KNN이란?
k-nearest-neighbor algorithm(KNN)은 machine learning 중 지도학습에 속하며 분류와 회귀에 사용됩니다.
-
지도학습(supervised learning)이란?
정답을 알려주며 학습시키는 것 -
분류(classification)이란?
데이터를 특정한 범주 내로 분류하는 것 -
회귀(regression)이란?
데이터들의 특징을 토대로 값을 예측하는 것
KNN 알고리즘은 모델을 별도로 구축하지 않아도 된다는 점에서 게이른 모델(lazy model)이라고도 불립니다.
KNN 분류(classification)
KNN 분류는 데이터로부터 거리가 가까운 'k'개의 다른 데이터들의 레이블을 참조하여 분류하는 알고리즘입니다.
이 알고리즘에서의 hyperparameter는 탐색할 이웃 수 'k'와 거리 측정 방법입니다.
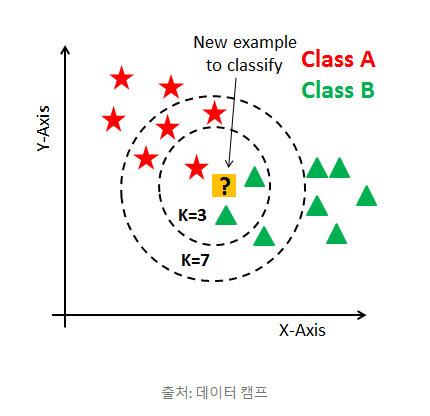
'k'의 범위
아래 그림에서 보았을 때, k=3인 경우 새로운 샘플은 세모로 분류되지만, k=7인 경우 별표로 분류됨을 확인할 수 있다. k값은 동점이 발생할 경우를 대비하여 홀수로 정하는 것이 바람직합니다.
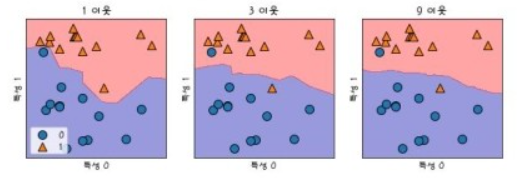
'k'가 너무 작을 경우, 모델이 데이터의 지역적인 특성을 지나치게 반영하게 되면서 overfitting될 가능성이 높아지고 'k'가 너무 클 경우, 모델이 과하게 정규화되어 underfitting될 가능성이 높아집니다. 따라서 적절한 'k' 값을 경험을 통해 선정해야합니다.
거리 측정 방식
Euclidean Distance
두 관측치 사이의 직선 최단거리를 의미합니다.
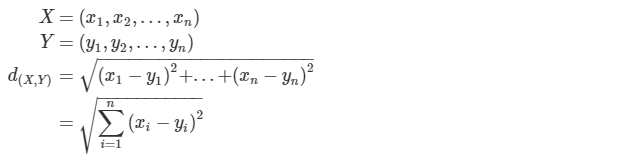
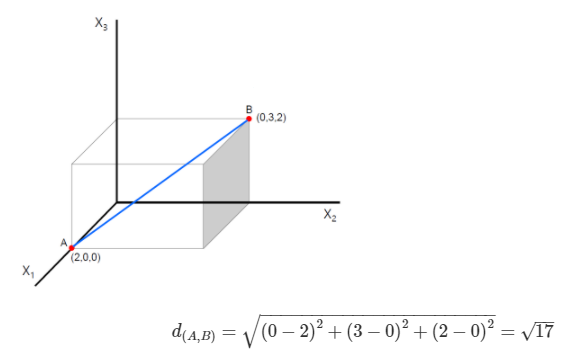
Manhattan Distance
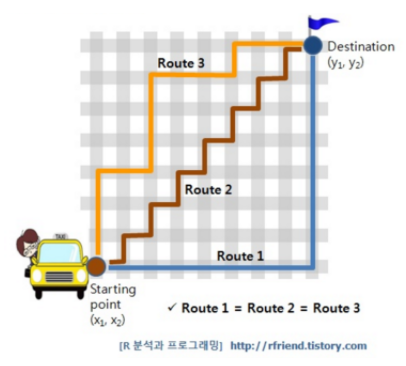
그림에서 보이듯 Route 1, Route 2, Route 3 모두 거리가 같음을 알 수 있습니다. 이처럼 x, y축 방향으로만 진행하는 격자에 맞추어 이동하는 거리를 아래 공식에 따라 구하는 것을 Manhattan Distnace라고 부릅니다.
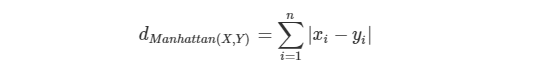
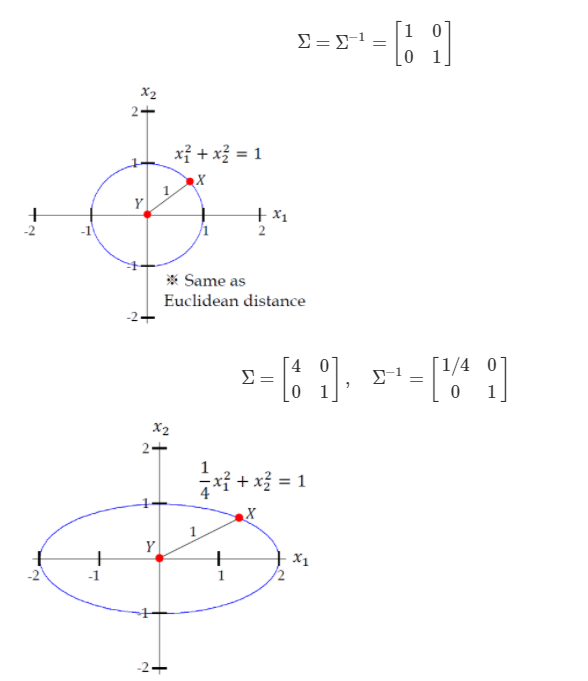
Mahalanobis Distance
여기서부터 나오는 공식들은 잘 모르지만, 나중에 보면 이해하겠지라는 심정으로 간단히 정리하겠습니다.
마할라노비스 거리는 변수 내 분산과 공분산 즉, 상관관계를 고려한 거리입니다.
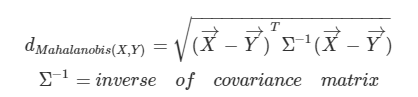
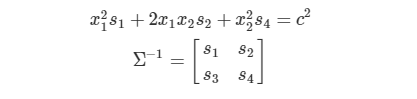
Correlation Distance
