Machine Learning
1.[Classifier] Linear Discriminant Analysis (LDA)
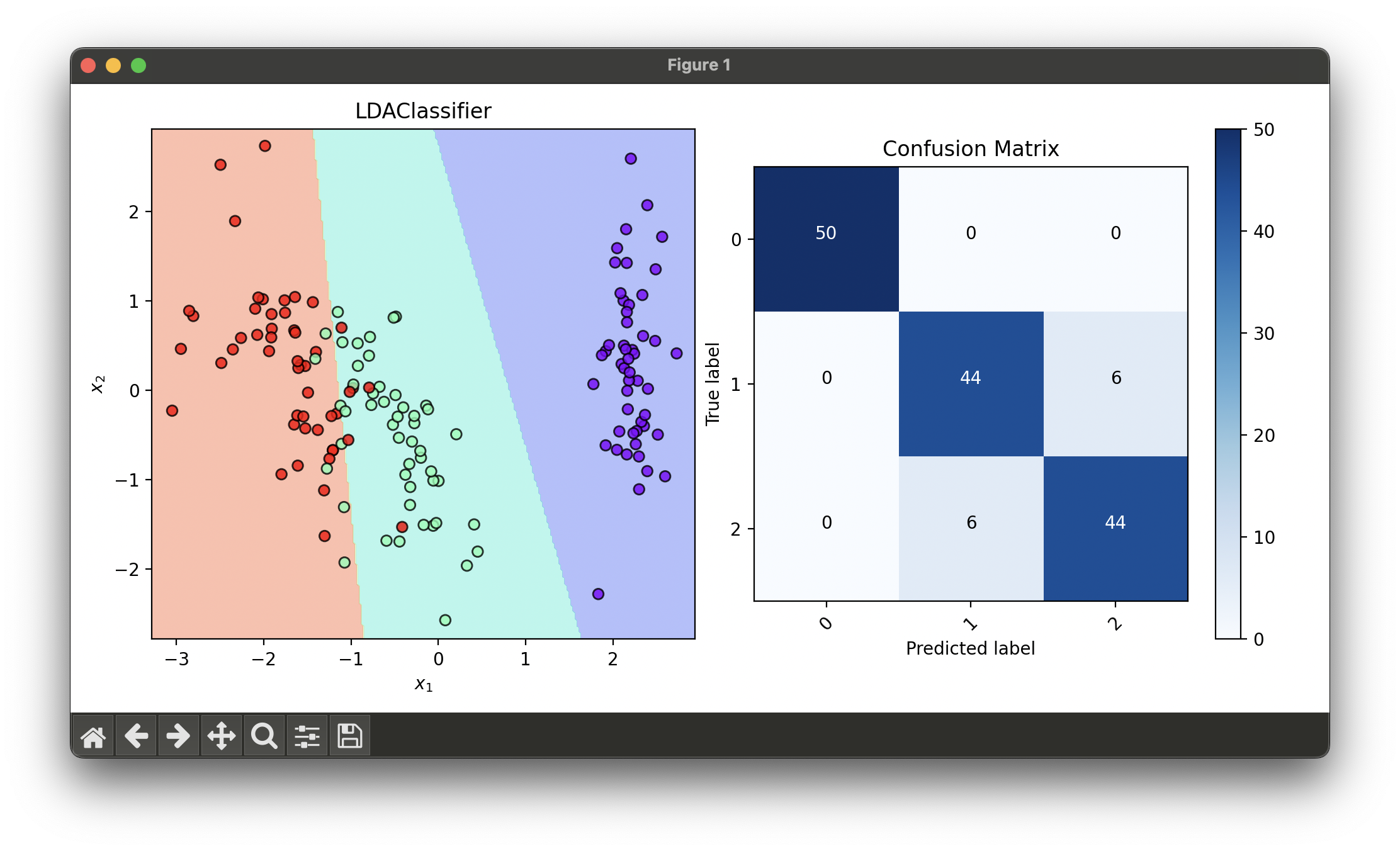
Linear Discriminant Analysis (LDA) is widely used in machine learning and statistics for pattern classification and dimensionality reduction.
2.[Classifier] Quadratic Discriminant Analysis (QDA)
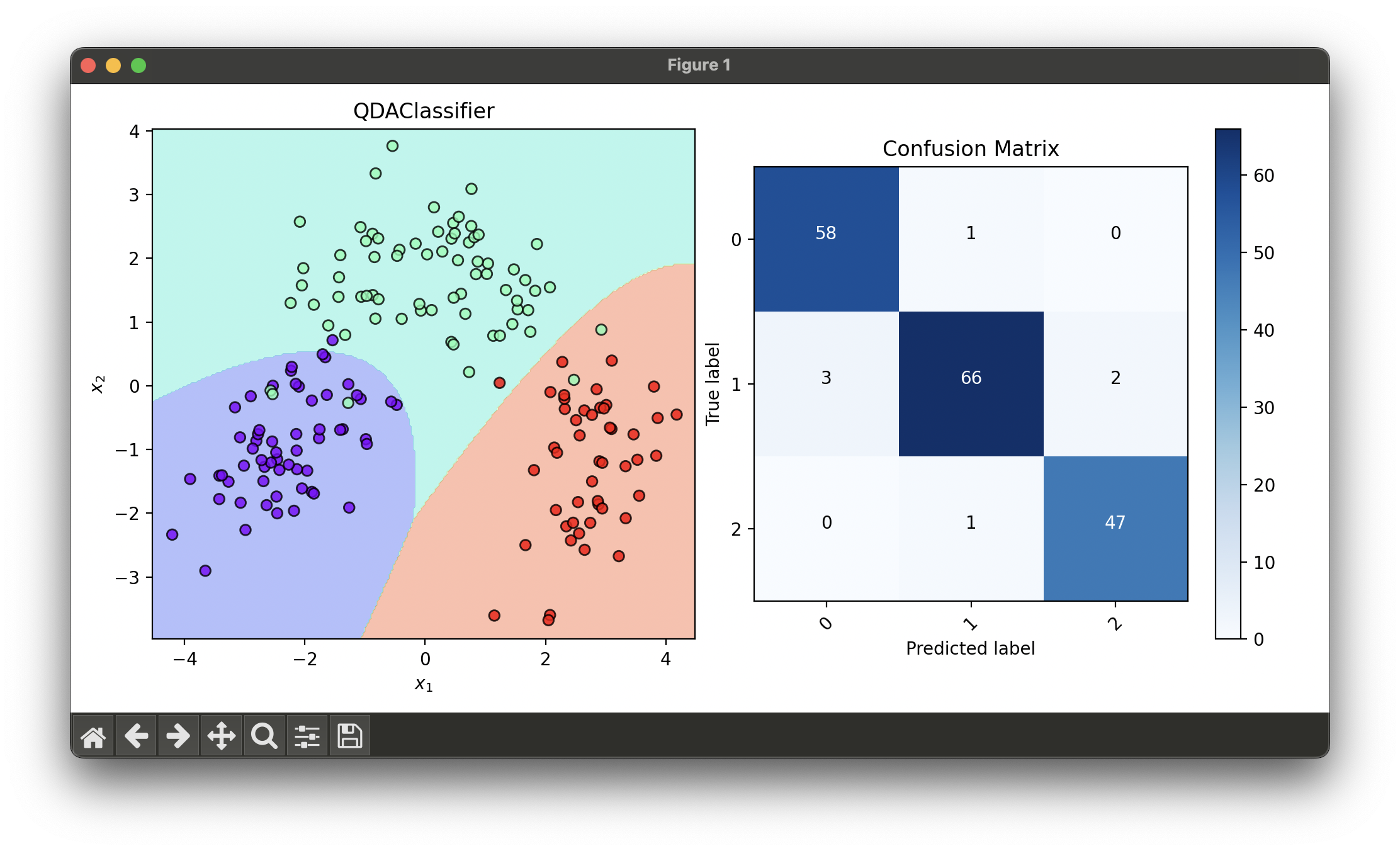
Quadratic Discriminant Analysis (QDA) is a statistical technique used in pattern recognition and machine learning to classify datasets.
3.[Classifier] Regularized Discriminant Analysis (RDA)
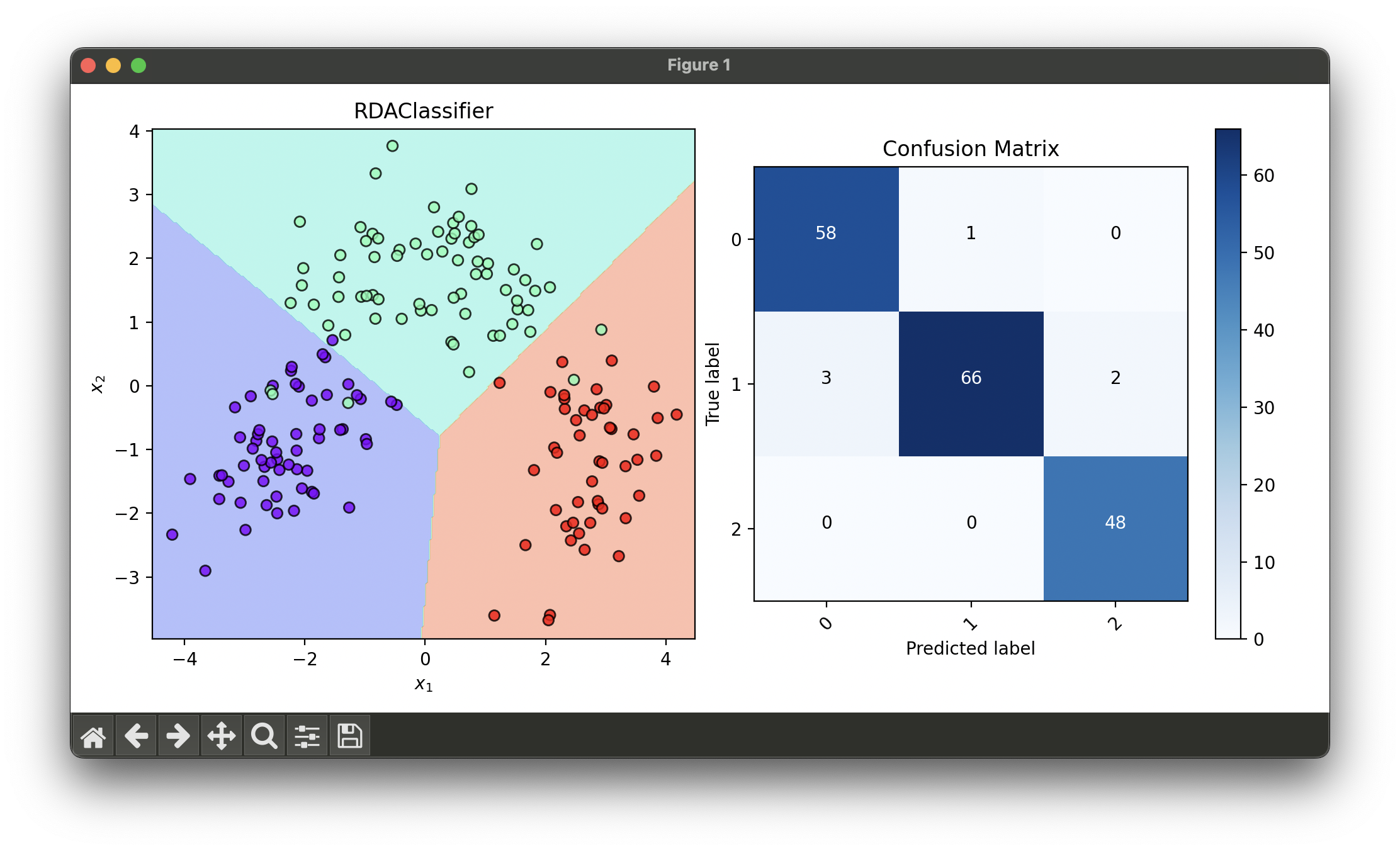
Regularized Discriminant Analysis (RDA) is an extension of Quadratic Discriminant Analysis (QDA) and Linear Discriminant Analysis (LDA).
4.[Classifier] Kernel Discriminant Analysis (KDA)
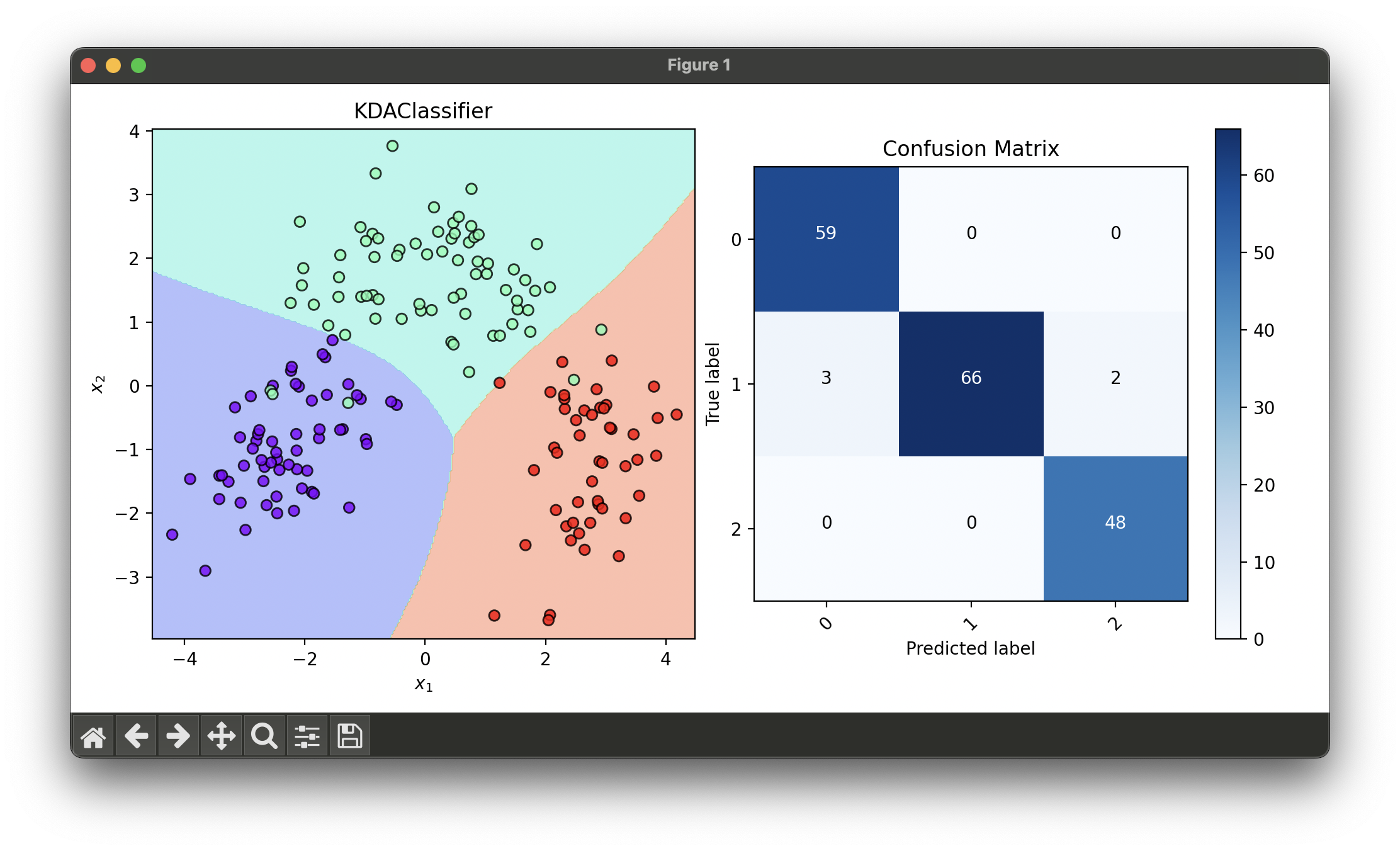
Kernel Discriminant Analysis (KDA), also known as Kernel Fisher Discriminant Analysis, is a nonlinear generalization of Linear Discriminant Analysis.
5.[Classifier] Logistic Regression
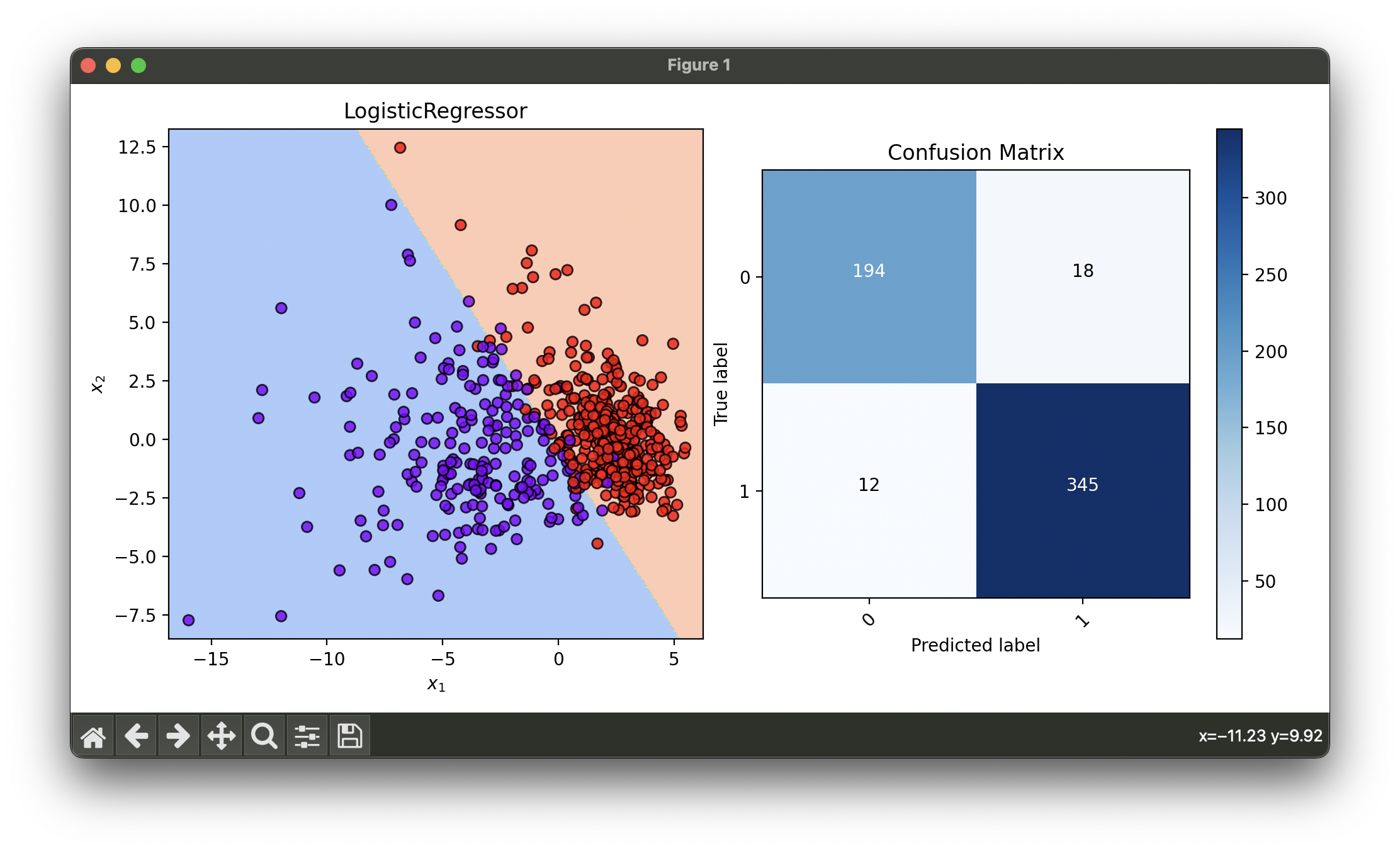
Logistic Regression is a statistical method for analyzing datasets in which there are one or more independent variables that determine an outcome.
6.[Classifier] Softmax Regression
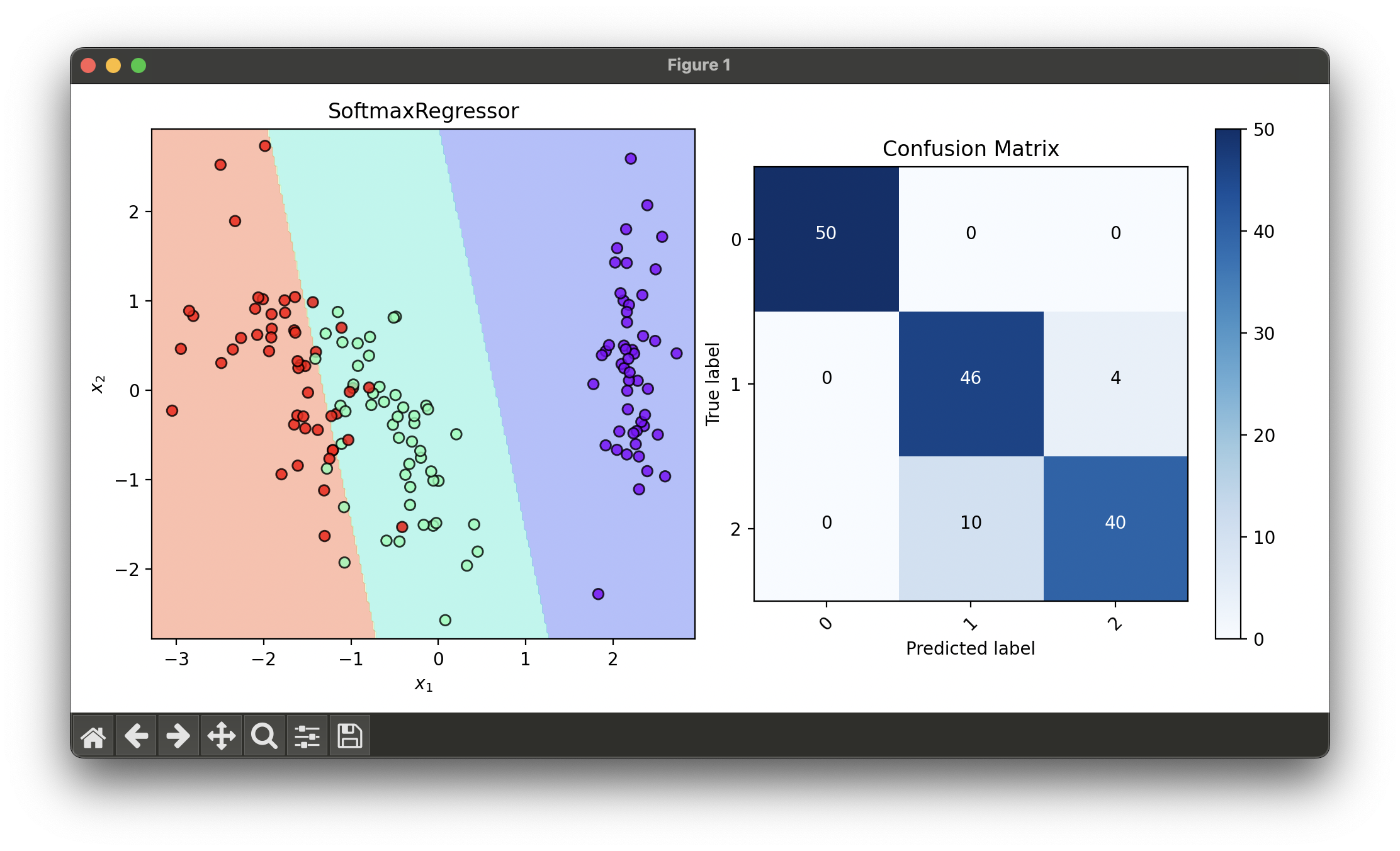
Softmax Regression, commonly known as Multinomial Logistic Regression, is a generalization of logistic regression.
7.[Classifier] Gaussian Naive Bayes
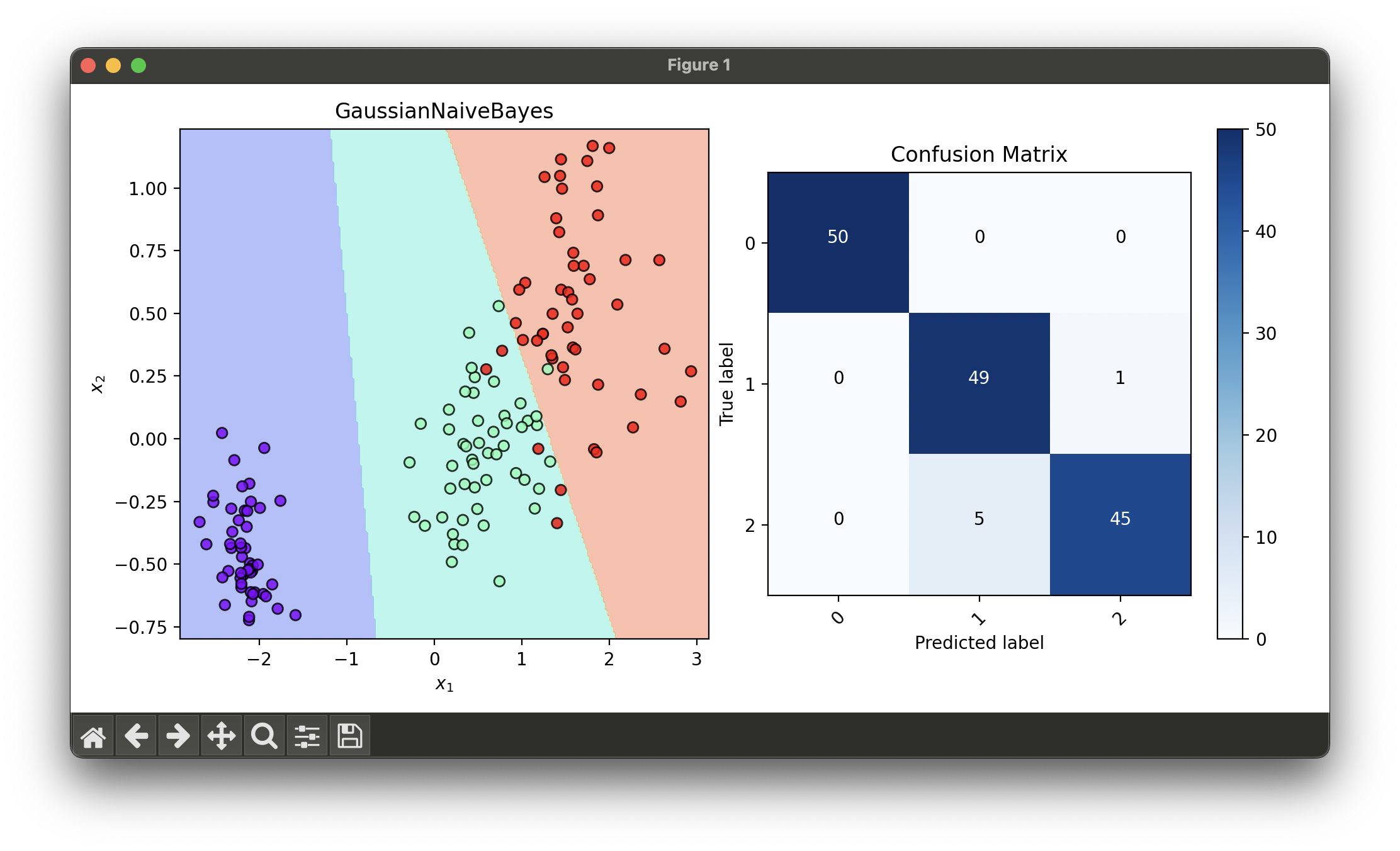
Gaussian Naive Bayes is a variant of Naive Bayes that assumes the likelihood of the features is Gaussian.
8.[Classifier] Bernoulli Naive Bayes
Bernoulli Naive Bayes is a variant of the Naive Bayes algorithm, designed specifically for binary/boolean features.
9.[Classifier] K-Nearest Neighbors (KNN)
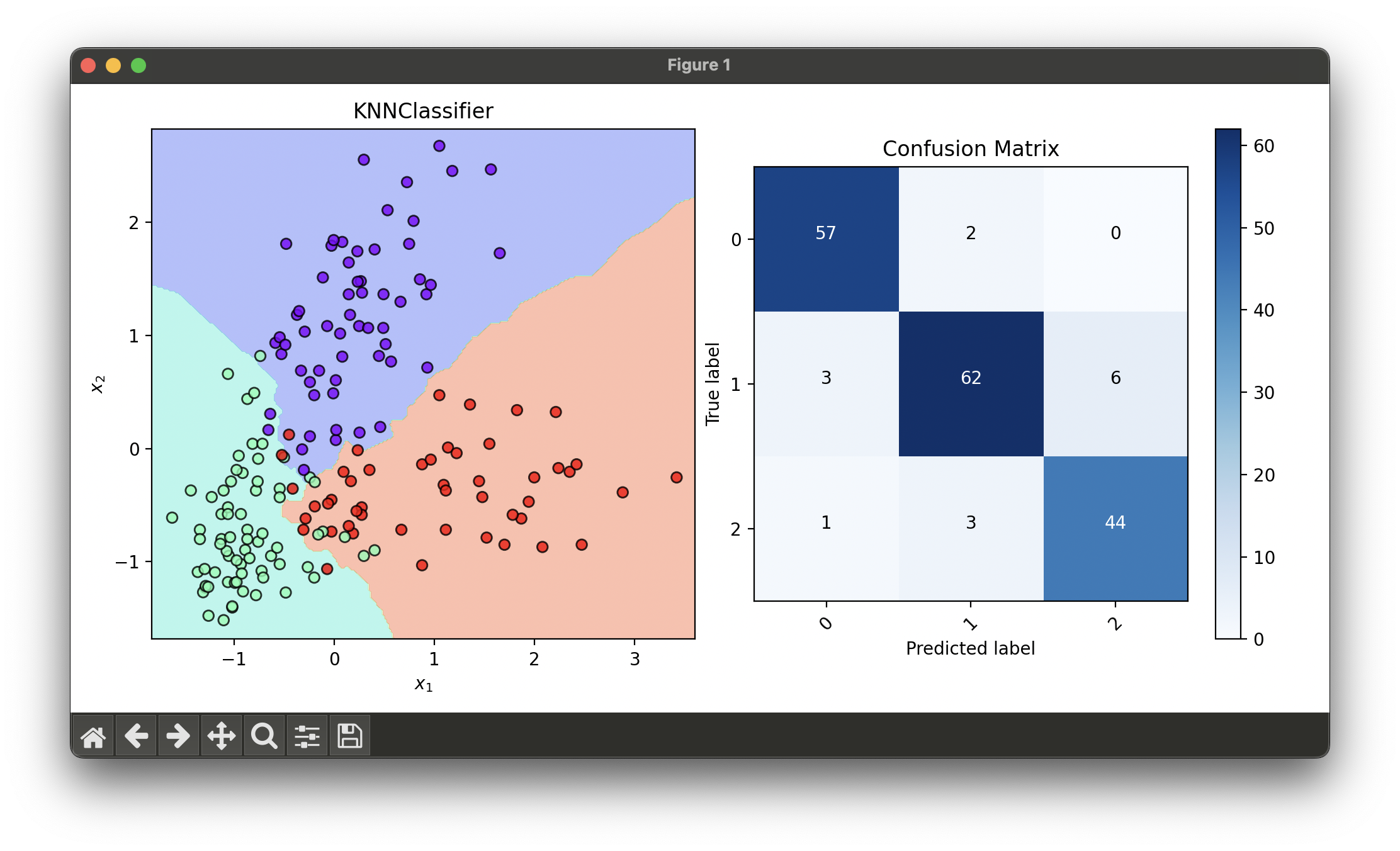
The K-Nearest Neighbors (KNN) classifier is a type of instance-based learning, or lazy learning, where the function is only approximated locally.
10.[Classifier] Adaptive K-Nearest Neighbors (AdaKNN)
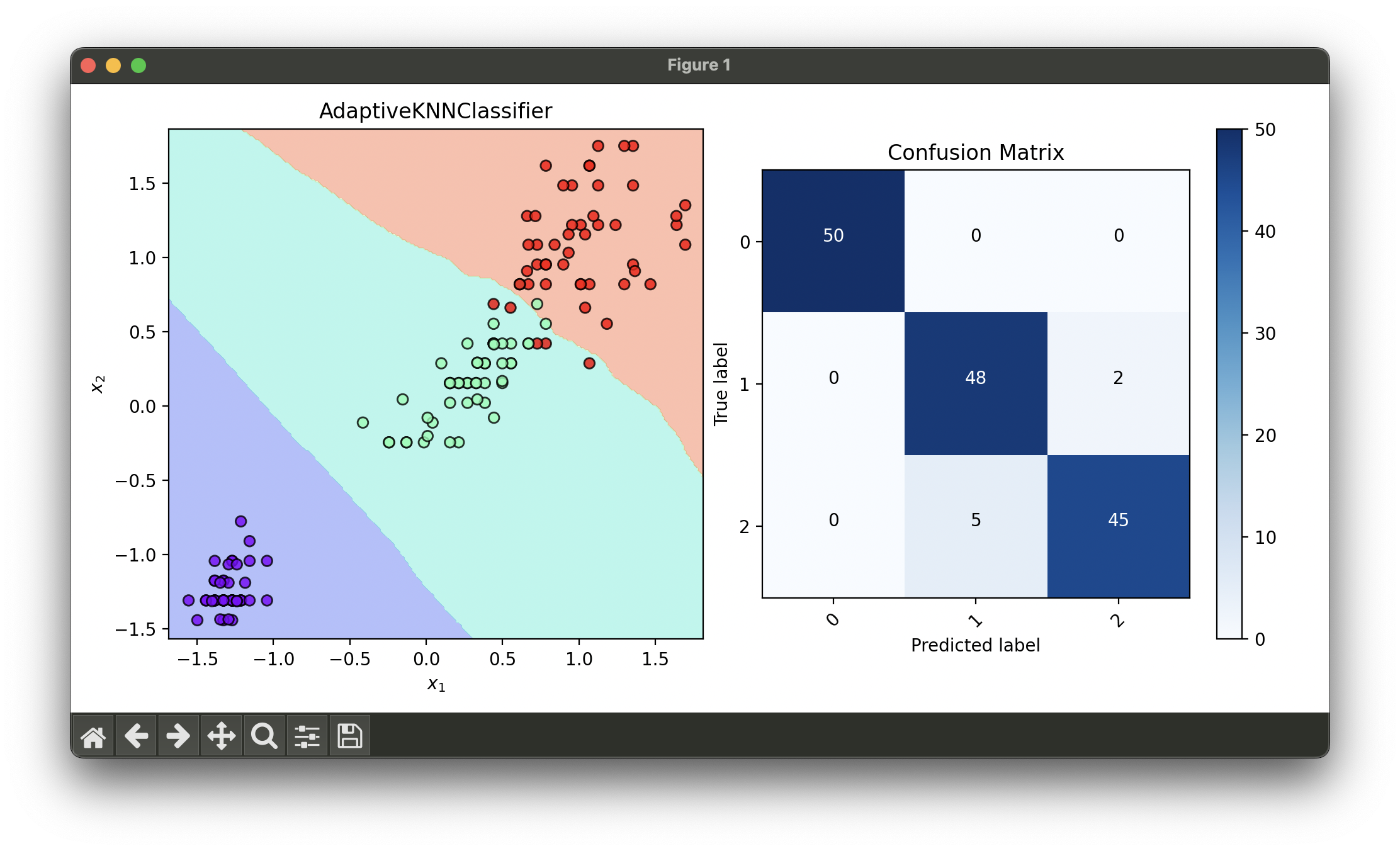
The Adaptive KNN Classifier is an extension of the traditional k-NN algorithm, which is widely used for classification and regression.
11.[Classifier] Weighted K-Nearest Neighbors
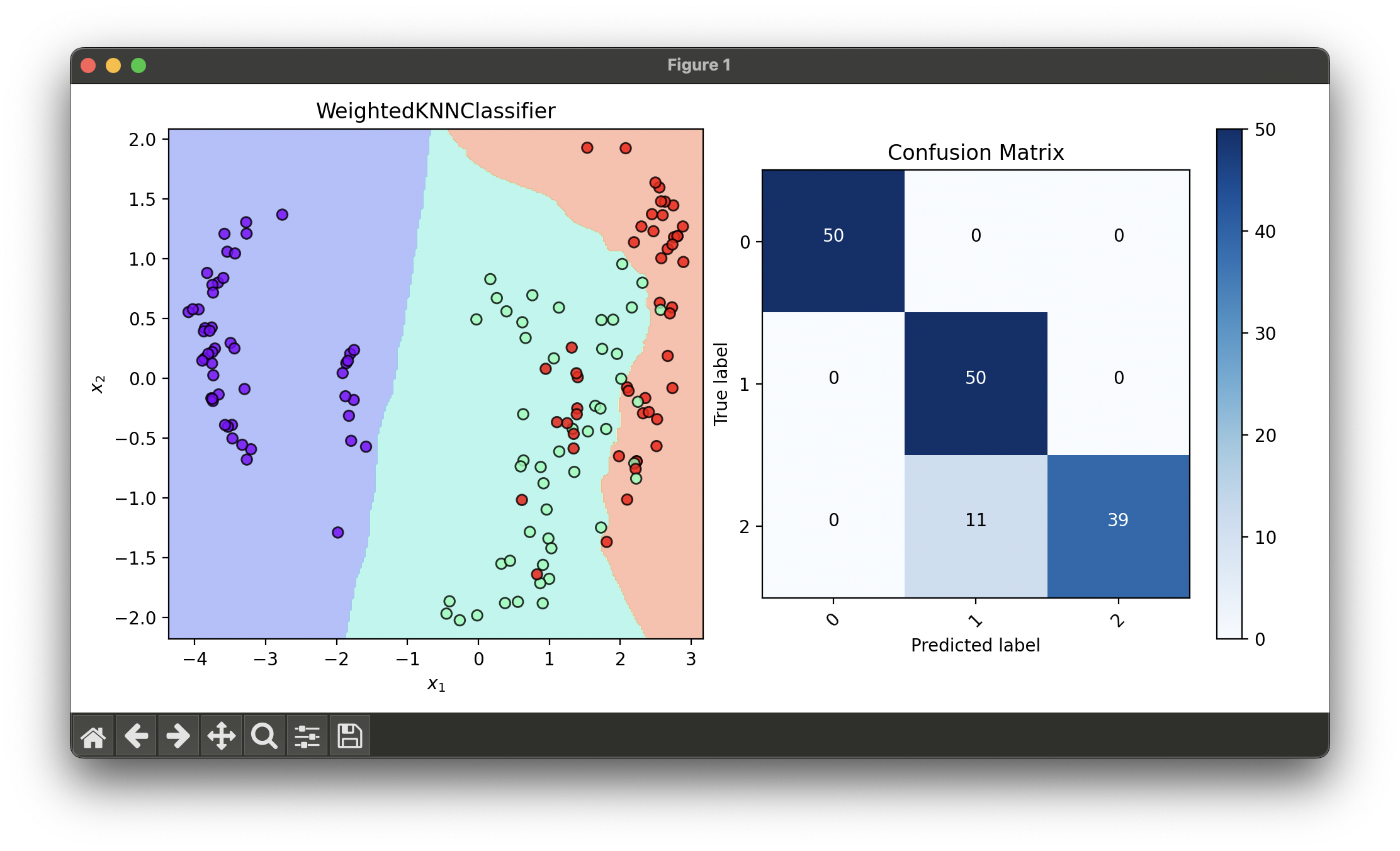
The Weighted KNN Classifier enhances the conventional KNN algorithm by introducing a weighting scheme for the neighbors based on their distance.
12.[Classifier] Support Vector Classification (SVC)
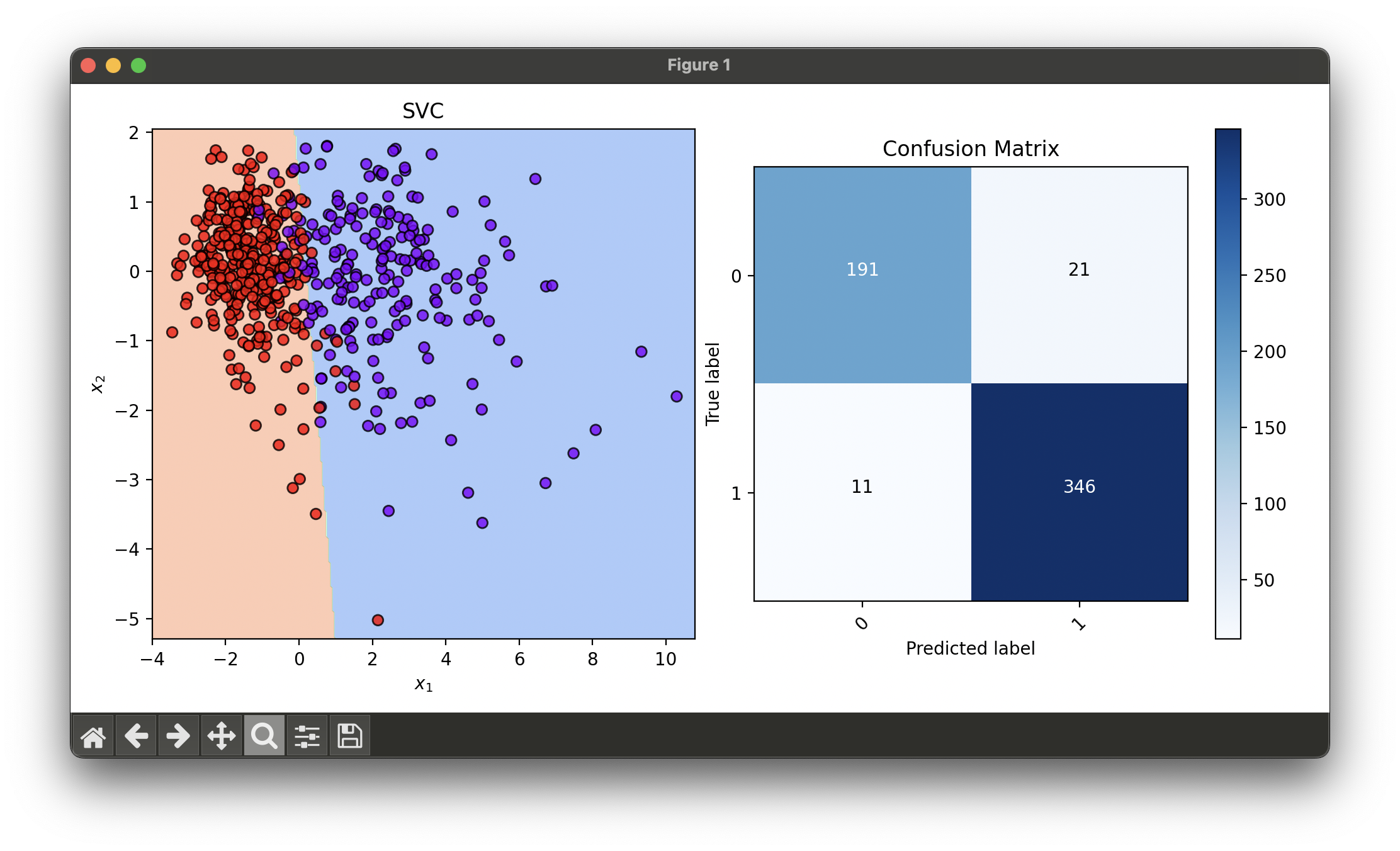
The Linear SVC is a powerful linear model for classification tasks, derived from the Support Vector Machine (SVM) framework.
13.[Classifier] Kernel Support Vector Classification
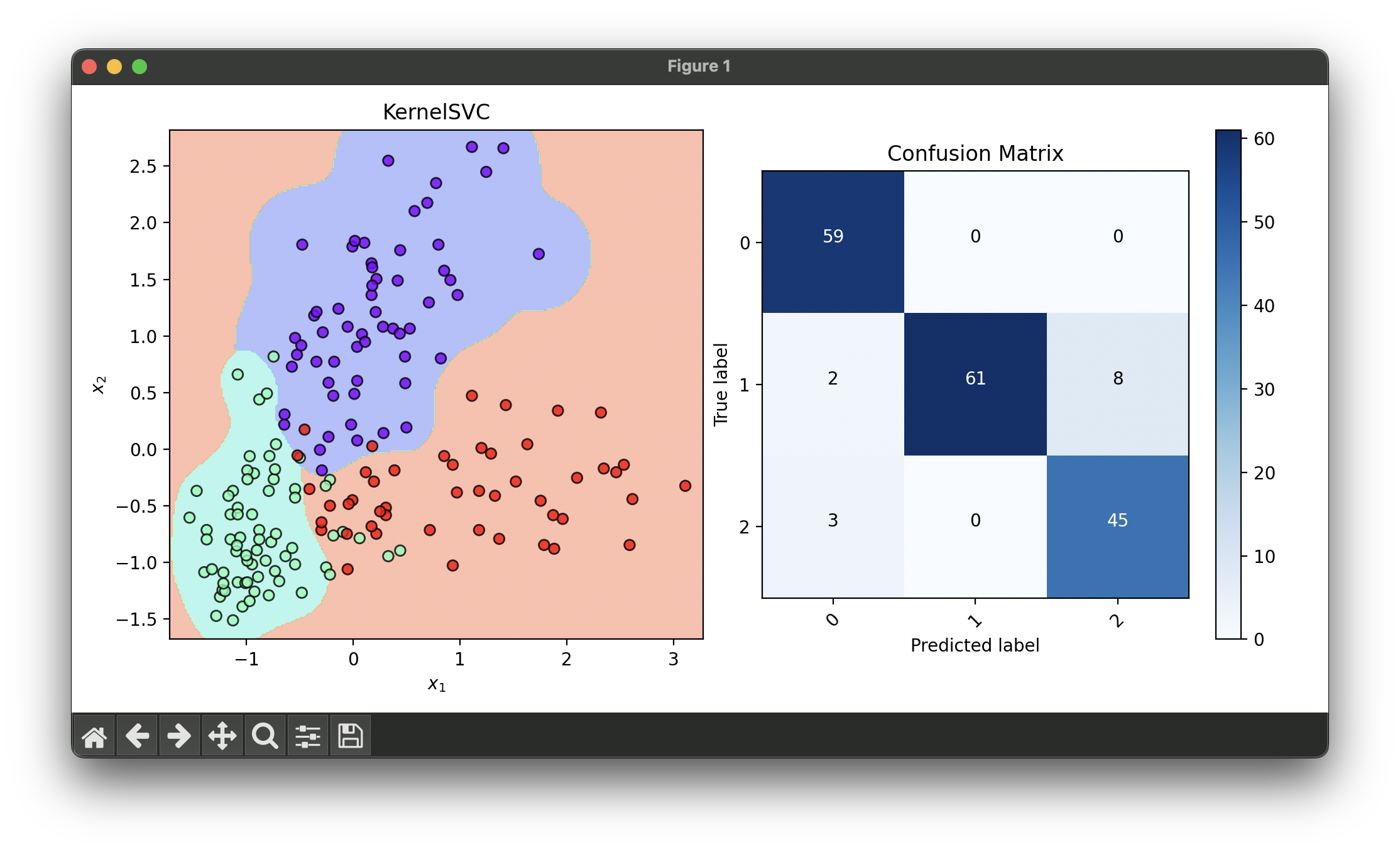
Kernel Support Vector Classifier (SVC) extends the Support Vector Machine (SVM) concept to handle non-linear data by applying kernel functions.
