Ensemble은 주로 피아노를 비롯해서 음악을 해보신 분이라면 많이 들었을 것 같은 표현인데요, 앙상블은 프랑스어로 '함께', '동시에'라는 의미에서 '조화'의 의미를 갖는 음악 용어로 사용되었다고 합니다. 머신러닝에서도 이러한 어원에서 출발하였답니다.
Ensemble Learning이란?
머신 러닝에서 앙상블은 여러개의 모델들을 활용하여 더 강력한 성능의 모델을 만드는 기법입니다. 크게 취합 방법(voting, bagging, random forest), 부스팅 방법(Ada Boost, Gradient Boost), 그리고 스태킹(stacking) 방법이 있습니다.
Voting
동일한 데이터셋을 다양한 모델에 학습시킵니다. 이때의 출력 결과는 hard voting과 soft voting으로 나뉩니다.
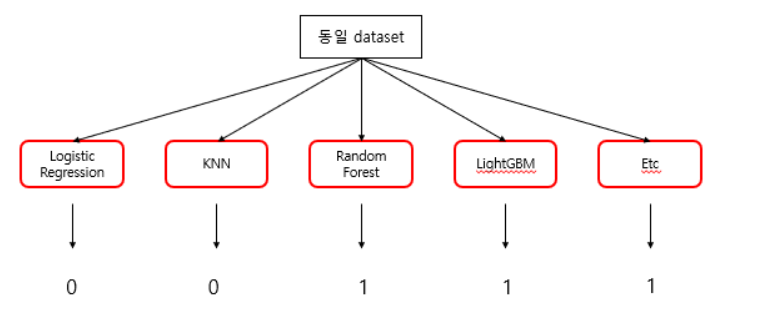
Hard Voting
hard voting은 단순하게 '다수결 투표'를 따라갑니다. 위의 예시에서 3개의 모델이 1을, 2개의 모델이 0으로 분류함으로써 최종적으로는 1로 분류하게 될 것입니다.
Soft Voting
soft voting은 예측확률의 평균으로 최종 결과를 선택합니다.
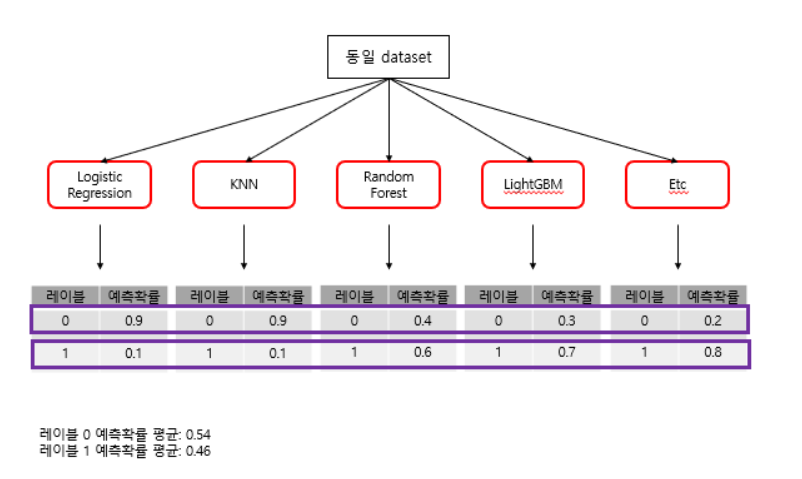
최종확률에서 0이 1보다 크기 때문에 위의 모델은 0으로 분류할 것입니다.
soft voting에서는 성격이 다른 모델들을 선정하는 것이 의미있습니다. 같은 기반의 모델들을 대상으로 voting을 진행할 경우 결과가 편향될 확률이 커지고 voting의 의미가 퇴색되기 때문입니다.
Bagging
Bagging은 Bootstrap과 Aggregating의 약자로 Training Set에서 복원추출을 통한 bootstrap을 만들고 이를 대상으로 훈련시켜 분류의 경우 Majority Voting을, 회귀의 경우 각 모델 결과의 평균값을 최종값으로 출력합니다.
