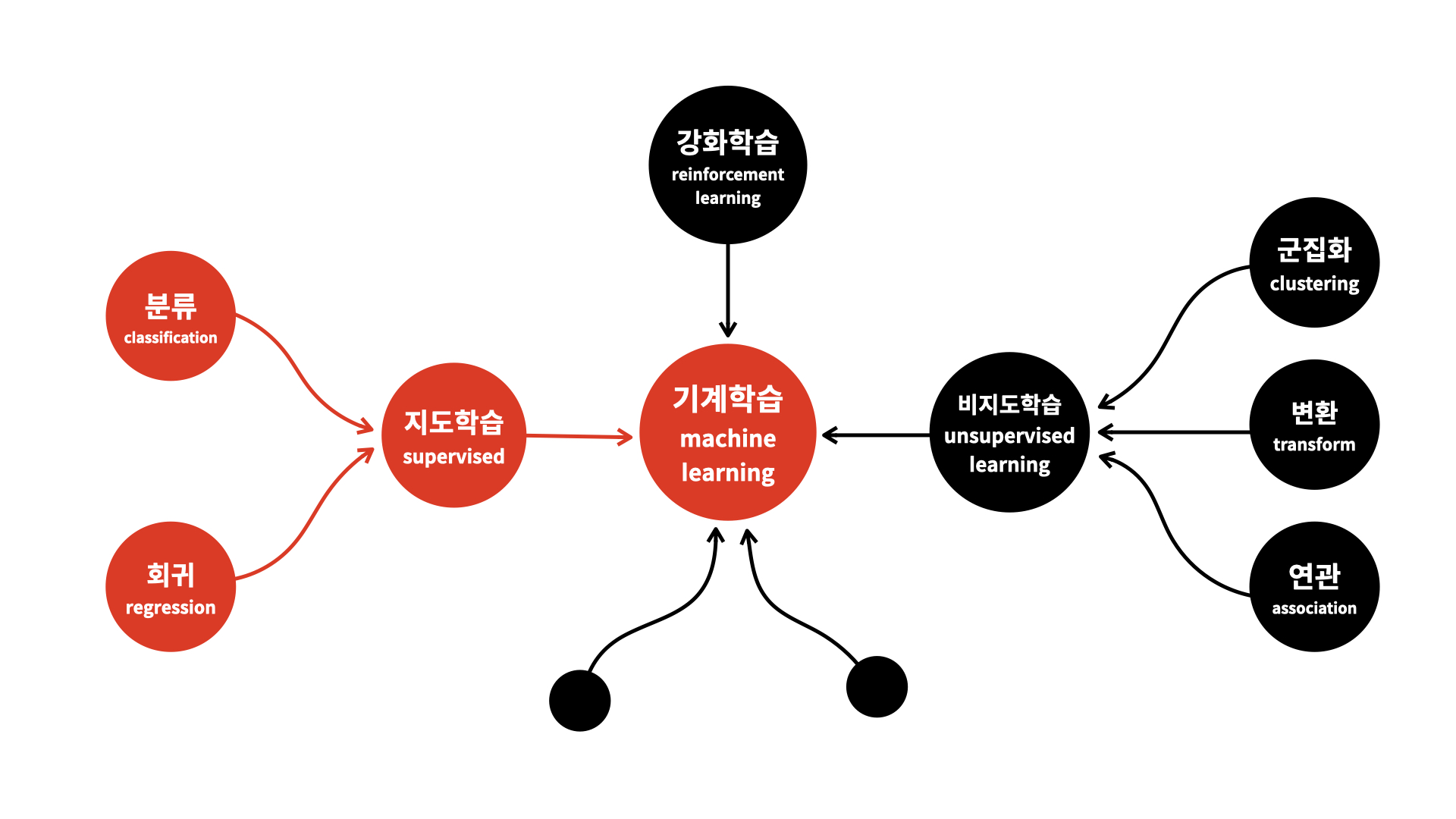
Machine Learning
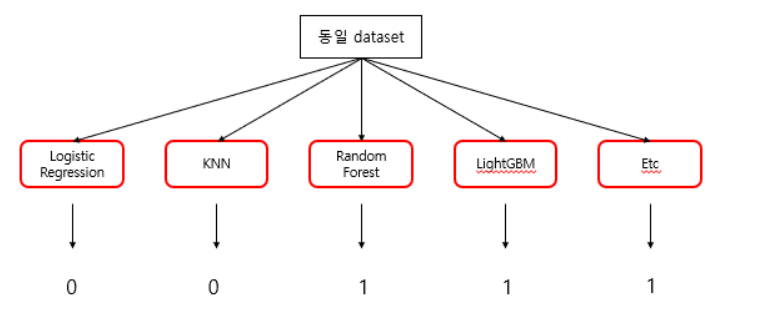
1.KNN 알고리즘
k-nearest-neighbor algorithm(KNN)은 machine learning 중 지도학습에 속하며 분류(classification)과 회귀(regression)에 사용됩니다.지도학습(supervised learning)이란?정답을 알려주며 학습시키는 것
2.Ensemble Learning
Ensemble은 주로 피아노를 비롯해서 음악을 해보신 분이라면 많이 들었을 것 같은 표현인데요, 앙상블은 프랑스어로 '함께', '동시에'라는 의미에서 '조화'의 의미를 갖는 음악 용어로 사용되었다고 합니다. 머신러닝에서도 이러한 어원에서 출발하였답니다.머신 러닝에서
3.Decision Tree
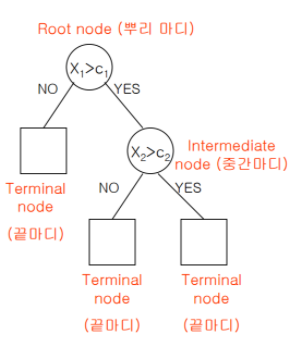