14.[Classifier] Decision Tree Classifier
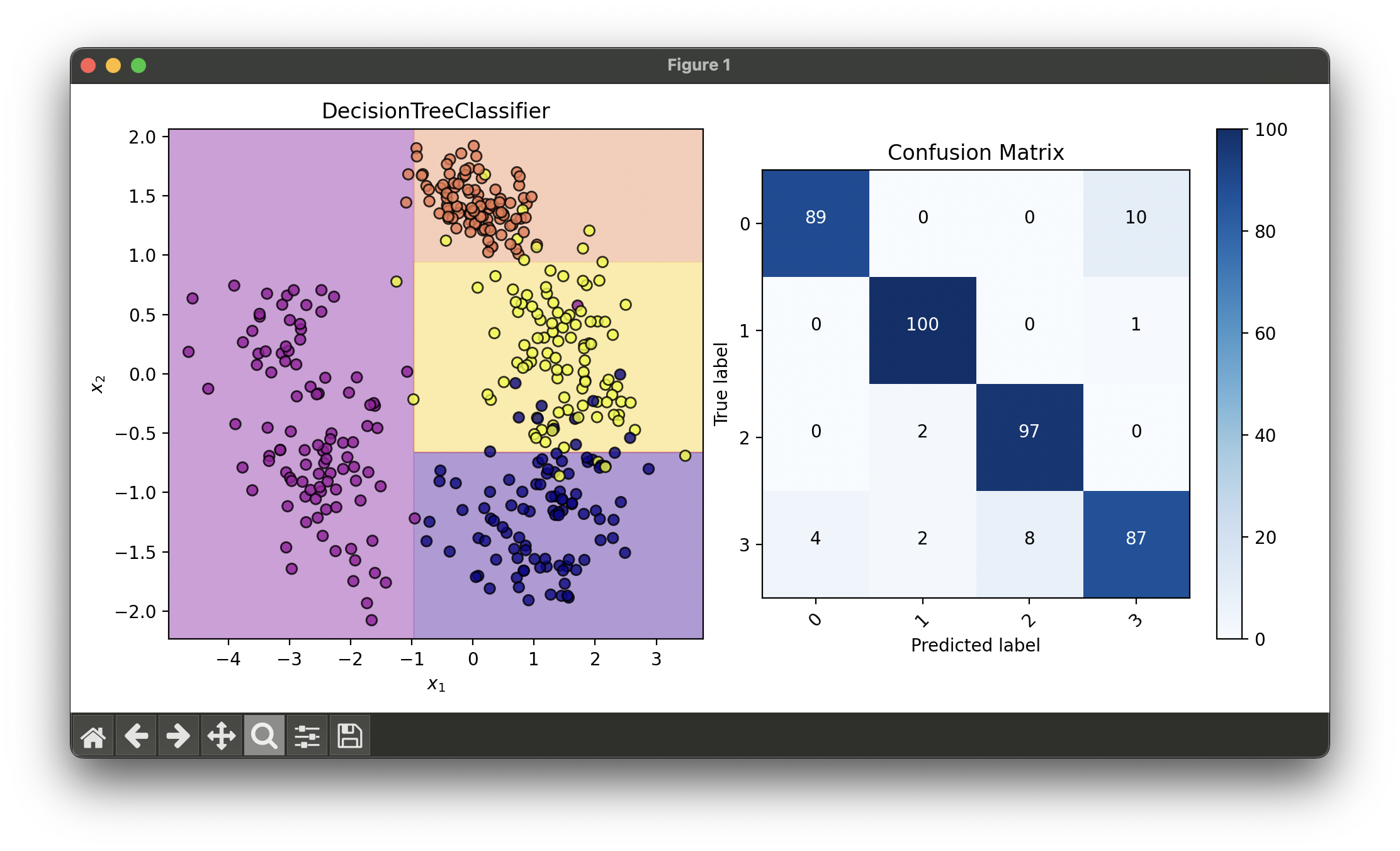
A Decision Tree Classifier is a non-parametric supervised learning method used for classification and regression tasks.
15.[Clustering] Affinity Propagation (AP)
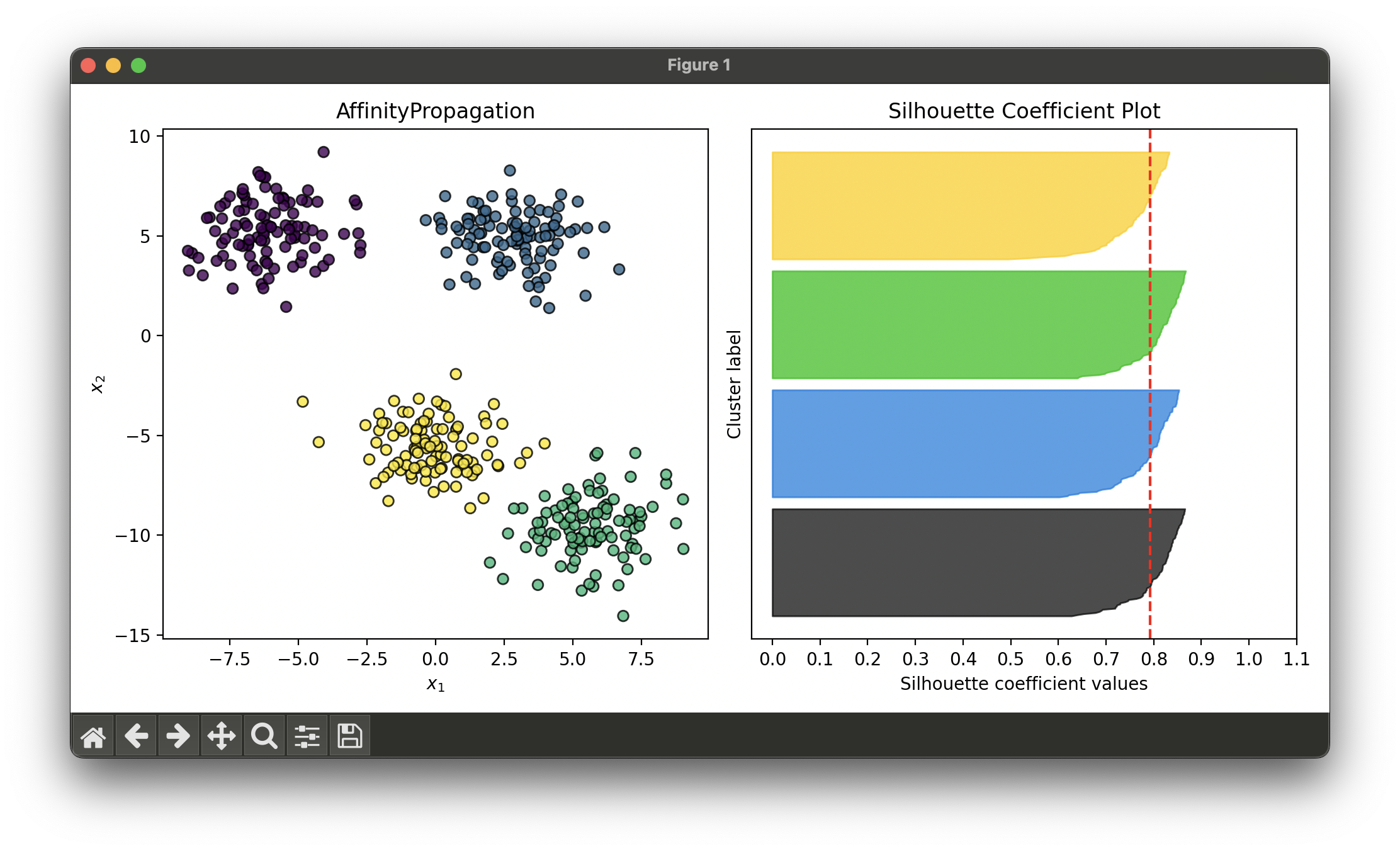
Affinity Propagation (AP) is a clustering algorithm introduced by Brendan J. Frey and Delbert Dueck in 2007.
16.[Clustering] Adaptive Affinity Propagation (AAP)
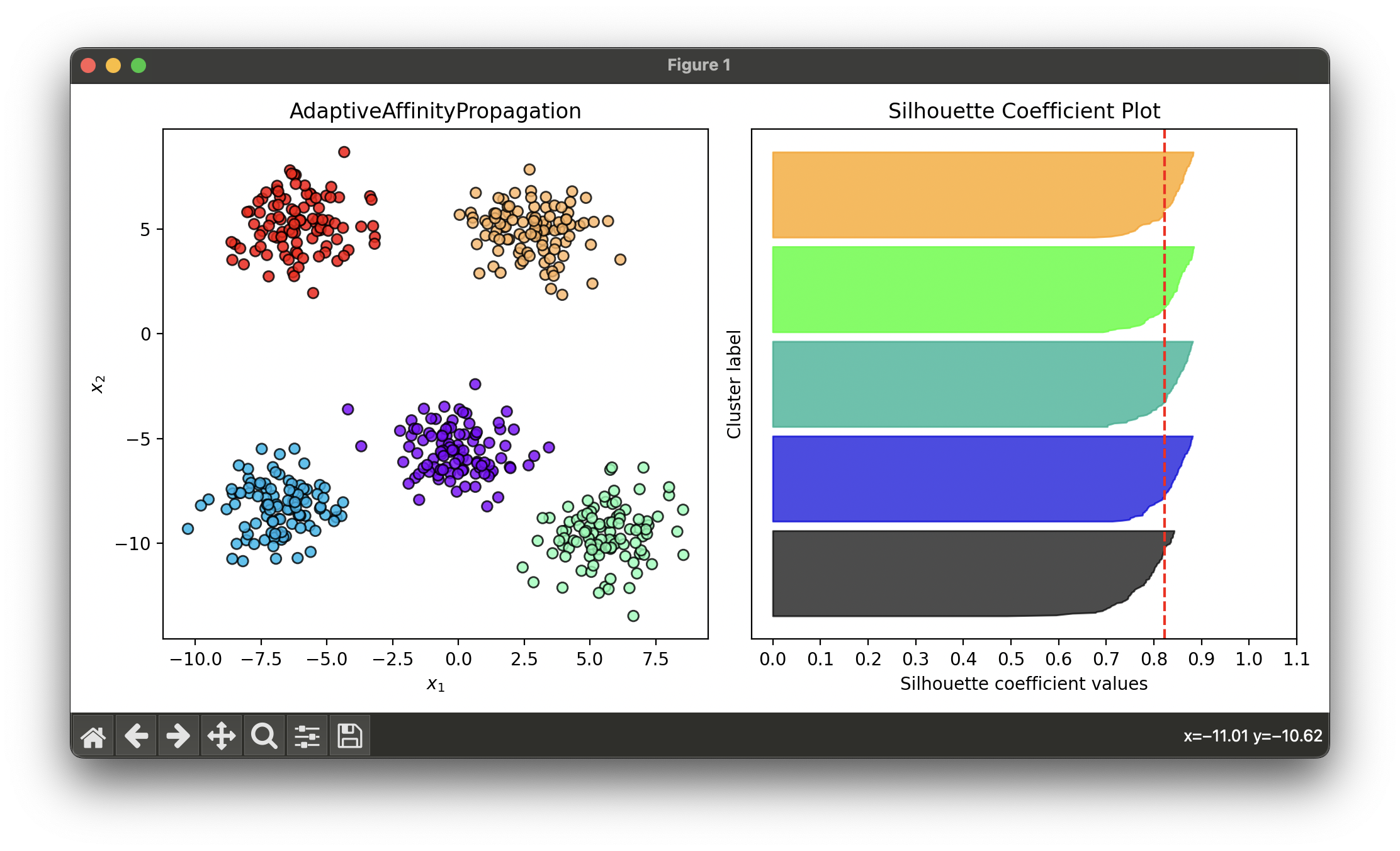
Adaptive Affinity Propagation is an extension of the Affinity Propagation algorithm that introduces mechanisms to dynamically adjust the preference.
17.[Clustering] Kernel Affinity Propagation (KAP)
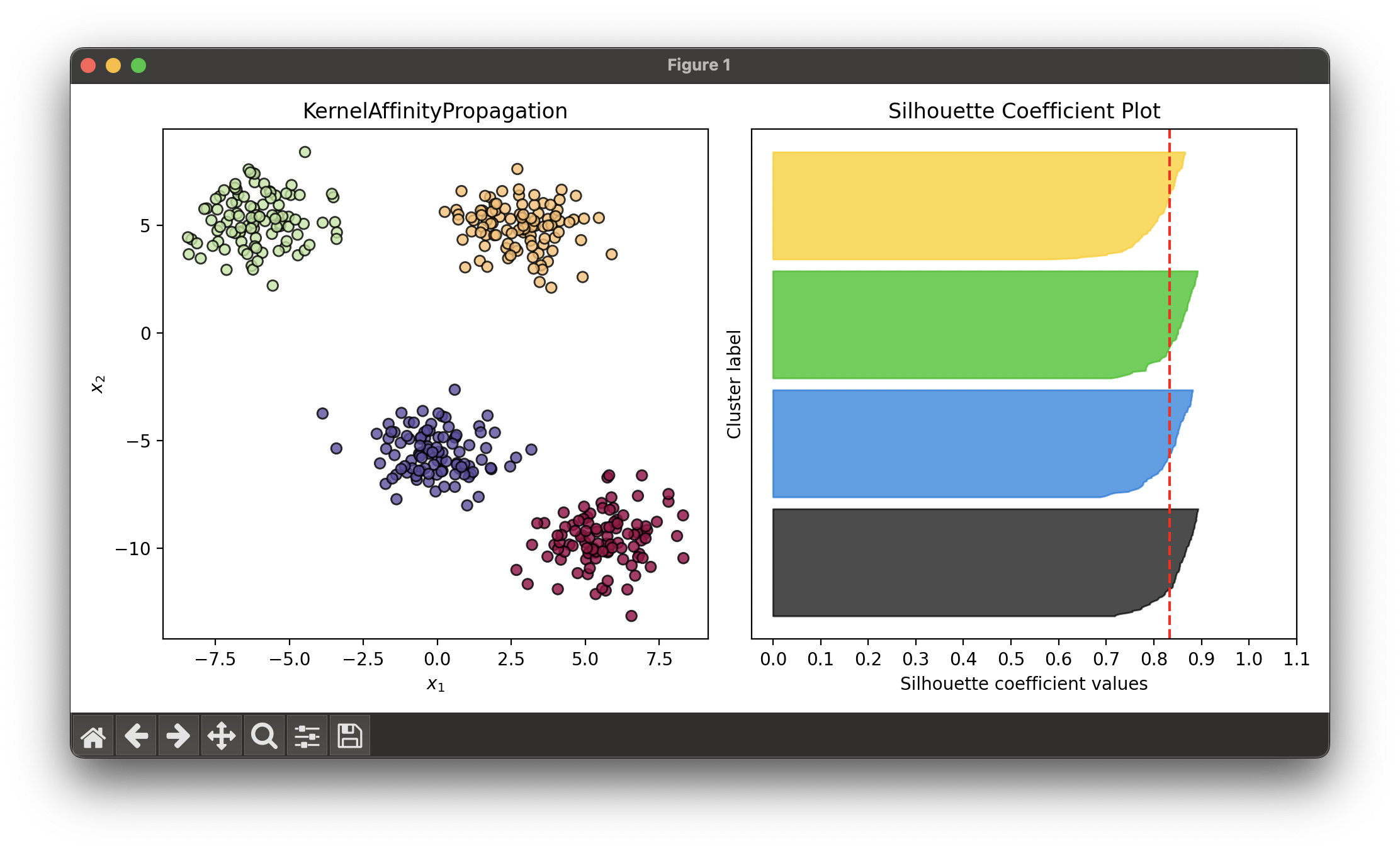
Kernel Affinity Propagation extends the Affinity Propagation clustering algorithm by incorporating kernel methods to handle non-linear data.
18.[Clustering] DBSCAN
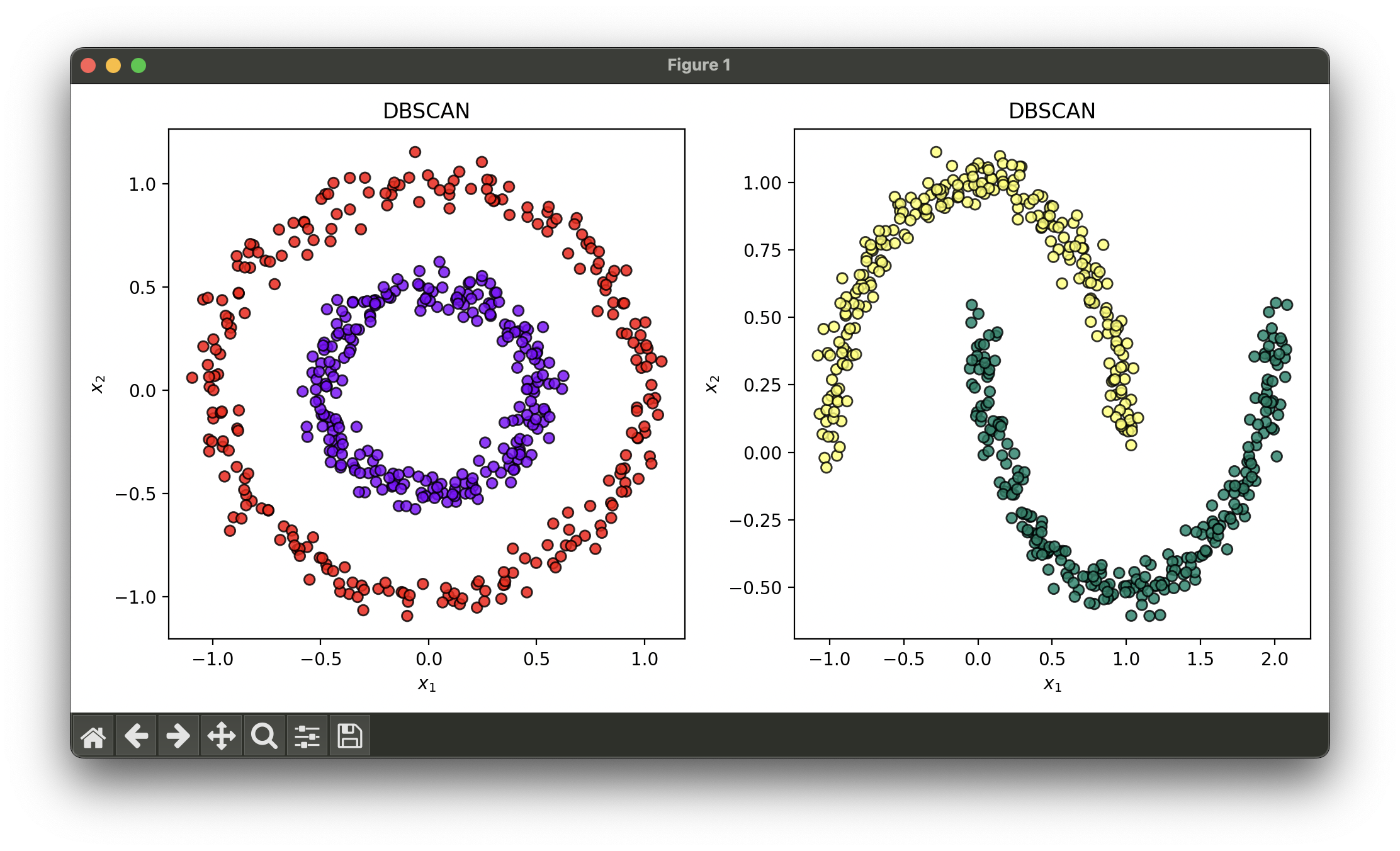
DBSCAN is a popular clustering algorithm that is notable for its ability to find clusters of varying shapes and sizes in a dataset with noise.
19.[Clustering] OPTICS
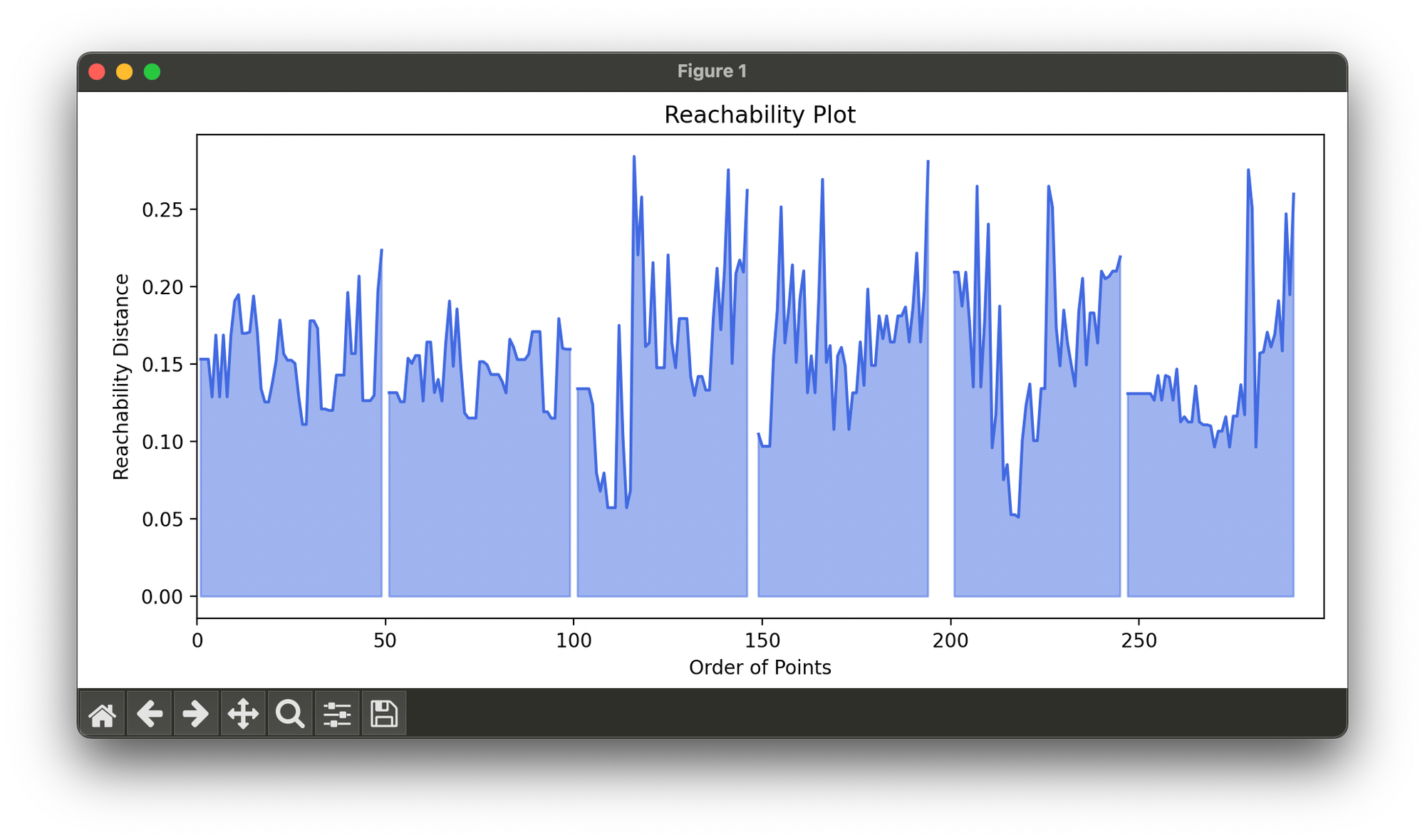
The OPTICS algorithm addresses one of DBSCAN's main limitations: the difficulty of identifying clusters of varying density.
20.[Clustering] DENCLUE
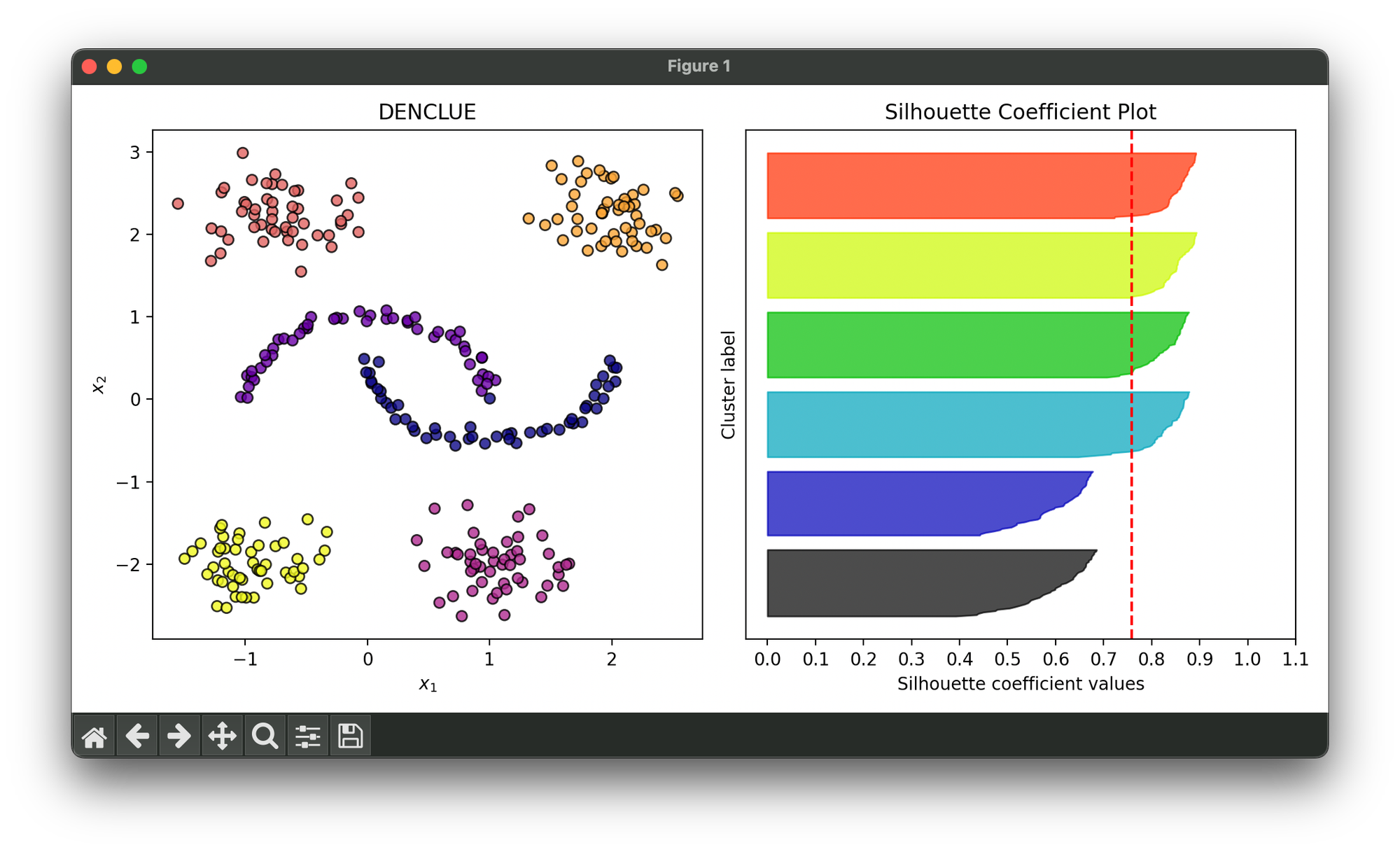
DENCLUE is an advanced clustering algorithm that leverages the concept of density functions to identify cluster structures within a dataset.
21.[Clustering] Mean Shift Clustering
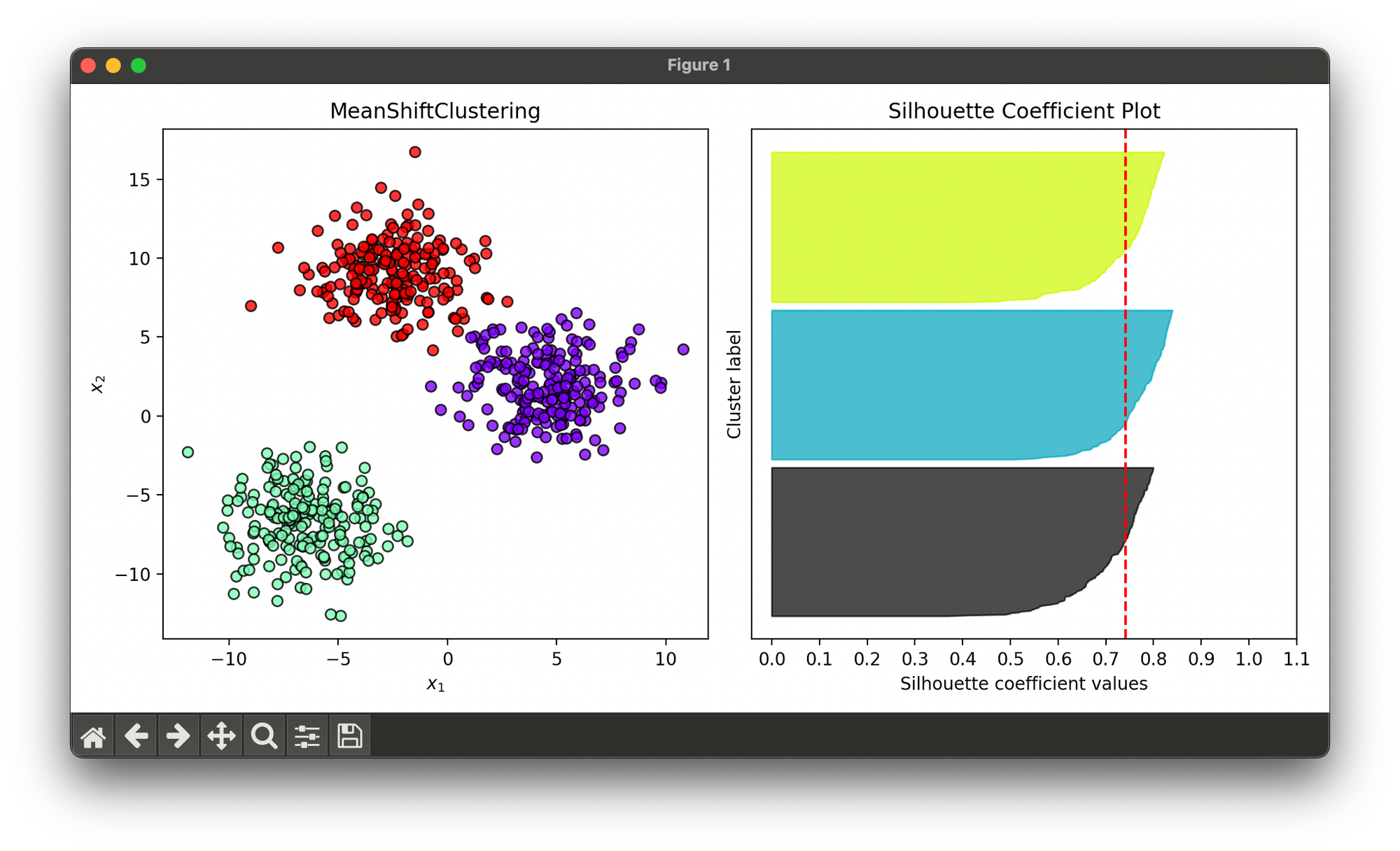
Mean Shift Clustering is a non-parametric, iterative algorithm that locates the maxima of a density function given discrete data.
22.[Clustering] Agglomerative Clustering
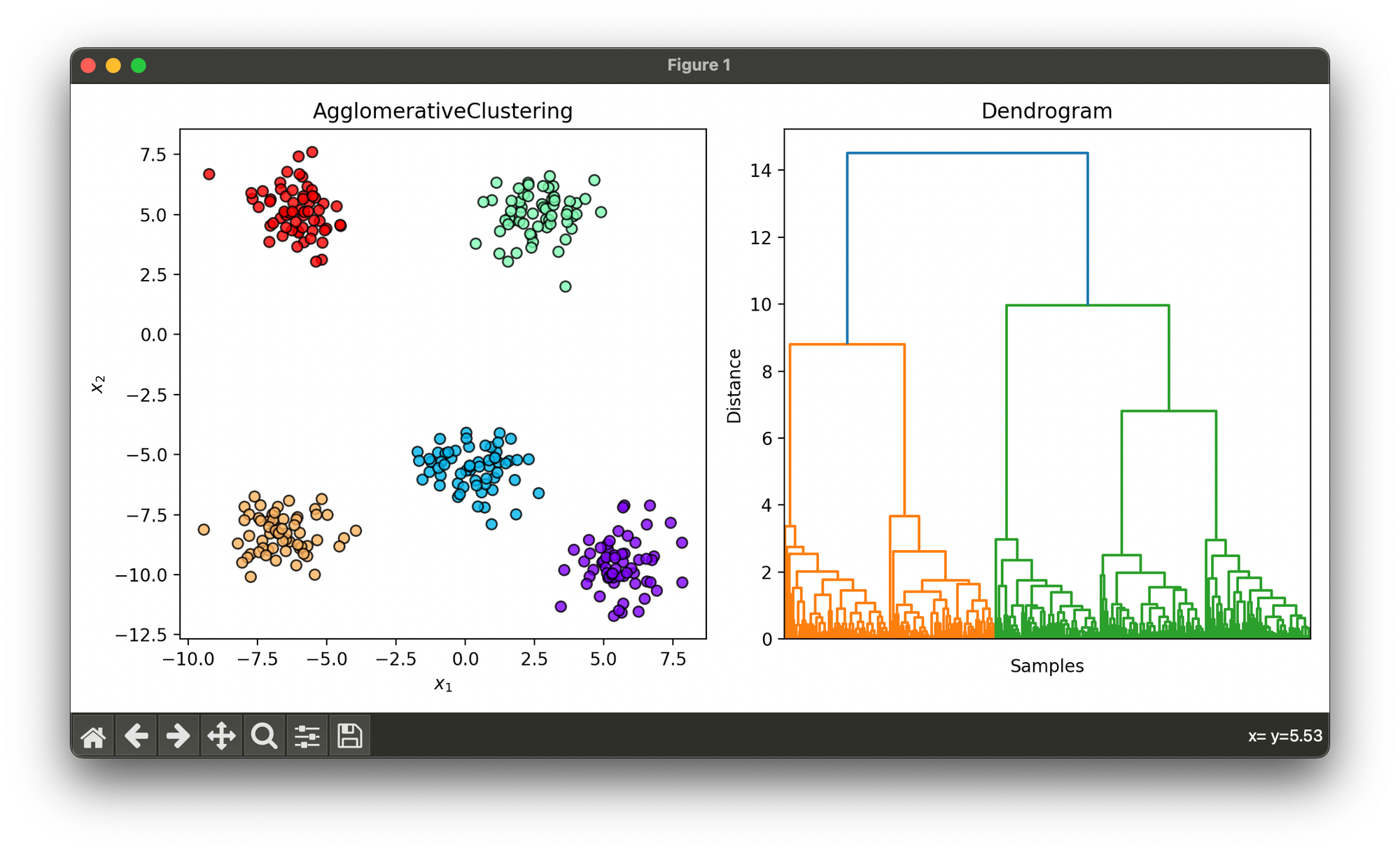
Agglomerative Clustering is a type of hierarchical clustering method used to group objects in clusters based on their similarity.
23.[Clustering] Divisive Clustering
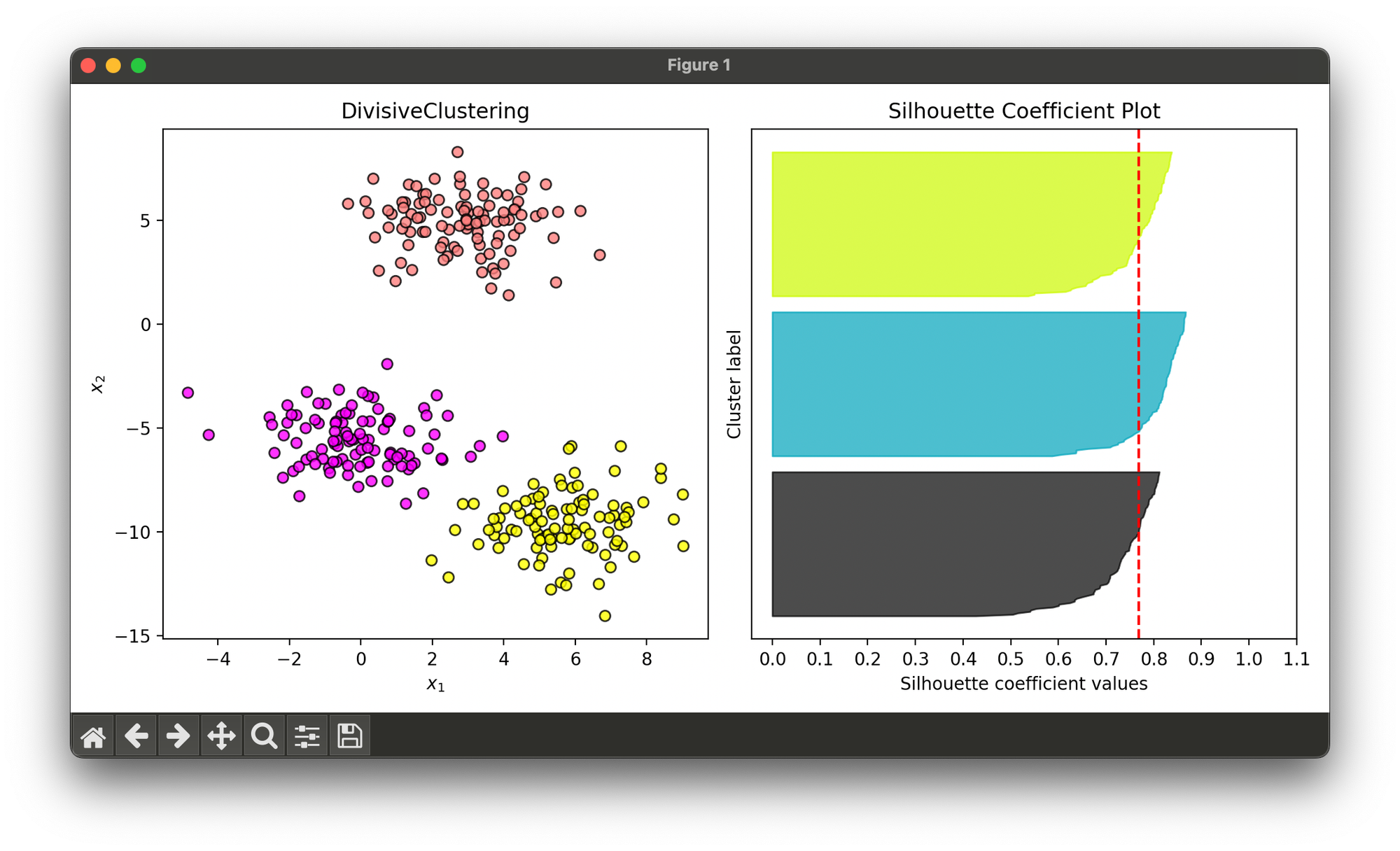
Divisive clustering, also known as DIvisive ANAlysis clustering (DIANA), is a top-down clustering method used in machine learning and data mining.
24.[Clustering] K-Means Clustering
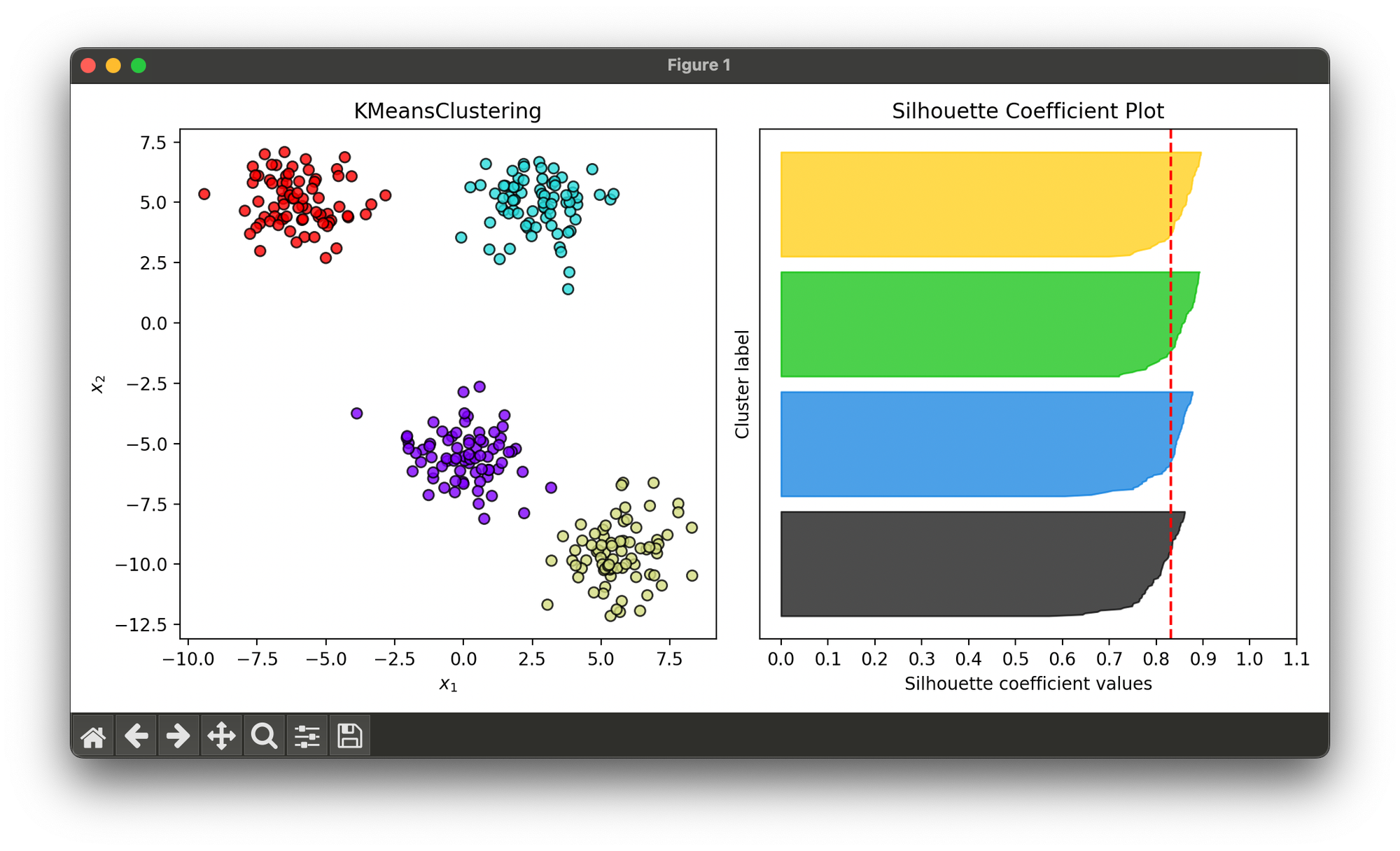
K-means clustering is a popular unsupervised learning algorithm used to partition n observations into k clusters.