이 계산 방식은 데이터의 pearson correlation값을 거리 척도로 사용합니다. 즉, 관측치 하나하나를 데이터 전체의 경향성과 비교한 계산 방식입니다. 상관계수는 -1부터 1까지의 범위를 가지므로 Correlation Distance가 0에 가까울수록 데이터 간의 유사도가 큰 것이고 2에 가까울수록 그렇지 않다고 해석할 수 있습니다.
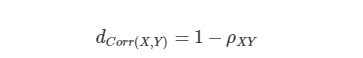
Rank correlation Distance
데이터에 순위(rank)가 주어졌을 때, Spearman rank correlation을 거리 척도로 사용하고 나머지 feature에 대해서는 pearson correlation값을 사용합니다.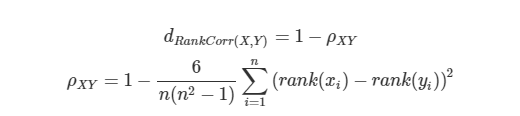
KNN 회귀(regression)
KNN 회귀에서는 연속 변수의 예측값을 출력합니다. k개의 최근접 이웃들의 거리의 역수를 가중치로 한 가중 평균을 사용하여 예측값을 출력합니다.
KNN 사용시 주의해야할 점
Combining rule
KNN은 주변 이웃의 분포에 따라 예측 결과가 달라집니다. 가장 단순한 결정 방식에는 다수결(majority voting)이 있습니다. 또 다른 방식으로는 가중합(weighted voting)이 있습니다. 거리(d)(=유사도)가 가까울수록 더 큰 가중치를 주는 것입니다. 1/d 등 같은 단조감소함수에 따라 가중치를 적용하면 됩니다.
정규화
데이터간 분포가 크게 다를 경우 각 변수의 차이를 해석하기 어렵습니다. 이러한 경우에도 알고리즘을 적절하게 적용하기 위해서 변수 값을 표준 범위로 재조정하는 정규화 과정이 필요합니다. 크게 두 가지 방식이 있습니다.

장단점
그림으로 대체하겠습니다 ㅎㅎ

출처
https://ratsgo.github.io/machine%20learning/2017/04/17/KNN/
https://john-analyst.medium.com/knn-%EC%B5%9C%EA%B7%BC%EC%A0%91-%EC%9D%B4%EC%9B%83-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-b397a0b2030e
https://blog.naver.com/winddori2002/221868468602
https://blog.naver.com/so15284/222120498851
https://ko.wikipedia.org/wiki/K-%EC%B5%9C%EA%B7%BC%EC%A0%91_%EC%9D%B4%EC%9B%83_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
https://hiruby.tistory.com/373
https://m.blog.naver.com/bestinall/221760380344
https://marobiana.tistory.com/155
https://opentutorials.org/module/4916/28942

근데 mahalanobis distance 에서 inverse of covariance matrix 에서 s3 가 어떤 s3 인가요..?