의사결정나무(decision tree)는 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내준답니다. 흡사 '스무고개' 놀이를 떠올리면 쉽게 이해할 수 있답니다.초기 지점은 root node이고 그로부터 시작해서 terminal node
4.Random Forest
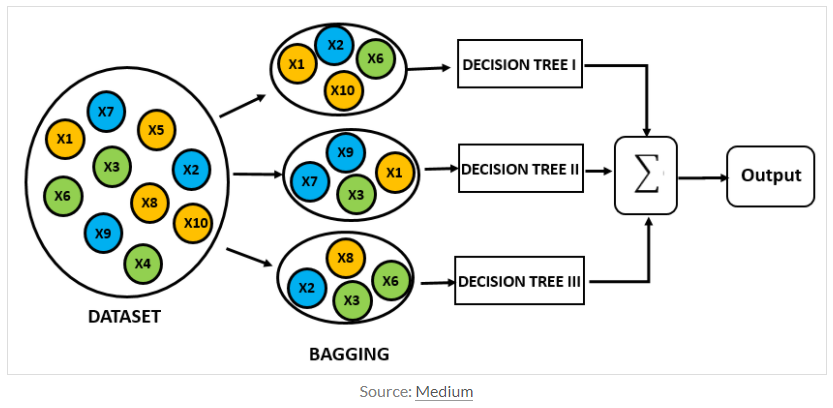
무려 2개의 포스팅 동안 random forest에 대해 소개를 못했는데요, random forest는 ensemble(앙상블)에 속하는 머신 러닝 모델이면서 decision tree에 대한 지식이 있어야 하기에 이제서야 소개를 해드리게 되었습니다.Random fore
5.K-means

K-means clustering(줄여서 kc)운 입력받은 데이터를 토대로 k개의 중심(centeroid)을 기준으로 군집을 형성하는 알고리즘입니다.단점이자 특징으로는 이때 k는 hyperparameter이라는 점입니다. KNN처럼 K-means는 유클리드 거리를 기준