25.[Clustering] K-Means++ Clustering
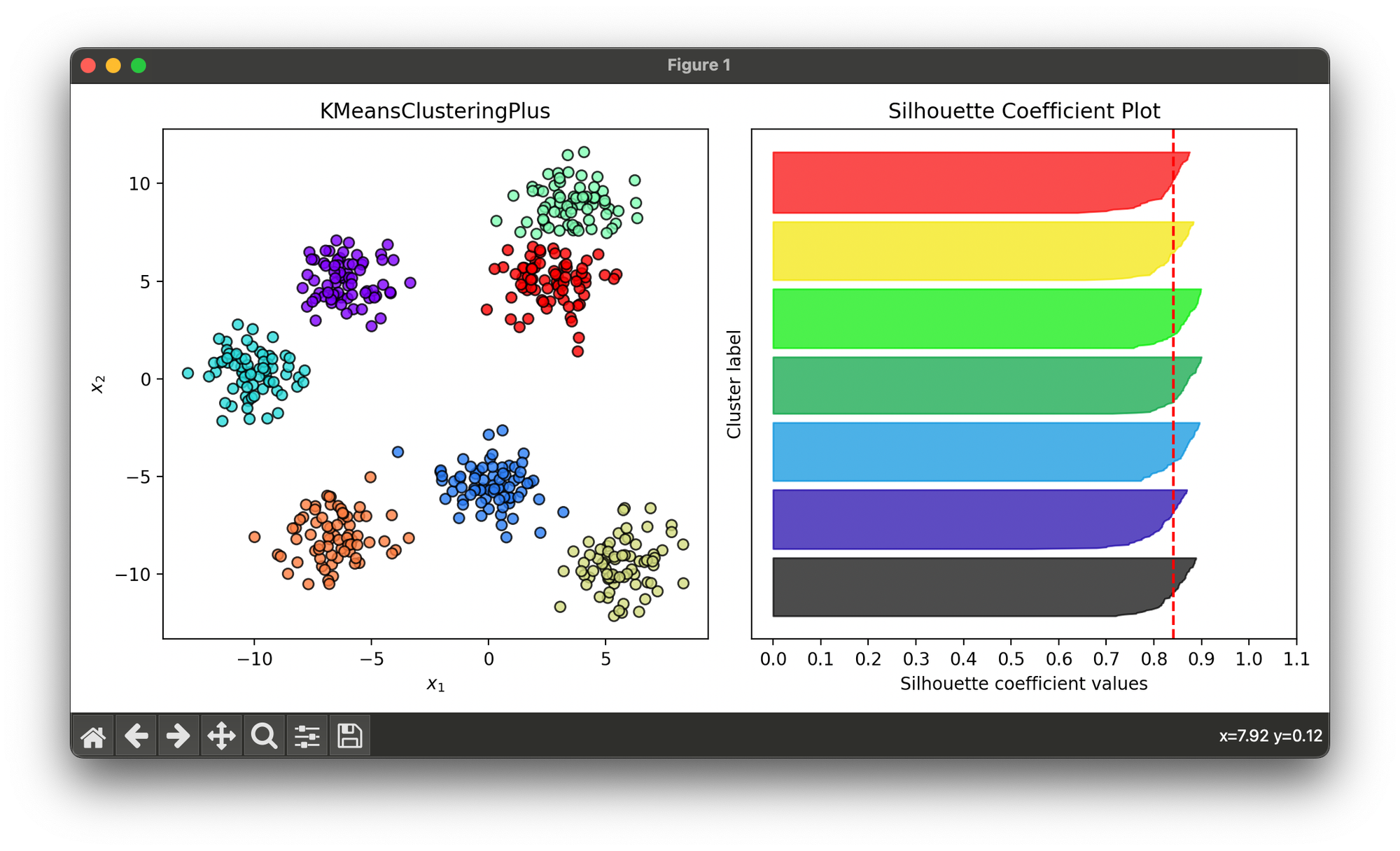
K-means++ enhances the initialization phase of the K-means clustering algorithm, which partitions n observations into k clusters based on their probs.
26.[Clustering] K-Medians Clustering
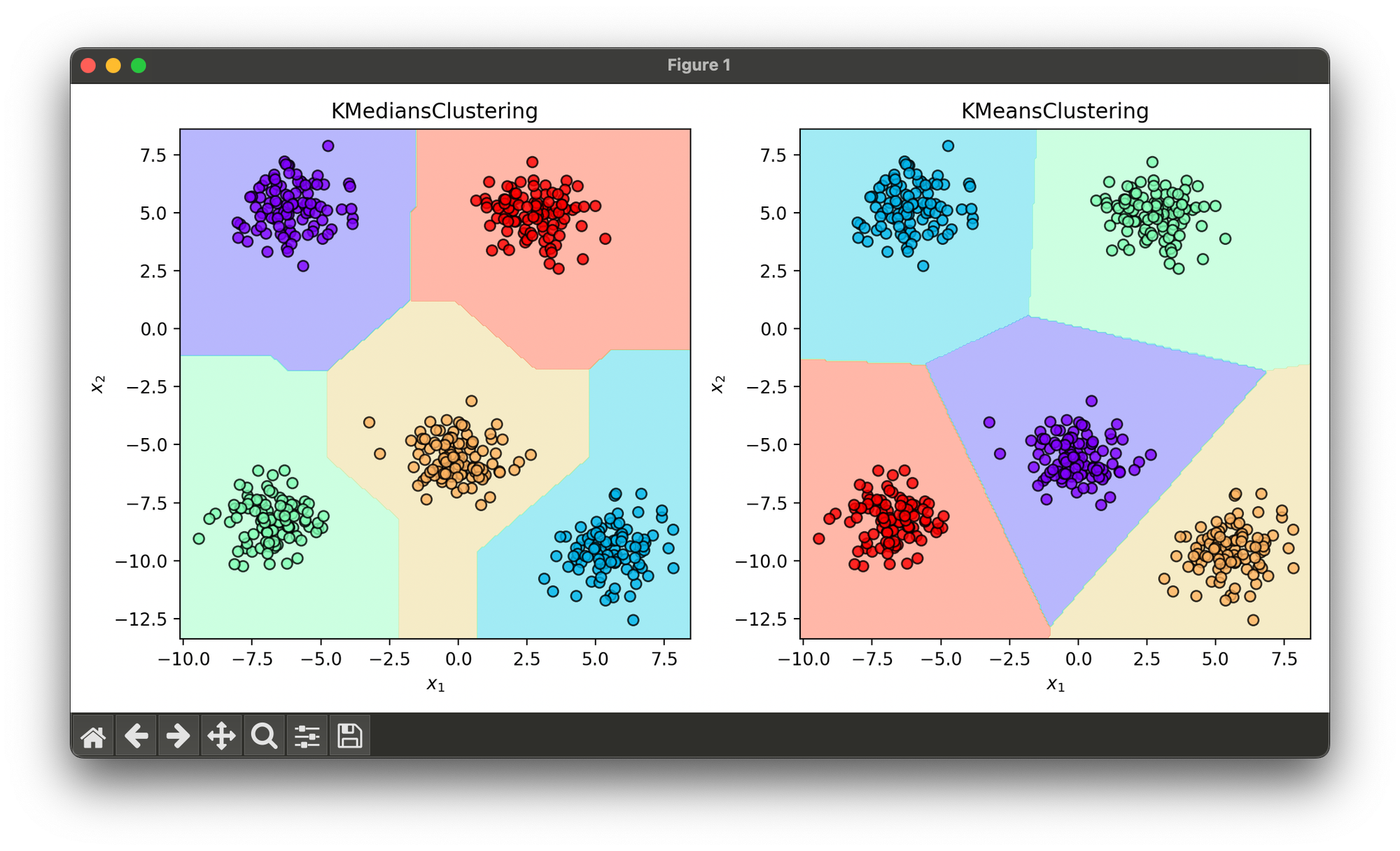
K-Medians clustering is a partitioning technique that divides a dataset into K groups or clusters by minimizing the median distance between points.
27.[Clustering] K-Medoids Clustering
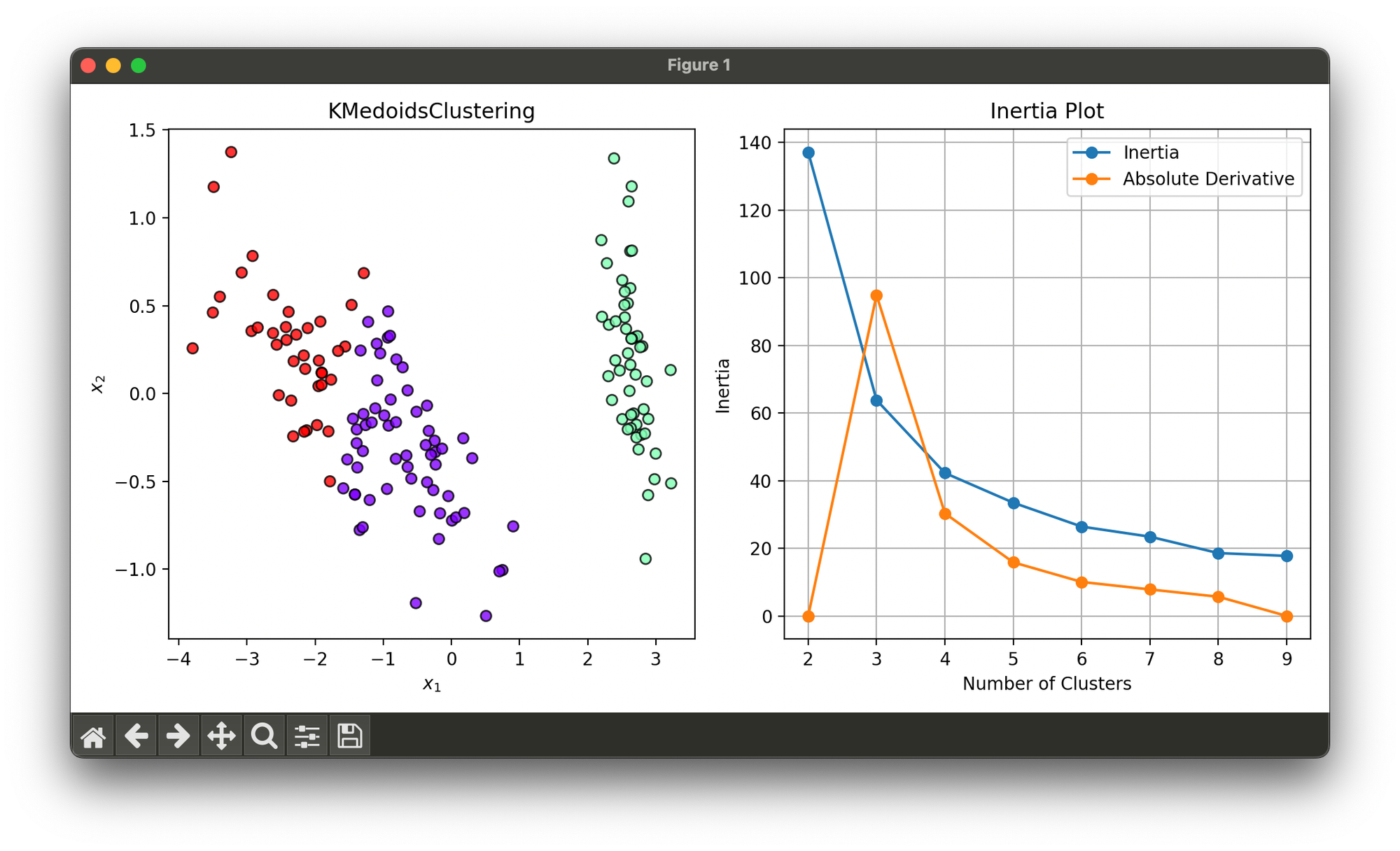
K-Medoids is a clustering algorithm similar to K-Means, with the primary difference being the choice of centroids.
28.[Clustering] Mini Batch K-Means Clustering
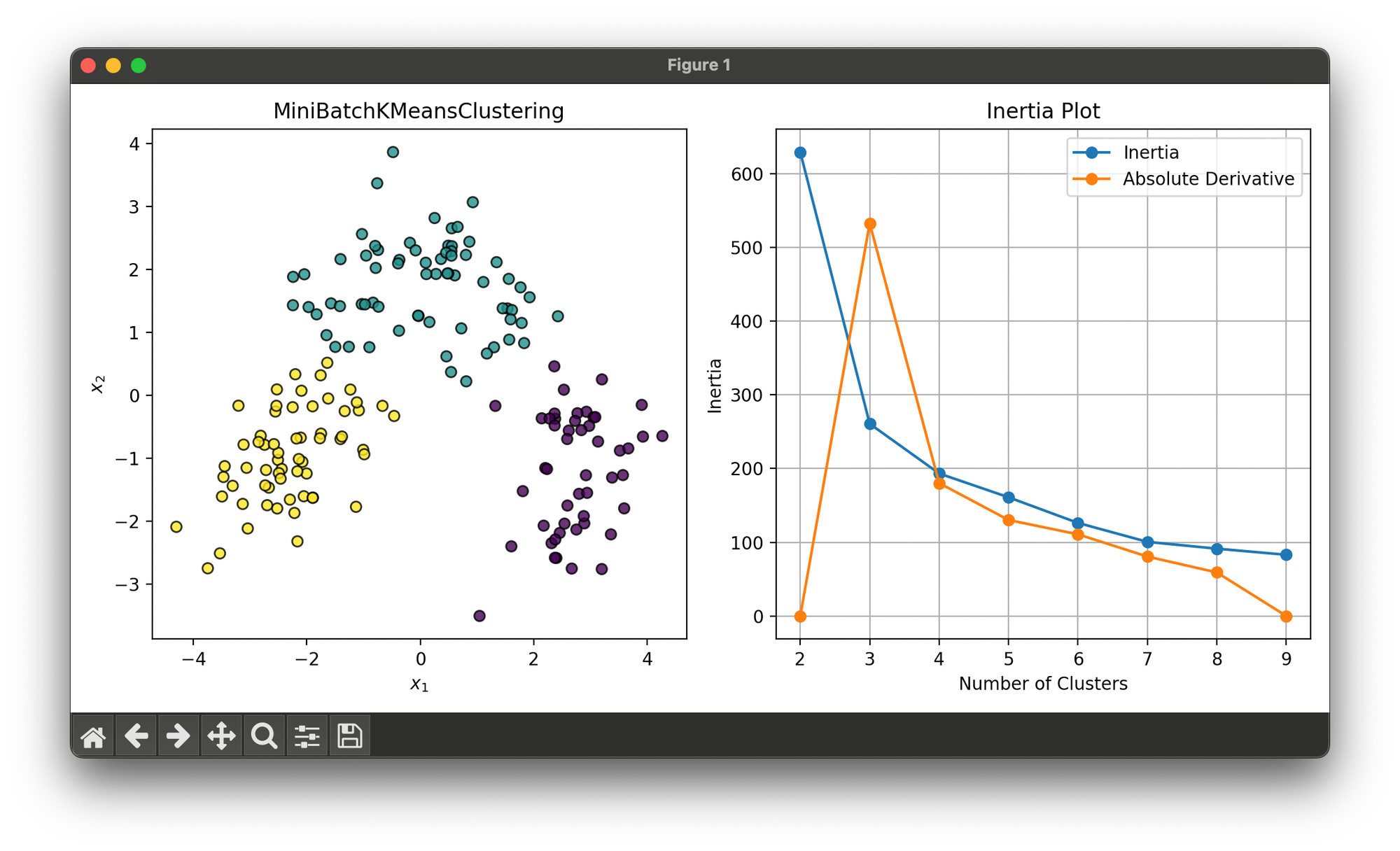
Mini-Batch K-Means is a variant of the K-Means clustering algorithm that aims to reduce the computational cost by using small, random samples.
29.[Clustering] Fuzzy C-Means Clustering
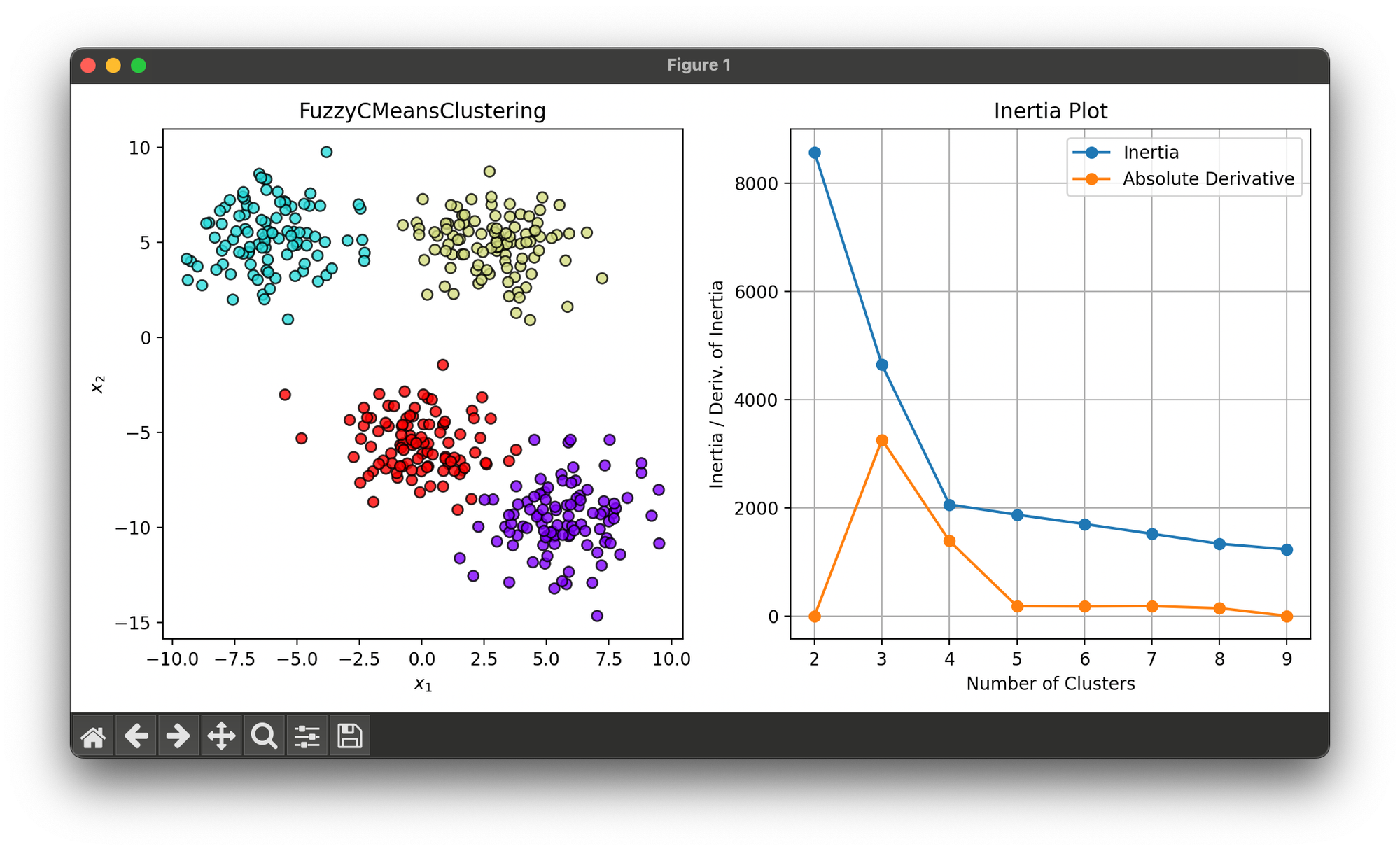
Fuzzy C-Means (FCM) is an extension of the traditional K-Means clustering algorithm that allows data points to belong to multiple clusters.
30.[Clustering] Gaussian Mixture Model (GMM)
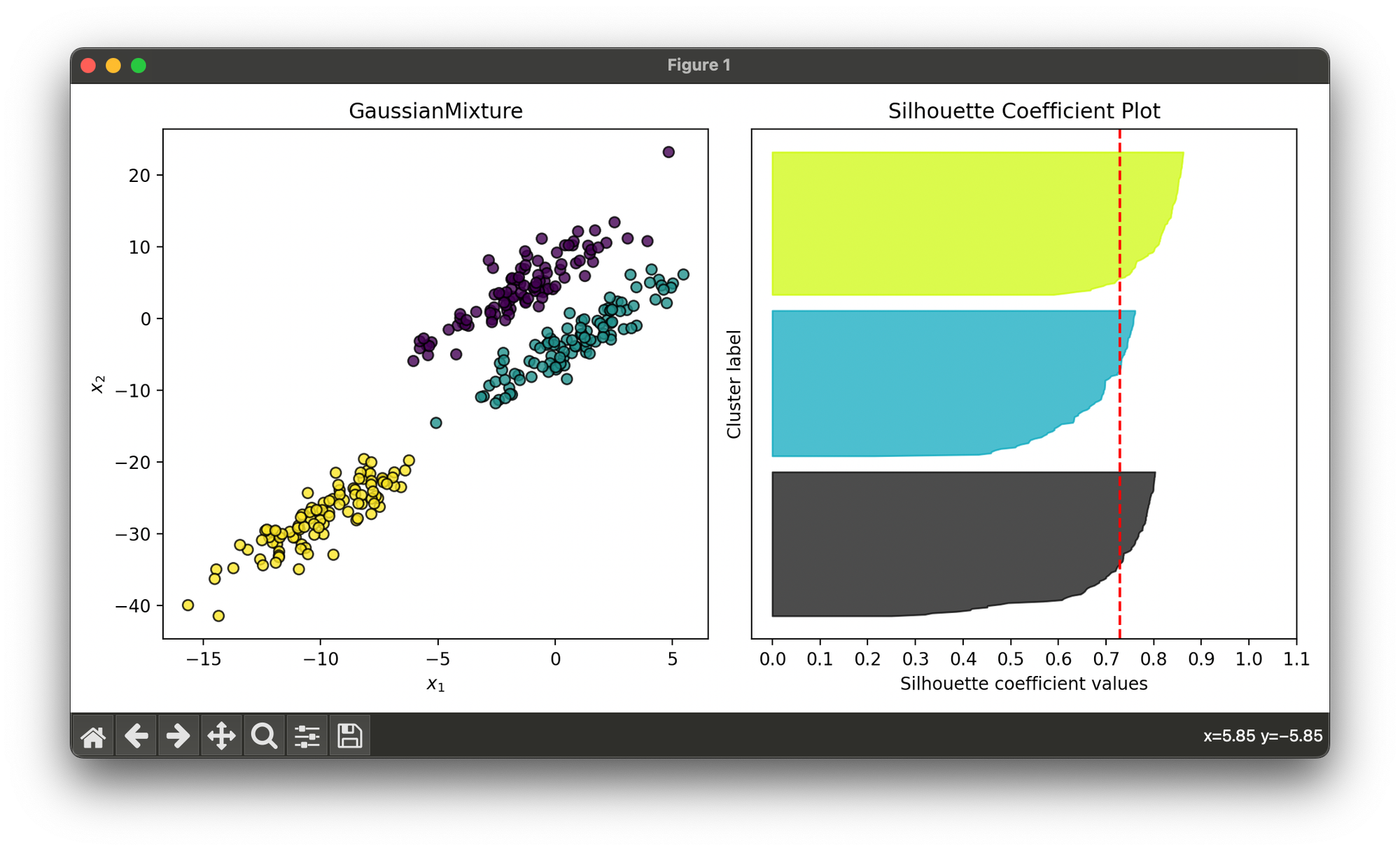
Gaussian Mixture Models (GMMs) are a probabilistic model for representing normally distributed subpopulations within an overall population.
31.[Clustering] Multinomial Mixture Model (MMM)
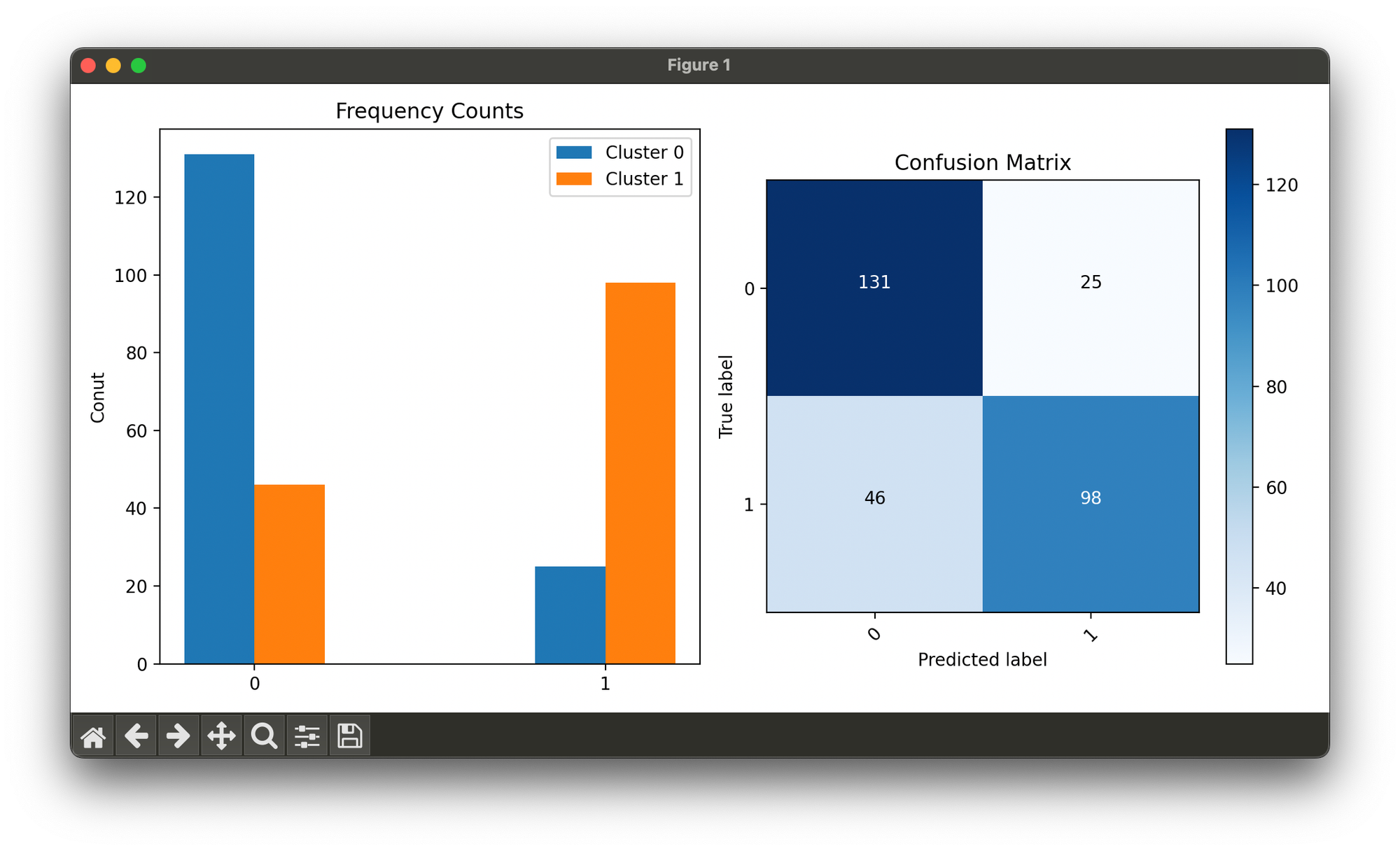
Multinomial Mixture Models are probabilistic models used for clustering categorical data.
32.[Clustering] Spectral Clustering
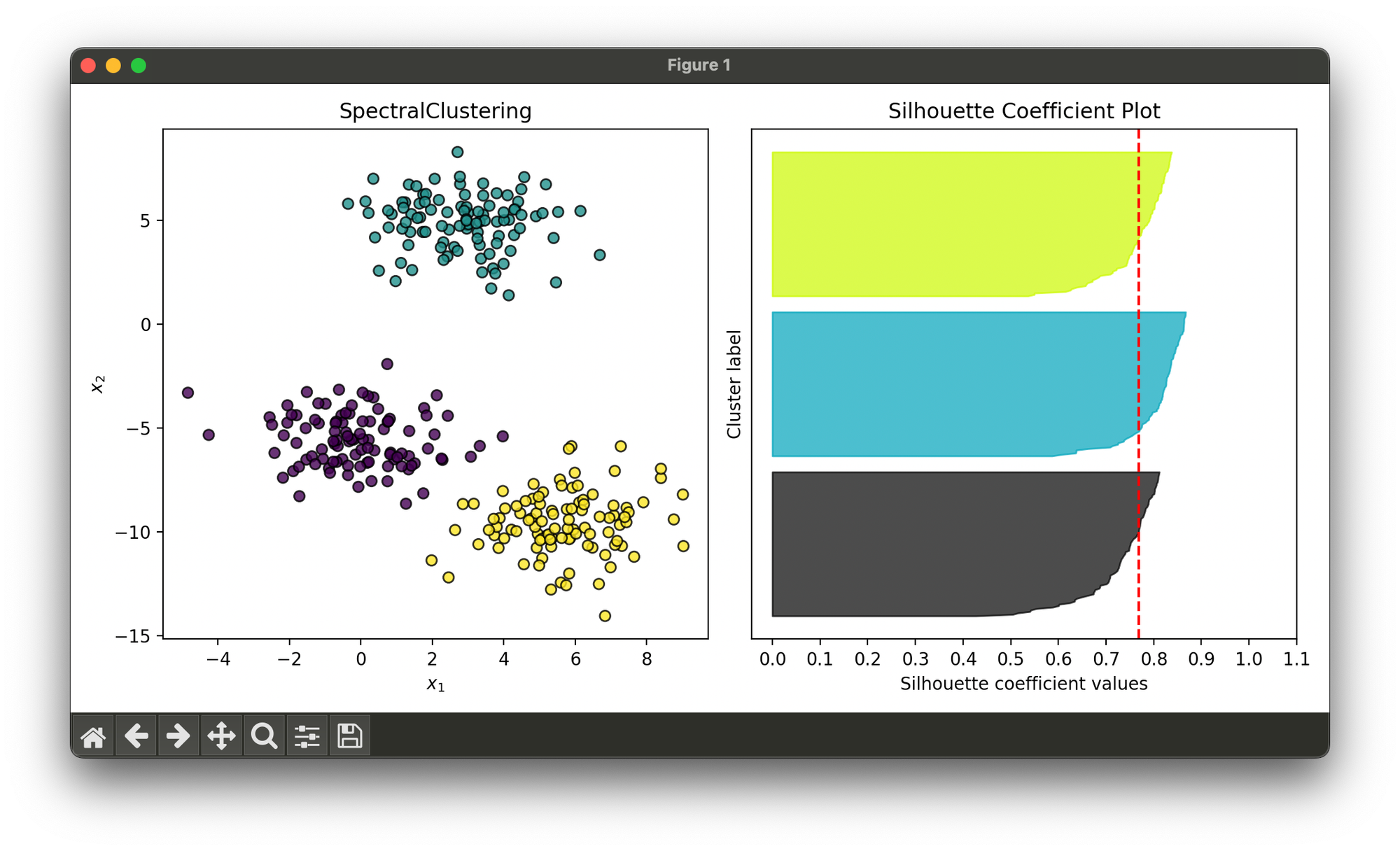
Spectral Clustering is a versatile algorithm for grouping objects in various applications, such as image and social network segmentation.
33.[Clustering] Normalized Spectral Clustering
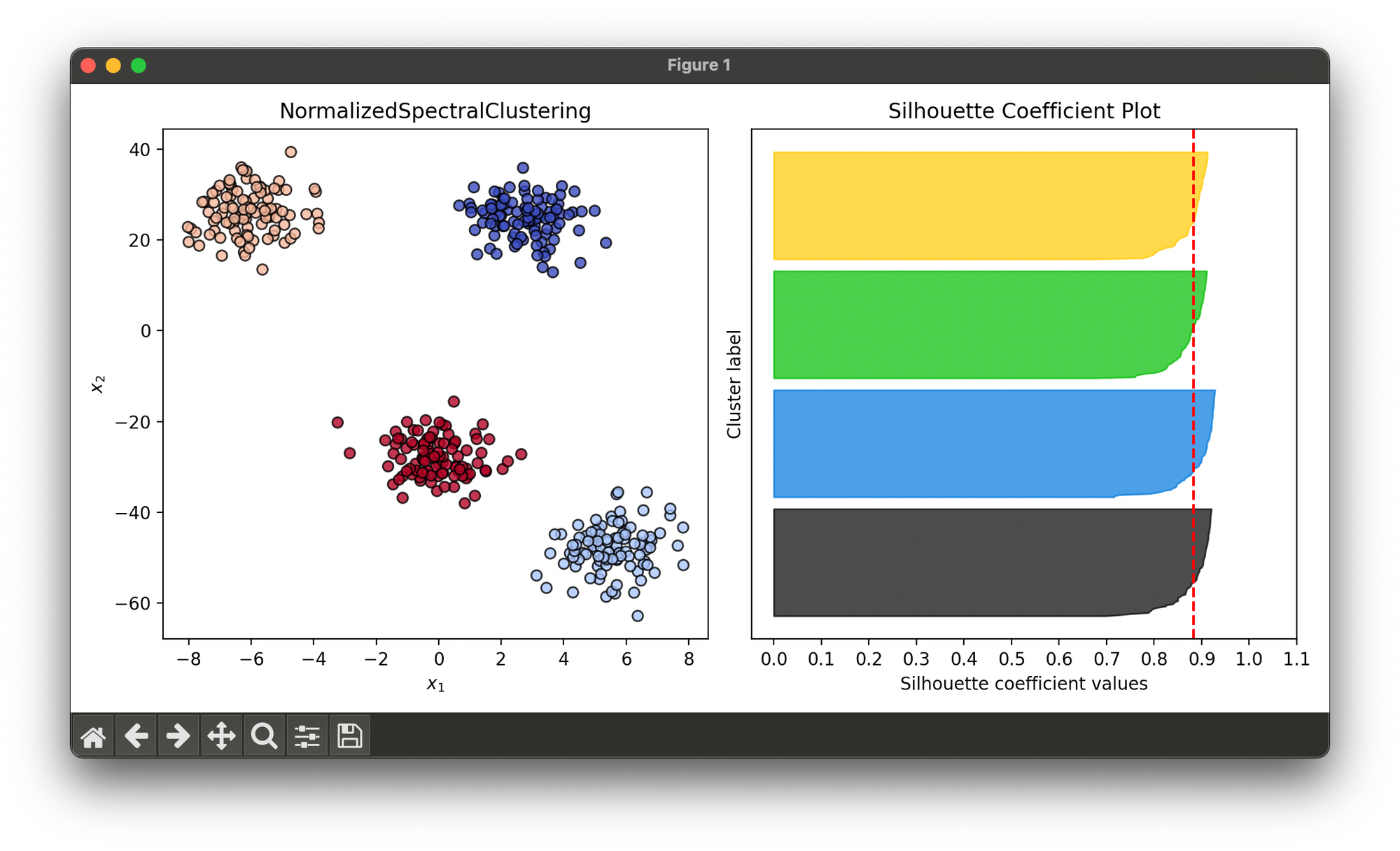
Normalized Spectral Clustering refines the standard Spectral Clustering approach by normalizing the data in a way that emphasizes the innate geometry.
34.[Clustering] Hierarchical Spectral Clustering
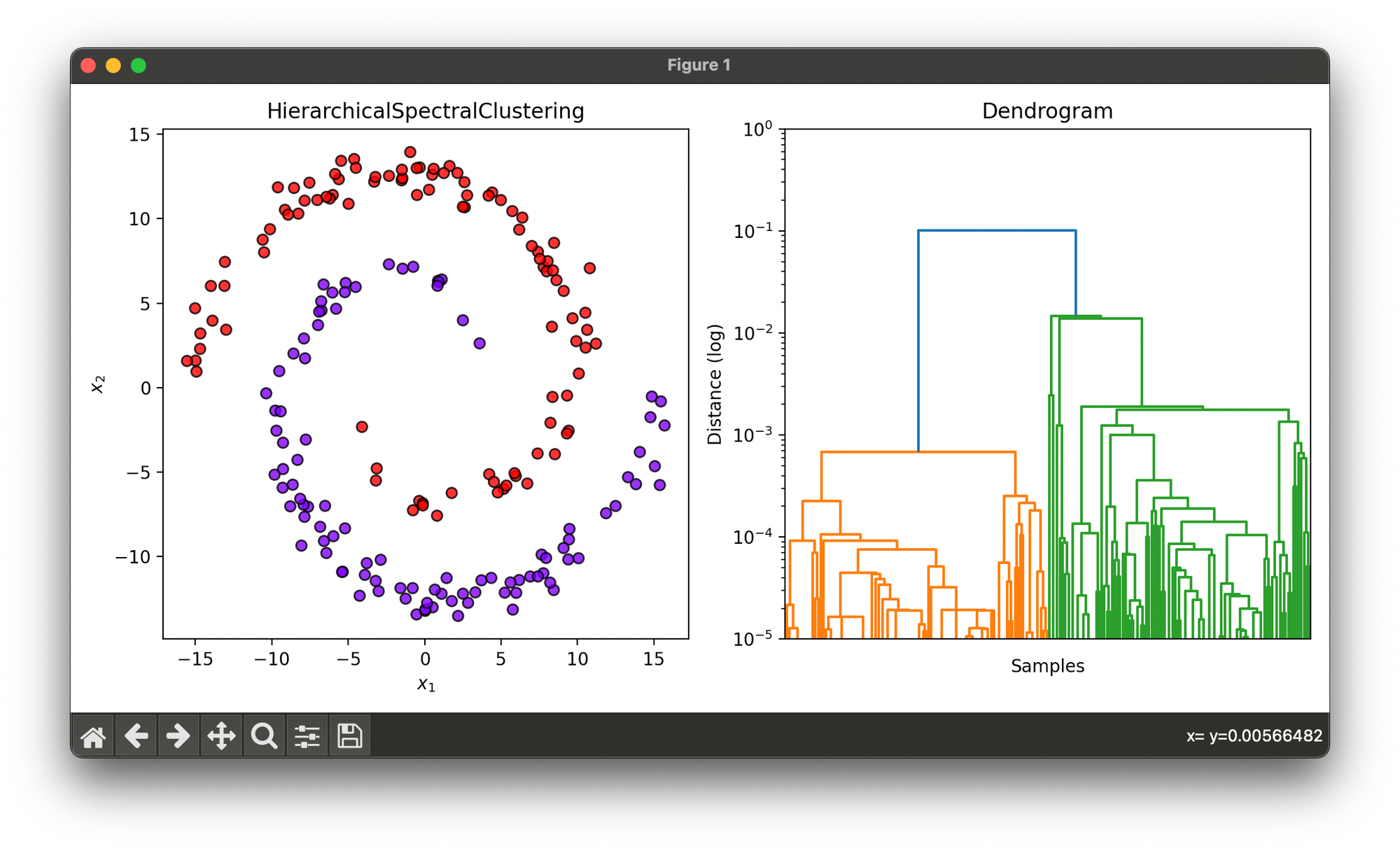
Hierarchical Spectral Clustering combines the principles of hierarchical clustering with spectral methods to analyze data structures at various scale.
35.[Clustering] Adaptive Spectral Clustering
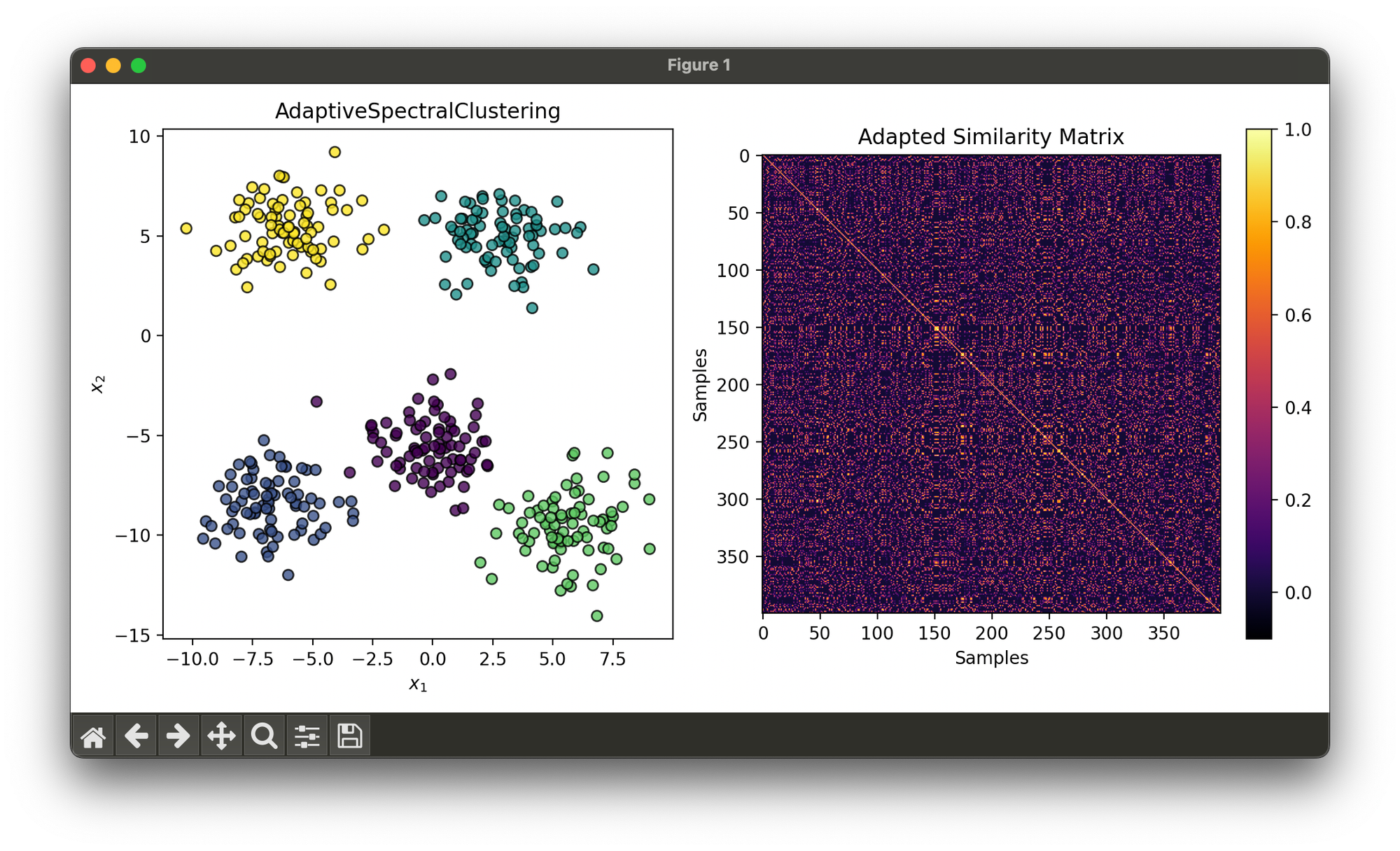
Adaptive Spectral Clustering enhances the spectral clustering framework by dynamically adjusting the algorithm's parameters.
36.[Ensemble] Bagging Classifier
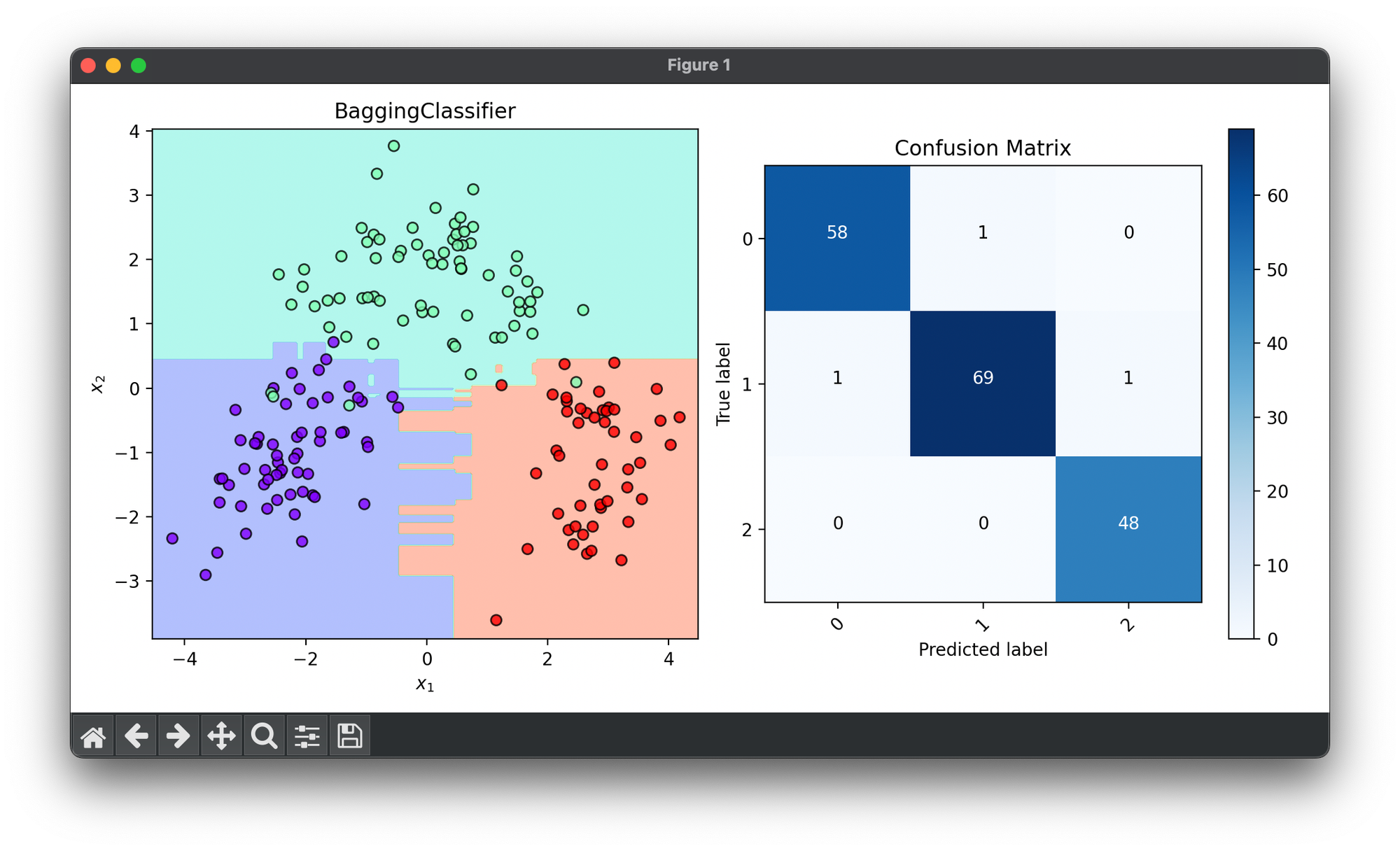
The Bagging Classifier is a machine learning ensemble meta-algorithm designed to improve the stability an accuracy of ML algorithms.