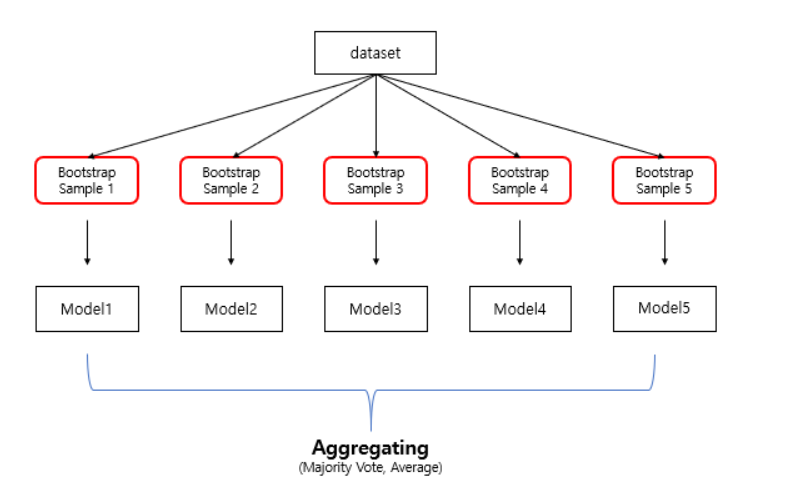
Bagging의 장점
배깅을 사용하게 되면 모델의 bias를 유지하면서 variance를 줄일 수 있습니다. 보통 배깅을 random forest와 같은 방식을 통해 decision tree에 적용을 하는데 배깅을 통해 트리가 깊어질 수록 variance가 커지는 문제를 해결할 수 있습니다. 또한 여러 트리를 만들어 평균을 내는 방식이기 때문에 노이즈에 강합니다.
Random Forest
다음 포스트에서 다루도록 하겠습니다!
Boosting
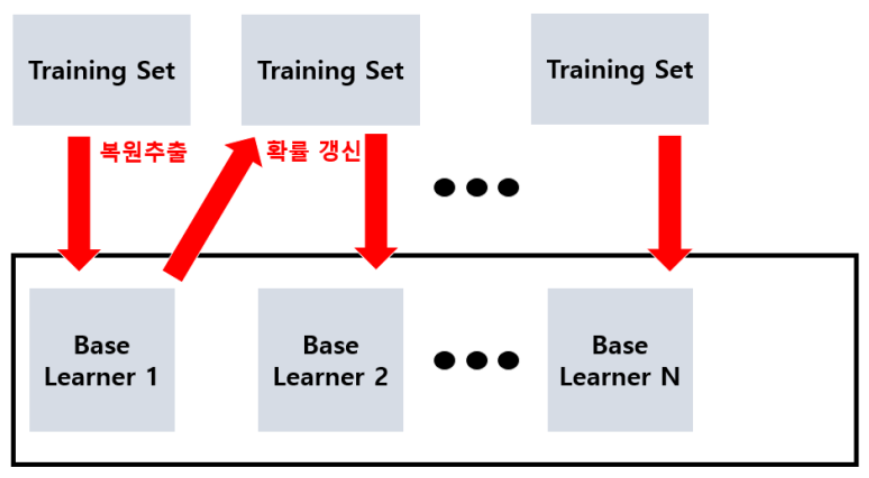
boosting은 bagging에서 다루었던 것처럼 복원 추출을 통해 여러 모델들을 만드는 과정까지는 같으나, 앞선 앙상블 기법들은 병렬적으로 모델들을 결합했더라면 boosting은 단일 모델을 순차적으로 학습을 진행합니다. 학습을 진행한 후 샘플 1에서 잘 분류하지 못한 데이터들에 가중치를 부여하여 샘플 2로 넘깁니다. 이를 n번 반복함으로써 학습을 진행합니다.