6.Hierarchical Clustering
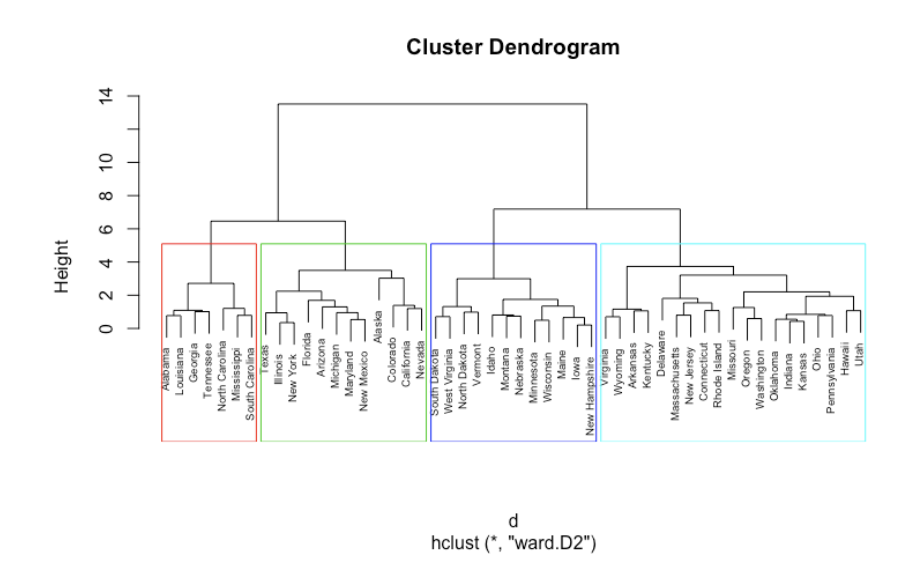
이번 시간에는 hierarchical clustering, 즉 계층적 군집화에 대해 알아볼거에요. 여태까지 다루었던 여러 알고리즘처럼 이 알고리즘 또한 데이터들을 분류해주는 알고리즘이랍니다.hierarchical clustering 알고리즘은 개체들을 가까운 집단부터
7.SVM
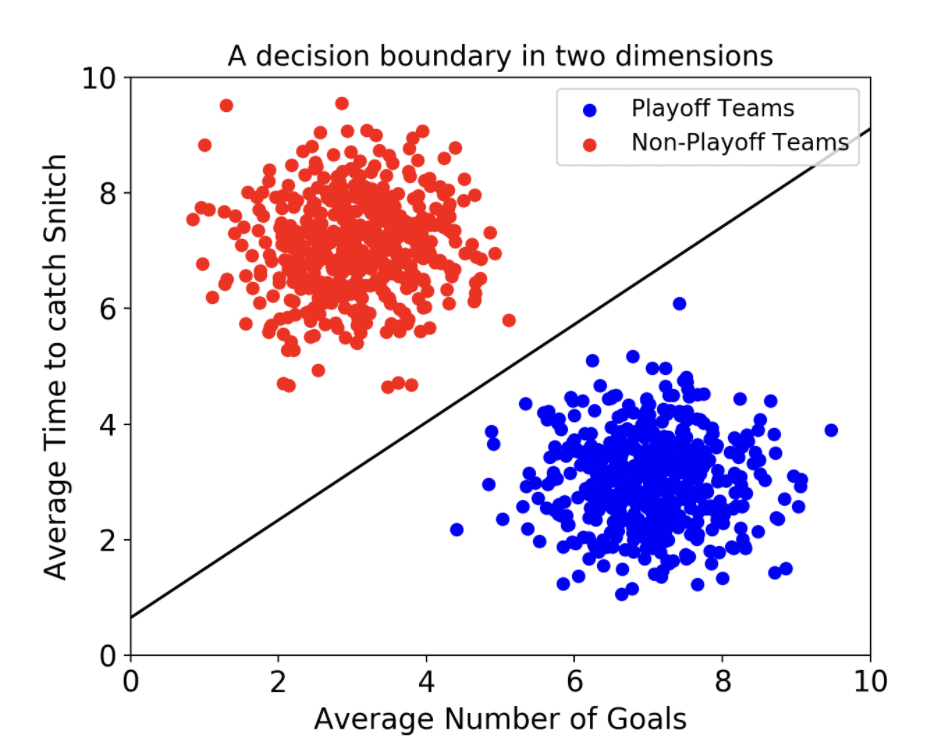
저번 포스팅에 이어 이번에는 support vector machine(SVM)에 대해 알아보도록 할게요. SVM은 역사가 오래되었답니다. 무려 1963에 개발된 머신러닝 기법이랍니다. 역사가 깊은 만큼 수학적인 내용도 꽤 많습니다. 그러나 그 내용이 매우 복잡하고 살아