37.[Ensemble] Bagging Regressor
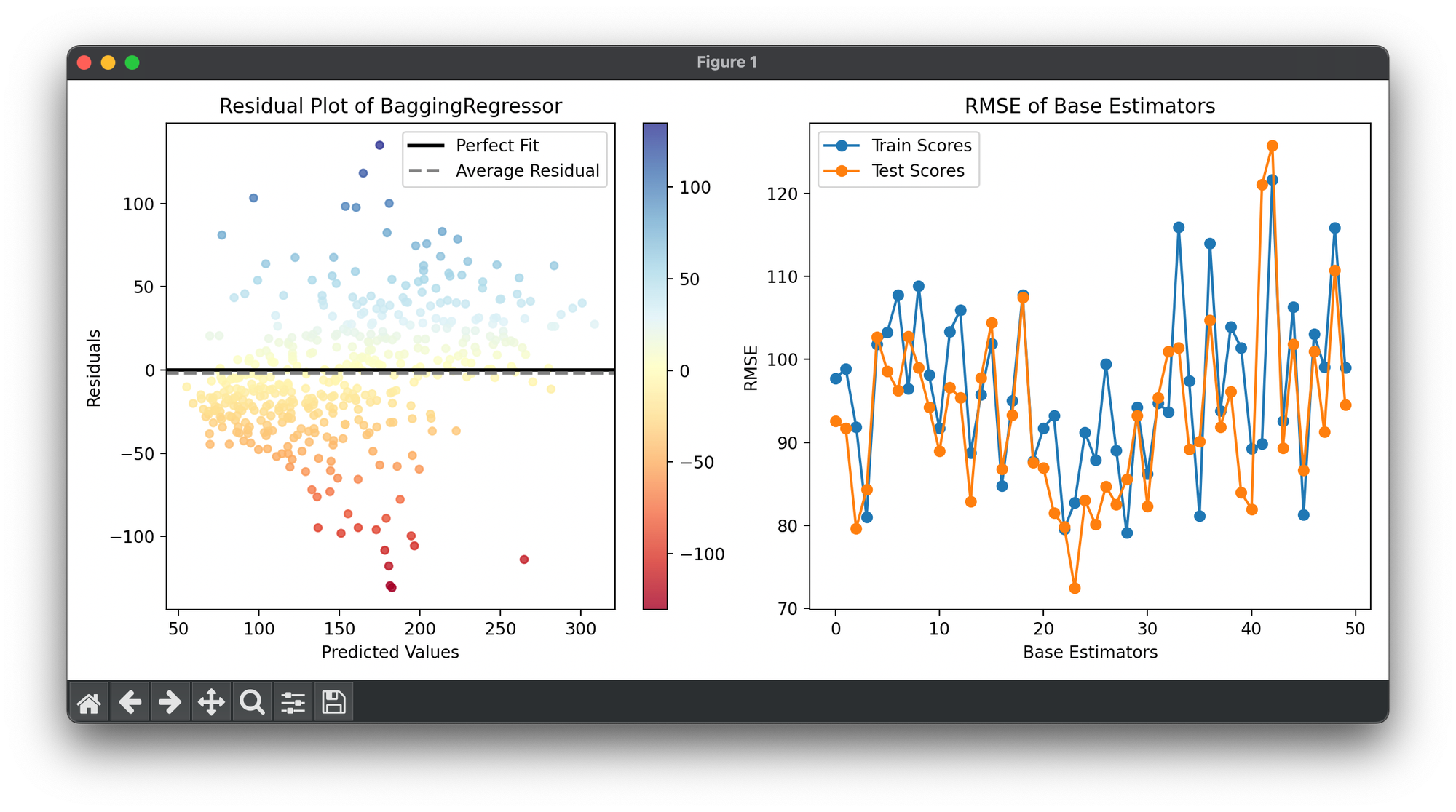
The Bagging Regressor is an ensemble meta-algorithm designed to improve the stability and accuracy of machine learning algorithms.
38.[Ensemble] AdaBoost Classifier
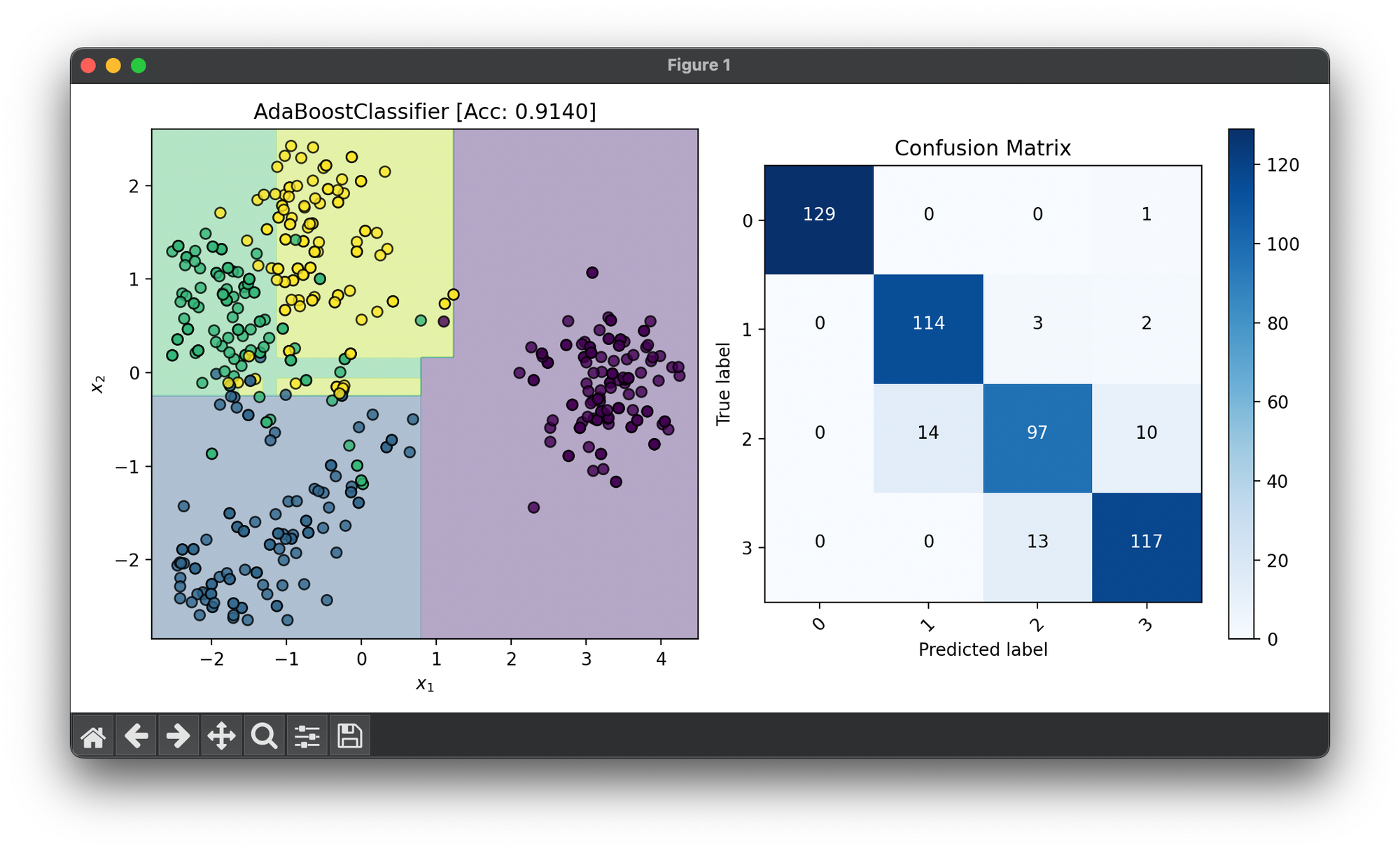
AdaBoost is an ensemble learning method that is used primarily for classification tasks. It combines multiple weak classifiers to create a strong one.
39.[Ensemble] AdaBoost Regressor
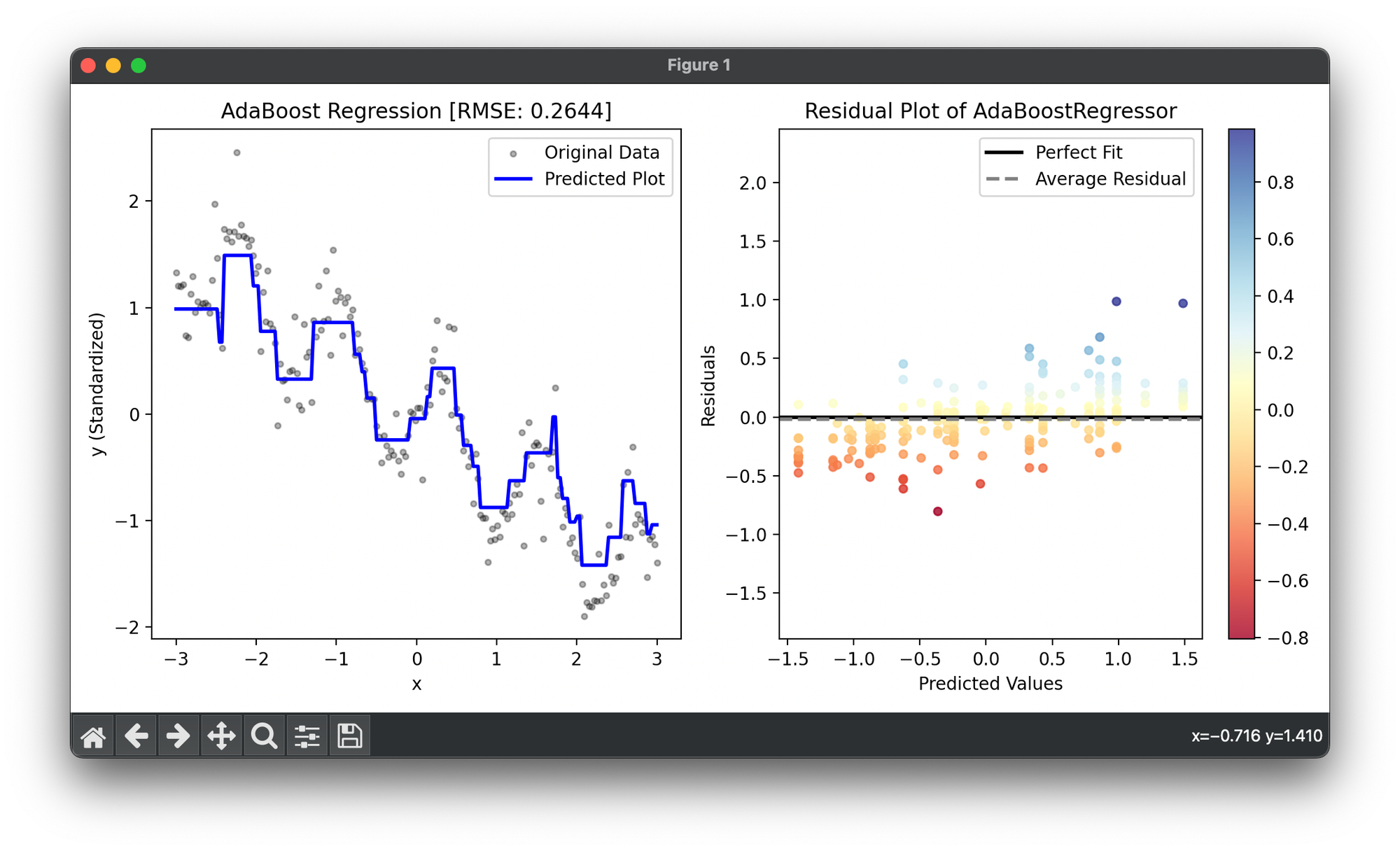
AdaBoost Regressor is an ensemble learning method specifically adapted for regression problems. It combines multiple weak regressors.
40.[Ensemble] Gradient Boosting Classifier
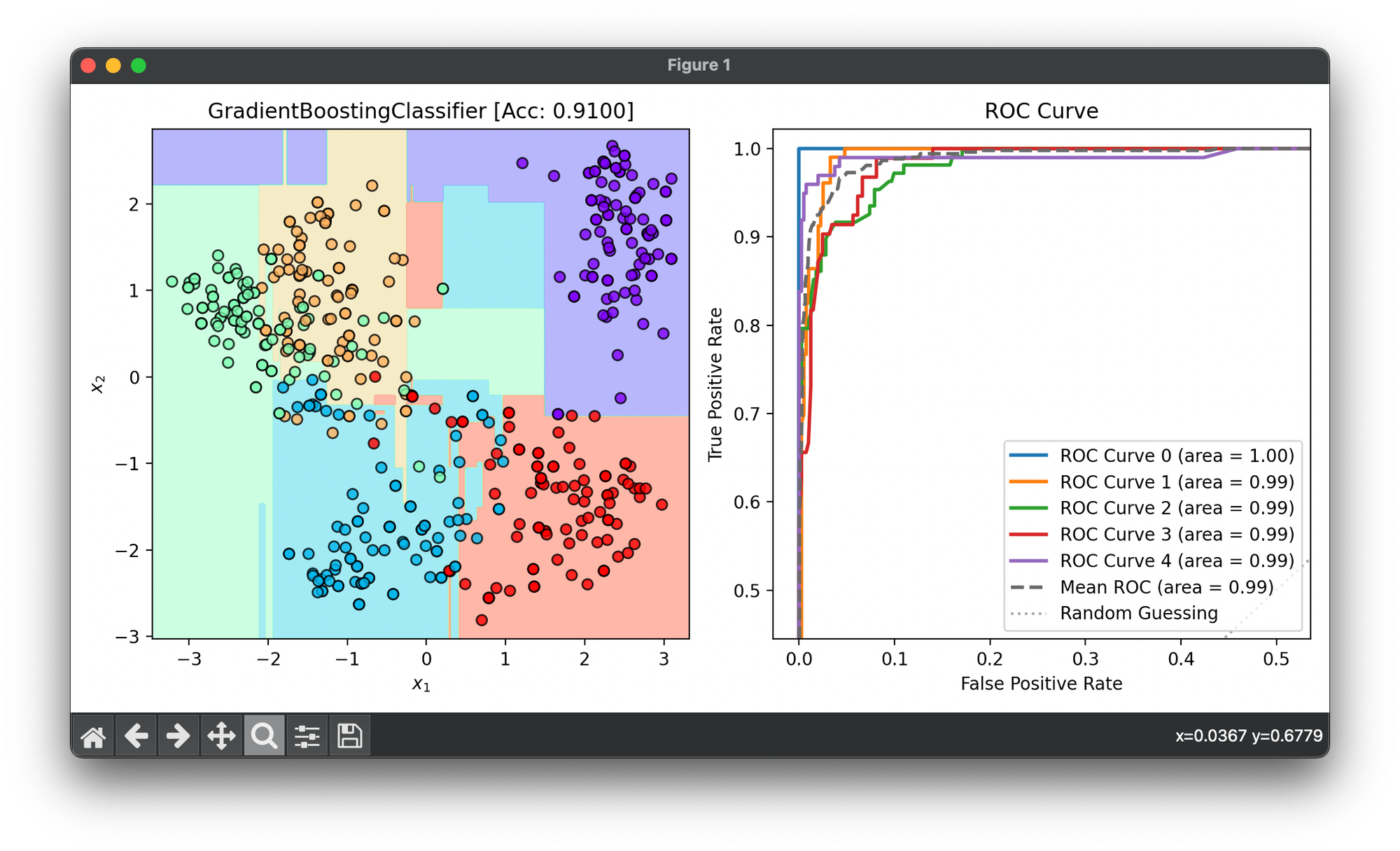
Gradient Boosting Classifier is a powerful machine learning algorithm that belongs to the ensemble methods, specifically to boosting techniques.
41.[Ensemble] Gradient Boosting Regressor
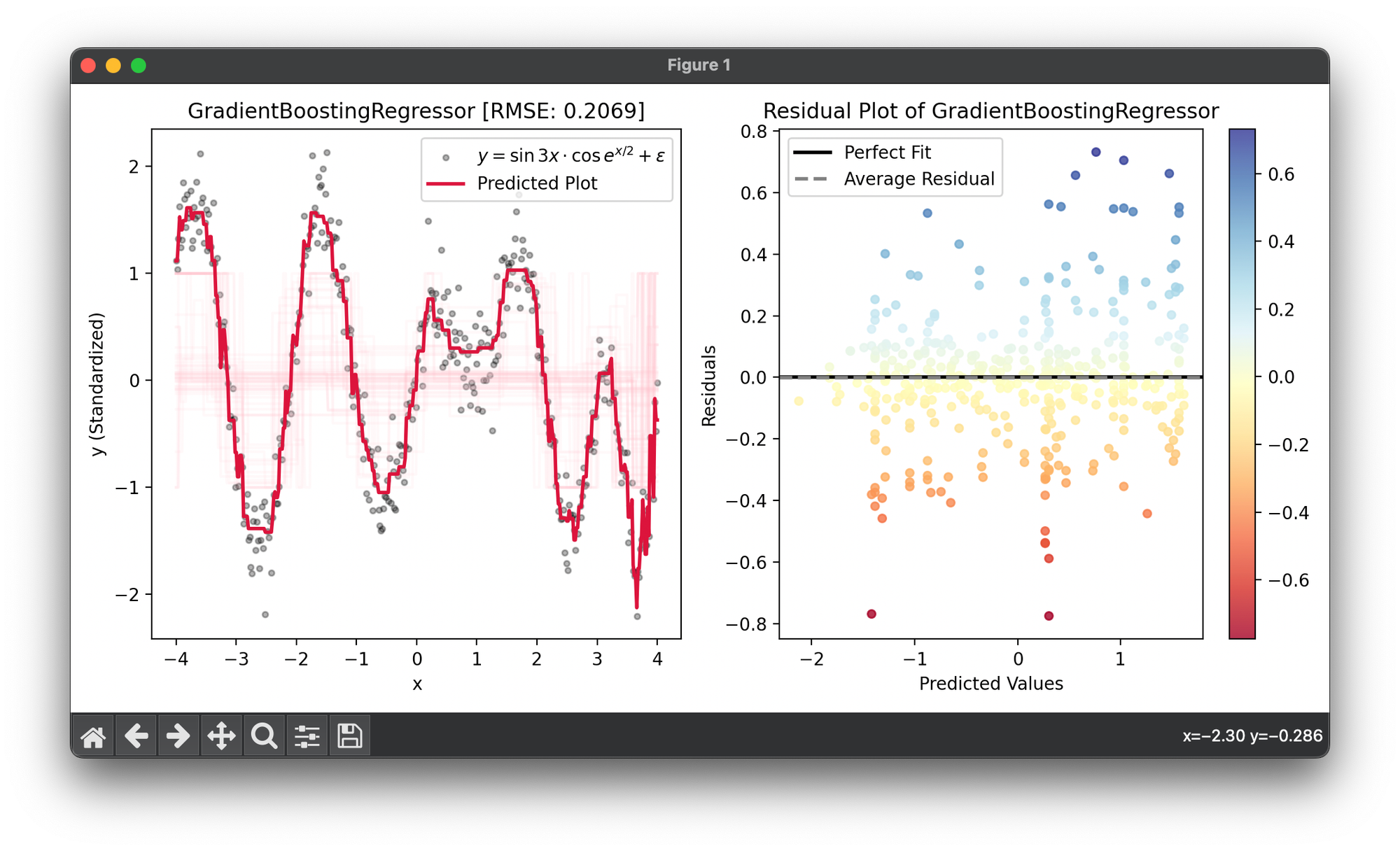
Gradient Boosting Regressor is a potent machine learning algorithm that is part of the ensemble methods, particularly within the boosting techniques.
42.[Ensemble] Random Forest Classifier
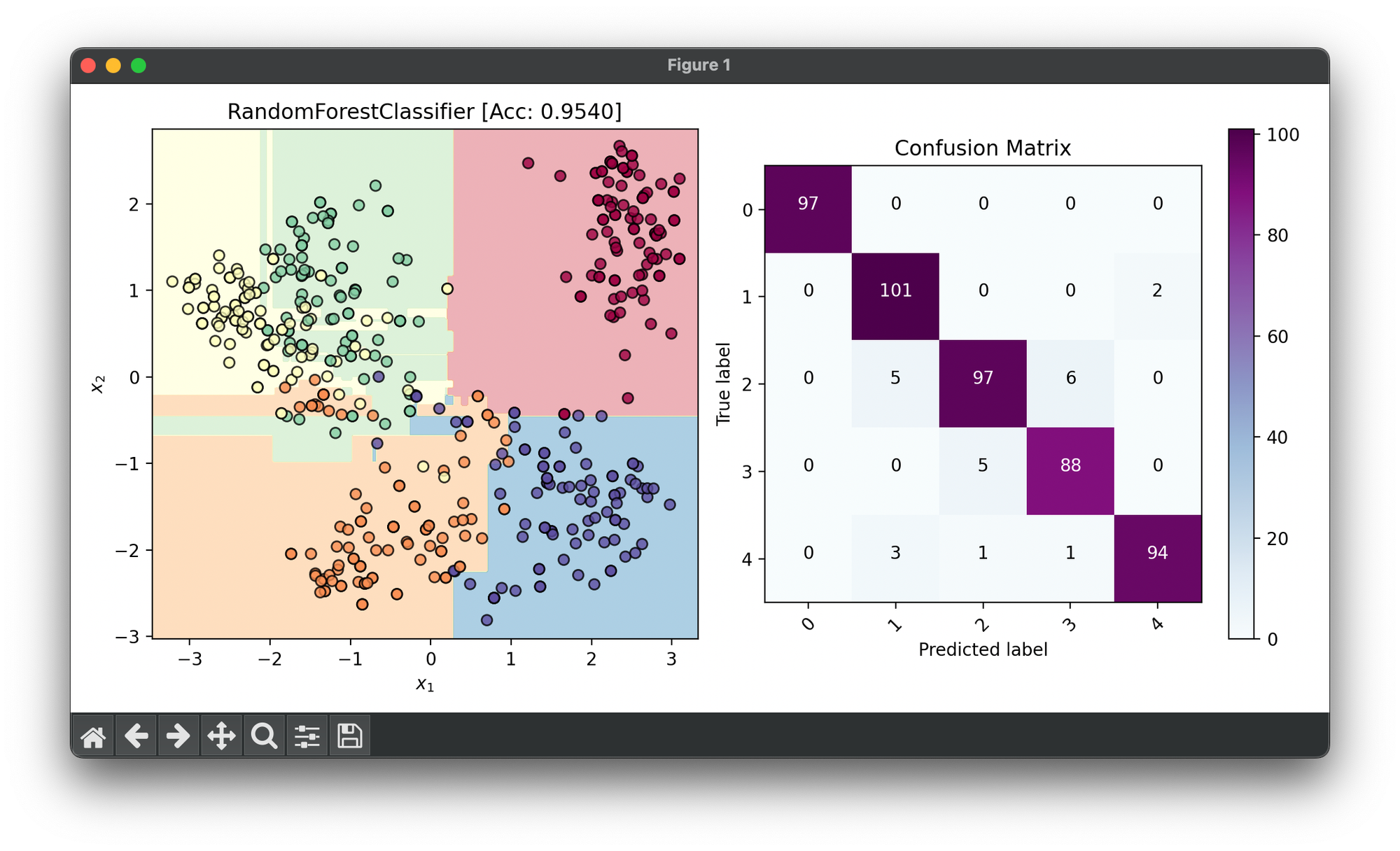
Random Forest Classifier is a powerful machine learning algorithm used for classification tasks. It operates by constructing a multitude of trees.
43.[Ensemble] Random Forest Regressor
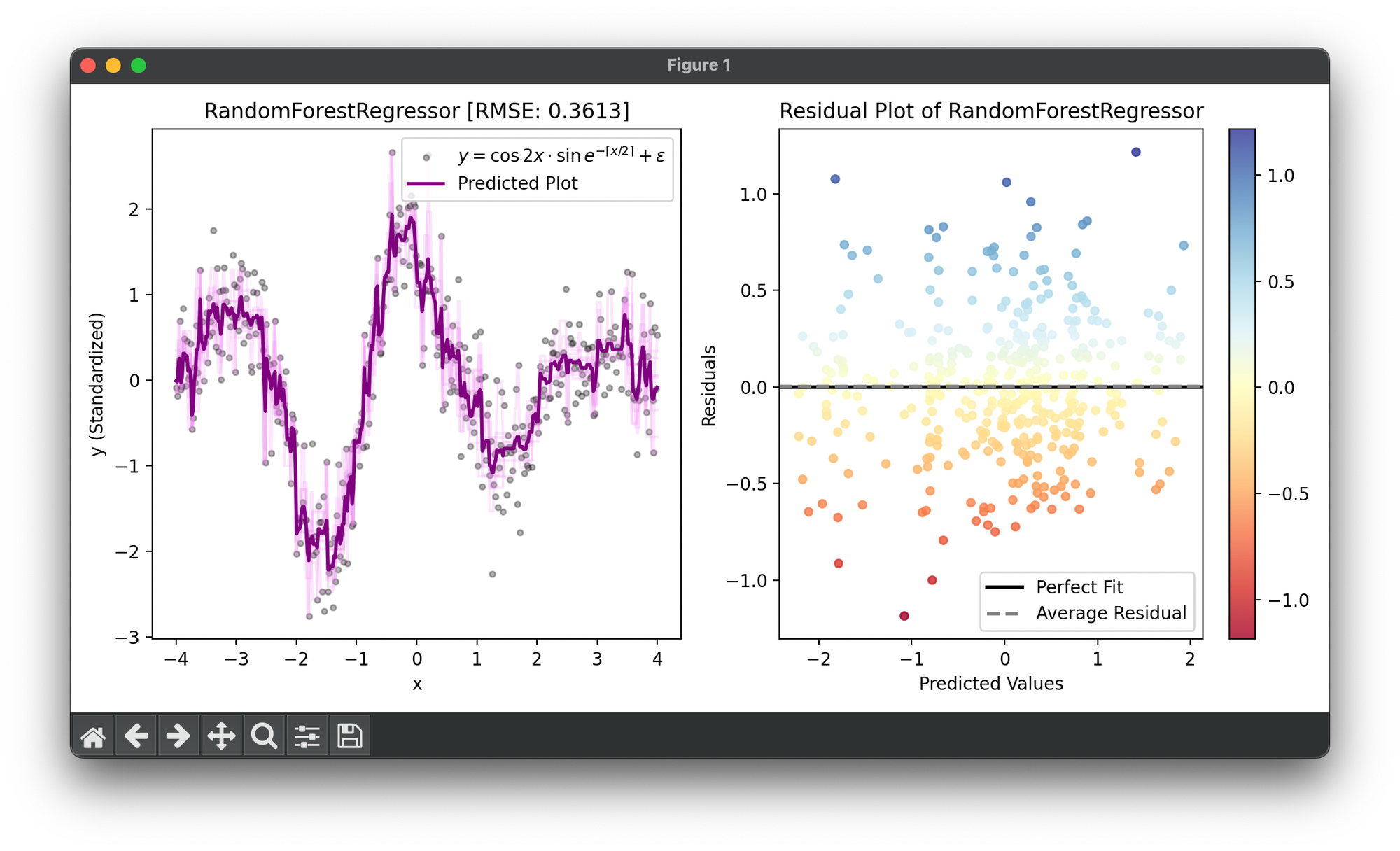
Random Forest Regressor is a machine learning algorithm used for regression, which predicts a continuous value for new observations by aggregation.
44.[Ensemble] Voting Classifier
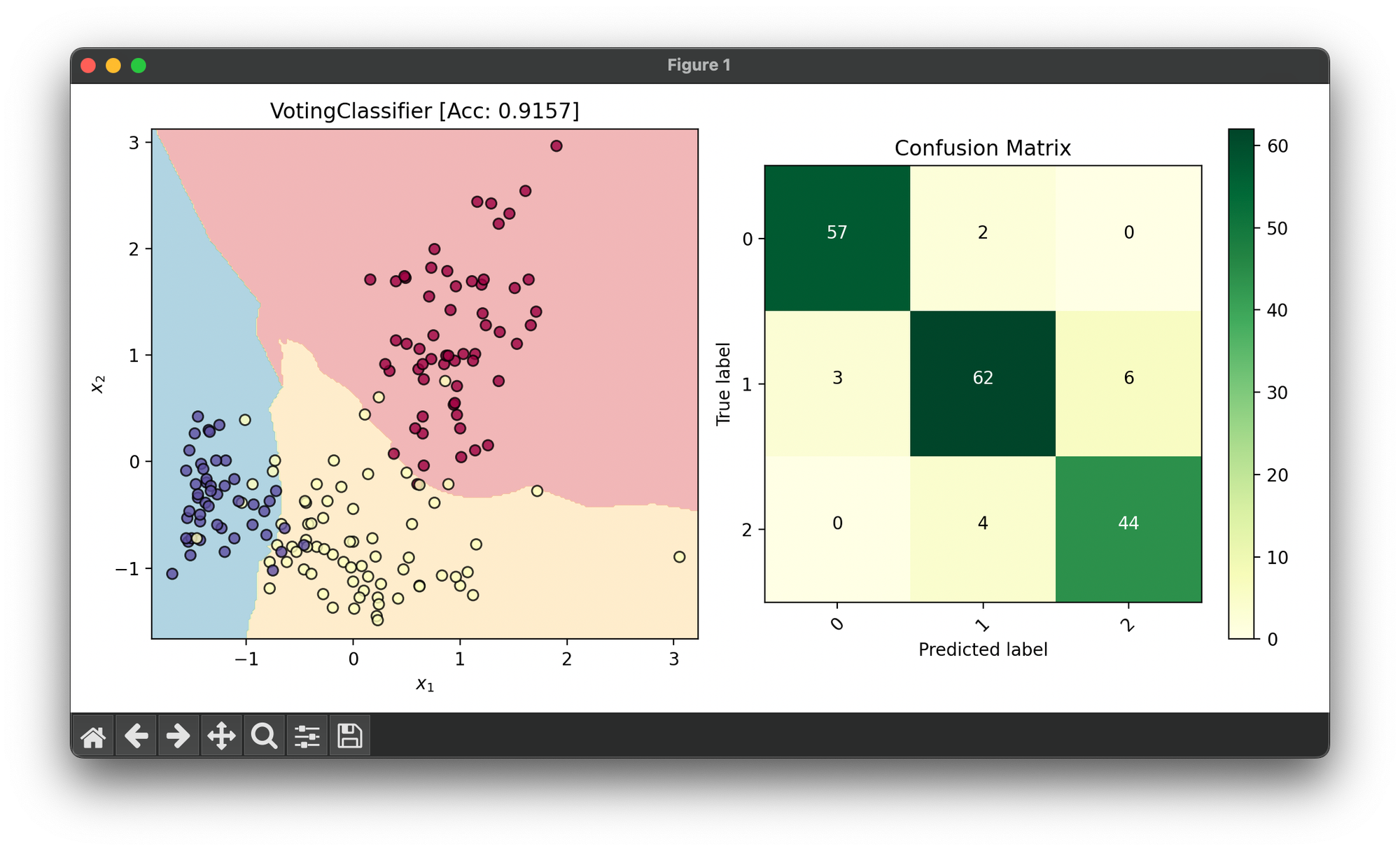
The Voting Classifier is a machine learning model that combines the predictions from multiple different models to make a final prediction.
45.[Ensemble] Voting Regressor
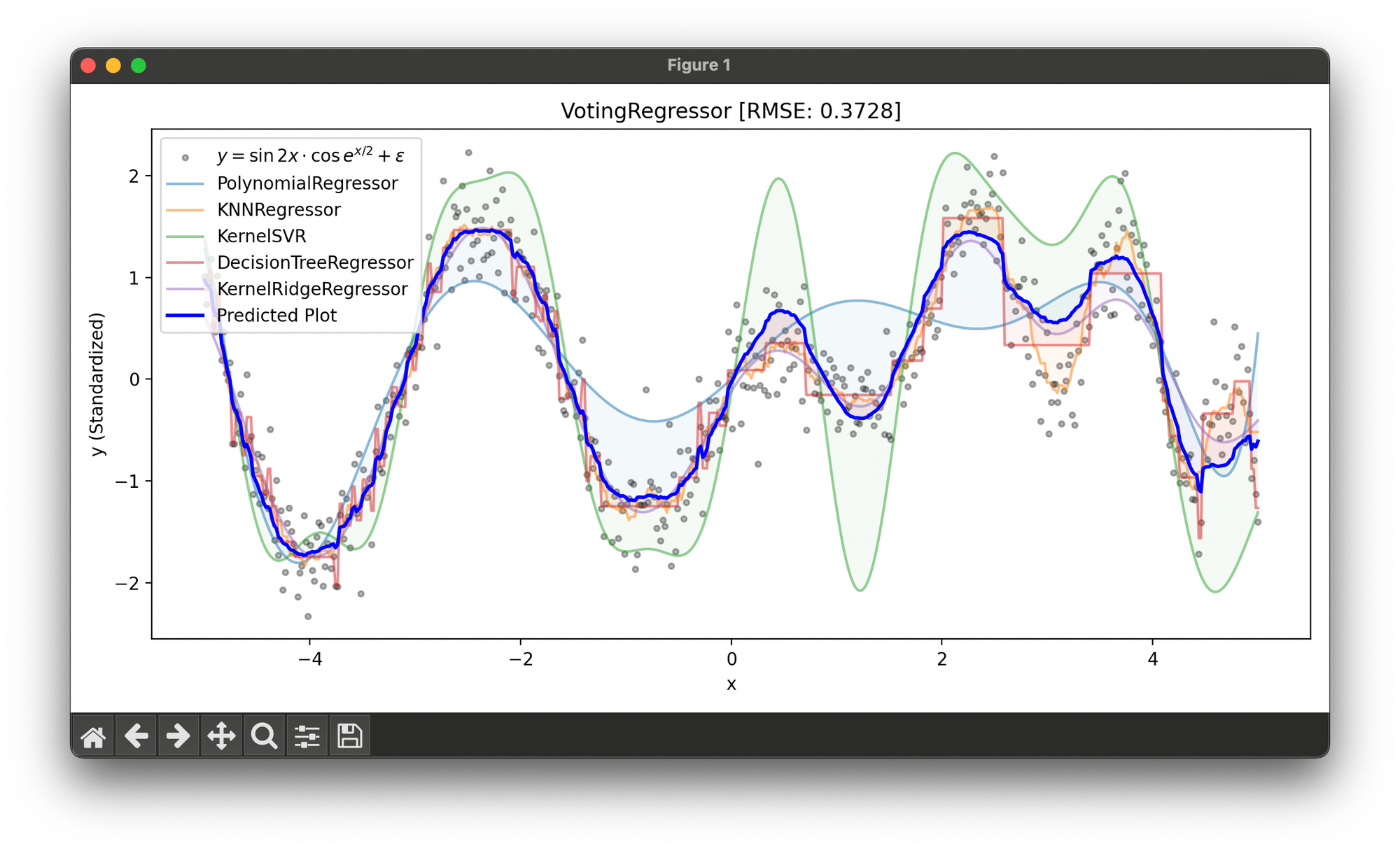
Voting Regressor is an ensemble machine learning algorithm used for regression tasks. It combines the predictions from several different regressors.
46.[Ensemble] Stacking Classifier
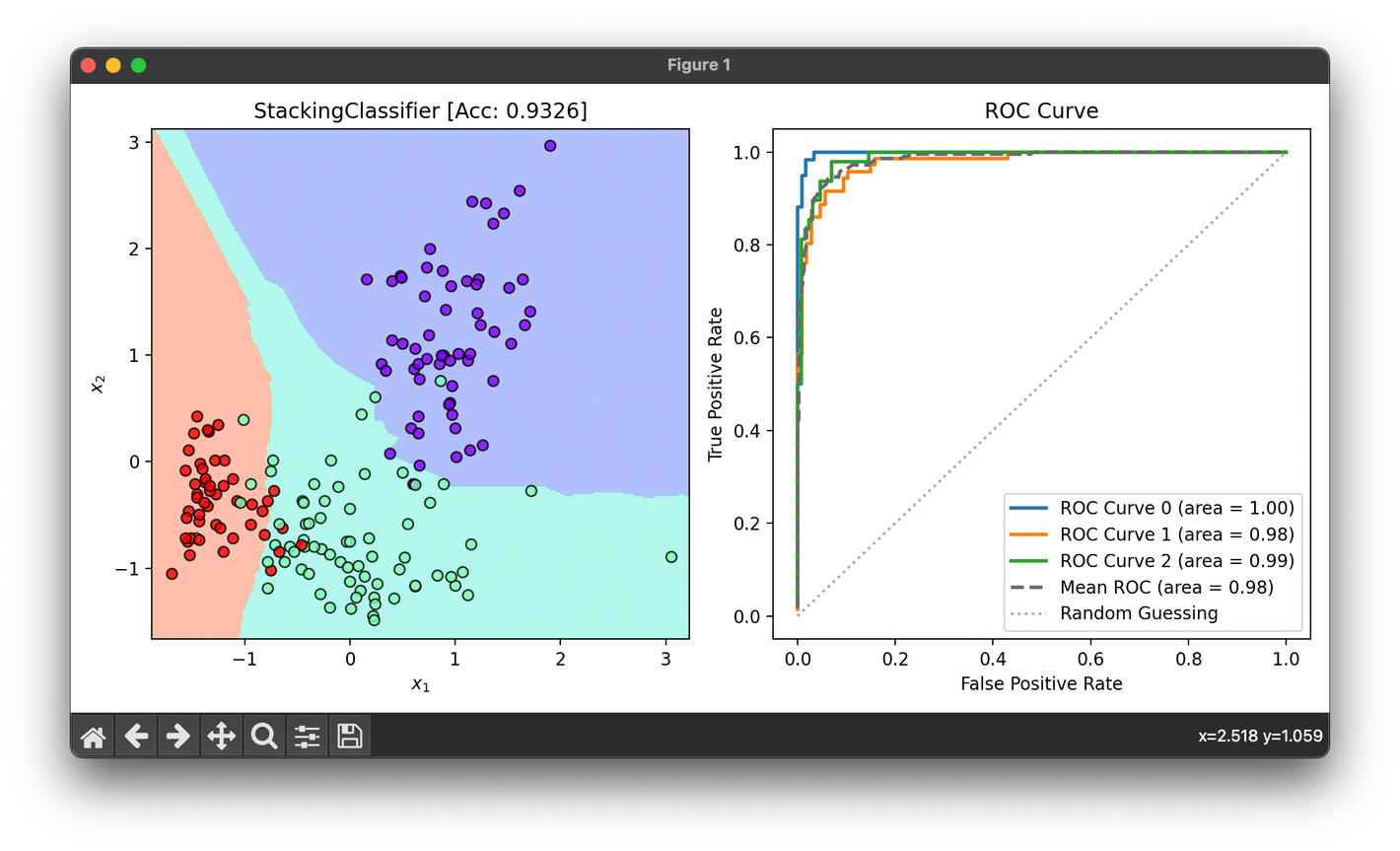
Stacking involves training a model to combine the predictions of several other models. The aim is to use the stacked model to achieve better score/
47.[Ensemble] Stacking Regressor
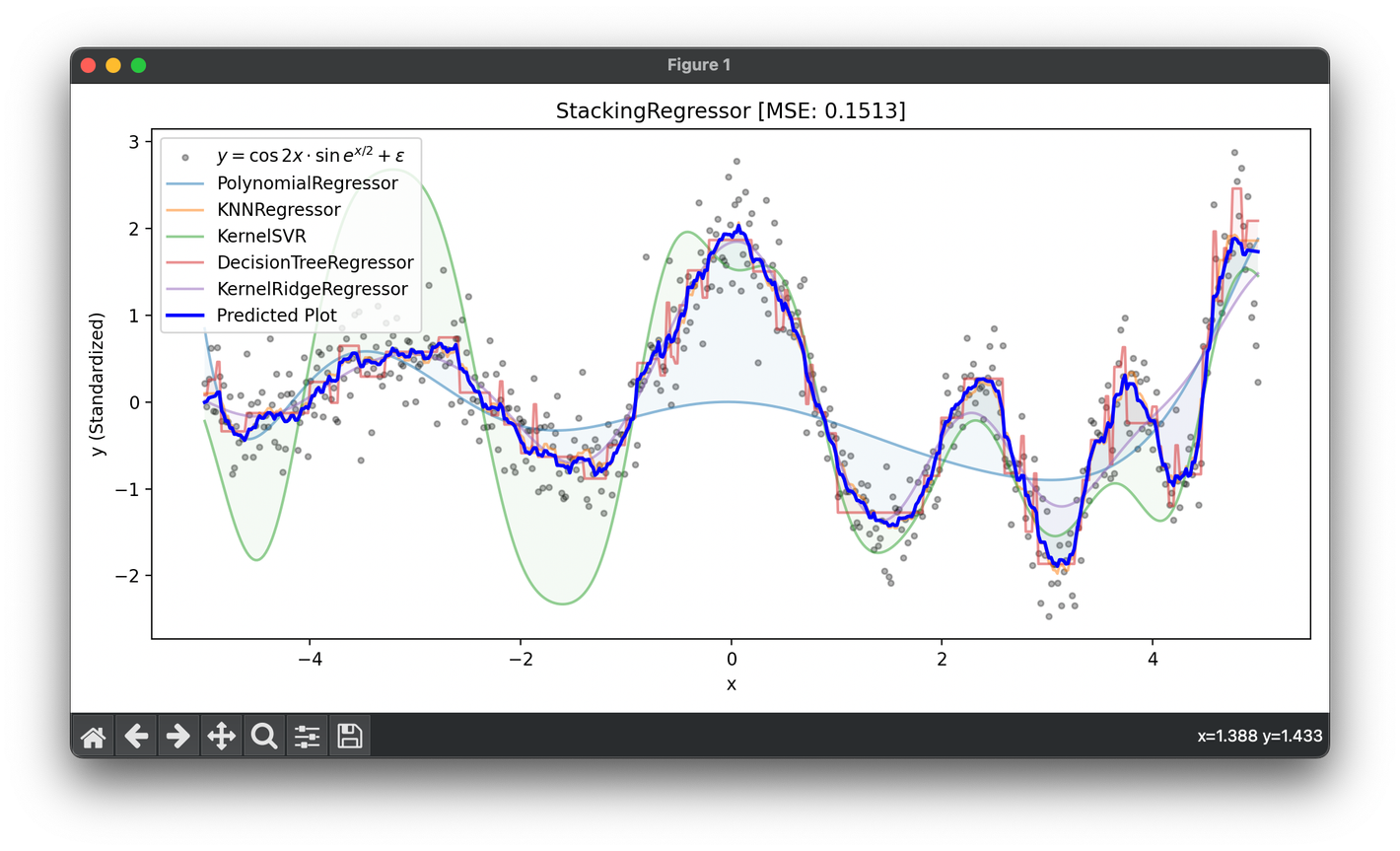
Stacking Regressor is an ensemble learning technique that combines multiple regression models via a meta-regressor.
48.[Metric] Accuracy
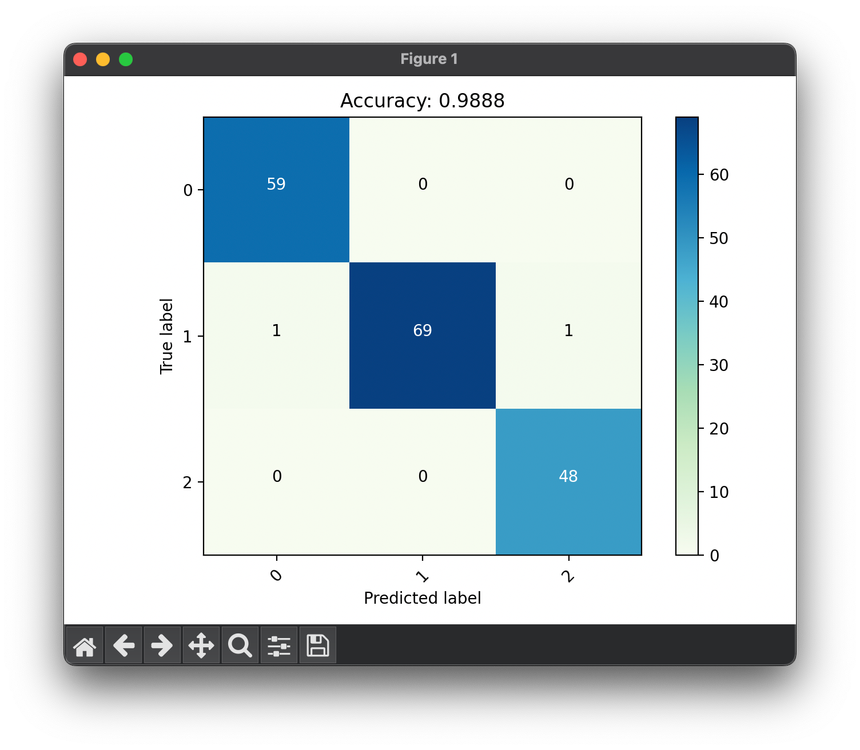
Accuracy is one of the most intuitive and widely used performance metrics for evaluating classification models in machine learning.