즉, weak model을 보완함으로써 strong model을 만드는 방법인 것입니다.
Adaboost(adaptive boosting)
Adaboost는 boosting의 대표적인 방법으로 우선 처음 만든 데이터에서 잘못 분류한 데이터에 가중치(weight)를 증가시켜 다음 모델이 순차적으로 만들어질 때 다시 선택될 확률을 높여 더 많이 학습될 수 있도록 해줍니다. 그리고 다음 모델들이 분류를 올바르게 해내게 되면 다시 그 가중치를 감소시킵니다. 그 과정을 통해 최종 모델이 완성됩니다.
Gradient boosting(GBM)
gradient boosting에서 'gradient'가 적혀있듯이 gradient descent가 GBM에서 가장 핵심적인 방법입니다. Adaboost는 오분류한 데이터에 가중치를 더해 모델을 보완했더라면, GBM은 오차를 미분한 gradient를 줌으로써 모델을 보완합니다.
GBM을 보완한 알고리즘으로는 XGBoost, LightGBM, CatBoost등이 있습니다.
Stacking
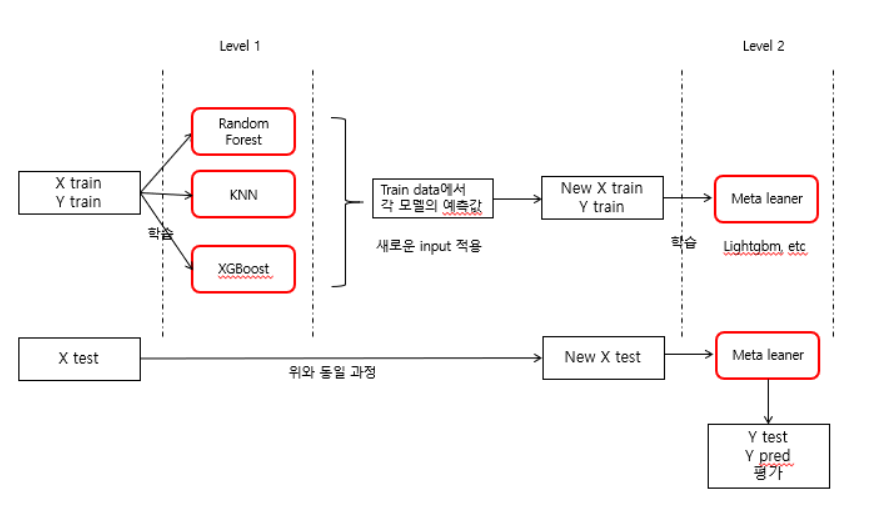
stacking 기법은 정말로 기묘한 알고리즘인 것 같습니다. 예측값을 대상으로 훈련을 진행한다니... 기묘합니다 ! 이러한 특징을 meta-level learner라고 부른답니다.
- Train과 Test 데이터를 분리한다.
- Train 데이터에 대해 다양한 알고리즘을 적용하여 학습하고 예측값을 뽑아낸다.( 단 voting classifer와 동일하게 비슷한 알고리즘이 아닌 기반이 다른 알고리즘을 적용하는 것이 효과적)
- 2번에서 출력된 예측값만을 독립변수의 input으로 사용한 모델 1개를 학습한다.
- Test 데이터에 대해 2번(학습된 알고리즘에 예측값 출력)을 수행하고 3번에서 학습된 meta learner로 최종 결과를 뽑는다.
- 평가 진행
Stacking의 장단점
인기는 bagging이나 boosting보다는 적지만 kaggle에서 좋은 성능을 보이는 경우가 있답니다. 하지만, 연산량이 많고 과적합의 위험도 있다는 단점이 존재합니다.
출처
https://blog.naver.com/ollehw/221563443494
https://blog.naver.com/winddori2002/221837065744
http://blog.naver.com/PostView.nhn?blogId=qbxlvnf11&logNo=221488622777&categoryNo=0&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView
