Gradient Boosting Classifier
Introduction
Gradient Boosting Classifier is a powerful machine learning algorithm that belongs to the ensemble methods family, specifically to boosting techniques. It works by sequentially adding predictors (typically decision trees), where each one corrects its predecessor. Unlike other boosting methods that adjust the weights of observations, Gradient Boosting focuses on minimizing the loss function, a differentiable function that measures the error of the model.
Background and Theory
Gradient Boosting combines multiple weak learners (models that perform slightly better than random guessing) to create a strong learner in a sequential manner. The core principle is to construct new models that predict the residuals or errors of prior models and then add these new models to the ensemble.
Mathematical Foundations
Let's denote our data set as , where represents the features and the target variable for the observation. The goal is to find a function that maps input features to predictions as close as possible to the target values .
The algorithm starts with a model that makes constant predictions:
where is the loss function evaluated at the initial prediction and the true target value .
At each stage to , where is the total number of trees, the algorithm fits a new model to the negative gradient of the loss function evaluated at the previous model's predictions:
Then, it finds the best-fit model to these residuals. The model is typically a decision tree.
Next, it computes a multiplier for the model that minimizes the loss when added to the existing model :
The model is then updated:
where is the learning rate, a parameter that scales the contribution of each .
The process repeats for iterations or until a stopping condition is reached, resulting in a final model:
Algorithmic Contemplation
Let’s try generalizing the problem Gradient Boosting algorithm is about to solve. We want to find the function which minimizes the expected loss function in terms of -dimensional loss function , where .
Unfortunately, is an enormous set for the algorithm to find optimal . Therefore, some constraints are needed, which constrains to:
where is a natural number.
In short, a structure which can be expressed through a linear combination of a constant and several functions is added, rather than a simple generic function.
Moreover, since the distributions of are unknown, it is highly demanding to figure out the expected loss. Therefore, we have to find that minimizes the experienced loss function, which can be derived by utilizing a finite amount of data .
This can be found by following several steps:
At this point, Gradient Boosting reforms the last equation by substituting the minimizing part with the gradient descent method as following:
can be approximated with respect to the positive integer . This is the reason why the term Gradient is included in the name of this boosting algorithm.
Here, the gradient can be computed as:
which in most cases(except for MSE loss), are very complitated to compute. Therefore, we take the 1st-order Taylor approximation with respect to , which necessarily requires the loss function to be differentiable.
If we differentiate the right-hand term of the above equation with respect to , we can approximate the by:
And therefore:
Additionaly, we can optimize in order to minimize the residuals:
As a result, we can define the pseudo-residual as following:
For the next step, we train a new function , which accepts as an input variable and as an output variable, by approximating with respect to . Then we can redefine as following:
Consequently, can be finally set as by adopting , which is for the prevention of overfitting.
From previous explanations, are in fact .
Loss Functions
In the Gradient Boosting Classifier, the choice of the loss function is crucial as it directly influences the model's performance by determining how well the predictions fit the actual data. Here are two popular loss functions and their mathematical integration into the algorithm:
Binary Cross-Entropy Loss
For a binary classification with target variable and predicted probability where is the sigmoid function, the Binary Cross-Entropy loss for a single observation is given by:
In the context of Gradient Boosting, the gradient (negative gradient of the loss with respect to ) that we fit the next model to is:
where is the predicted probability based on the model at iteration .
Multinomial Deviance Loss
For a classification problem with classes, let be the true class encoded as a one-hot vector , where for the correct class and for all . Let be the predicted probability that observation belongs to class . The Multinomial Deviance Loss for a single observation is given by:
The gradient of this loss function with respect to the model's output for class is:
where is the predicted probability for class , computed using the softmax function over the outputs for all classes.
Exponential Loss
For a binary classification problem with target variable (note the difference in encoding compared to the binary cross-entropy loss, where targets are usually and ), and a prediction model , the Exponential Loss for a single observation is given by:
The negative gradient of this loss function with respect to the prediction , which is what the next model in the sequence will predict, is given by:
This formulation effectively weights the update of each point by how poorly it was predicted by the previous model: the worse the prediction (in terms of sign and magnitude of the margin ), the higher the weight of the corresponding point for the next model to focus on.
Procedural Steps
- Initialization: Start with a constant model .
- For to :
- Compute the residuals , the negative gradient of the loss function.
- Fit a model to these residuals.
- Find the optimal multiplier .
- Update the model .
- Output: The final model .