49.[Metric] Precision
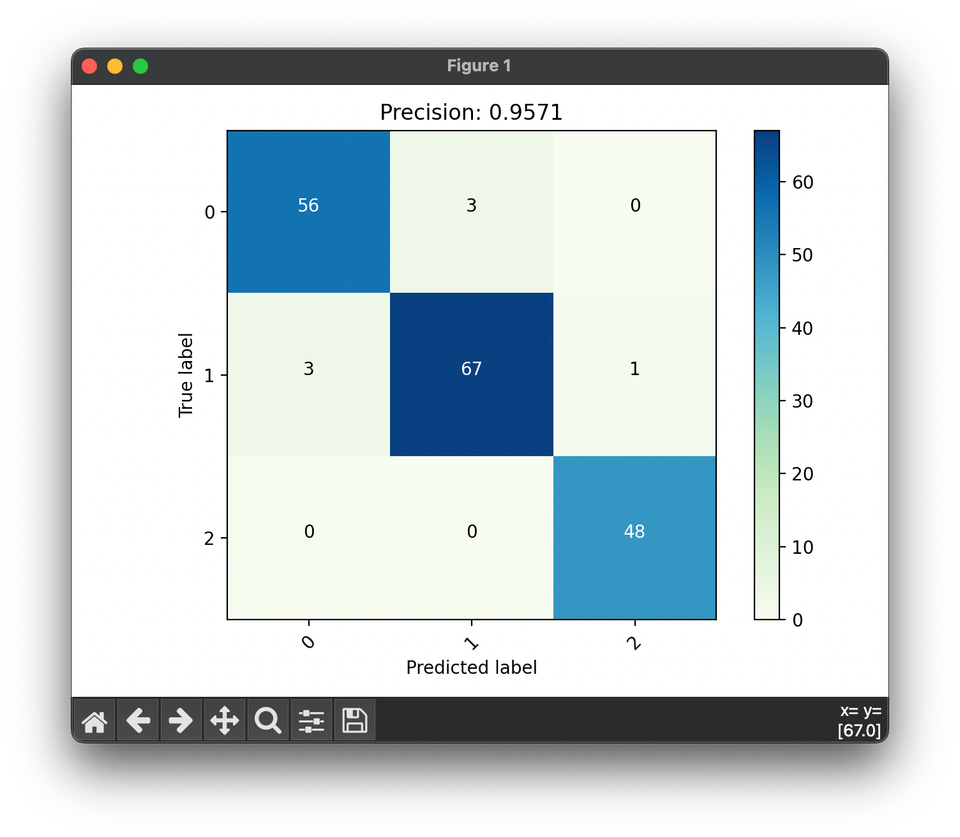
Precision is a metric in the evaluation of classification models within machine learning, particularly in scenarios where the cost of FP is high.
50.[Metric] Recall (Sensitivity, TPR)
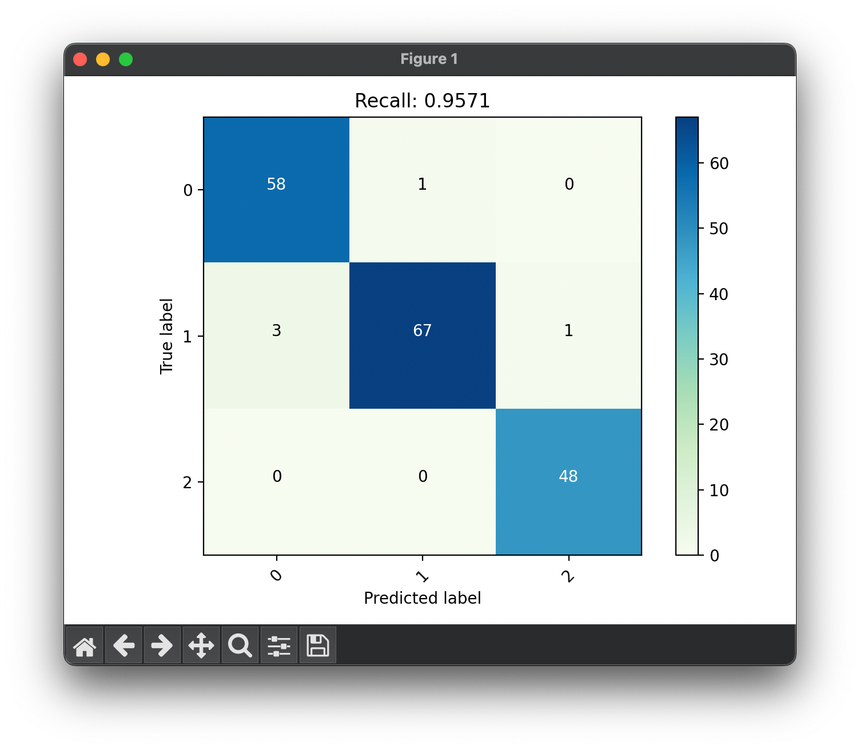
Recall is a vital metric for evaluating the performance of classification models, especially in contexts where FN carries significant consequences.
51.[Metric] F1 Score
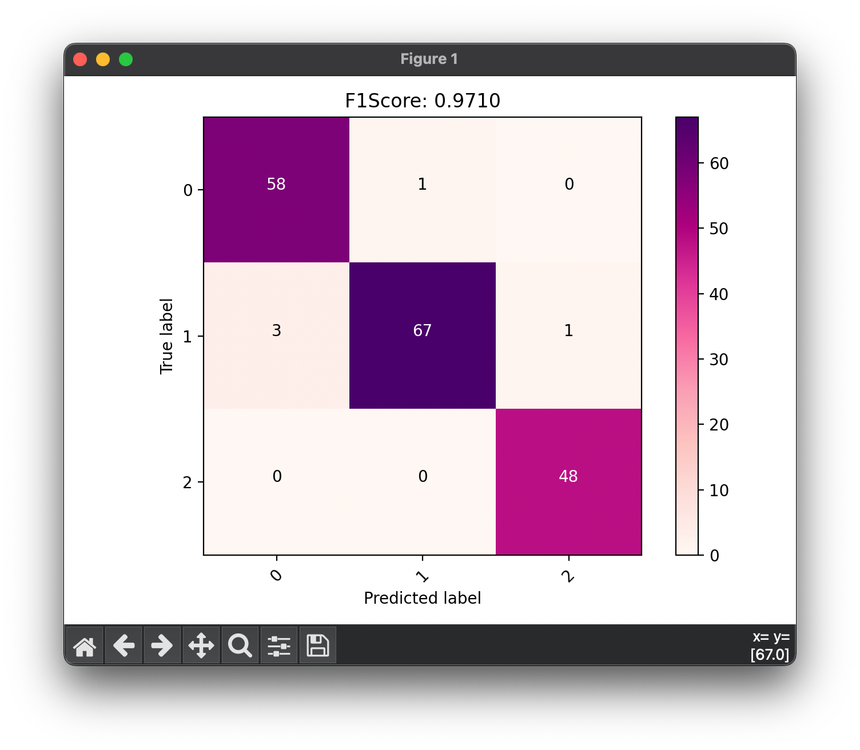
The F1 Score is a widely used metric for measuring a model's accuracy on datasets where true negatives don't matter as much.
52.[Metric] Specificity (TNR)
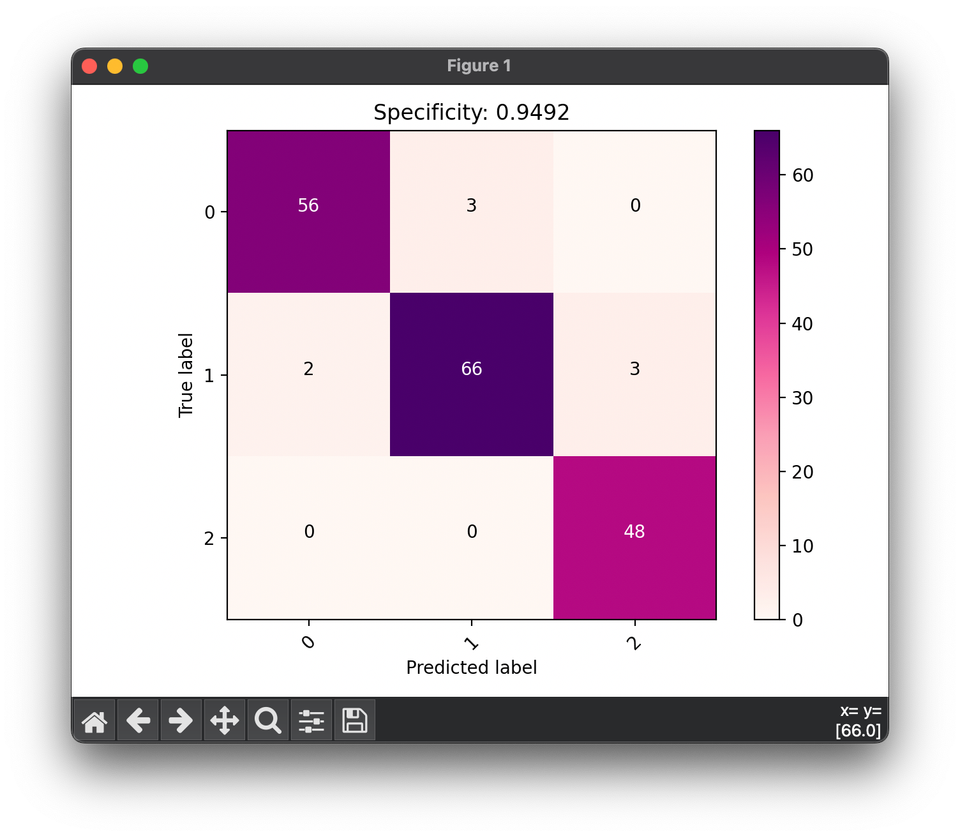
Specificity(TNR) is a performance metric used to evaluate the effectiveness of a classification model in identifying negative instances correctly.
53.[Metric] Silhouette Coefficient
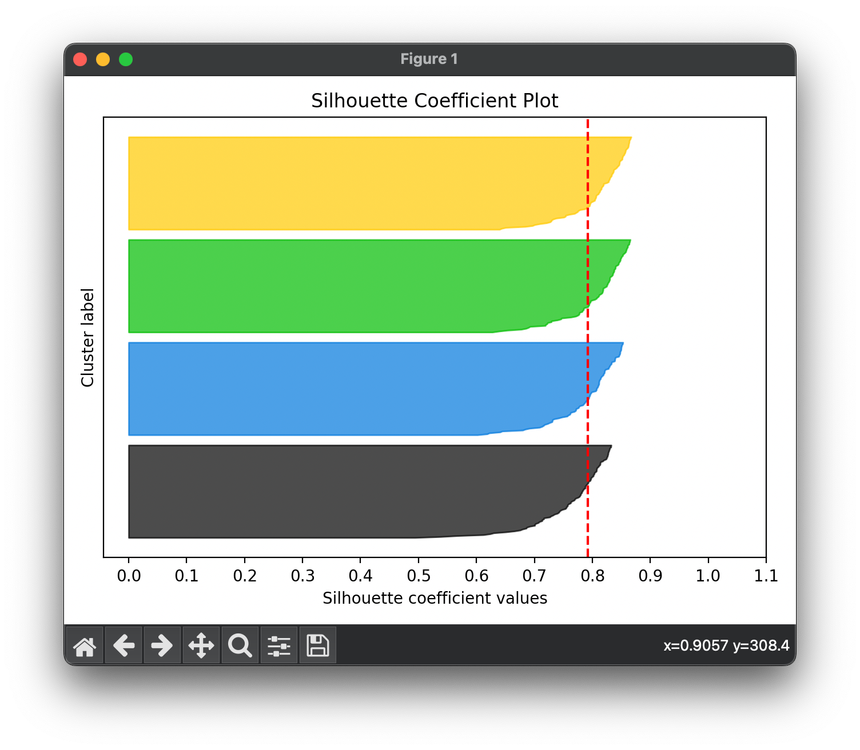
The Silhouette Coefficient is a metric used to calculate the effectiveness of clustering algorithms.
54.[Metric] Davies-Bouldin Index (DBI)
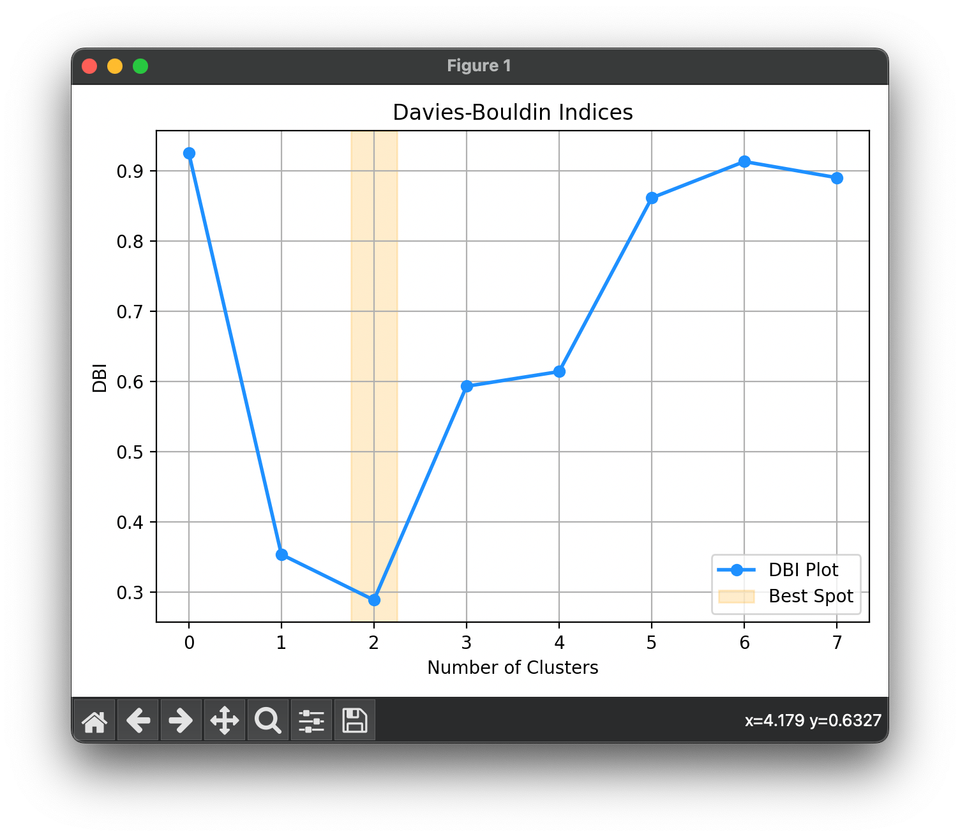
The Davies-Bouldin Index (DBI) is a metric for evaluating clustering algorithms. The lower the DBI value, the better the clustering quality.
55.[Metric] Inertia
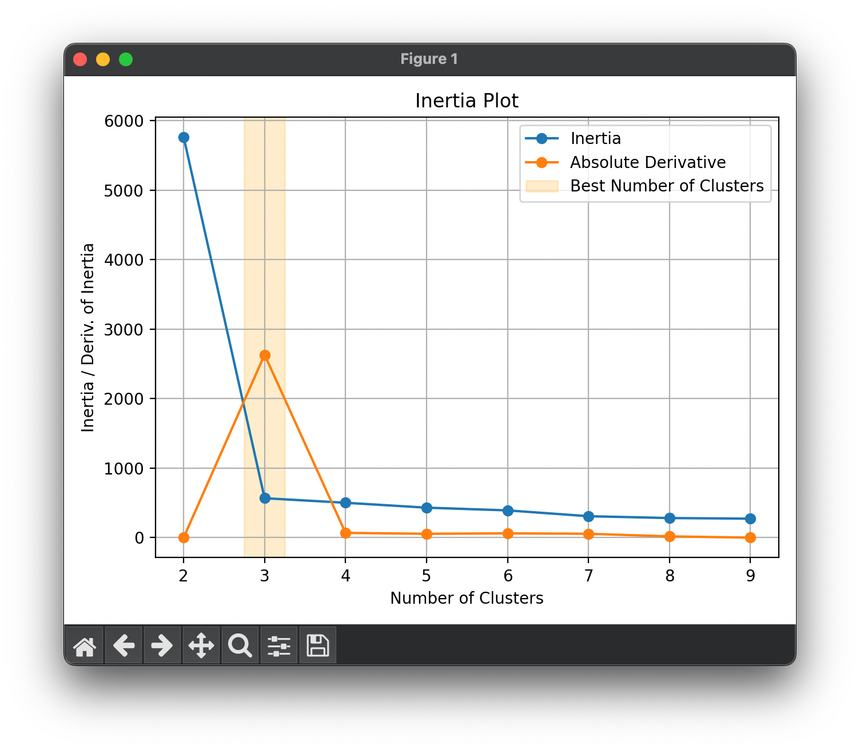
Inertia, often referred to in the context of k-means clustering, is a metric used to evaluate the quality of cluster assignments.
56.[Metric] Mean Absolute Error
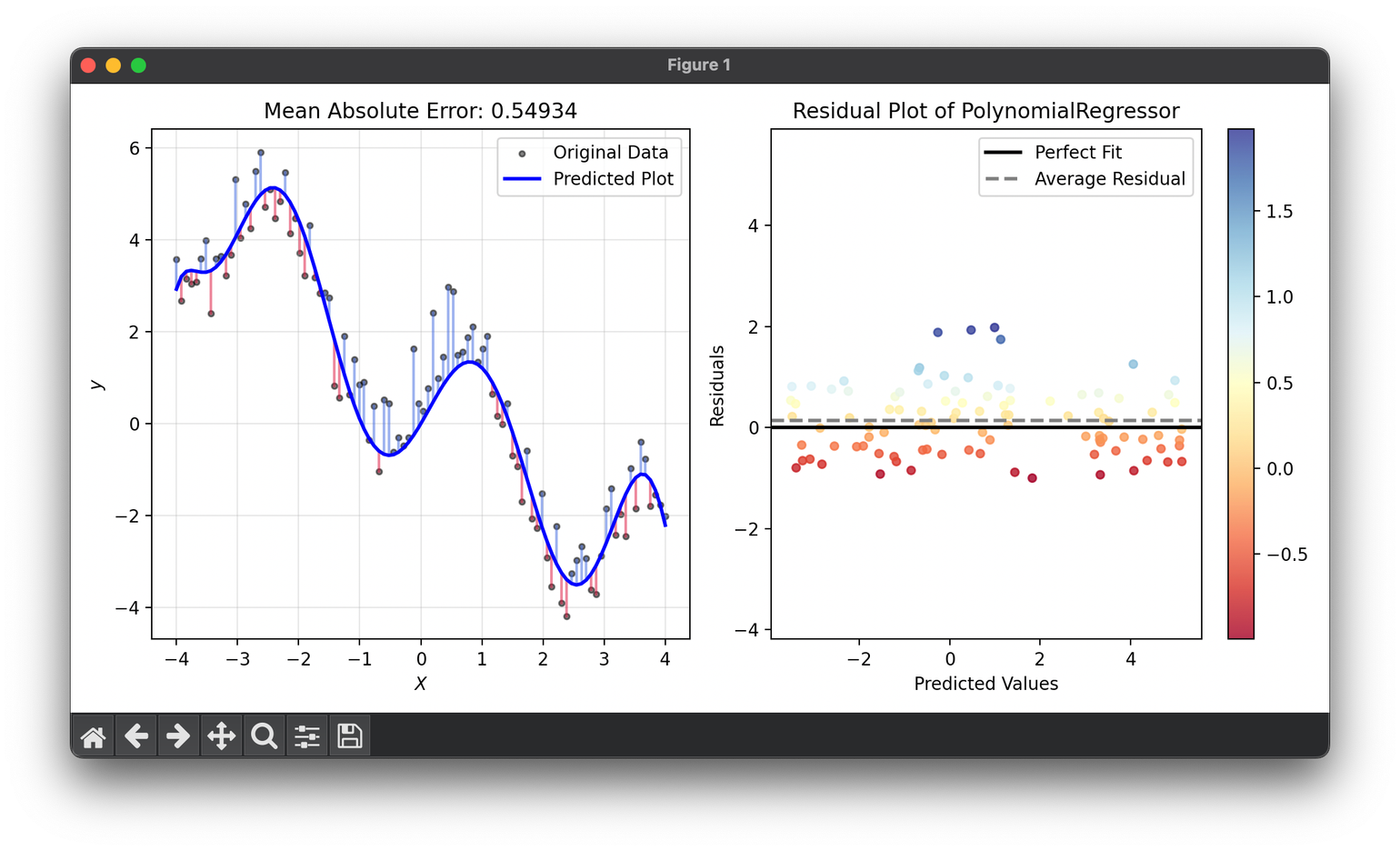
Mean Absolute Error (MAE) is a metric used to evaluate the performance of regression models. It quantifies the average magnitude of errors.
57.[Metric] Mean Squared Error (MSE)
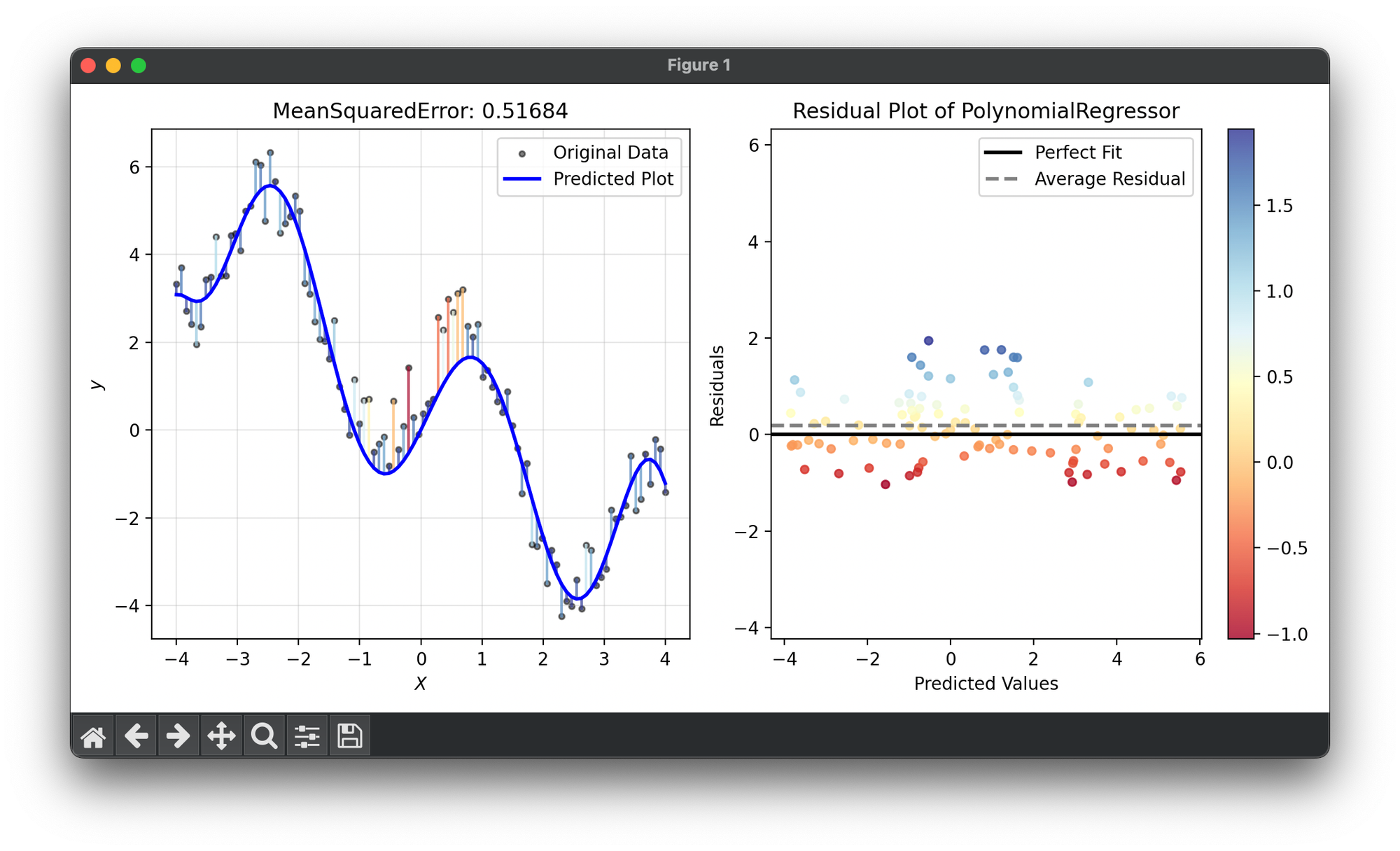
Mean Squared Error is a statistical measure used to evaluate the performance of regression models. It calculates the average of the squares of errors.
58.[Metric] Root Mean Squared Error (RMSE)
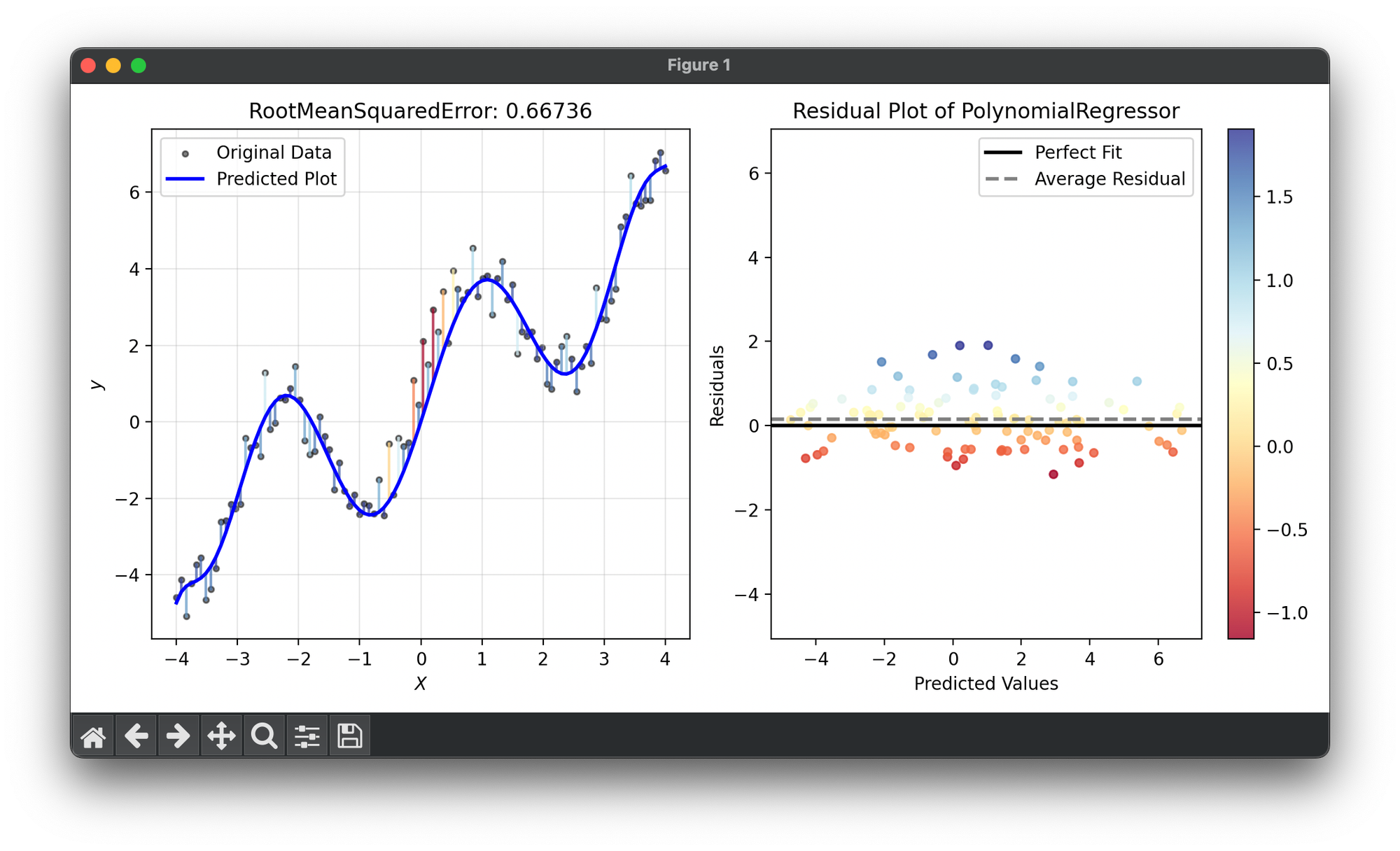
Root Mean Squared Error (RMSE) is a standard way to measure the error of a model in predicting quantitative data.
59.[Metric] Mean Absolute Percentage Error
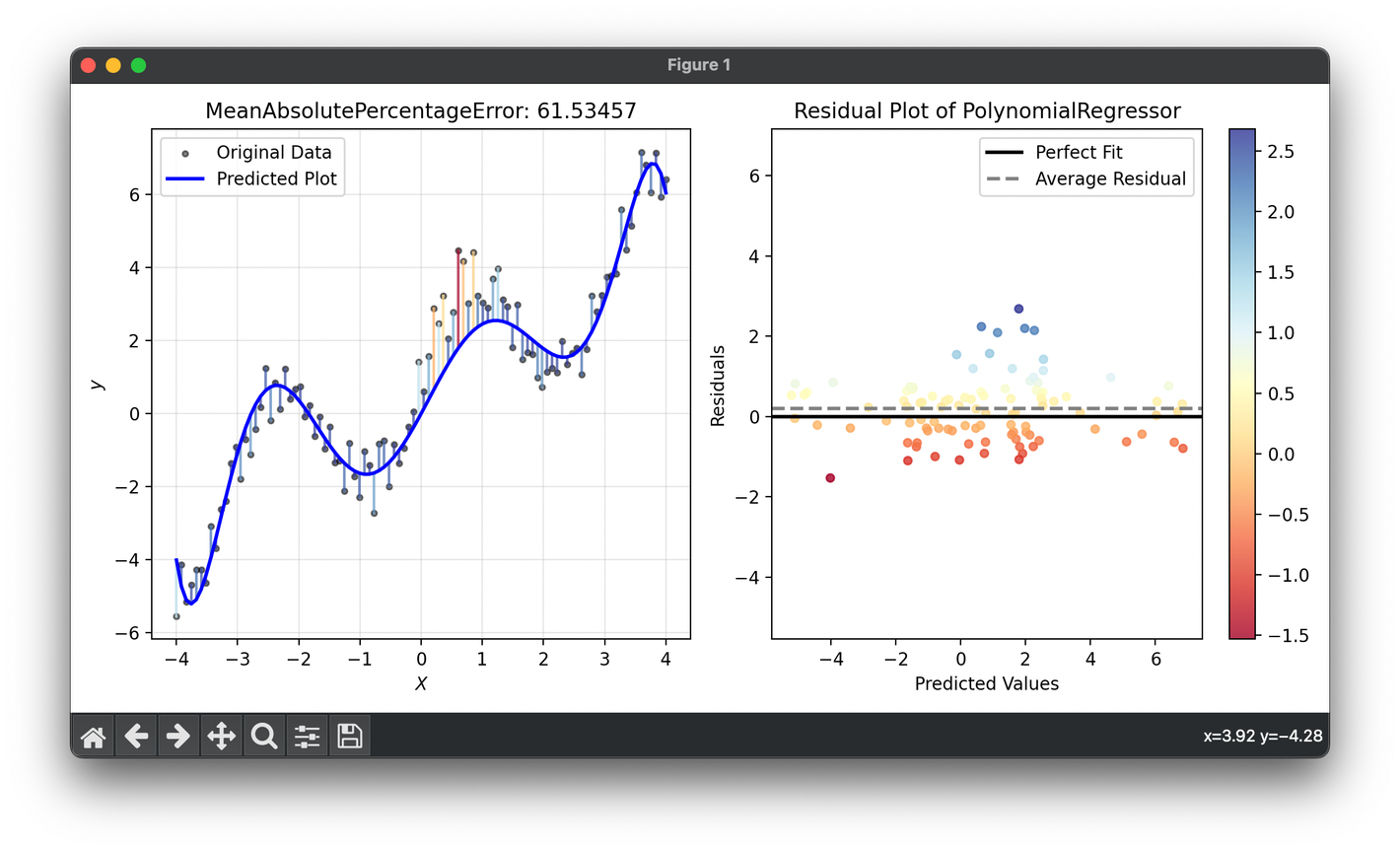
Mean Absolute Percentage Error (MAPE) is a statistical measure often used to assess the accuracy of forecast models.
60.[Metric] R-Squared Score
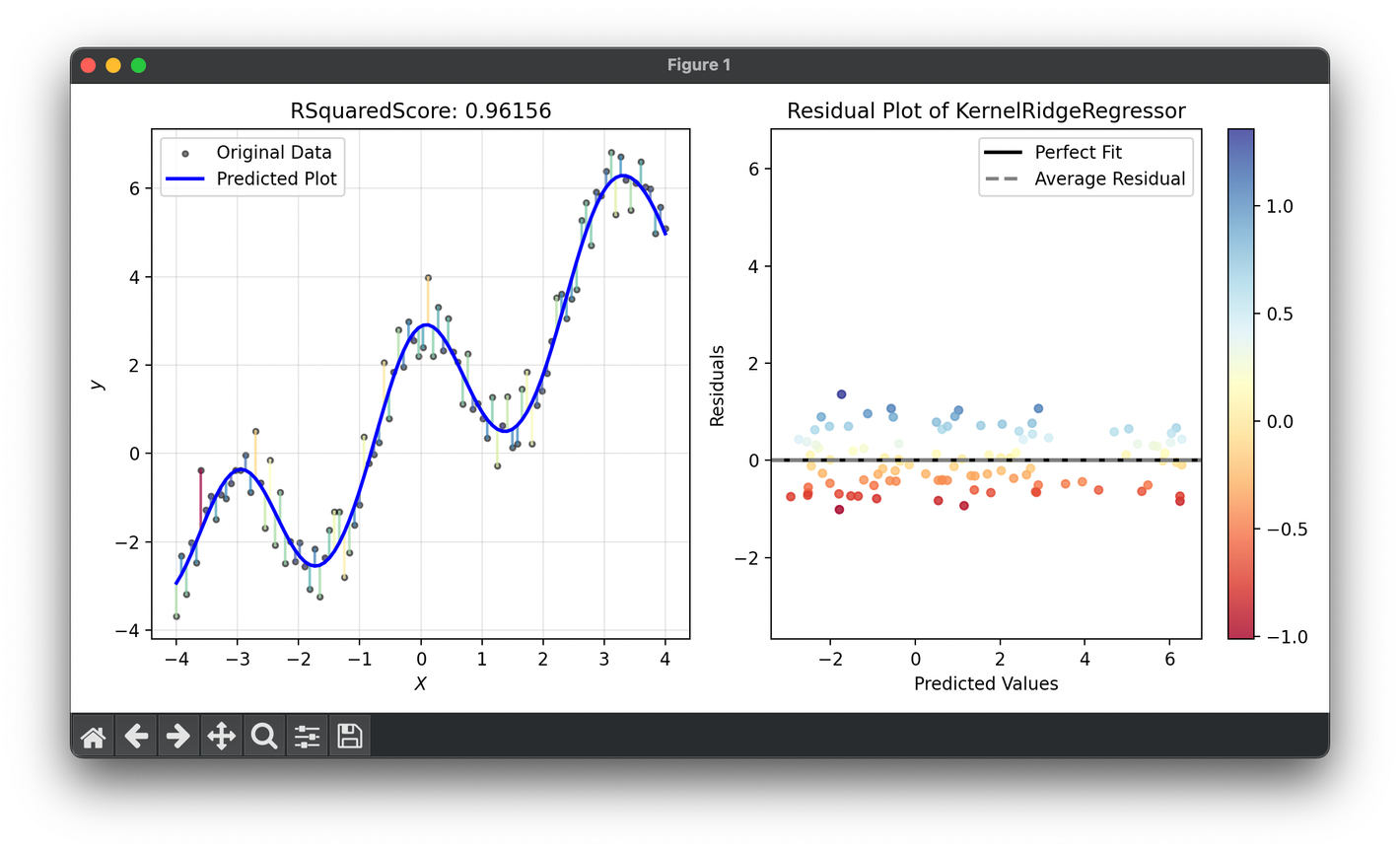
R-Squared, also known as the coefficient of determination, is a statistical measure used to assess the goodness of fit of a regression model.
61.[Metric] Adjusted R-Squared Score
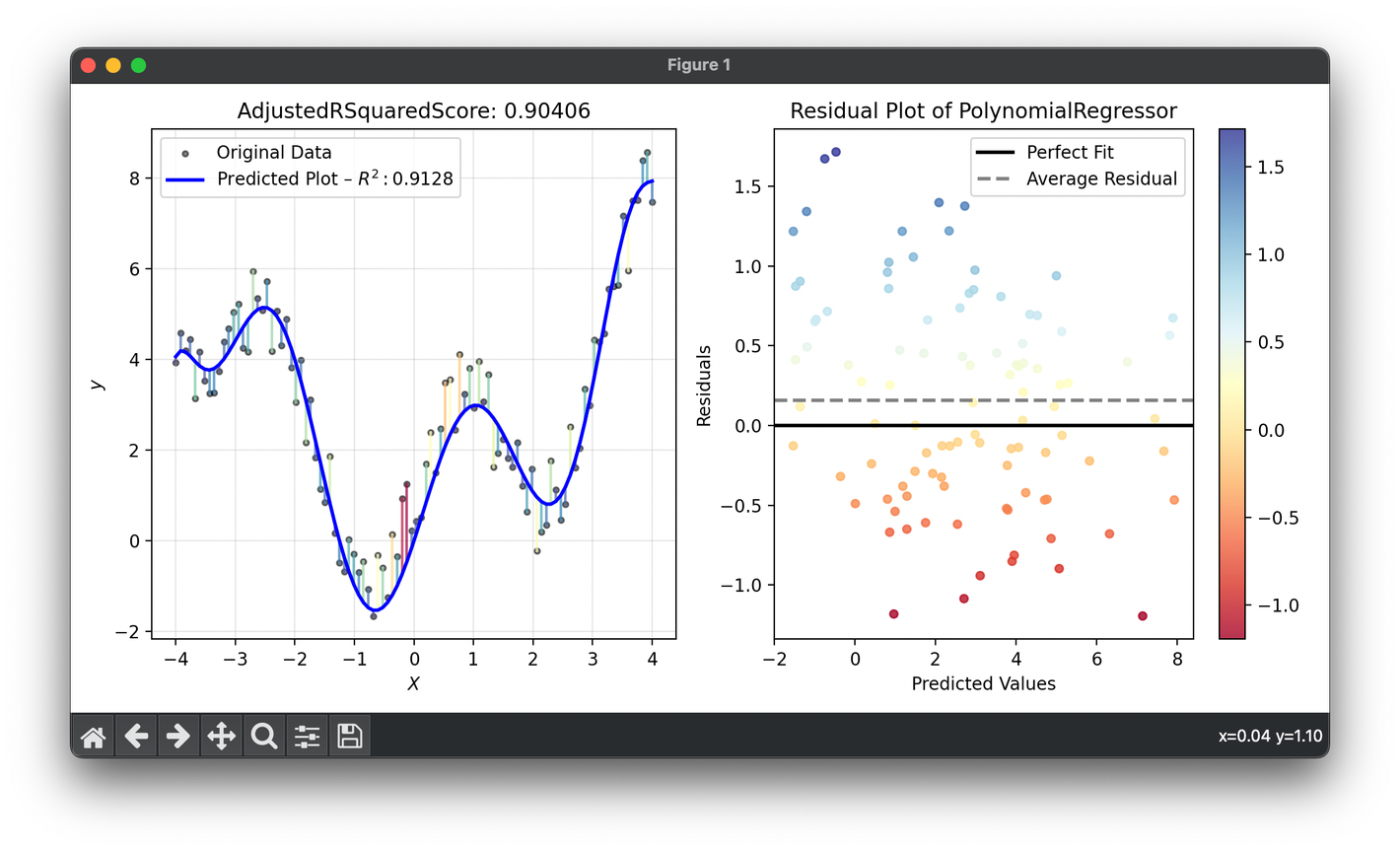
Adjusted (Adjusted Coefficient of Determination) enhances the traditional R-Squared metric by adjusting for the number of predictors in a regression.
62.[Reduction] Principal Component Analysis (PCA)
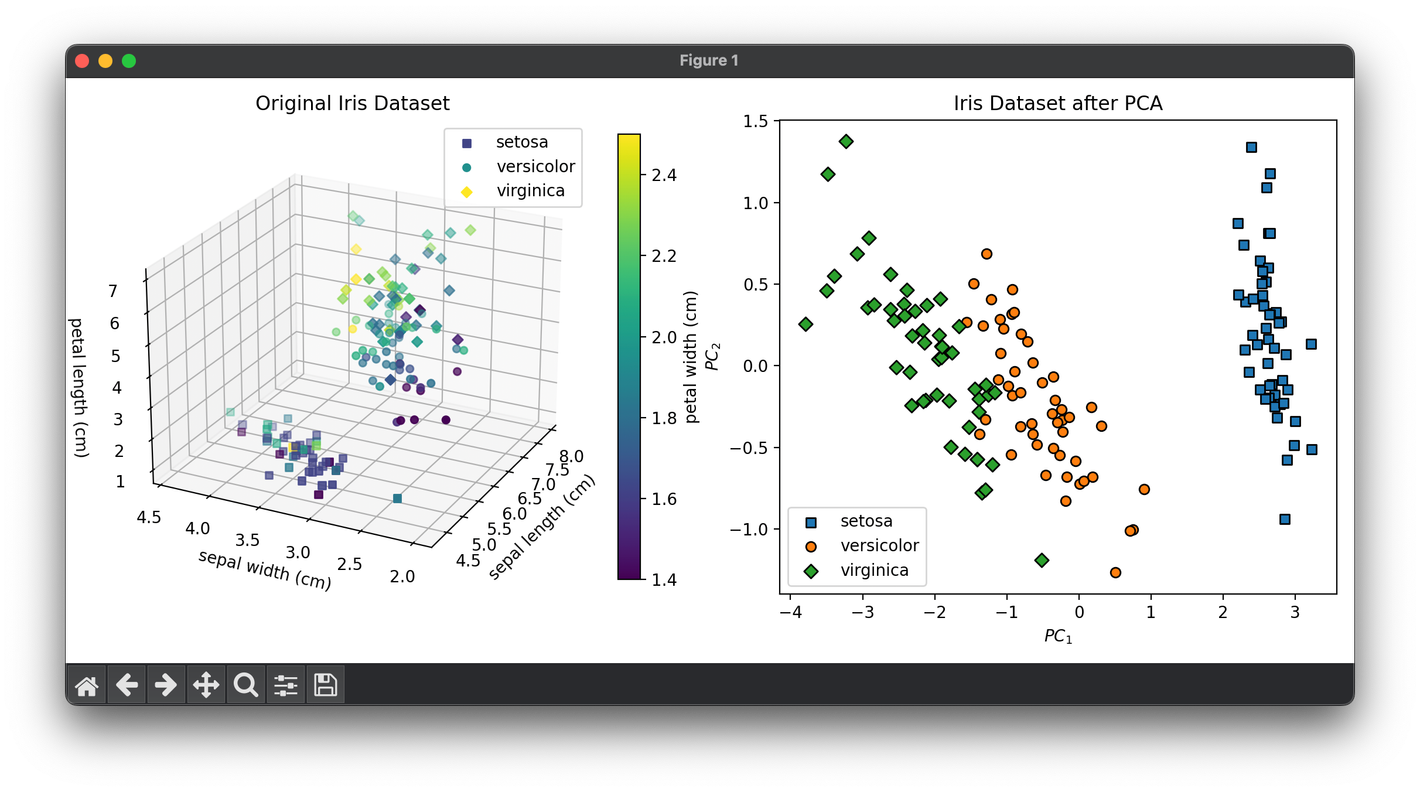
PCA is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into PCs.
63.[Reduction] Linear Discriminant Analysis (LDA)
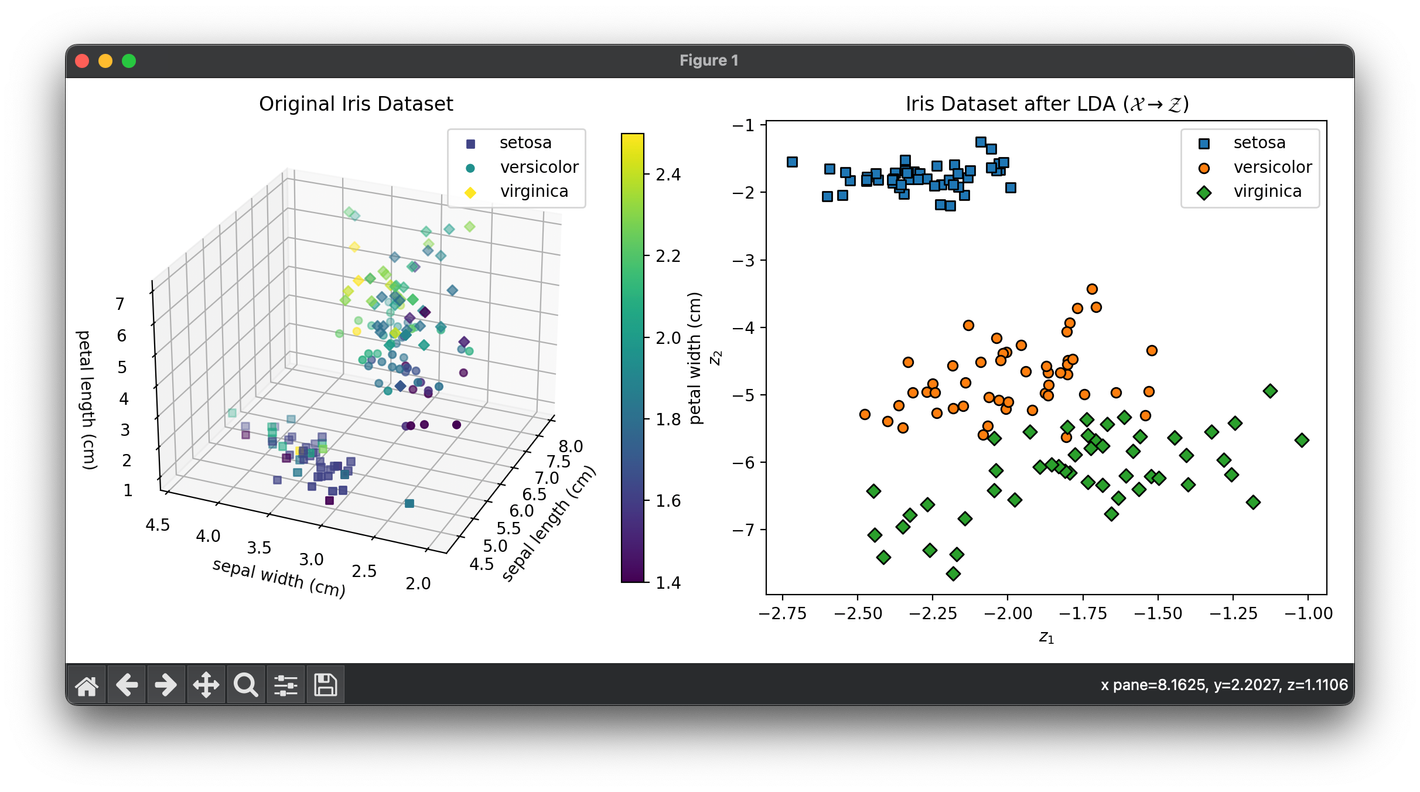
Linear Discriminant Analysis (LDA) is a supervised machine learning algorithm used for both classification and dimensionality reduction.
