니다.
decision tree는 분류와 회귀 둘 다 가능합니다.
분류의 경우 새로운 데이터가 특정 terminal node내에 속한다는 정보를 확인하게 된다면 그 terminal node에서 가장 빈도가 높은 범주에 새로운 데이터를 분류하게 됩니다.
회귀의 경우 terminal node의 평균을 예측값으로 반환하게 됩니다.
불순도/불확실성
decision tree는 데이터를 분리한 후 영역의 순도(homogeneity)가 증가, 불순도(impurity) 혹은 불확실성(uncertainty)이 최대한 감소하는 방향으로 학습을 진행합니다. 그리고 이러한 과정을 정보이론에서는 정보획득(information gain)이라고 합니다. 이 '순도'를 계산하는 방식에는 다양한 방식이 존재한답니다.
엔트로피 entropy
지니 계수 gini index
오분류 오차 misclassification error
decision tree의 학습 과정
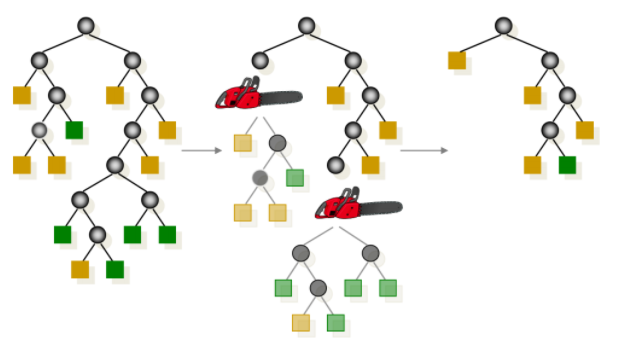
decision tree는 학습 과정에서 변수 영역을 두 개로 구분하는 재귀적 분기(recurisive partitioning)와 너무 자세하게 구분된 영역을 통합하는 가지치기(pruning) 두 가지 과정이 존재합니다.
recursive partitioning
pruning
장단점과 random forest
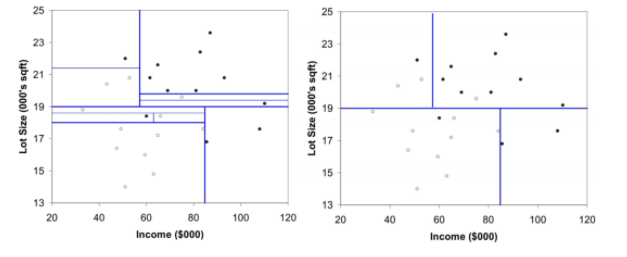
decision tree는 계산 복잡성 대비 좋은 성능을 냅니다. 그리고 변수 단위의 설명력을 지닌다는 점에서 강점이 있습니다. 그러나 결정경계(decision boundary)가 데이터 축에 수직이어서 특정 데이터에서만 잘 작동할 가능성이 높습니다.
이에 대한 보완으로 random forest 기법이 존재하는데요, 간단히 설명하자면, random forest는 decision tree를 여러 개를 만들고 그 결과를 종합해 예측 성능을 높이는 기법이랍니다. 이에 대해서는 다음 포스트에서 다뤄보도록 할게요!
출처
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
https://tensorflow.blog/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D/2-3-5-%EA%B2%B0%EC%A0%95-%ED%8A%B8%EB%A6%AC/