Implementation
Parameters
base_estimator:Estimator, default =DecisionTreeRegressor()
Base estimator for training multiple models
n_estimators:int, default = 100
Number of base estimators to fit
learning_rate:float, default = 0.1
Shrinking factor of the contribution of each estimator
subsampling:float, default = 1.0
Fraction of samples to be used for fitting each estimator
Examples
Test on standardized and reduced() digits dataset with only 5 classes:
from luma.ensemble.boost import GradientBoostingClassifier
from luma.preprocessing.scaler import StandardScaler
from luma.model_selection.split import TrainTestSplit
from luma.reduction.linear import KernelPCA
from luma.visual.evaluation import DecisionRegion, ROCCurve
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
X, y = load_digits(n_class=5, return_X_y=True)
indices = np.random.choice(X.shape[0], size=500)
X_sample = X[indices]
y_sample = y[indices]
sc = StandardScaler()
X_sample_std = sc.fit_transform(X_sample)
kpca = KernelPCA(n_components=2, gamma=0.01, kernel='rbf')
X_kpca = kpca.fit_transform(X_sample_std)
X_train, X_test, y_train, y_test = TrainTestSplit(X_kpca, y_sample,
test_size=0.3).get
gb = GradientBoostingClassifier(n_estimators=100,
learning_rate=0.1,
subsample=1.0,
max_depth=3)
gb.fit(X_train, y_train)
X_cat = np.concatenate((X_train, X_test))
y_cat = np.concatenate((y_train, y_test))
score = gb.score(X_cat, y_cat)
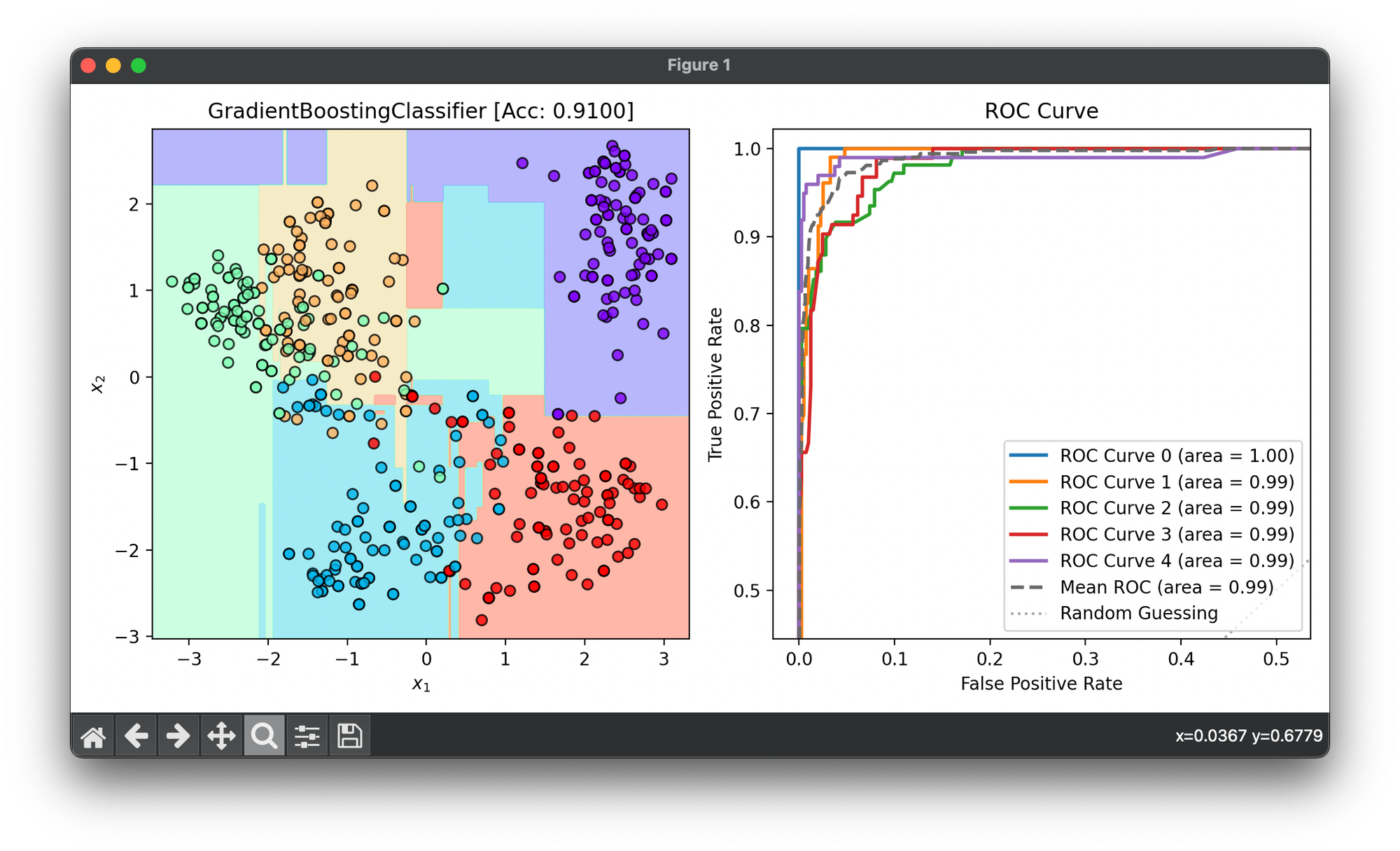
fig = plt.figure(figsize=(10, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
dec = DecisionRegion(gb, X_cat, y_cat)
dec.plot(ax=ax1)
ax1.set_title(f'GradientBoostingClassifier [Acc: {score:.4f}]')
pr = ROCCurve(y_cat, gb.predict_proba(X_cat))
pr.plot(ax=ax2, show=True)
Applications
Gradient Boosting Classifier is used in a variety of domains due to its flexibility and accuracy. Common applications include but are not limited to:
- Fraud detection in banking.
- Customer churn prediction.
- Disease outbreak prediction.
- Demand forecasting in retail.
Strengths and Limitations
Strengths
- Highly Accurate: Often provides very high accuracy across a wide range of applications.
- Flexibility: Can handle different types of data and is adaptable to various loss functions.
Limitations
- Prone to Overfitting: Especially with noisy data and without proper regularization.
- Computationally Intensive: Can be slower to train due to the sequential nature of boosting.
- Parameter Tuning: Requires careful tuning of parameters and stopping criteria to avoid overfitting and underfitting.
Advanced Topics
- Regularization Techniques: Techniques like shrinkage (learning rate) and stochastic gradient boosting can help prevent overfitting.
- Loss Functions: Beyond the typical use with classification and regression tasks, custom loss functions can be implemented for specific applications.
References
- Friedman, J. H. (2001). "Greedy Function Approximation: A Gradient Boosting Machine." Annals of Statistics.
- Natekin, A., & Knoll, A. (2013). "Gradient boosting machines, a tutorial." Frontiers in Neurorobotics.