64.[Reduction] Kernel Principal Component Analysis (KPCA)
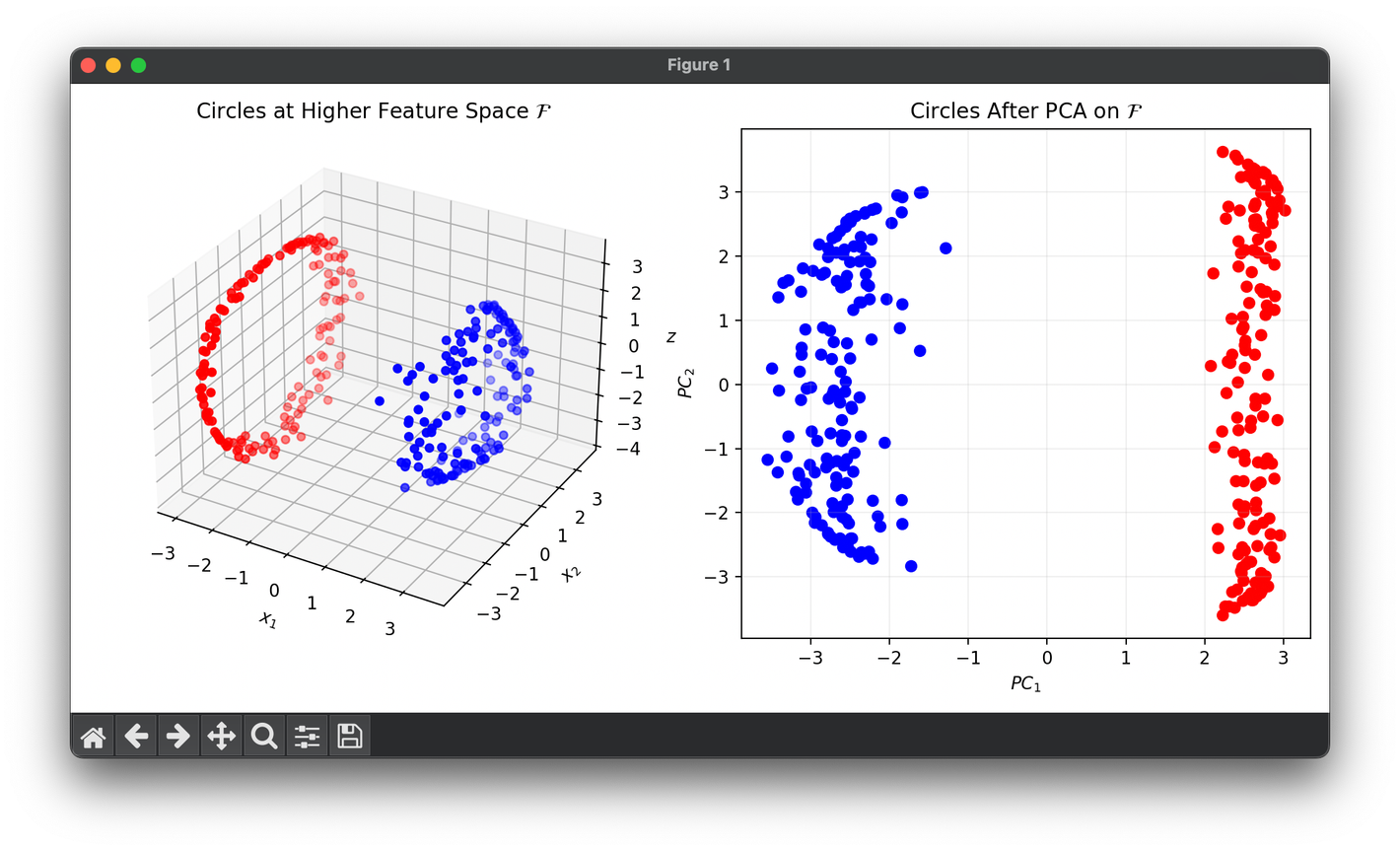
KPCA is an extension of PCA that utilizes kernel methods to perform nonlinear dimensionality reduction.
65.[Reduction] Truncated SVD
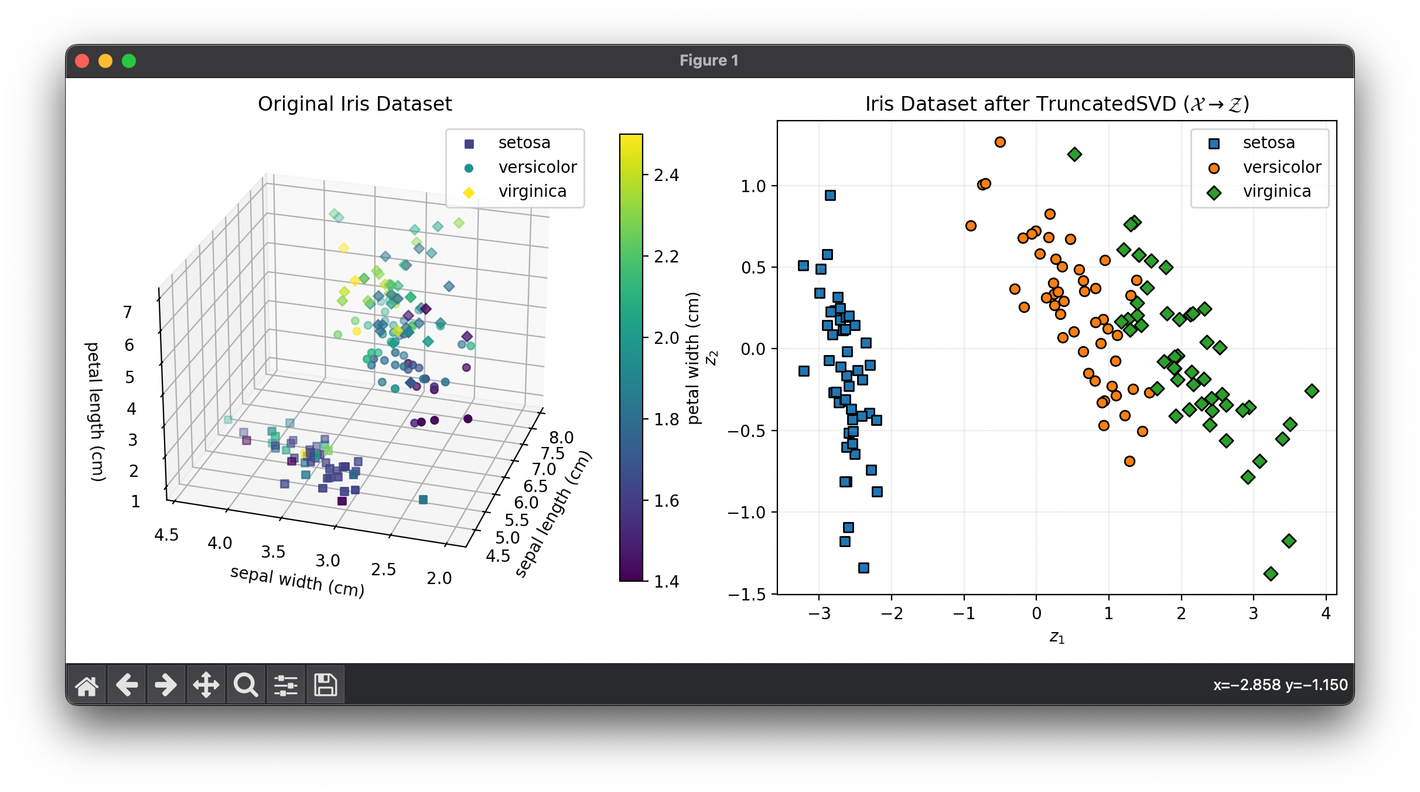
Truncated SVD is a matrix factorization technique that reduces the dimensionality of data by truncating the SVD of a matrix.
66.[Reduction] Factor Analysis (FA)
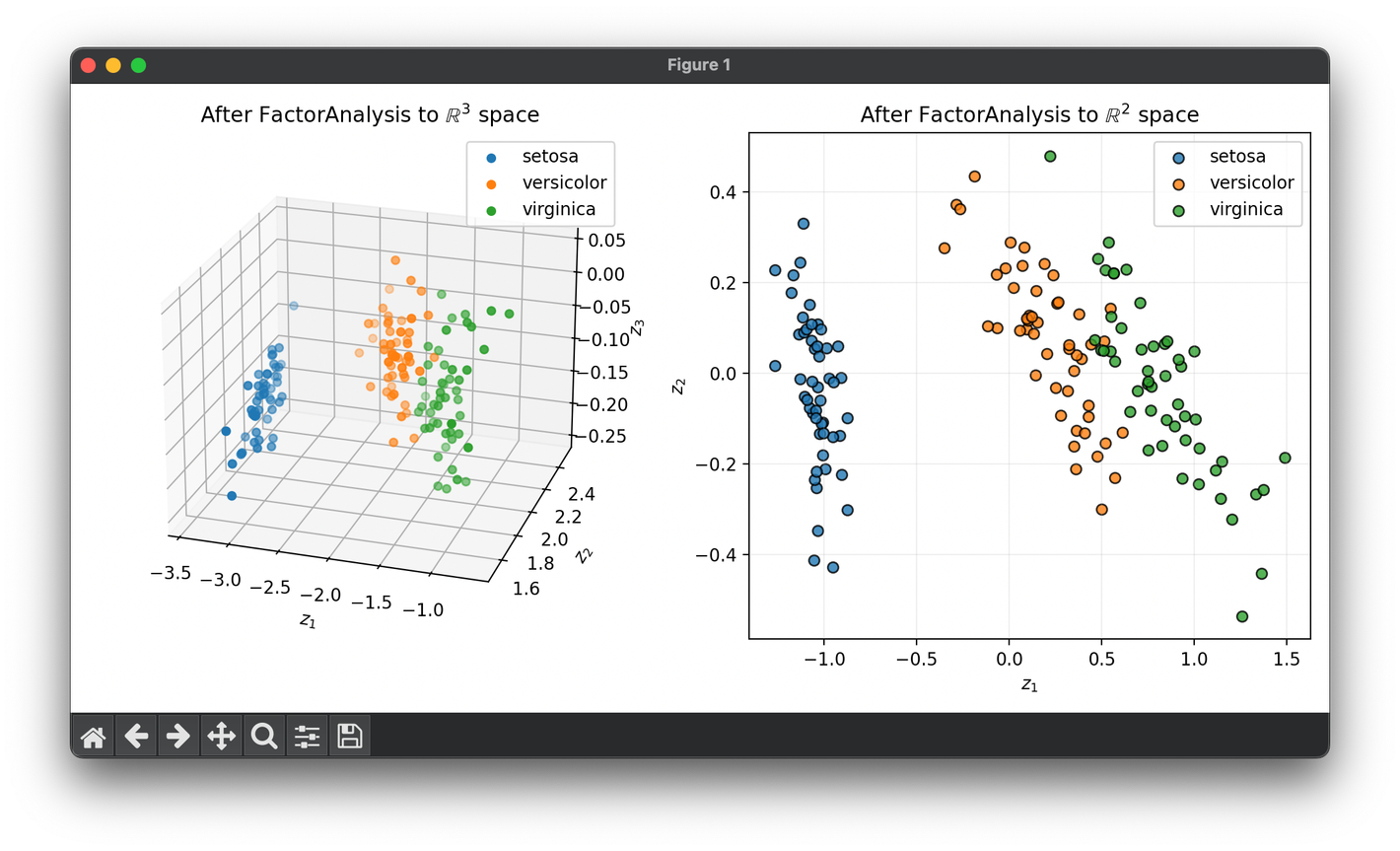
Factor Analysis is a statistical method used to describe variability among observed, correlated variables in terms of a lower number of 'factors'.
67.[Reduction] Kernel Discriminant Analysis (KDA)
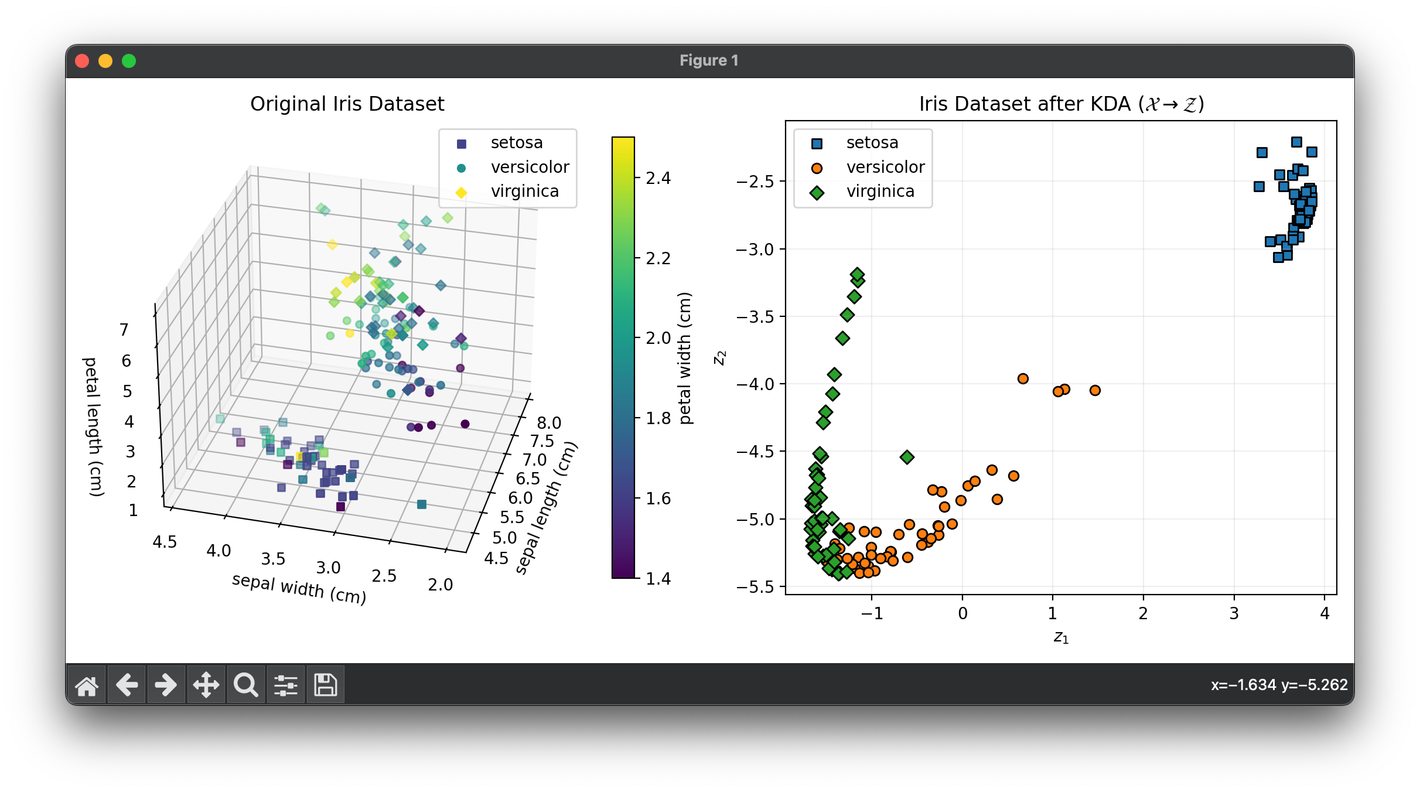
Kernel Discriminant Analysis is an extension of Linear Discriminant Analysis that employs kernel methods to find a linear combination of features.
68.[Reduction] Canonical Correlation Analysis (CCA)
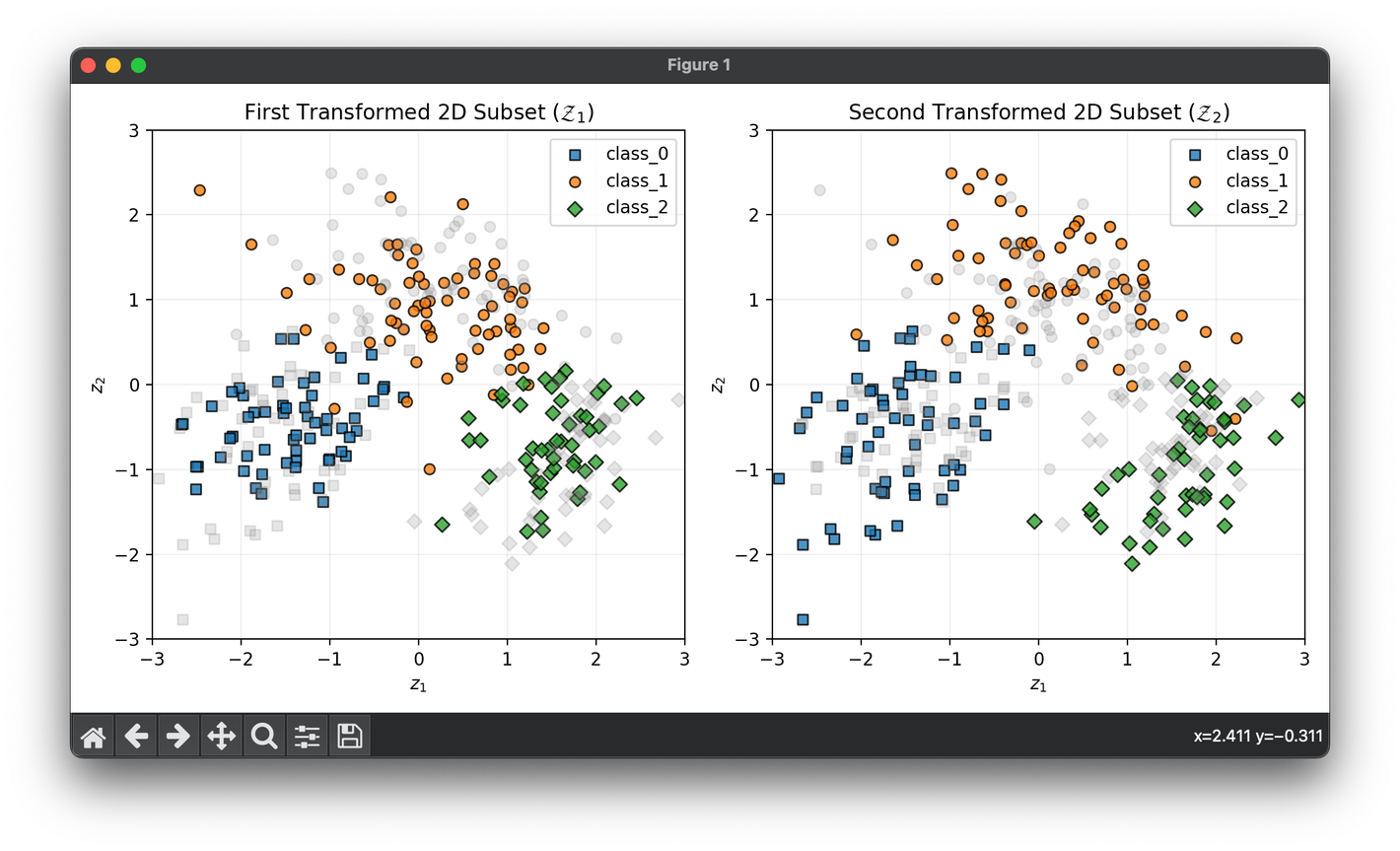
CCA is a multivariate statistical method concerned with understanding the relationships between two sets of variables.
69.[Reduction] t-Distributed Stochastic Neighbor Embedding (t-SNE)
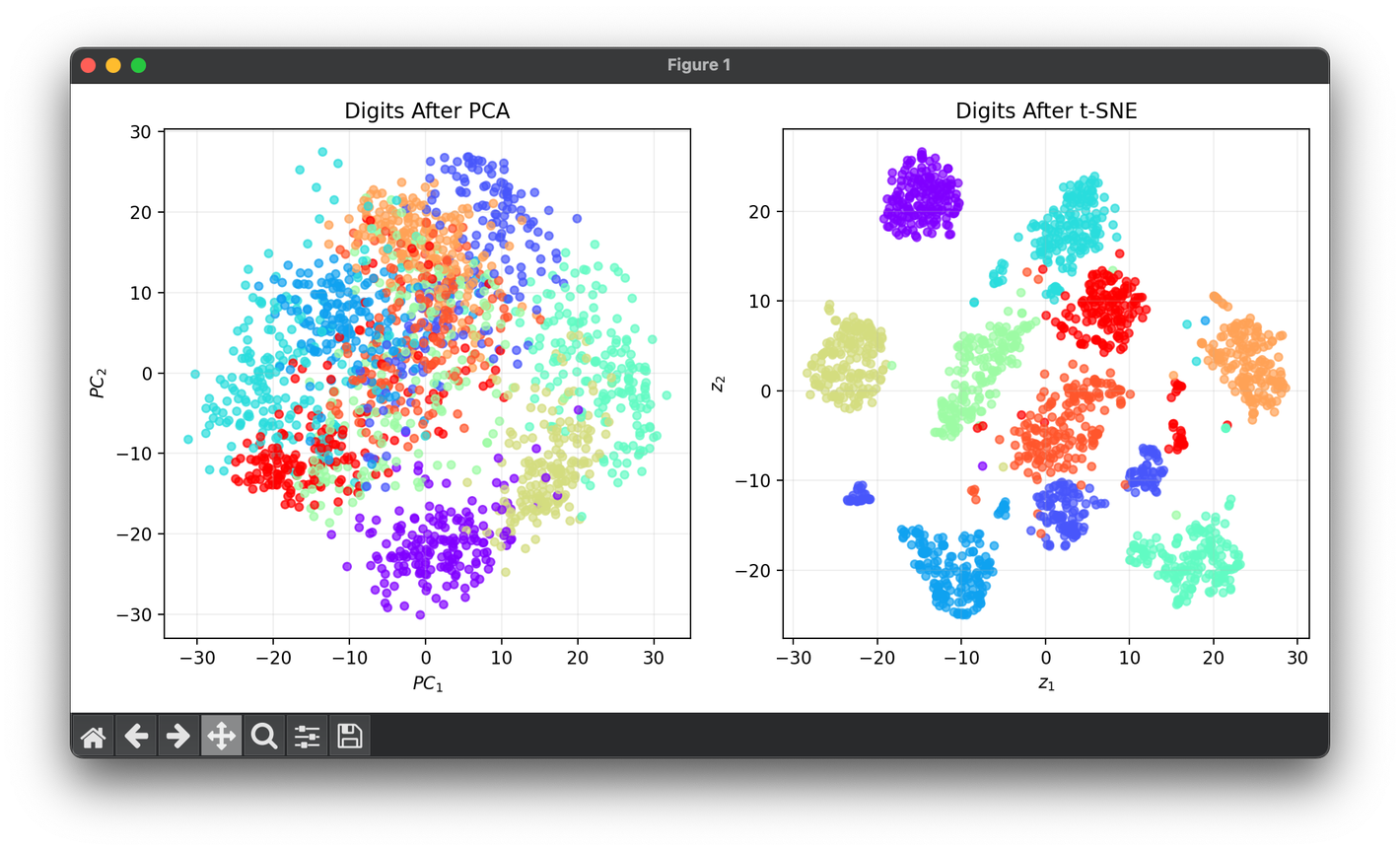
t-SNE is a powerful machine learning algorithm for dimensionality reduction, particularly for the visualization of high-dimensional datasets.
70.[Reduction] Multidimensional Scaling (MDS)
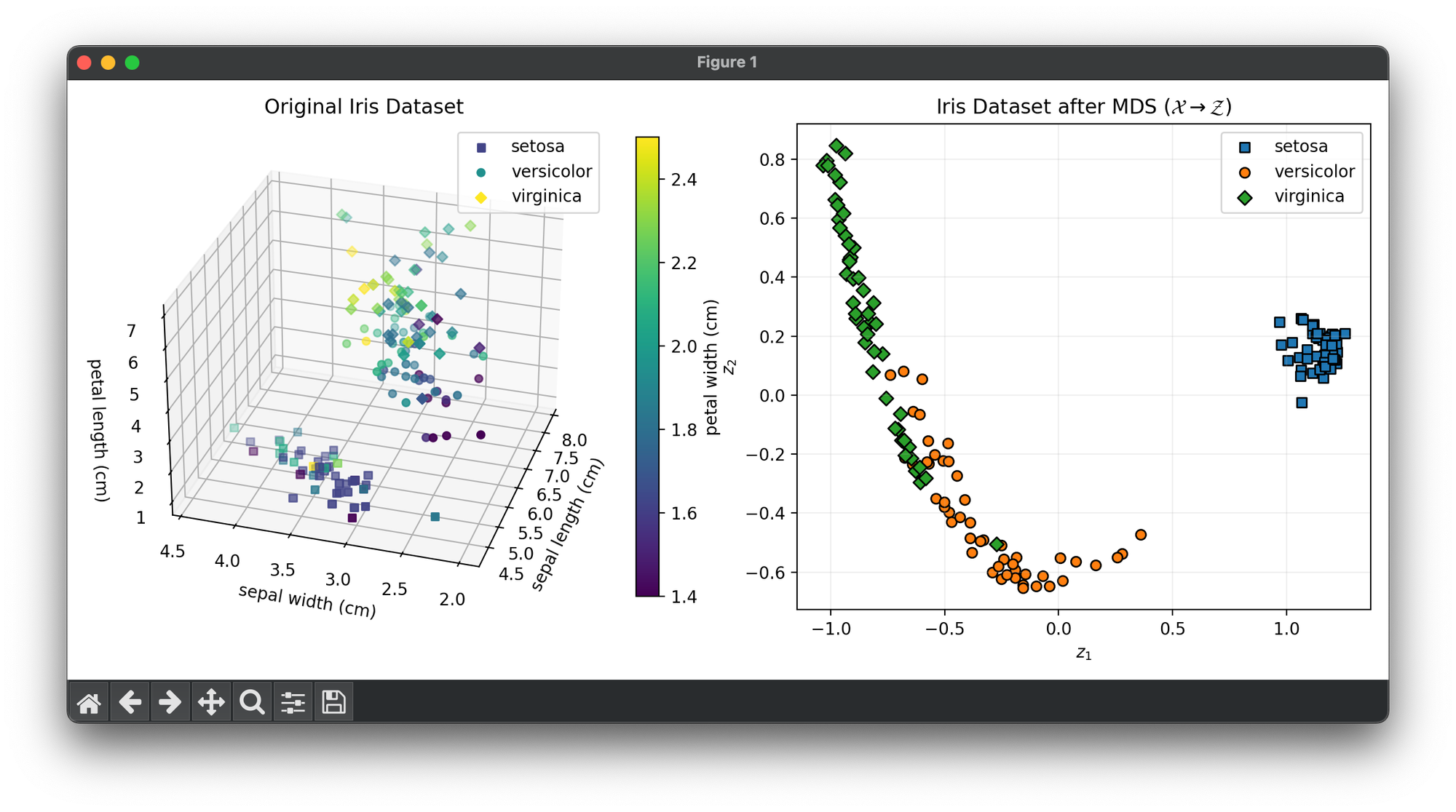
Multidimensional Scaling (MDS) is a statistical technique used for analyzing similarity or dissimilarity data.
71.[Reduction] Metric MDS
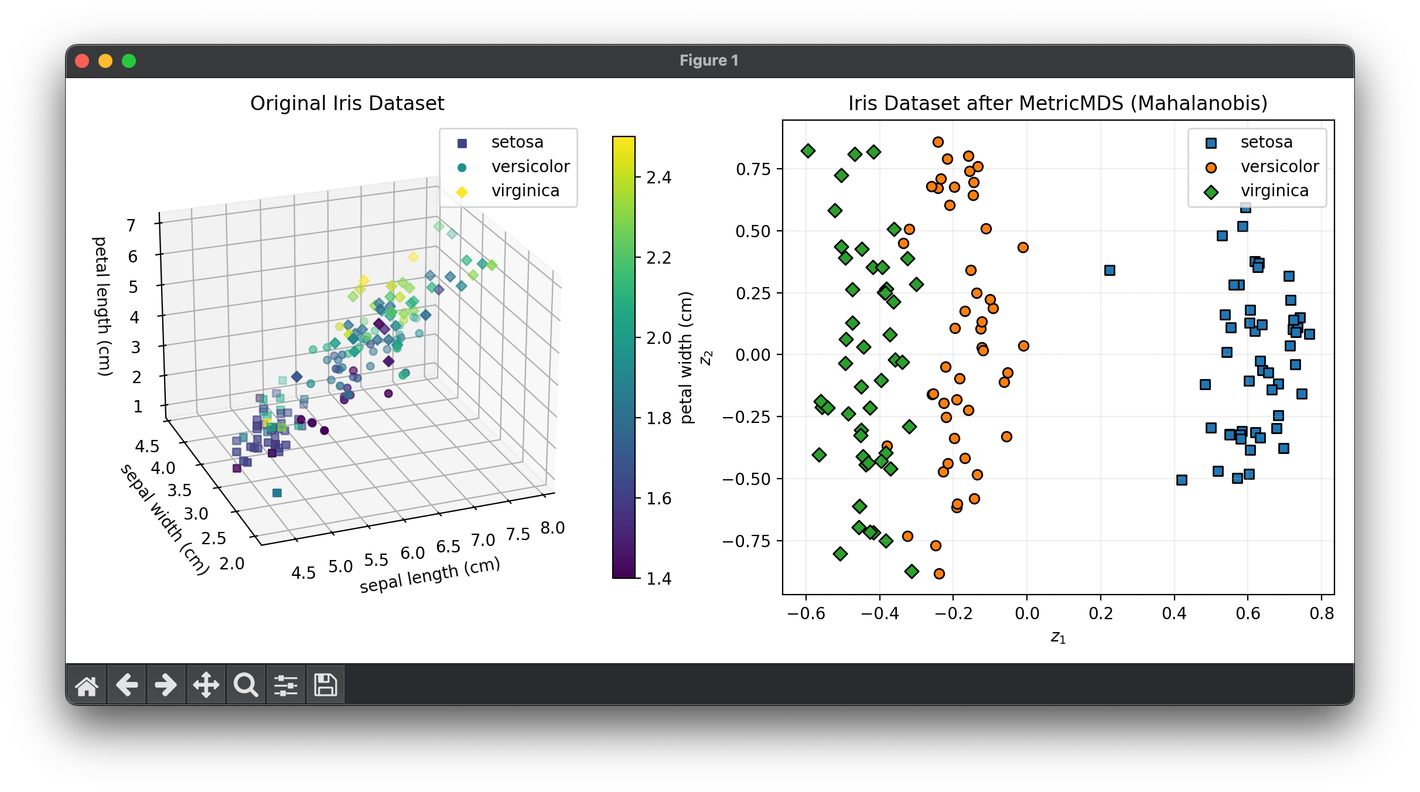
Metric MDS is a form of MDS that focuses on preserving the metric distances between point in a high-space when mapping them to a low-space.
72.[Reduction] Landmark MDS
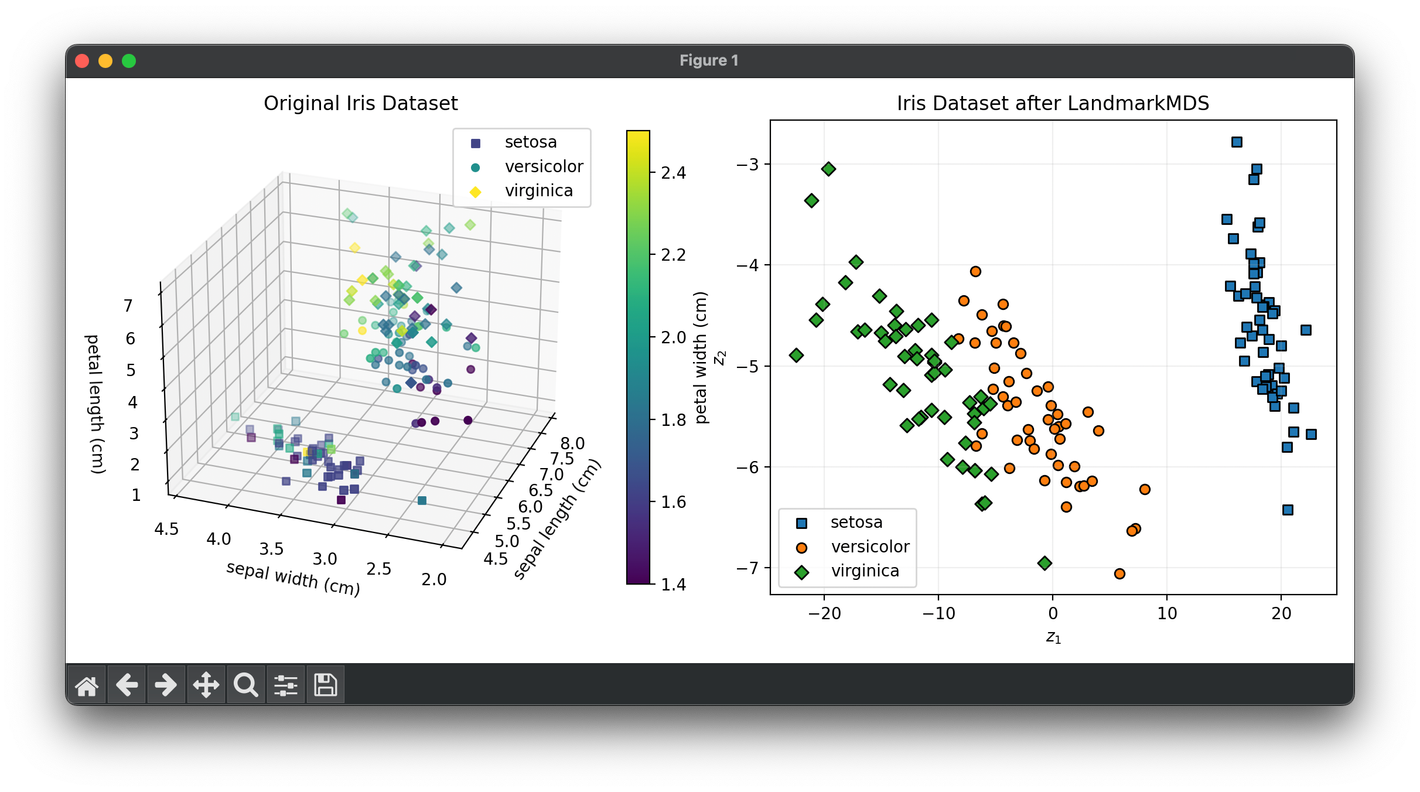
Landmark MDS is an advanced variation of the classical MDS technique, which is aimed at dimensionality reduction and visualization.
73.[Reduction] Locally Linear Embedding (LLE)
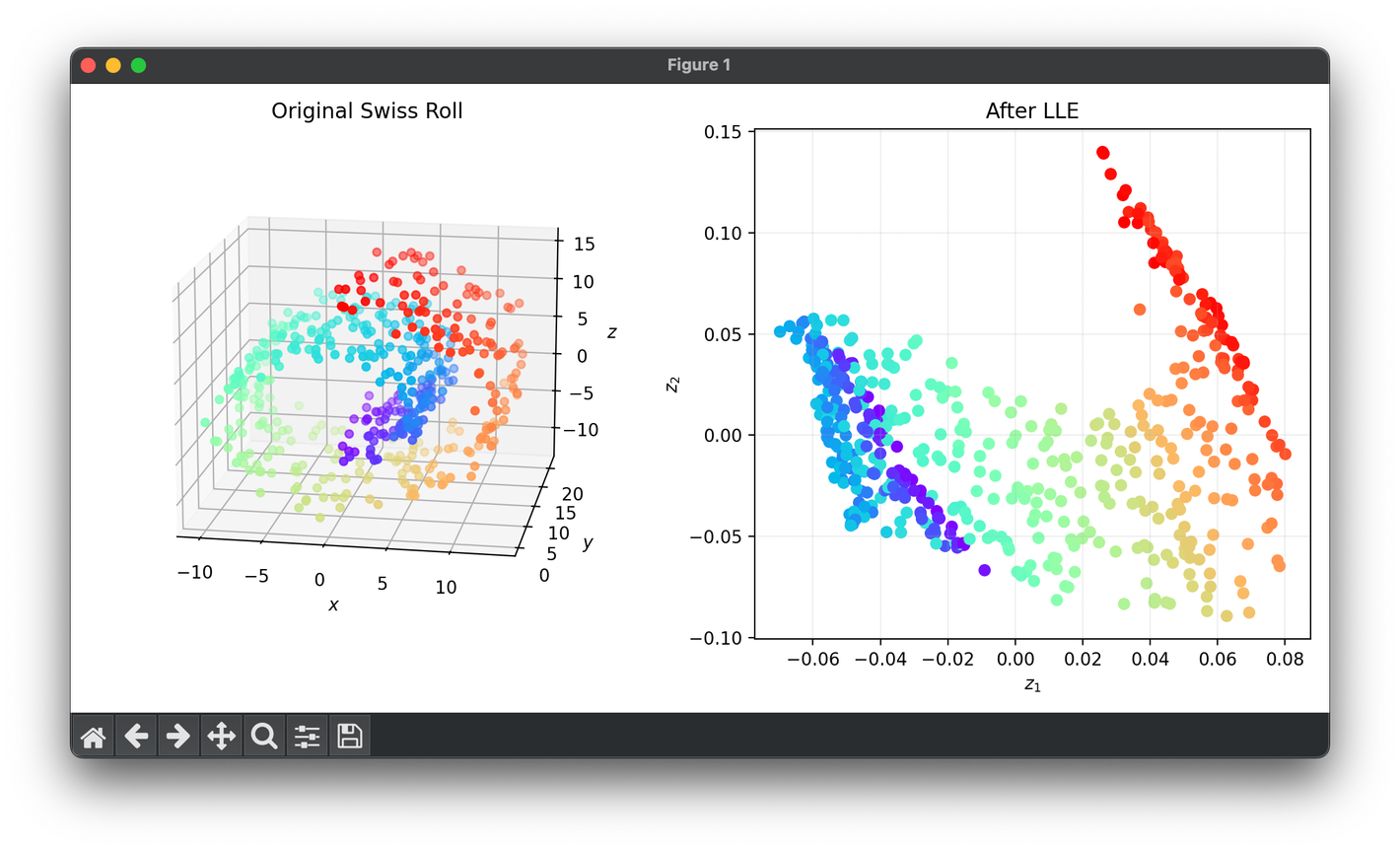
Locally Linear Embedding (LLE) is a non-linear dimensionality reduction technique widely used for exploring the structure of high-dimensional data.
74.[Reduction] Modified Locally Linear Embedding (MLLE)
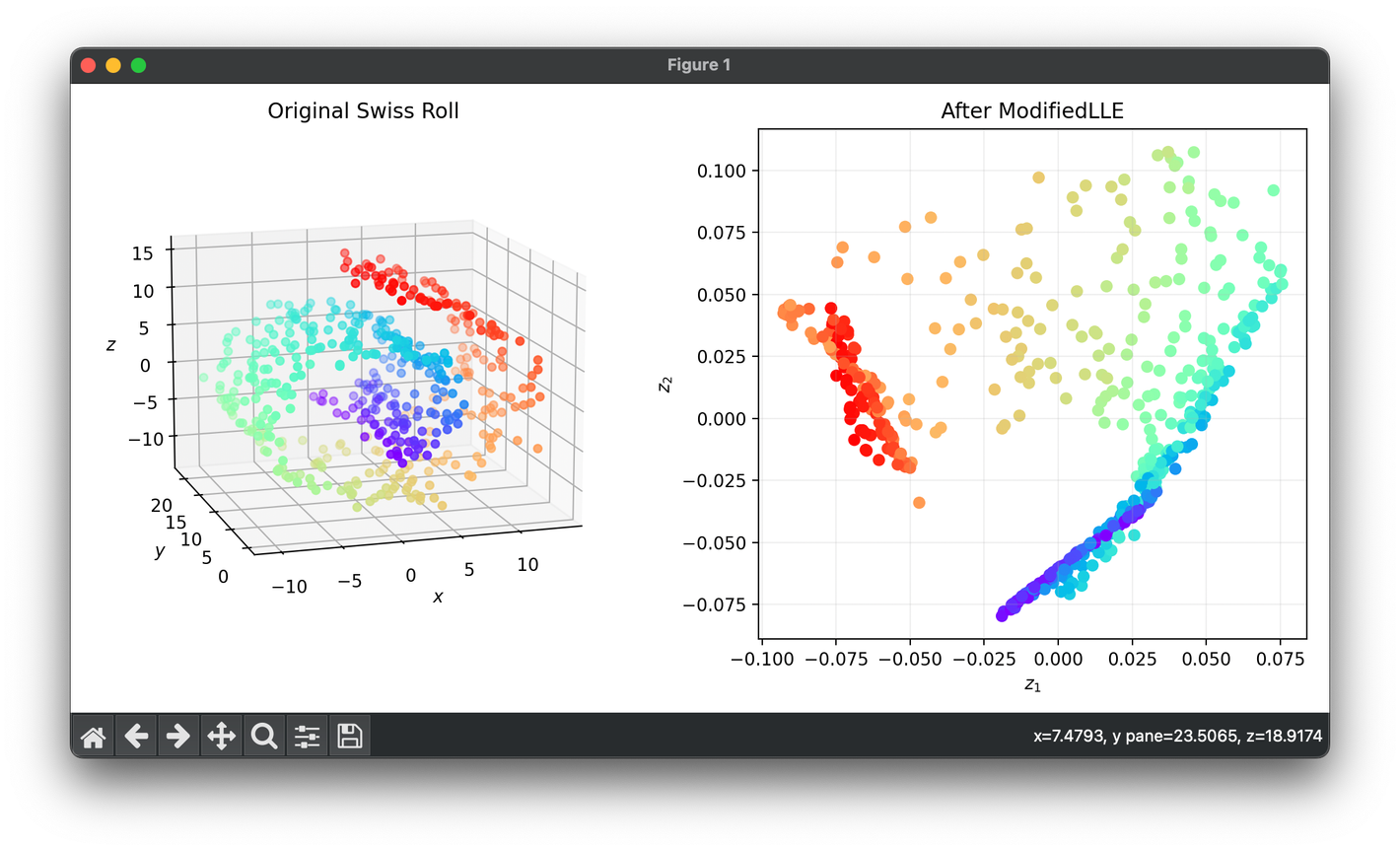
MLLE is an enhanced version of the classic LLE algorithm, designed to address some of its limitations, particularly in preserving the local geometry.
75.[Reduction] Hessian Locally Linear Embedding (HLLE)
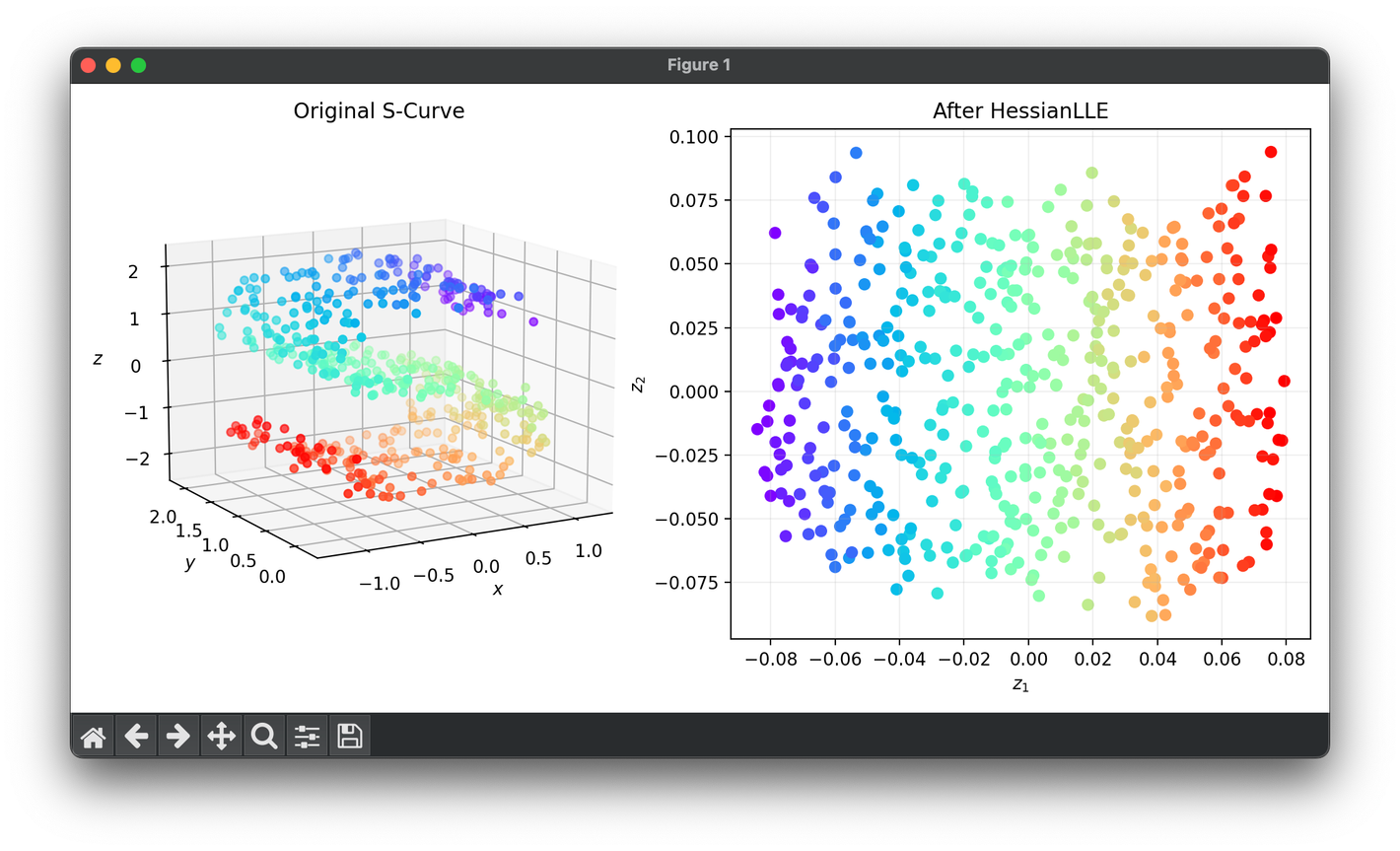
HLLE is an advanced non-linear dimensionality reduction technique used to unfold high-dimensional data into lower-dimensional spaces.
76.[Reduction] Sammon Mapping
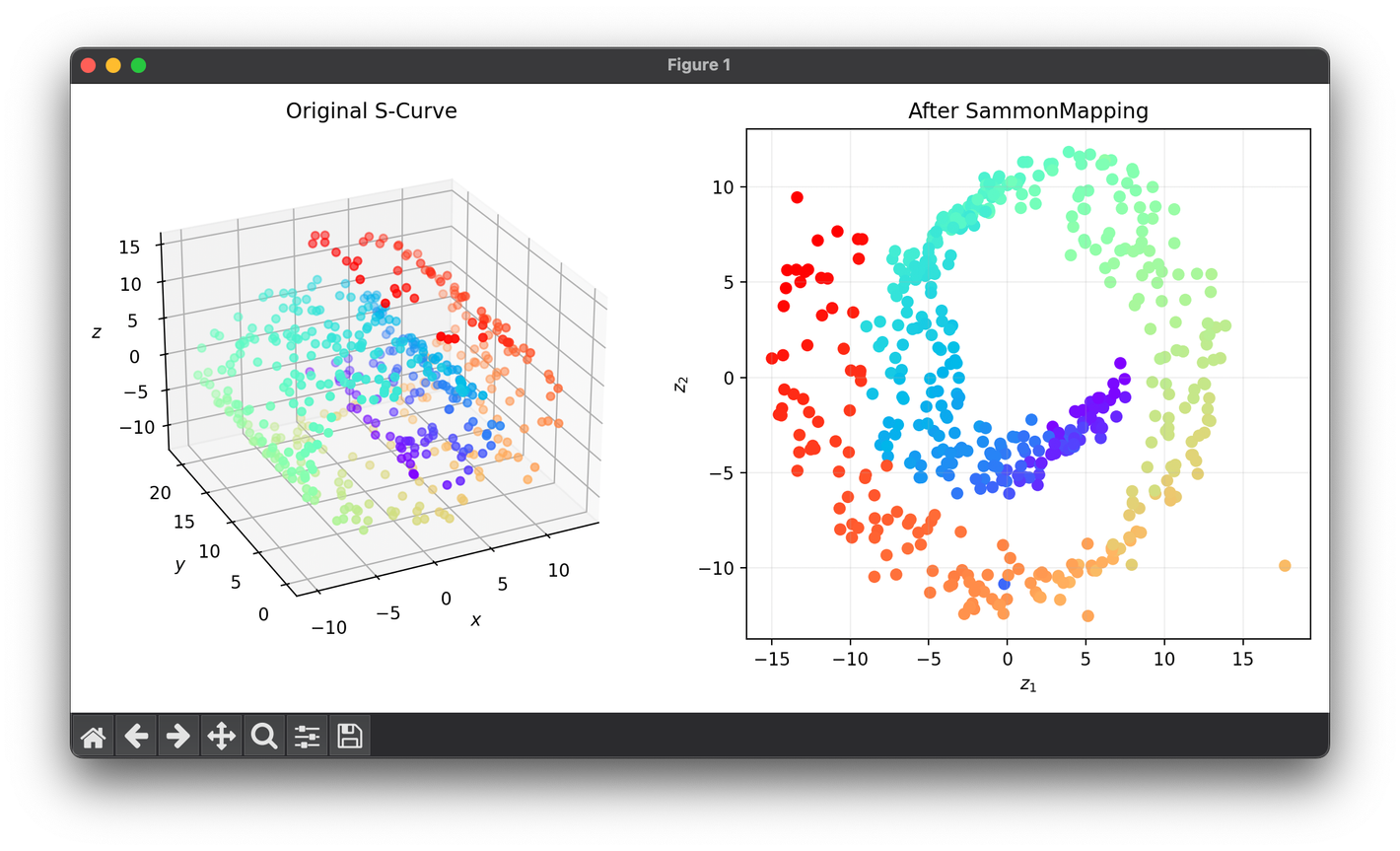
Sammon Mapping is a non-linear dimensionality reduction technique introduced by John W. Sammon in 1969.
77.[Reduction] Laplacian Eigenmap
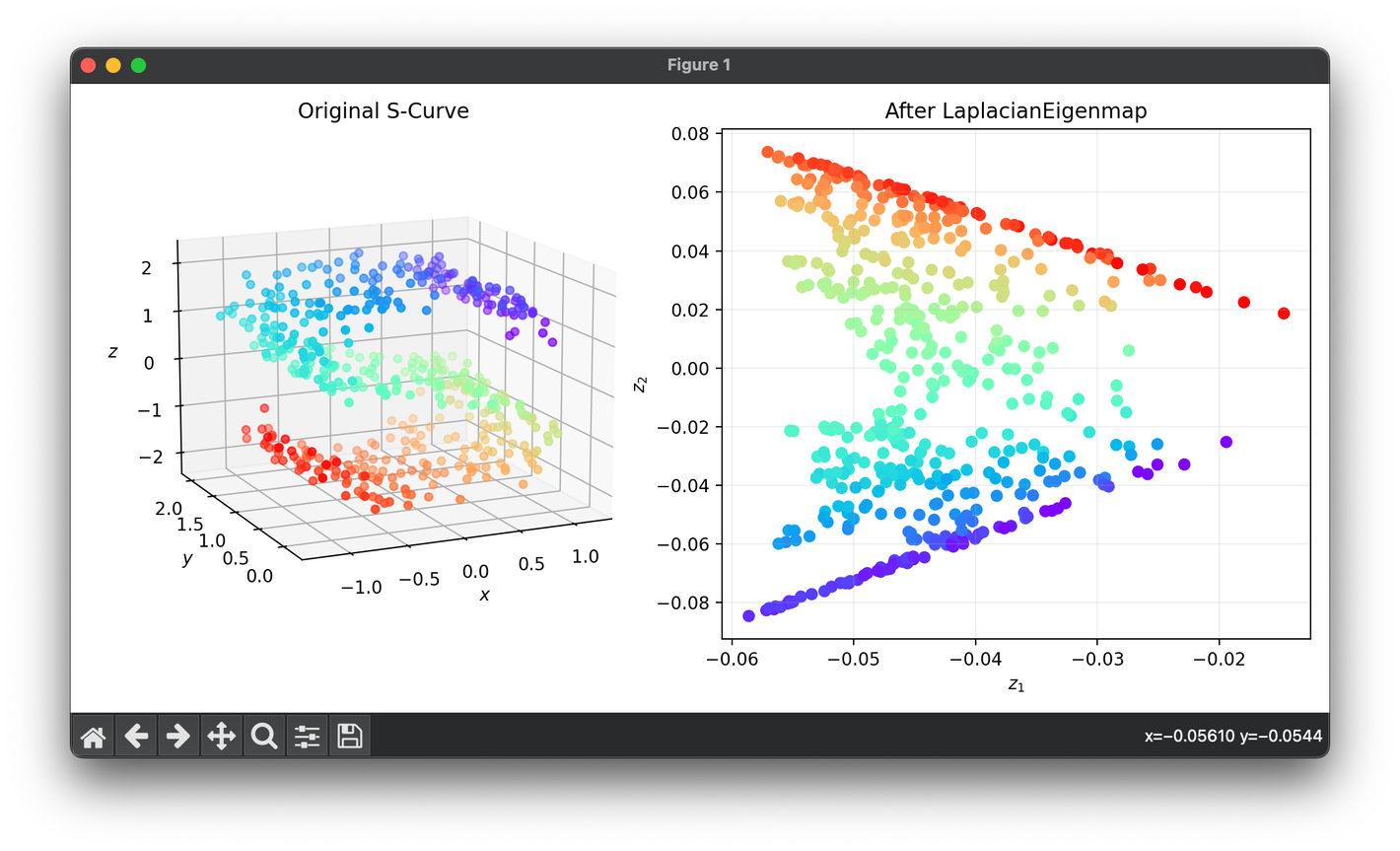
Laplacian Eigenmap is a dimensionality reduction technique used in machine learning and data science to project high-dimensional data into a lower-dim
78.[Reduction] Conformal Isometric Mapping (C-Isomap)
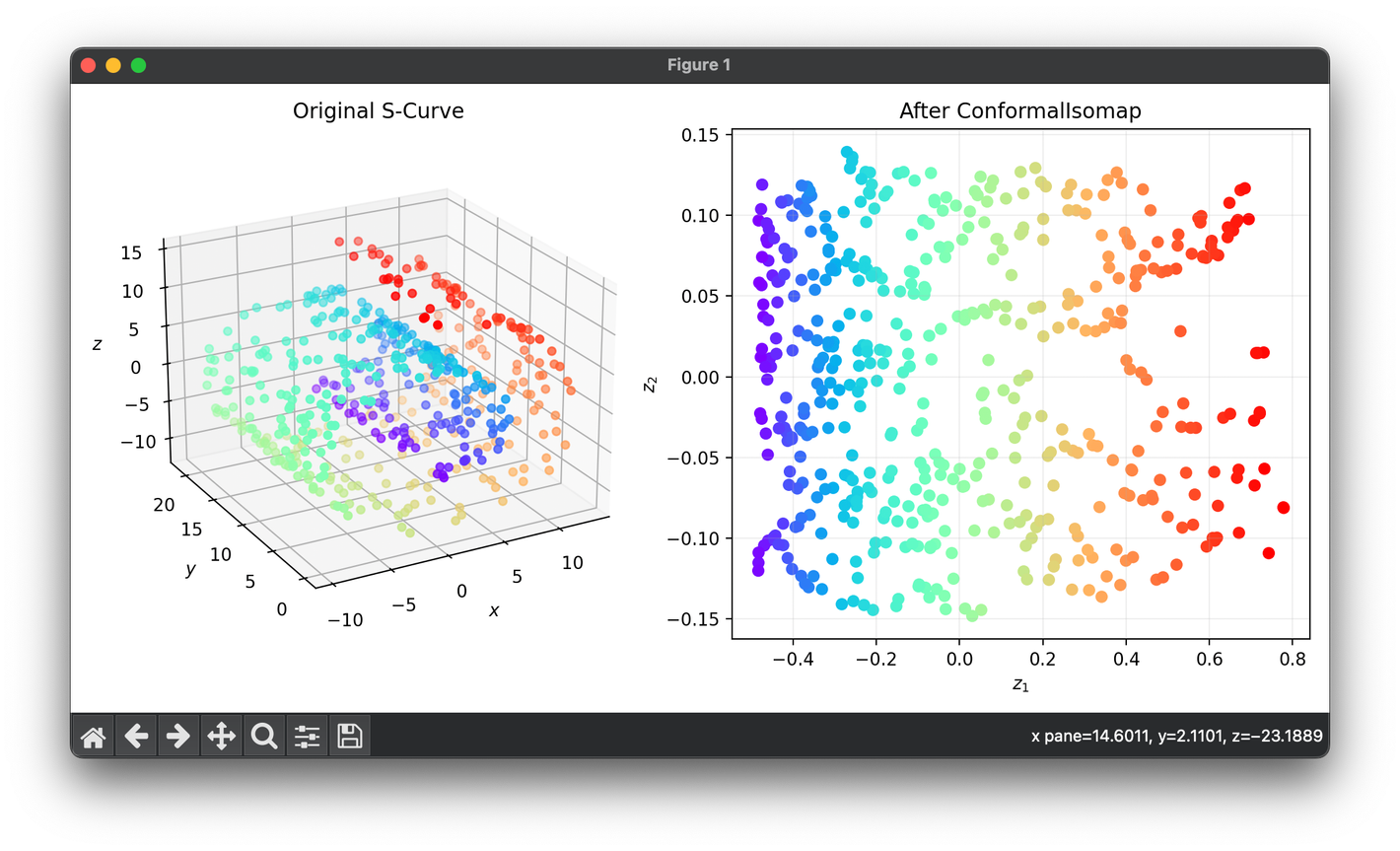
C-Isomap refines the Isometric Mapping (Isomap) technique by incorporating the principle of conformality into the dimensionality reduction.
79.[Reduction] Locally Tangent Space Alignment (LTSA)
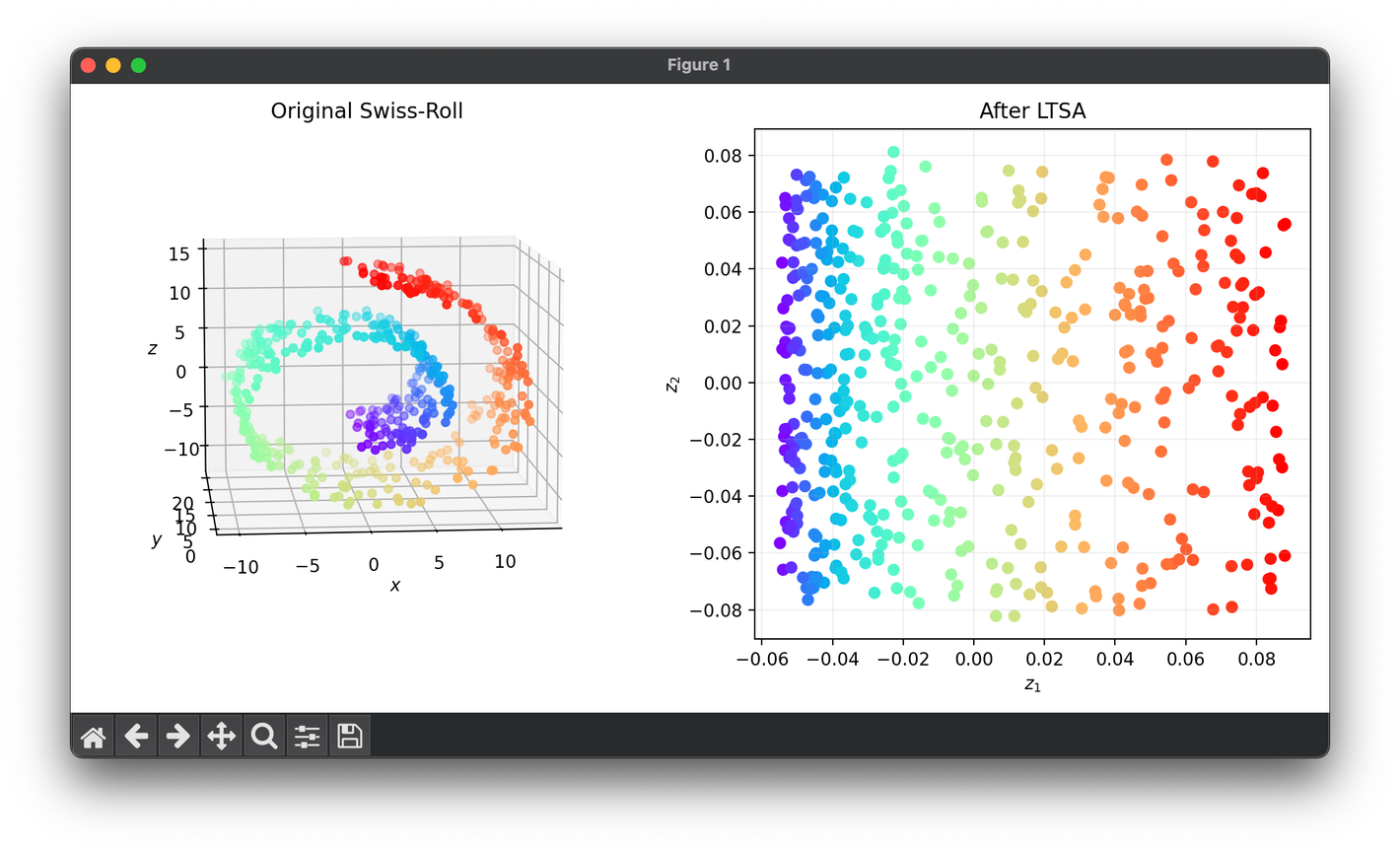
LTSA is a prominent technique in the realm of non-linear dimensionality reduction, focusing on preserving the local geometry of high-dimensional data.
80.[Reduction] Sequential Backward Selection (SBS)
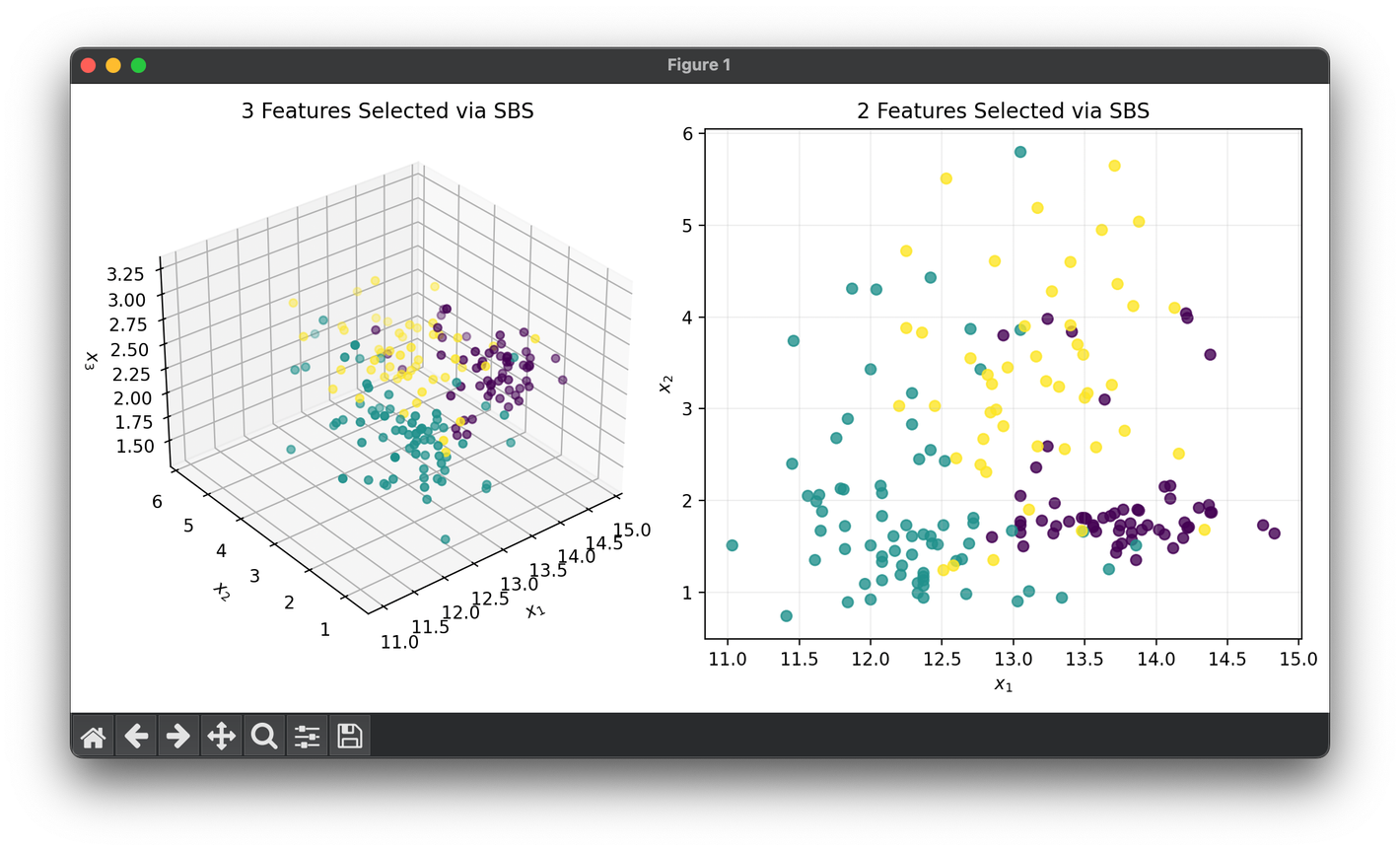
SBS is a feature selection technique used in machine learning to reduce the dimensionality of the data by sequentially removing features.
81.[Reduction] Sequential Forward Selection (SFS)
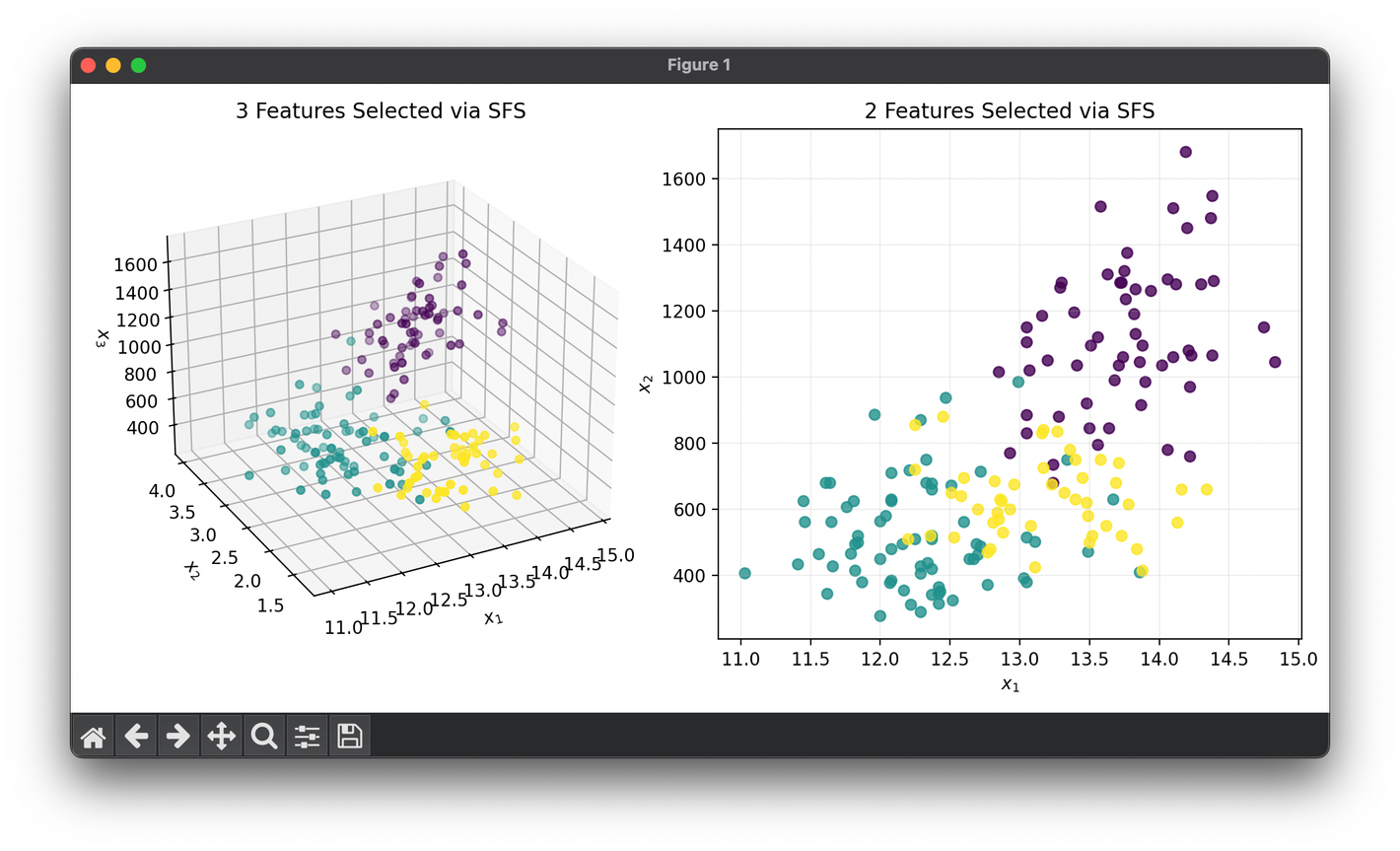
Sequential Forward Selection (SFS) is a heuristic algorithm used in machine learning for feature selection.
82.[Reduction] Recursive Feature Elimination (RFE)
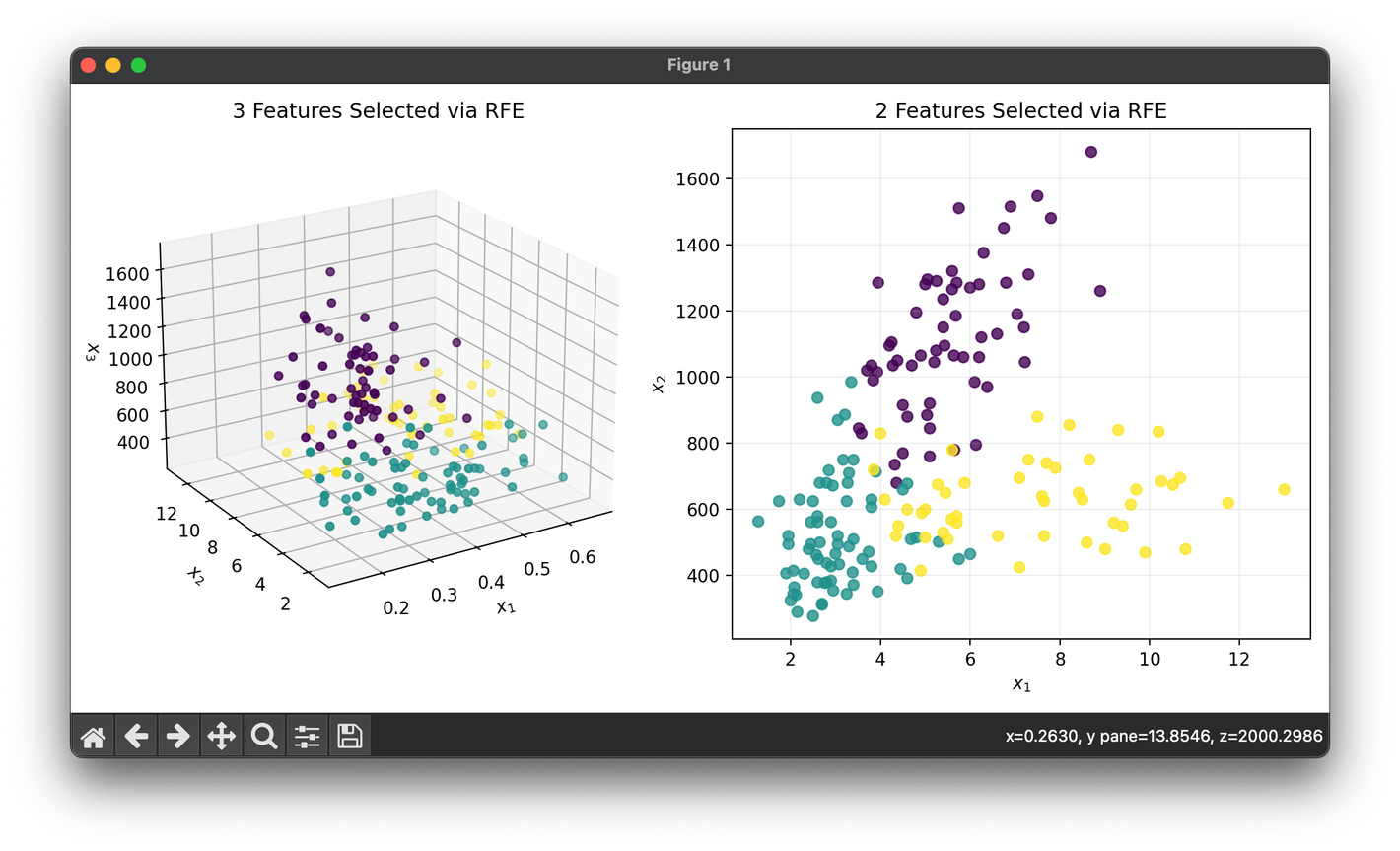
RFE is a feature selection method used in machine learning to identify and select features by recursively considering smaller sets of features.
83.[Regressor] Poisson Regression

Poisson Regression is a statistical approach used to model count data, particularly for outcomes that represent counts or rates following Pois. dist.
84.[Regressor] Negative Binomial Regression
Negative Binomial Regression offers a robust alternative to Poisson regression for modeling count data, particularly when overdispersion occurs.
85.[Regressor] Gamma Regression
Gamma Regression is utilized for modeling positive continuous data with skewed distributions.
86.[Regressor] Beta Regression
Beta Regression is tailored for modeling variables that take values in the open interval (0, 1), making it ideal for proportions.
87.[Regressor] Inverse Gaussian Regression
Inverse Gaussian Regression is a specialized regression model used for positive continuous outcomes, particularly when the data exhibit a long tail.
88.[Regressor] Ridge Regression
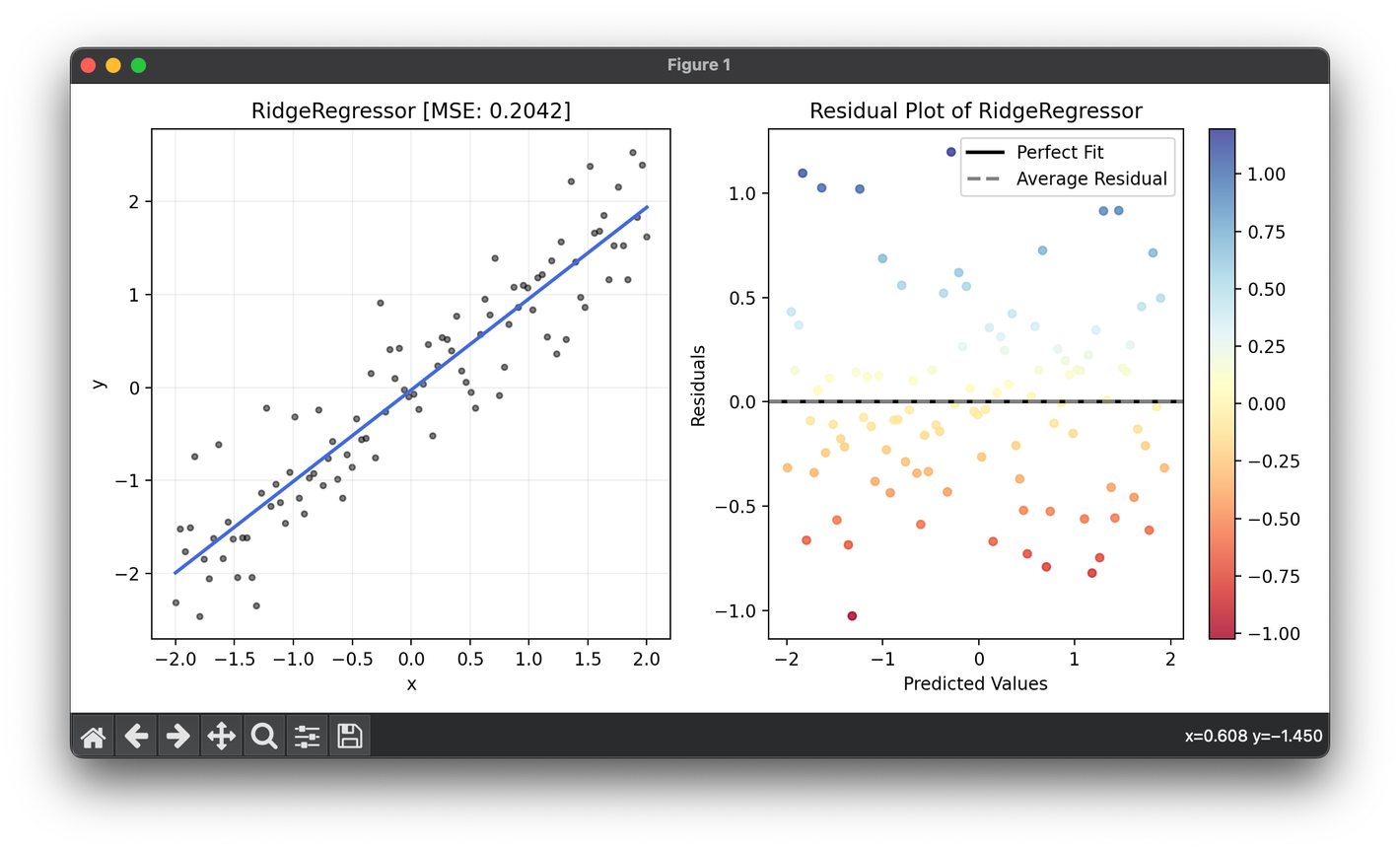
Ridge regression, also known as Tikhonov regularization, is a technique used for analyzing multiple regression data that suffer from multicollinearity
89.[Regressor] Lasso Regression
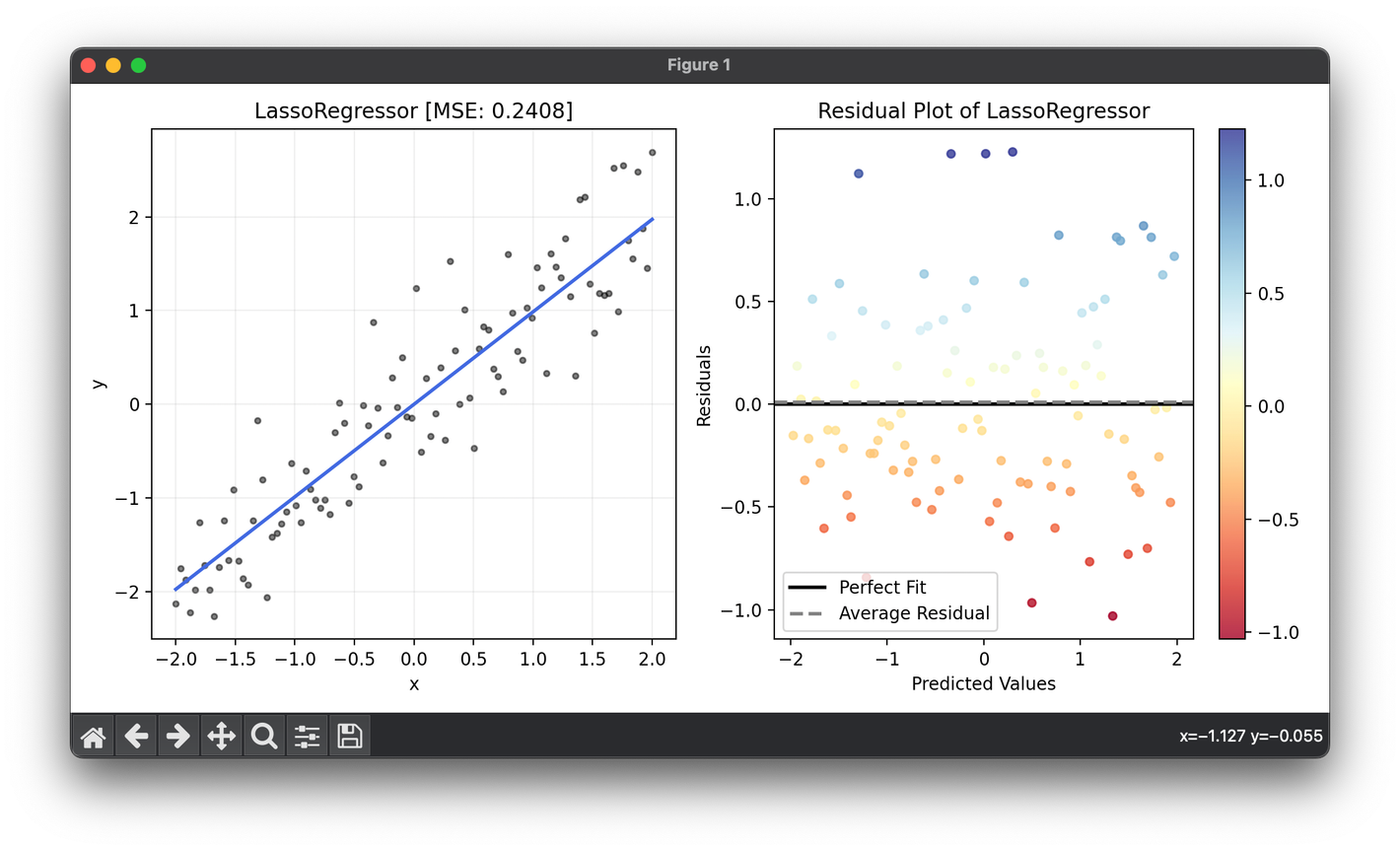
Lasso regression, standing for Least Absolute Shrinkage and Selection Operator, is a regression analysis method that performs variable selection & reg
90.[Regressor] Elastic-Net Regresison
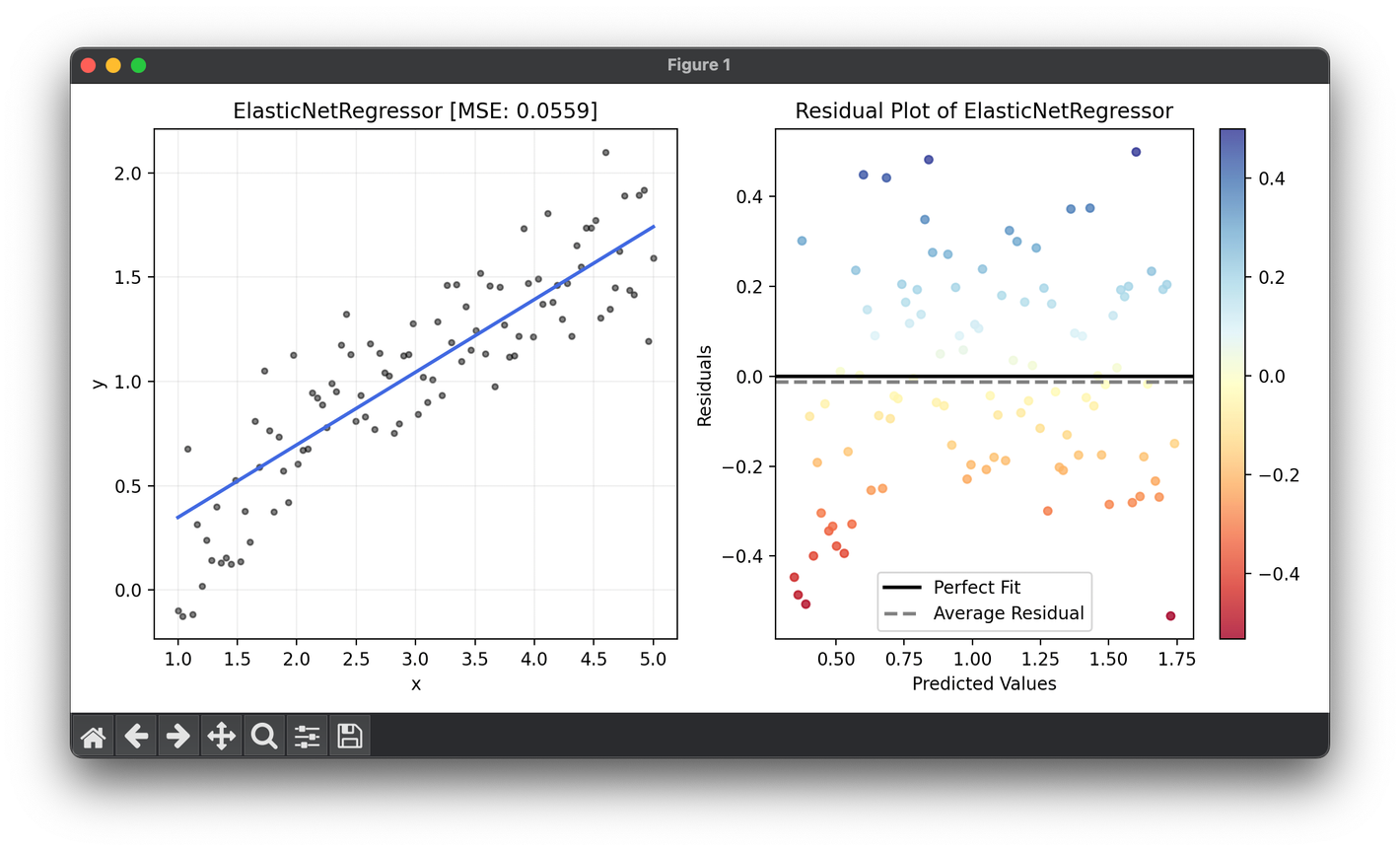
Elastic Net Regression is an advanced regularization technique that synergizes the regularization aspects of both Lasso and Ridge regularization.
91.[Regressor] Linear Regression (OLS)
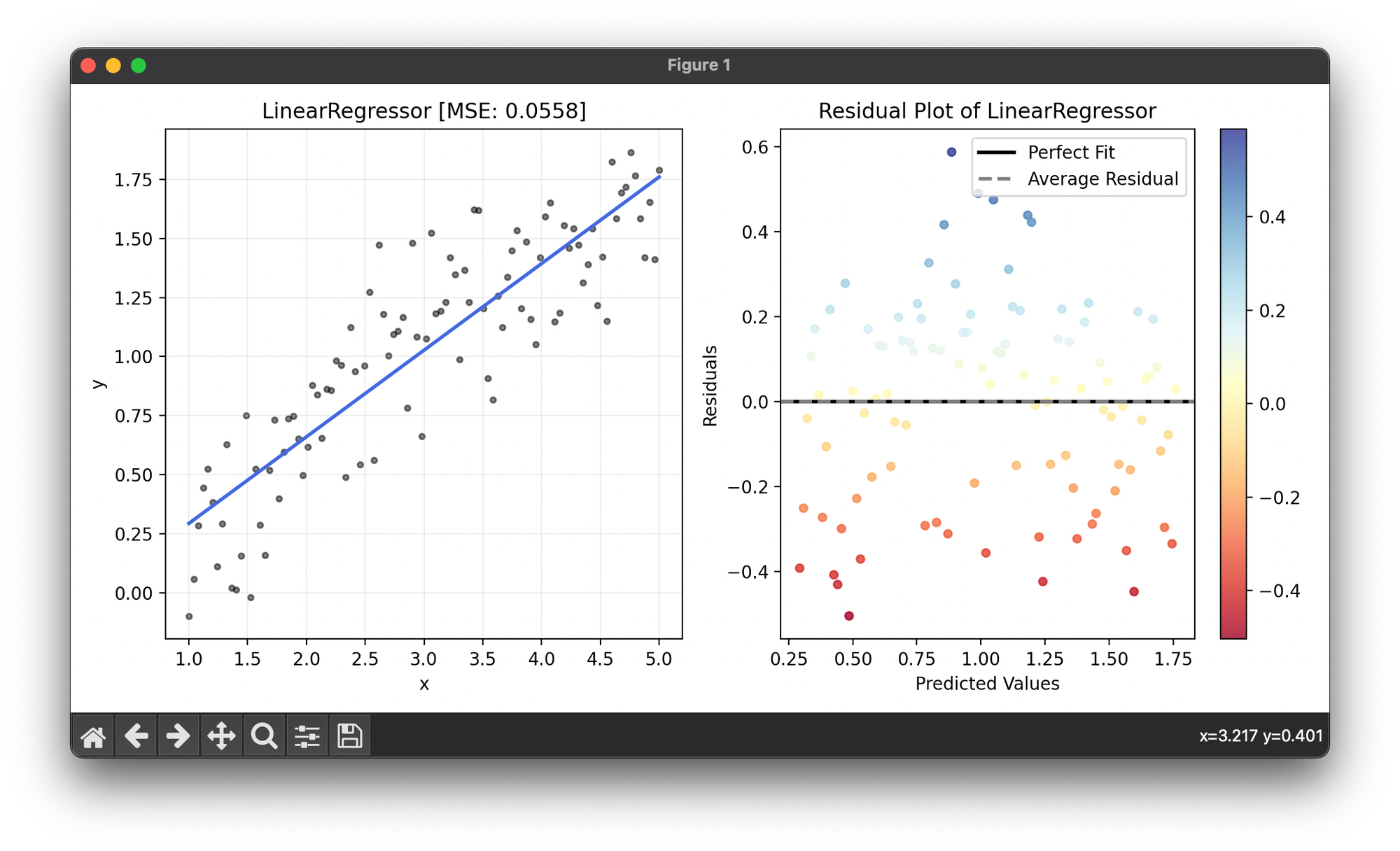
Linear regression is a foundational statistical method used to model the relationship between a dependent variable and one or more indep. variables.
92.[Regressor] Kernel Ridge Regression
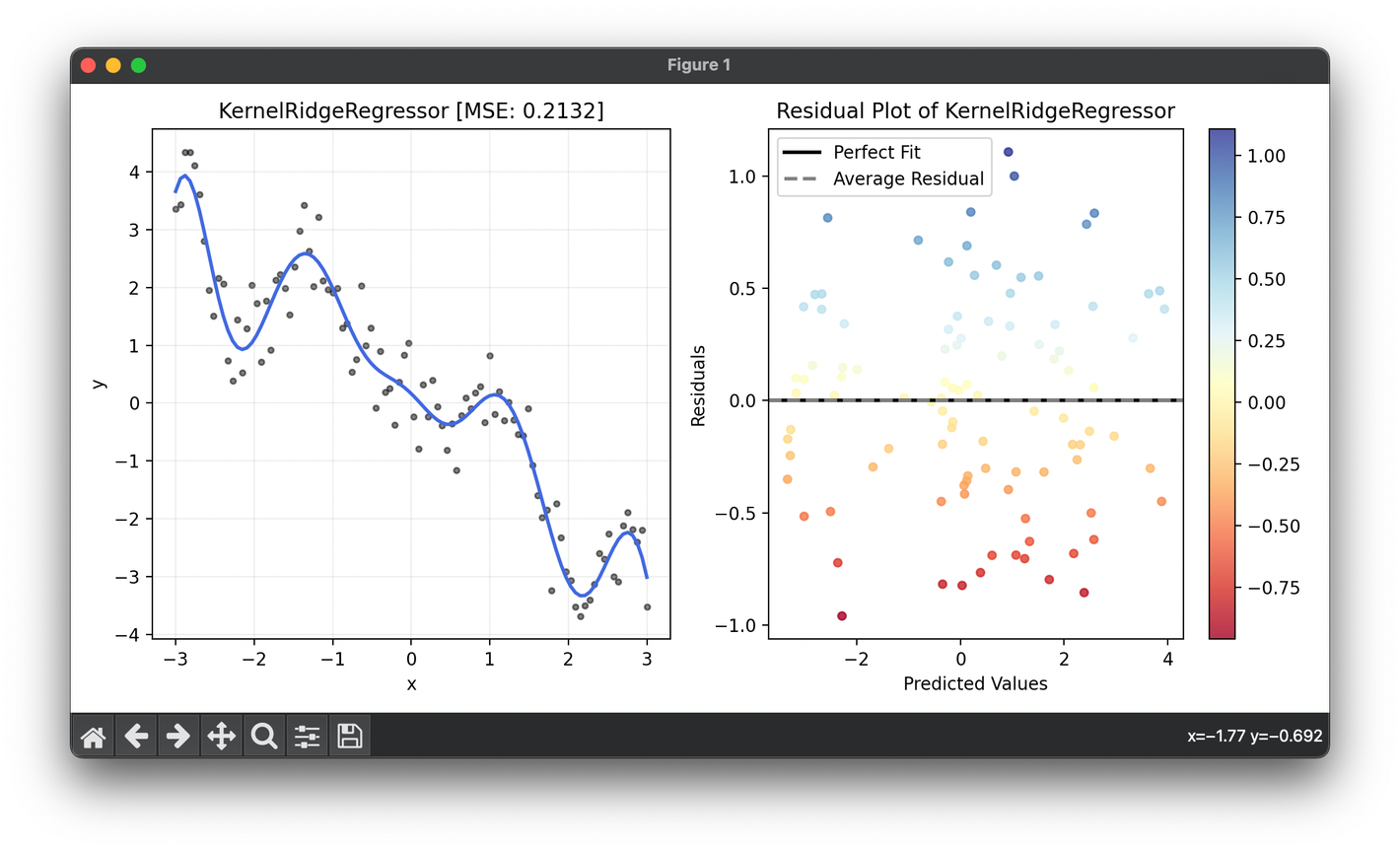
Kernel Ridge Regression is an advanced machine learning algorithm that combines ridge regression's regularization techniques with the kernel trick.
93.[Regressor] Bayesian Ridge Regression
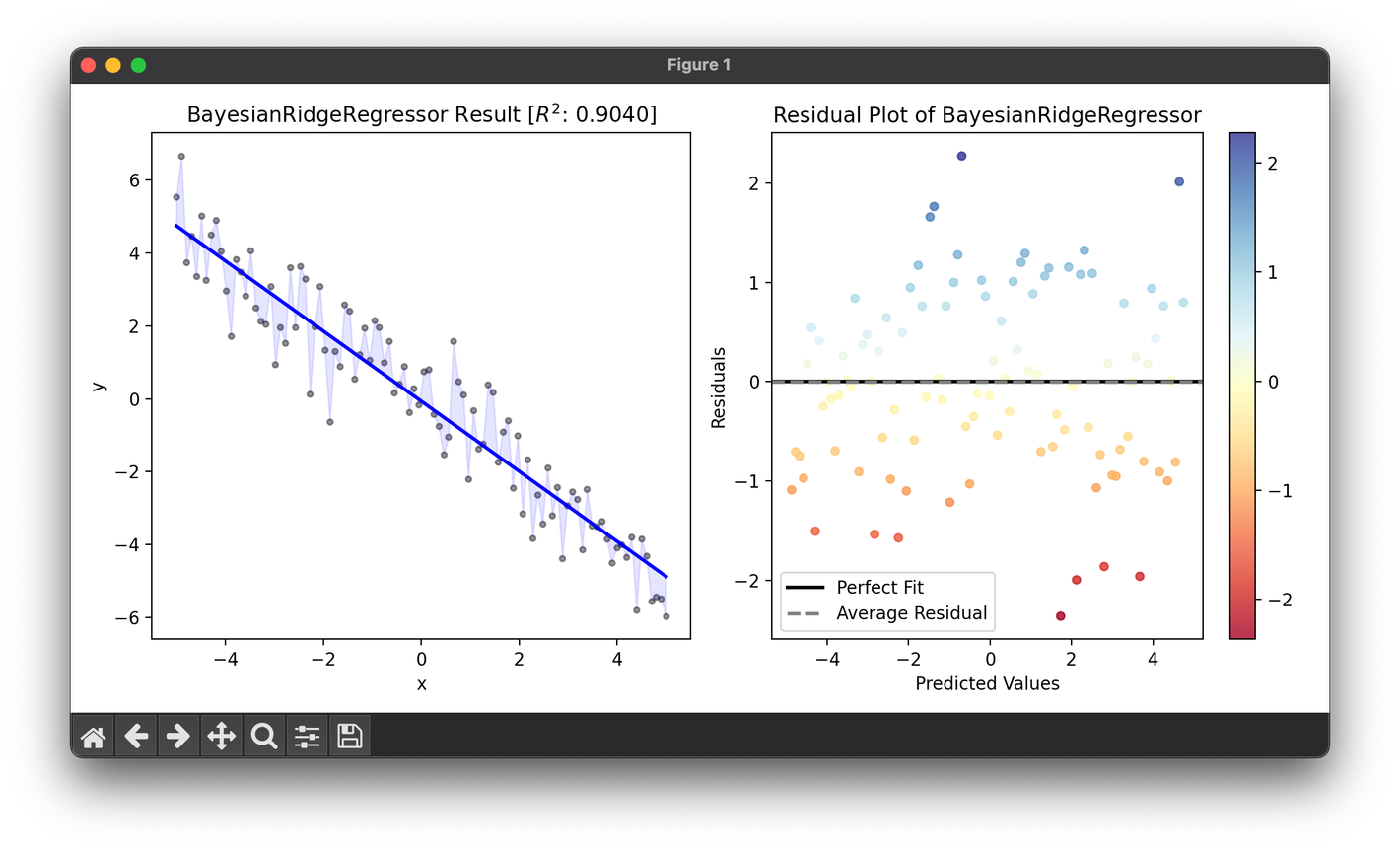
Bayesian Ridge Regression extends traditional ridge regression by incorporating Bayesian inference, offering a probabilistic approach to regression.
94.[Regressor] K-Nearest Neighbors Regression
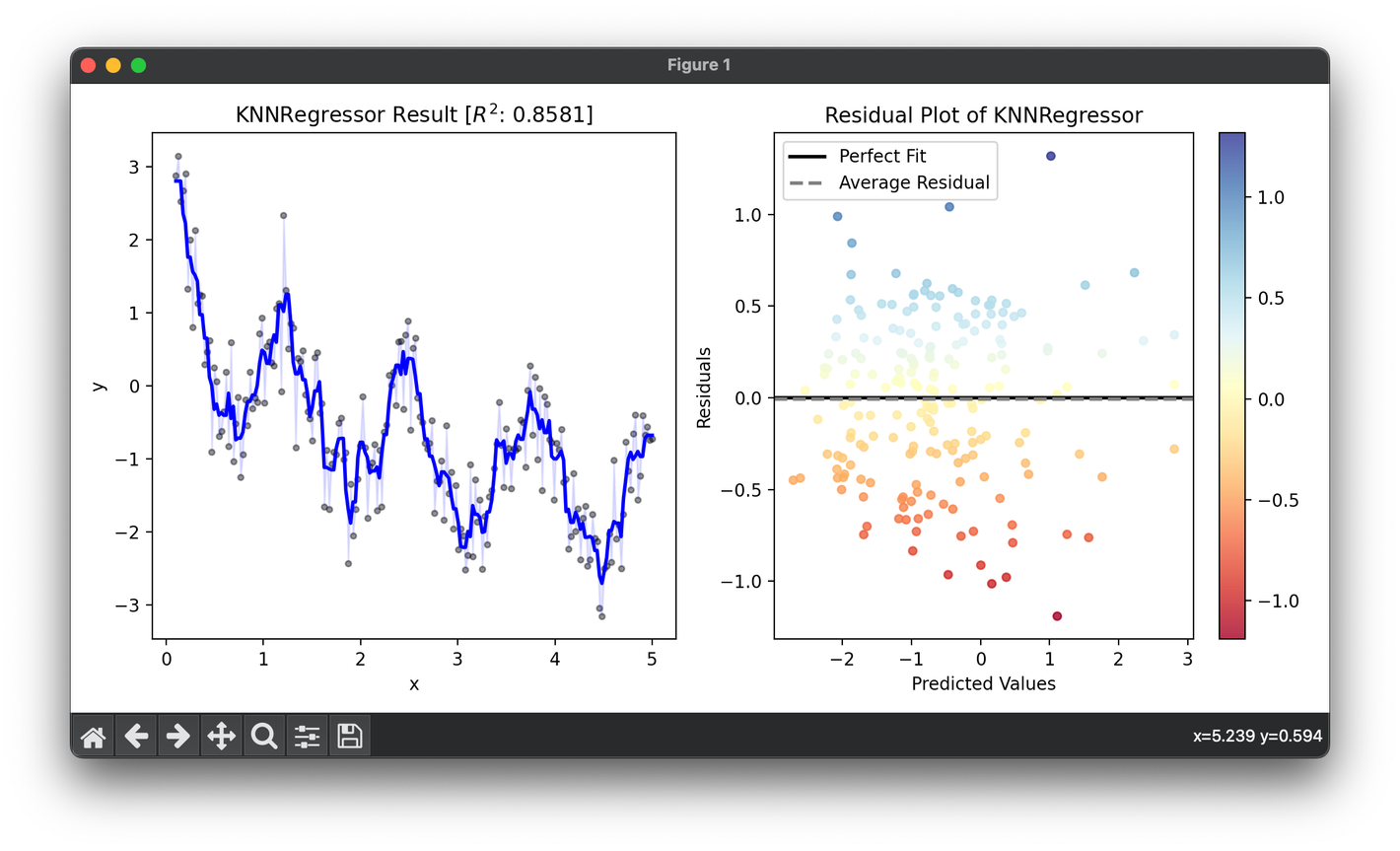
The k-Nearest Neighbors regressor is a type of instance-based learning, or lazy learning, where the function is only approximated locally.
95.[Regressor] Adaptive KNN Regression
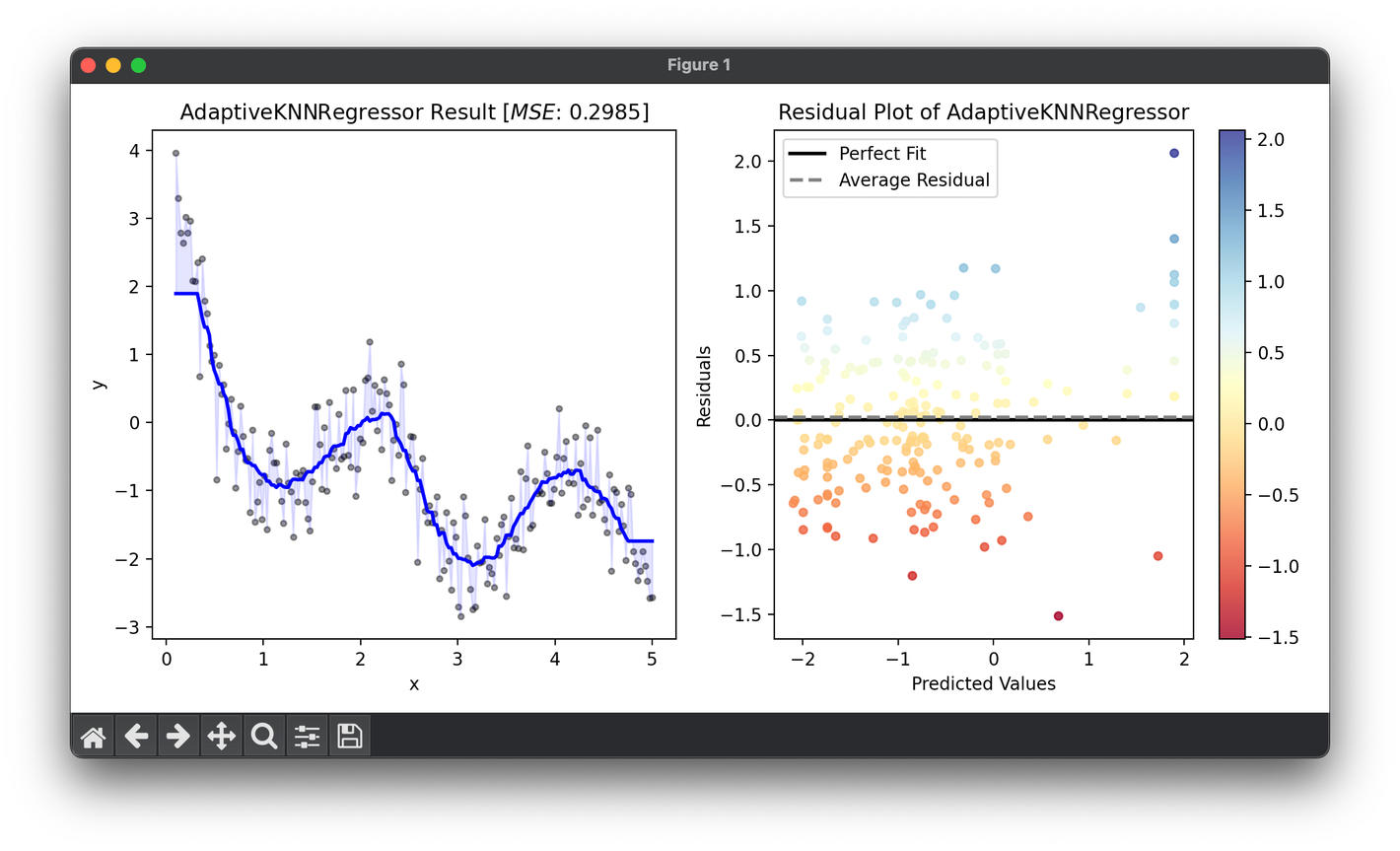
Adaptive k-Nearest Neighbors (Adaptive KNN) regression is an enhanced variant of the standard KNN regression algorithm.
96.[Regressor] Weighted KNN Regression
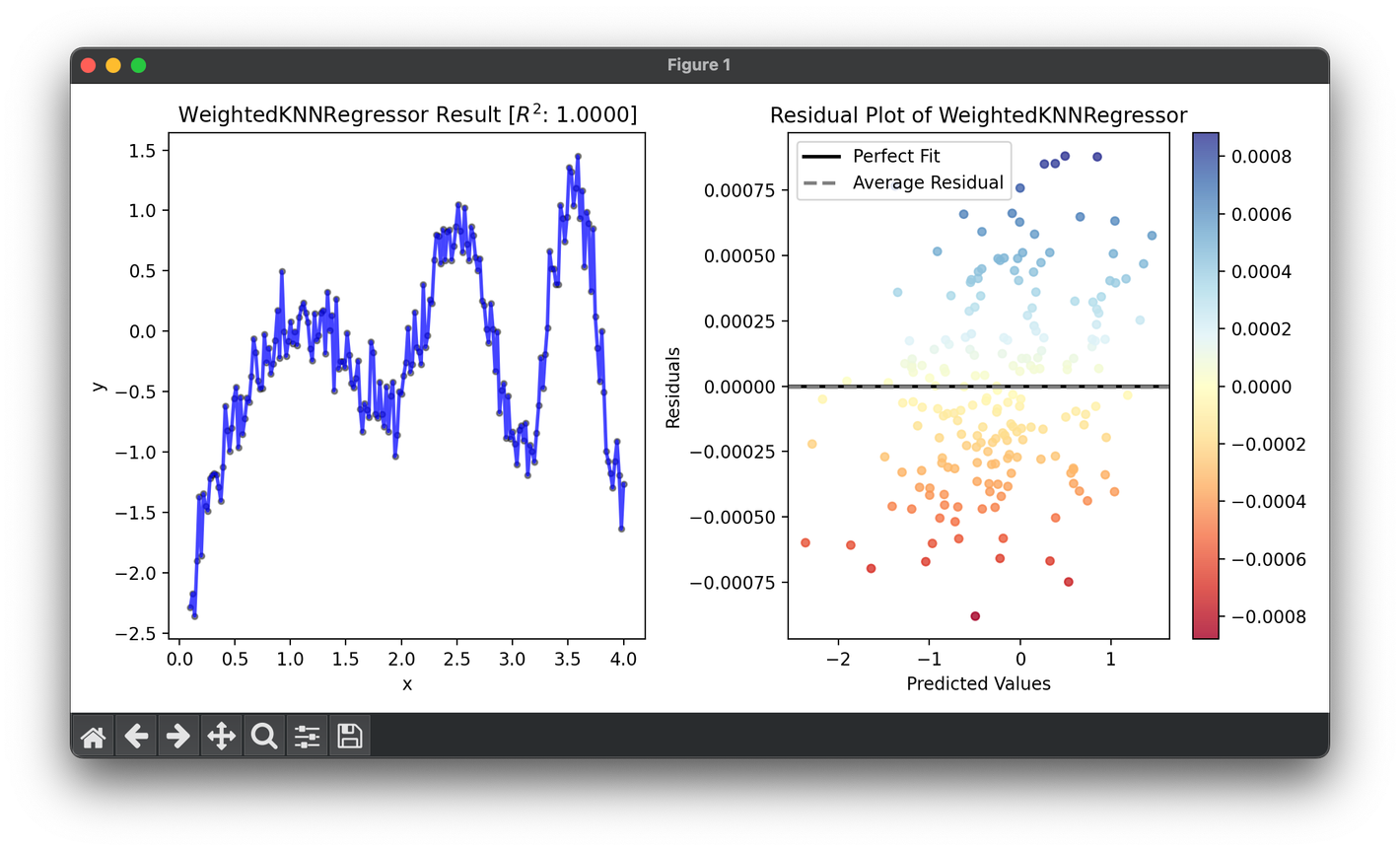
Weighted k-Nearest Neighbors regression is an advanced variation of the basic KNN regression algorithm, which assigns weights to their contributions.
97.[Regressor] Polynomial Regression
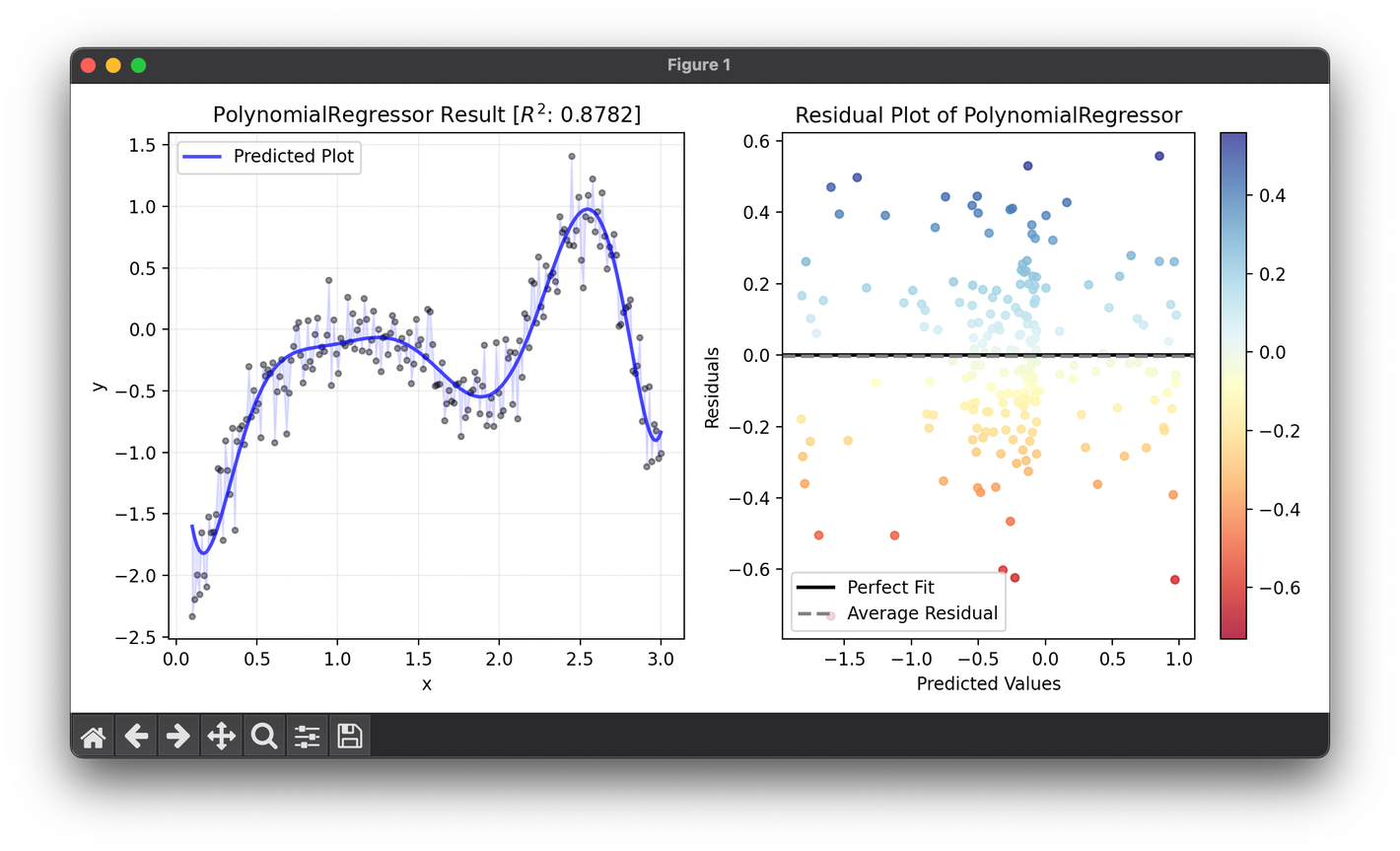
Polynomial regression is a statistical technique that expands the capabilities of linear regression by modeling the relationship between the variables
98.[Regressor] RANSAC
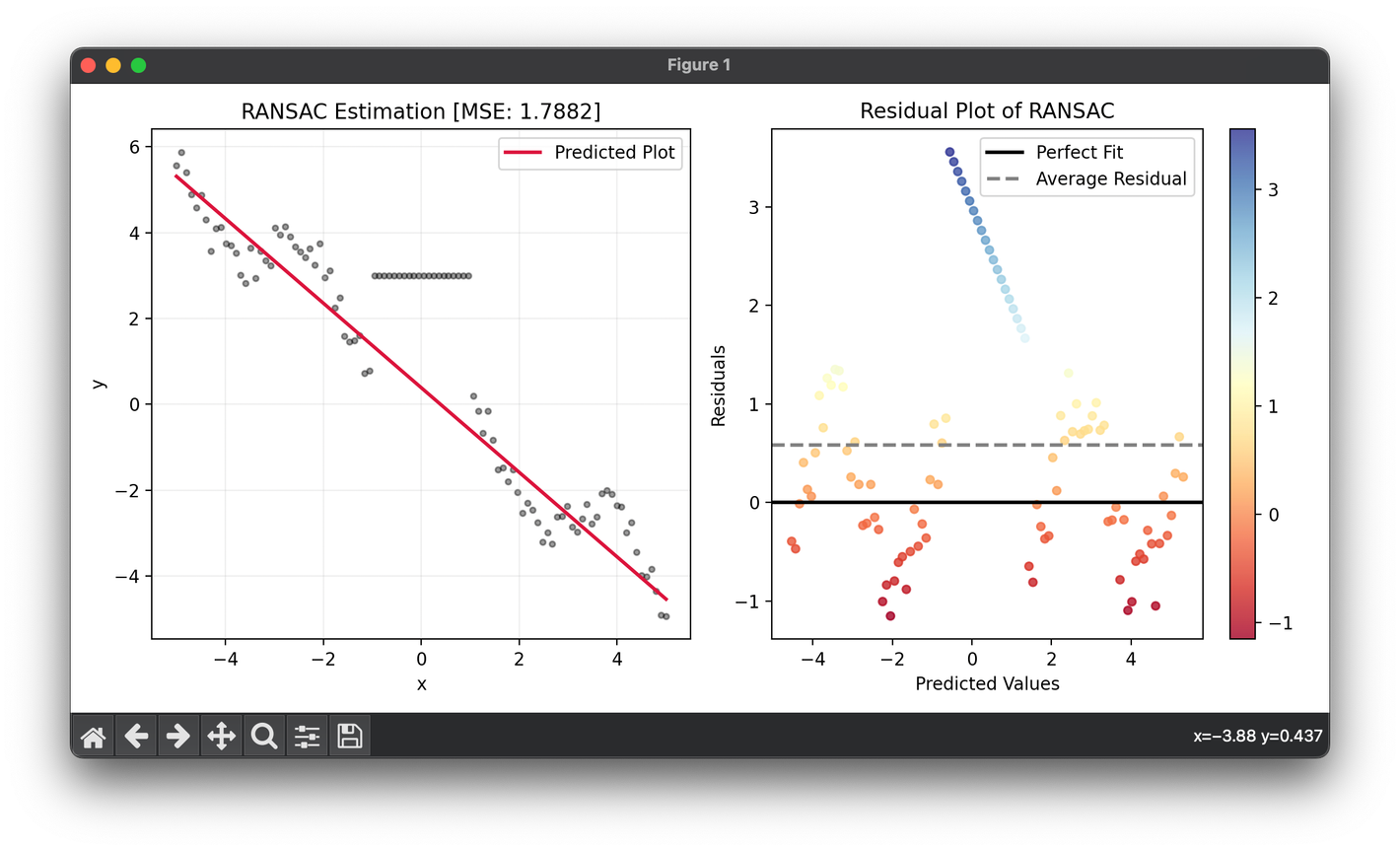
RANSAC is an iterative method to estimate parameters of a mathematical model from a set of observed data that contains outliers.
99.[Regressor] MLESAC
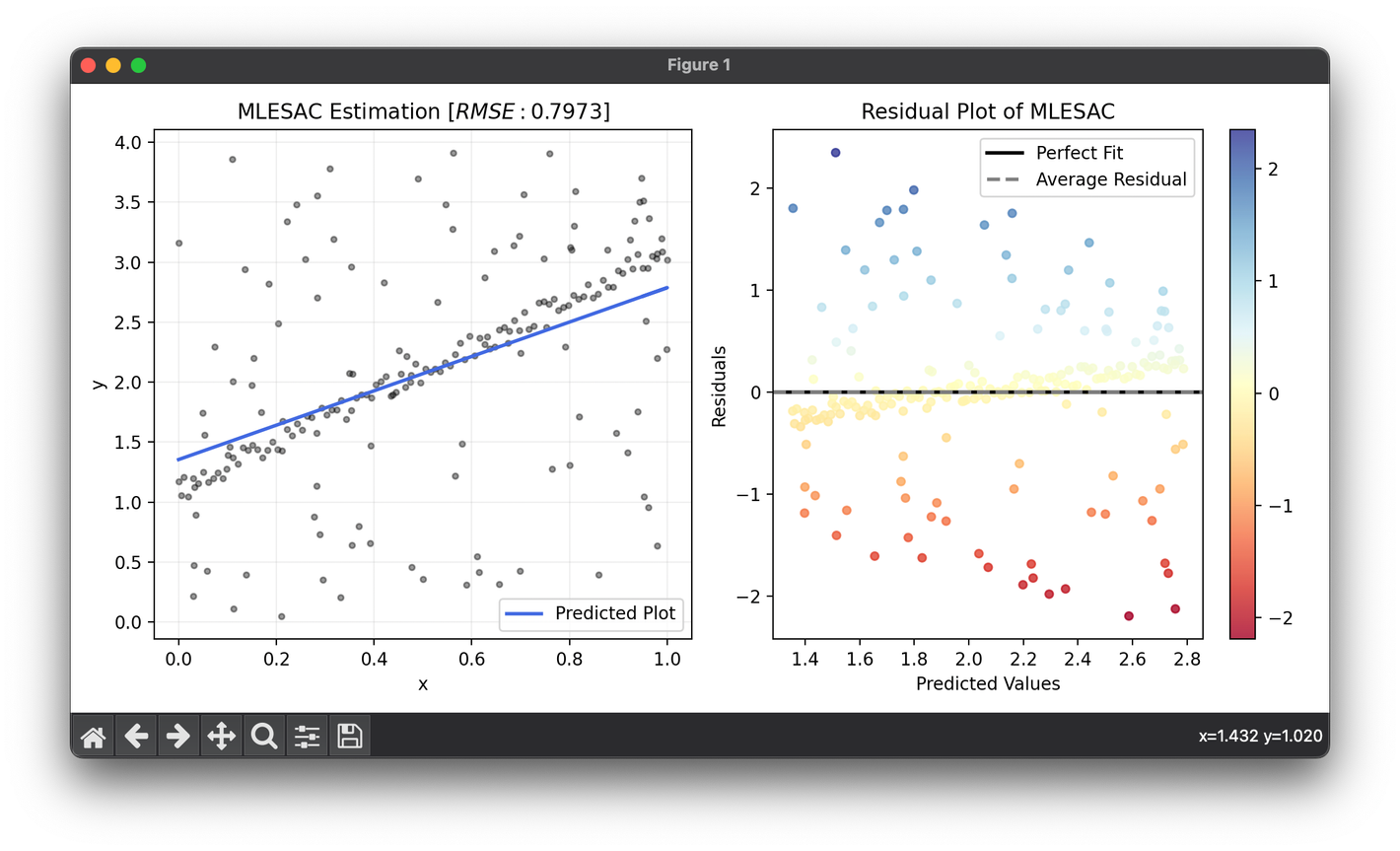
MLESAC algorithm extends the RANSAC methodology by incorporating a probabilistic framework for model fitting in data sets with significant outlier.
100.[Regressor] Support Vector Regression (SVR)
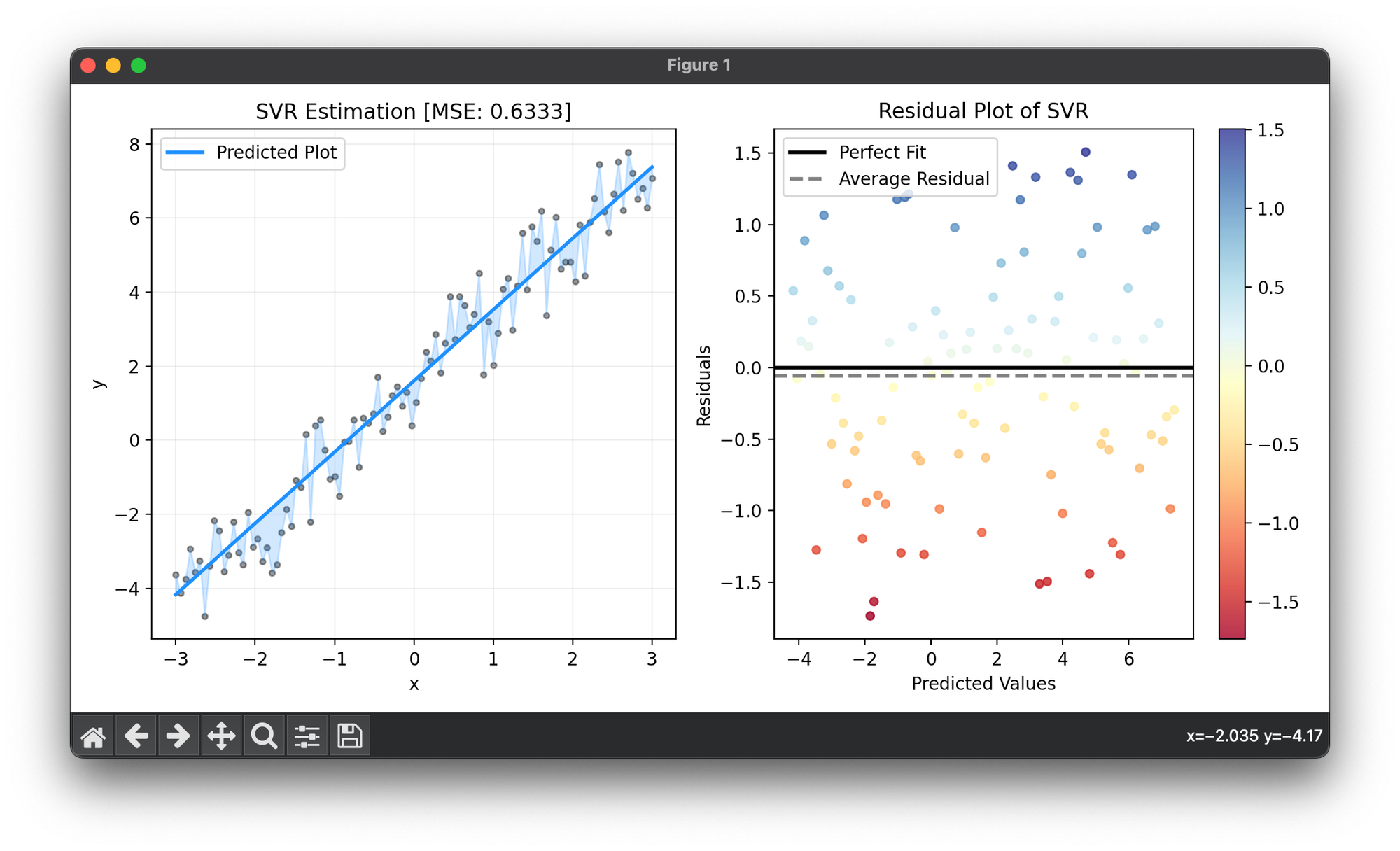
Support Vector Regression (SVR) extends the principles of Support Vector Machines (SVMs) from classification to regression problems.
101.[Regressor] Kernel Support Vector Regression (Kernel SVR)
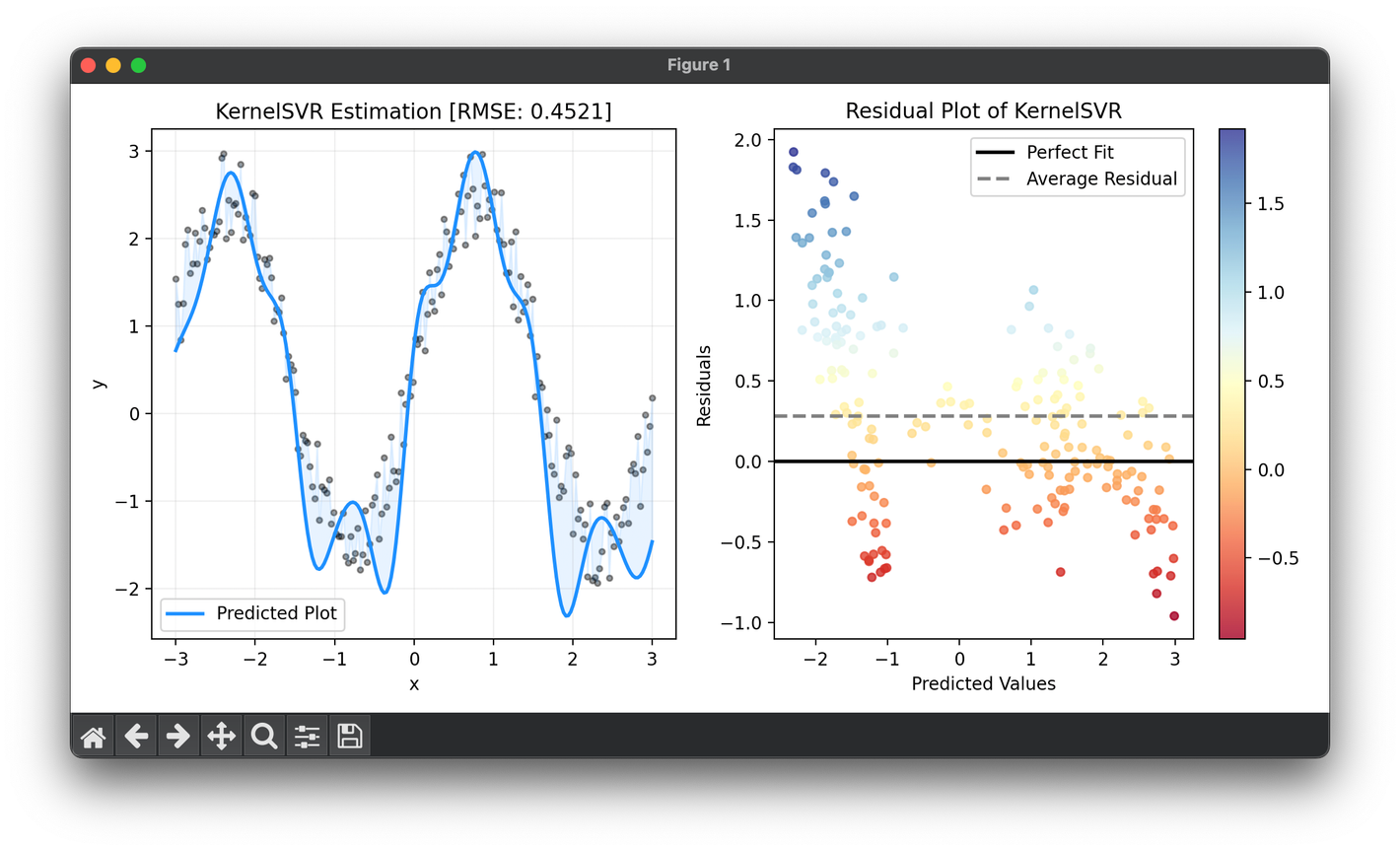
Kernel SVR is an advanced machine learning algorithm that extends the concept of Support Vector Regression by employing kernel functions.
102.[Regressor] Decision Tree Regression
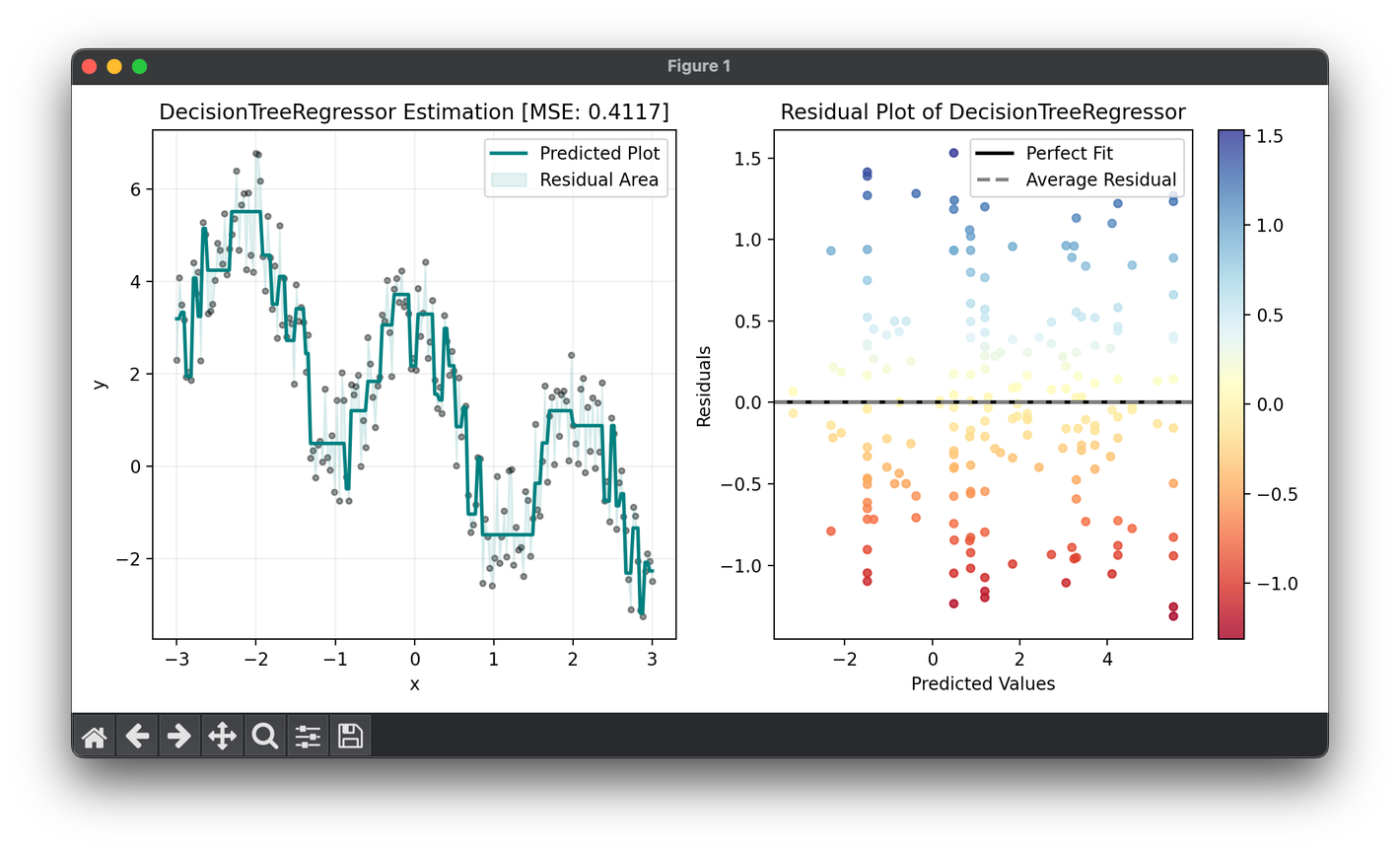
Decision Tree Regression is a versatile machine learning algorithm used for predicting a continuous quantity.
103.[Preprocess] Local Outlier Factor (LOF)
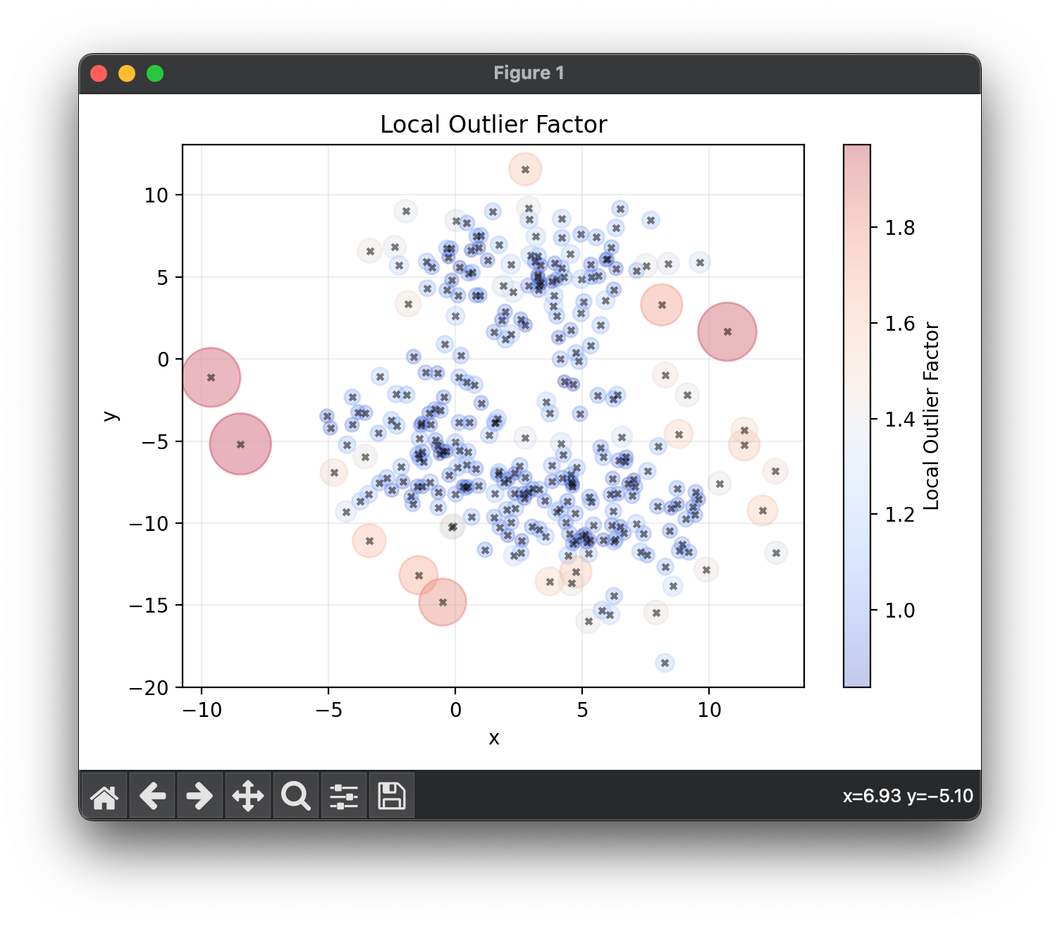
The Local Outlier Factor (LOF) algorithm is a density-based outlier detection method used in data analysis and machine learning to identify anomalies.